前言
在目标检测中,通常会设定一个IoU阈值来区分正样本和负样本,一般将这个阈值设为0.5。但如果以0.5的阈值来训练检测器,检测器会生成许多noisy bbox。如果增大这个阈值,检测器的性能会下降。原因如下:
- 由于增大了阈值,正样本会减少,在training时会出现过拟合问题。
- 在training时用于训练检测器的阈值,与inference时输入proposal的IoU相差过大。
因此本文提出了Cascade R-CNN用来解决这个问题,下面进行详细介绍。
介绍
目标检测需要解决两个主要任务:第一,检测器要进行识别,需要区分前景和背景,并为前景中的目标标记正确的类别标签;第二,检测器要进行定位,将不同的目标用bbox框起来。在这两个过程中,检测器会遇到许多close false positive,即那些非常接近正确的bbox,但它们本身又不是正确的bbox。
目前许多目标检测方法是基于R-CNN的two-stage方法,它们在training时将IoU阈值u设为0.5,这会产生很多正样本,但在inference时,检测器会产生许多noisy bbox,如下图(a)所示,这是由于大多数close false positive的IoU是大于0.5的。也就是说,当阈值为0.5是,虽然能产生丰富的样本,但很难训练出能拒绝close false positive的检测器。

如果将用于训练检测器的阈值提高,比如提高到0.7,那么在inference时检测器的输出结果如上图(b)所示,可以看到close false positive的数量变少了。

上图训练了三个不同的检测器,对应的阈值u分别是u = 0.5,0.6,0.7,其中u是在trainging时训练检测器所用的阈值。图(c)和图(d)分别描述了定位性能和检测性能。在图(c)中,横轴是输入的proposal的IoU,纵轴是proposal经过bbox回归后的IoU,可以看到,定位性能可以看成是相对于输入的proposal的IoU的函数。在图(d)中,横轴是inference时设定的IoU阈值,纵轴是检测器的性能,可以看到,检测性能可以看成是相对于设定的IoU阈值的函数。
在图(c)中,当输入pososal的IoU与阈值接近时,bbox回归输出的IoU是最好的。在图(d)中,当输入的proposal的IoU较低时,u=0.5比u=0.6时的检测性能要好;而当输入的proposal的IoU较高时,u=0.6比u=0.5时的检测性能好。也就是说,一个检测器以一个IoU阈值被训练到最佳之后,如果在inference时输入的proposal的IoU与阈值不同,那么检测器就不能达到最佳性能。这也就意味着,只有当训练检测器用的阈值和proposal自身的阈值较为接近的时候,检测器的性能才最好。否则就会出现mismatch问题(接下来会详细说明)。同时只有当proposal有较高质量时,检测器才会有较好的表现,如上图(b)所示。但是proposal有较高质量意味着阈值u的增大,那么是不是阈值设置的越高,检测器的性能就越好呢?
答案是否定的。在上图(d)中,当阈值为0.7时,检测器的性能反而下降了。这是由于当阈值设定的较高时,在training时大部分proposal的IoU都是低于阈值的,也就是正样本数量很少,会导致过拟合问题。另一个原因是,training时设置的用于训练检测器的阈值,与inference时输入的proposal的IoU相差太多。trainging时IoU阈值u设定较高的检测器,只有在inference时proposal的IoU也较高时,检测器才能获得很好的性能;如果proposal的IoU较低,检测器的性能将不会很好。
本文提出了Cascade R-CNN用来处理这些问题。在Cascade R-CNN中,training是stage-by-stage的,用一个阶段的输出训练下一个阶段。为什么会提出这种想法呢?从图(c)中可以看出,所有的点基本都在那条灰线的上面,也就是说,通过bbox回归输出的proposal的IoU比输入的proposal的IoU要高。因此,以一个确定的IoU训练的检测器的输出,可以作为另一个有着更高IoU阈值的检测器的输入。
Cascade R-CNN的大致原理如下:
- 通过调整bbox,每个阶段能找到一系列优质的close false positive来训练下一个阶段。也就是说,在training时,一系列检测器中的IoU阈值是不断增大的,能够克服过拟合问题。
- 在inference时,输入proposal的IoU是不断增大的,并且与每个阶段的检测器的IoU阈值相差的很小,这使检测精度更高。
mismatch问题
在training阶段,proposal与ground-truth之间的IoU是可以计算出来的,通过设定一个IoU阈值u将proposal划分为正样本和负样本。在inference阶段,由于不知道ground-truth,因此无法计算proposal的IoU,但它们本身是有IoU的。如果这些proposal的IoU与训练检测器时用的IoU阈值相差的很多,就会出现所谓的mismatch问题。
Cascade R-CNN与类似结构的对比

