本论文由FAIR的Kaiming He等联合创作。
1. 介绍
Mask R-CNN可以同时执行目标检测和实例分割任务,下图是它的架构:

Mask R-CNN是在Faster R-CNN上扩展出了一个并行分支,用来进行实力分割任务,原分支继续执行边界框预测任务。用来进行实例分割的分支就是一个作用于每一个ROI的简单的FCN。
2. 相关工作
R-CNN
R-CNN在每一张图片上生成多个候选区域,在每一个候选区域上独立的运行卷积网络预测对象位置。R-CNN在RoIs的特征映射上采用RoIPool来提高速度和准确度。Faster R-CNN增加了一个候选区域网络(RPN),是当下顶级的架构。
实例分割
早期的方法采用自下而上的分割,DeepMask和后面的一些方法采用推荐分割区域的方法,然后使用Fast R-CNN进行分类。上述的方法都是先进行分割,然后再分类,这样很慢且不准确。
3. Mask R-CNN
Faster R-CNN对于每一个候选对象有两个输出,类别标签和边界框补偿,Mask R-CNN在此基础上,增加了一个object mask的输出。
Faster R-CNN
首先简要回顾一下Faster R-CNN。Faster R-CNN分为两个stage,RPN(产生候选对象边界框)和Fast R-CNN(使用RoIPool提取特征,然后分类和边界框回归)。
Mask R-CNN
Mask R-CNN也分为两个stage,第一个依然是RPN,第二个在分类和边界框的基础上,增加了一个二进制mask的输出。
训练过程中,对于每一个RoI定义了一个多任务loss:

分别为分类loss,边界框预测loss和mask预测loss。前两个与Fast R-CNN所定义的一样。这里说一下mask预测loss。对于每一个RoI,输出为
mask预测损失的设计方法,解耦了mask预测和分类预测,有更好的效果。
Mask Representation
mask编码了一个输入对象的空间布局,是pixel-to-pixel级别,因此需要使用全卷积层。类别和边界框预测后面是用全连接层。
作者使用FCN(全卷积层),这种pixel-to-pixel级别的映射,需要RoI特征保存确切的空间相关性,因此作者提出了RoIAlign层。
RoIAlign
做segment是pixel级别的,但是faster rcnn中roi pooling有2次量化操作导致了没有对齐

两次量化,第一次是将RPN输出的相对于原图像上的rois的坐标映射feature mapping上,第二次是在划分bin。

RoIAlign的做法如下图:

