本文分两个部分,第一个部分是论文的笔记,第二个部分是结合代码来看fast-RCNN。
论文部分:
主要是为了对RCNN,SPPnet的效果上的改进,下面简述了一些RCNN的缺点:
- Training is a multi-stage pipeline
- Training is expensive in space and time
- object detection is slow
对于RCNN(SPPnet也差不多)来说,训练包括很多个阶段:提取特征、调整CNN网络、训练SVMs和对bbox做回归修整,而且,CNN得到的feature会被写入到磁盘,会占用很大的磁盘。
所以,在这里fast RCNN的主要贡献:
- 相比于RCNN和SPPnet,fast RCNN有更高的目标检测质量(mAP)
- 训练是一个单阶段的过程,使用了multi-task loss(多任务损失)
- 训练时可以更新所有网络层
- 无需磁盘存储feature的缓存
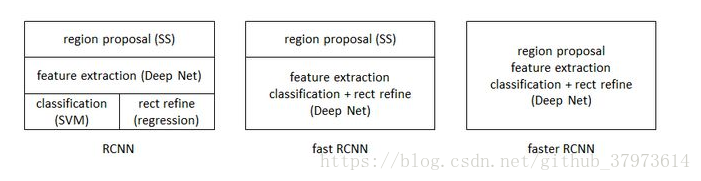
下面是fast RCNN的网络结构:它的输入有两部分,一是the entire image,二是a set of object proposals(即候选框的信息),通过卷积网络,从entire image中提取出feature map,然后,对于每一个object proposal,RoI pooling layer就从feature提取出对应的且fixed-length feature vector,然后这样得到的每一个feature vector送入到后面的FCs层。

网络的细节:
- RoI pooling layer:RoI pooling layer是将hxw的RoI window平分为HxW个子窗口,然后在子窗口里最大池化,即取其中的最大值,这样的操作,会使不论输入多大的尺寸,输出都会是一样的尺寸。paper中使用的是7x7。
- Initializing from pre-trained networks:一个预训练的网络来初始化一个fast RCNN需要三个转换:1、最后一层最大池化被一个RoI层代替和第一个全连接层相容;2、最后一个全连接层和softmax层被前文所述的兄弟层【即上图所示的softmax层和regressor层】替代;3、网络需要被修改成采用两个输入:一个图像列表和这些图像中的RoIs列表。
- Fine-tuning for detection:在fast RCNN训练的时候,SGD mini-batches是分层抽样的,首先采用N张图片,然后采用对每一张图片采样R/N个RoIs。关键是在前向和反向计算时,来自同一张图片的RoIs共享计算和内存,这将大大减少一个mini-batch的计算。例如,当N=2,R=128时,这种方法比从128个不同的图像中提取一个RoI的方法要快64倍。这种策略的缺点是可能会减慢训练的收敛,因为来自同一张图片的RoIs是相关的。但是在实践中这种担忧没有出现,当N=2,R=128时,比RCNN使用更少的SGD迭代次数得到了更好的效果。
- Multi-task loss:fast RCNN有两个输出,一个是对于每一个RoI类别判断的离散的概率分布
【k个类别,再加上一个背景】,另一个输出就是bbox的回归偏移
,下图是用于多分类任务的损失函数,u是ground-truth class,而v是ground-truth bbox regression target。这里的
应该是log损失函数。
- Multi-task loss:fast RCNN有两个输出,一个是对于每一个RoI类别判断的离散的概率分布
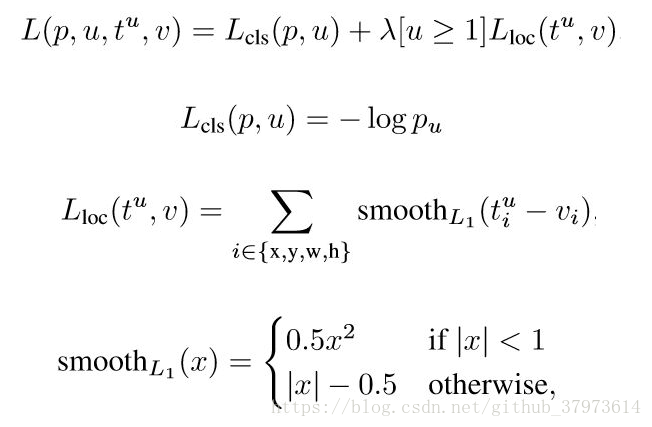
-
- Mini-batch sampling:每个mini-batch来自N=2张图片,mini-batch size取R=128,也就是每张图片里取64个RoIs。25%的RoIs和ground-truth的IoU有至少0.5,剩下的75%RoIs取自最大IoU在[0.1, 0.5)之间的候选区域,代表u=0的背景样例。训练时,图片以0.5的概率采用水平翻转,不采用其他的数据增强技术。
- Back-propagation through RoI pooling layers:这一部分推导ROI层前向和反向传播函数
- SGD hyper-parameters:分类和回归的全连接层分别被初始化为0均值的高斯分布,标准差分别是0.01和0.001,偏置项初始化为0,learning rate=0.001,30k次迭代后,lr降至0.0001,再训练10k次。但是训练大数据时,迭代更多次数,momentum=0.9,weight_decay=0.0005【权重衰减用在正则项】。
- Scale Invariance:尺度不变性的目标检测方法 1、蛮力学习法;2、图像金字塔的方法
Fast R-CNN detection
- 对于整张图片的分类,花在全连接层的时间要远小于卷积层。而对于检测任务,当RoIs的数量较大的时候,大约一半的时间都用在计算全连接层。这时,可以对全连接层采用SVD(奇异值分解)的方法, 减少其参数,从而加快运算速度。
- 一些实验结果
设计的评估
- 多任务训练确实对提高performance有帮助
- 对于尺度不变性,蛮力方法(single)更好,image pyramid(multi-scale)只能带来少量的mAP的提升,但是却让计算时间增加。也验证了SPPnet中的结果:深度卷积网络善于直接学习尺度不变性。
- SVMs并不是比softmax更好。

参考:https://zhuanlan.zhihu.com/p/22757861
代码部分:
GitHub上的fast-RCNN源代码:https://github.com/rbgirshick/fast-rcnn
可以使用caffe代码可视化工具:http://ethereon.github.io/netscope/#/editor
这里可视化的是models文件下的caffenet【分别还有VGG16中型模型、VGG_CNN_M_1024大型模型】来可视化,caffenet是Alexnet的一个变体,网络结构的变动主要是调整了pool和norm的位置。