Network Architecture
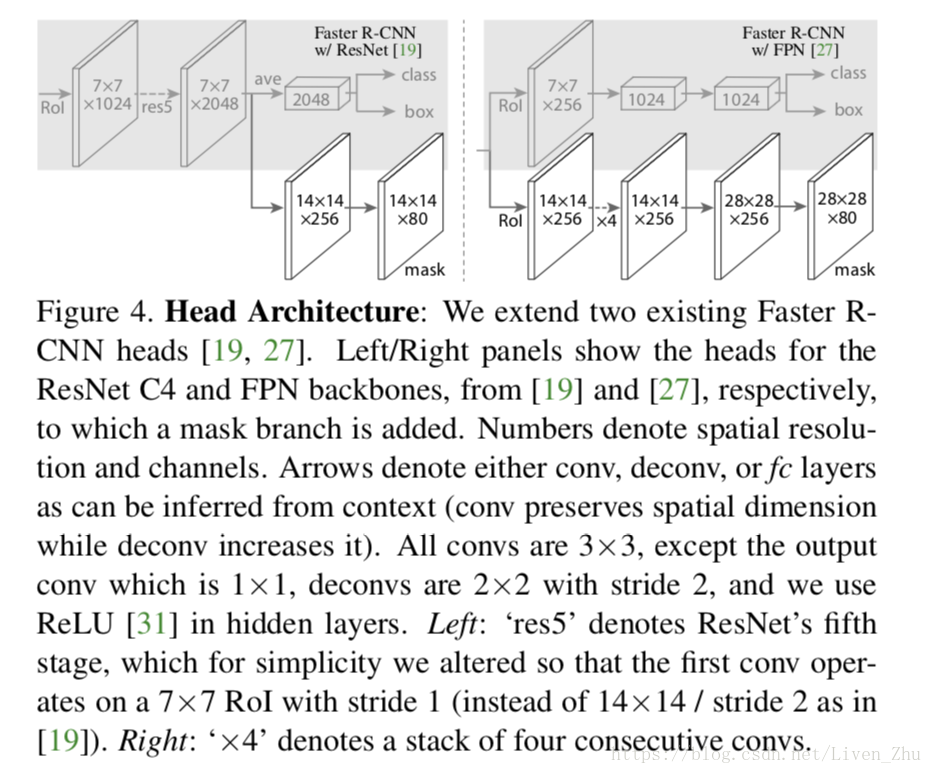
作者为了表述清晰,将Mask R-CNN网络分为两部分,(i)前半部分称为convolutional backbone,用来提取图像特征;(ii)后半部分称为head,用来进行进行分类,边界框回归和mask预测。下图为MaskR-CNN在使用ResNet网络的Faster R-CNN和在使用FPN网络的Faster R-CNN的head架构:
Implementation Details
训练:如果一个RoI与ground-truth的IoU大于0.5,判定该RoI为正例,否则为负例。mask损失只在正例上定义。mask就是一个RoI与其ground-truth的交集。
作者采用一图想为中心的训练方式。重新设置图像的大小。每一个GPU上的mini-batch有2张图像,每一个图像有N个RoIs,这些RoI的正负例比例为1 :3。对于采用ResNet网络的Mask R-CNN来说,N=64;采用FPN的Mask R-CNN,N=512。作者同时在8个GPU上进行训练,迭代160k次,开始的学习率为0.0001,迭代到120k时,学习率降为0.00001。使用0.0001的权重衰减和0.9的momentum。RPN设置5种规模的anchors,每种包含3中长宽比。RPN单独训练,不与Mask R-CNN分享权重。
推断:对于采用ResNet网络的Mask R-CNN来说,N=300;采用FPN的Mask R-CNN,N=1000。在这些proposal上进行box prediction,然后进行non-maximum suppression。然后,mask加到加到分数最高的100个检测box上,这与训练采用的并行方式是不同的。mask分支可以在每个RoI上预测K个masks,但是我们只使用第k个mask,k是分类分支预测的该RoI的类别。m*m个浮点数mask输出被resize成RoI的size,然后用0.5的阈值进行二值化。
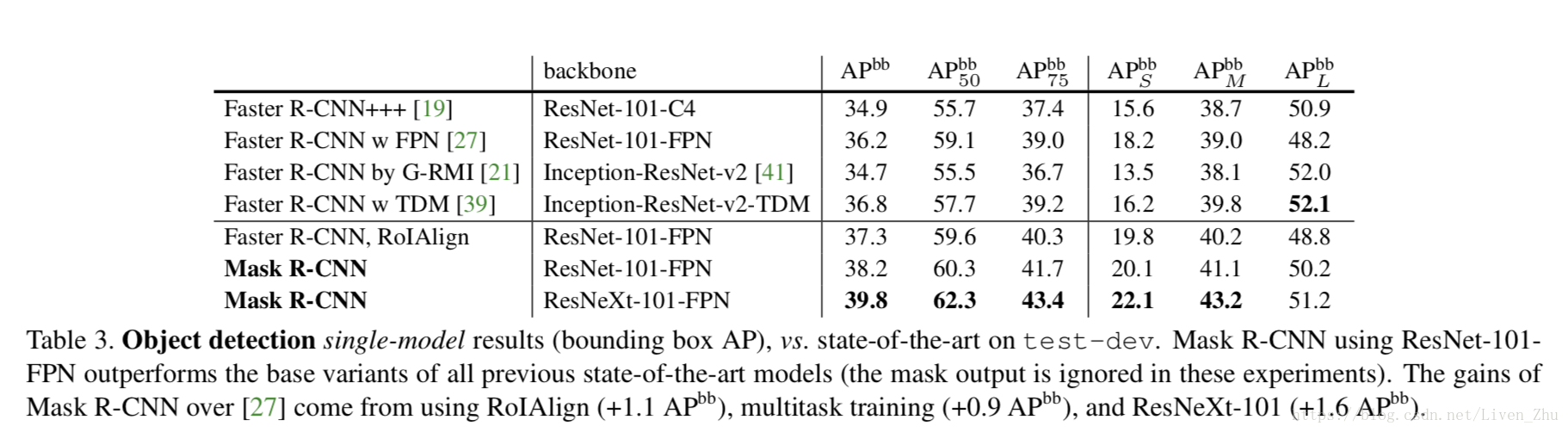
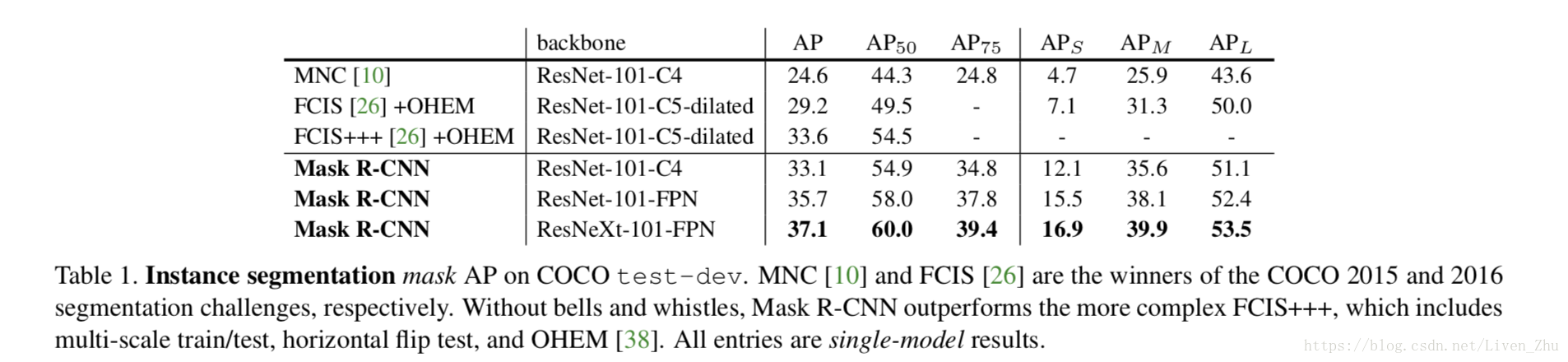
4. Experiments:Instance Segmentation



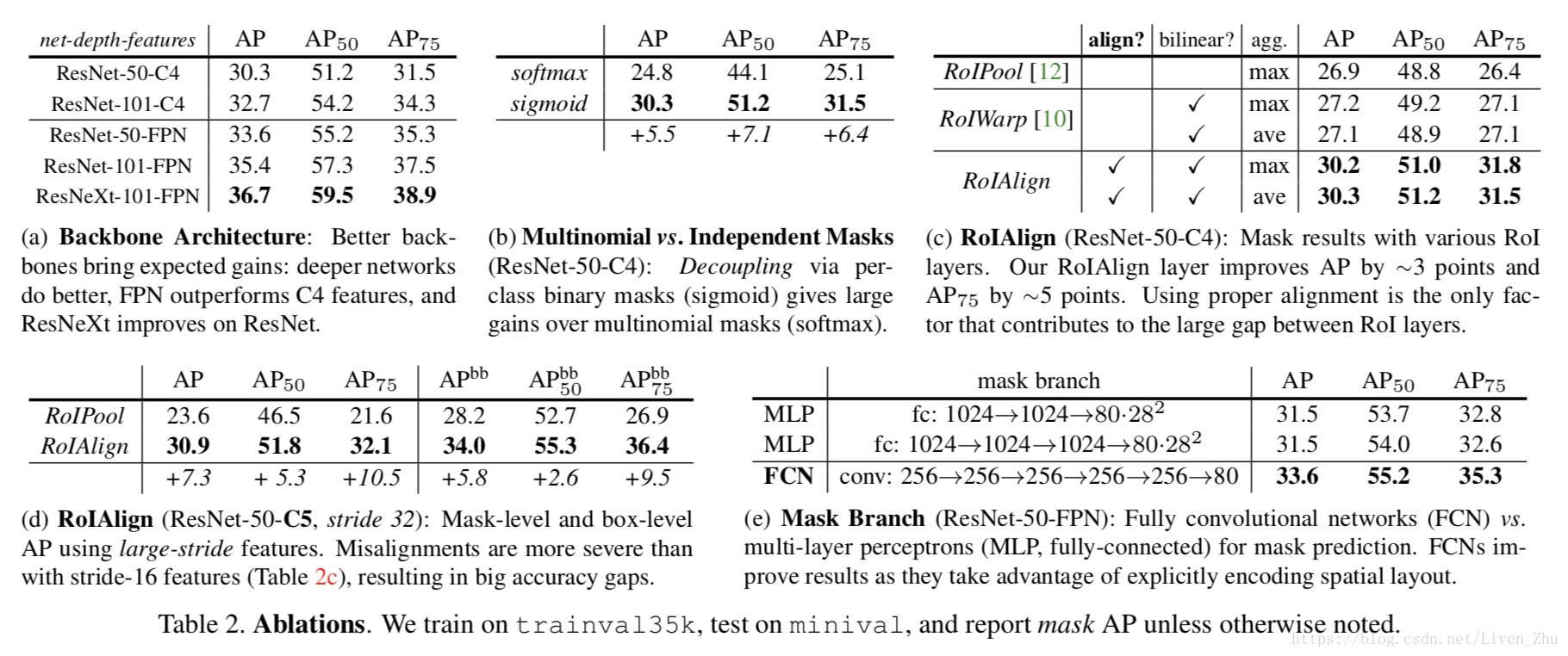
Ablation Experiments