上图给出了4种不同的结构,
是输入图像,
是主网络,
是池化层,
是network head,
是bbox回归器,
是分类器,
是proposal。
1. Faster R-CNN

图(a)是Faster R-CNN的结构,Faster R-CNN是two-stage的方法。其中第一阶段是
产生proposal,第二阶段是先由
(detection hesd)处理proposal,然后对每个proposal进行bbox回归和分类。
2. Iterative BBox

在Iterative BBox中,所有的head都是一样的,3个分支的IoU阈值都为0.5,存在的问题如下:
- 单一阈值0.5并不能对处理所有的proposal都有良好的效果。当proposal的IoU超过0.85时,bbox回归的性能会下降,即通过bbox回归输出的IoU小于输入proposal的IoU;
- 如下图所示,在每次迭代后proposal的分布会改变的非常明显。回归器在初始分布时达到最优,但在之后的每次迭代后由于分布的改变,回归器无法达到最优。

可以看到,从1st stage到2nd stage,proposal的分布已经发生很大的改变了。1st是初始阶段,IoU阈值为0.5。当经过一次迭代到2nd时,proposal更靠近ground-truth,即proposal的IoU更高。但此时的阈值仍为0.5,因此会有较多的离群点,也就是图中红色的点。如果不提高阈值来去掉这些离群点,就会引入大量噪声干扰,对结果造成不利影响。
3. Integral Loss
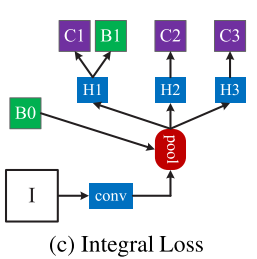
在目标检测时,如果IoU阈值u设的过高,将没有足够的正样本来训练,会出现过拟合问题;如u设的过低,正样本虽然变多了,但检测器难以拒绝close false positive。一个解决问题的方法是设计分类器的集合,如上图(c)所示,每个分类器对不同的u进行处理,不同的u也有不同的loss值:
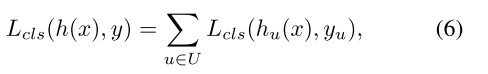
其中U是一系列IoU阈值的集合,在inference时需要将这些分类器集合起来。
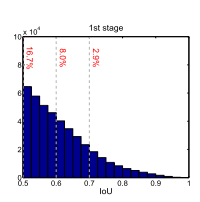
从上图可以看出,随着u的增大,正样本的数量迅速减少。也就是说,在式(6)中,随着u的改变,不同的loss值处理的正样本数量是不同的。这存在以下问题:
- 高阈值的分类器会过拟合;
- 在inference时,需要将3个分类器集合起来,这时高阈值的分类器也要处理大量低IoU的proposal,存在严重的mismatch问题。
Cascade R-CNN

在Cascade R-CNN中,回归器被设计为:
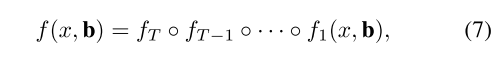
其中
是cascade stage的总数,注意每个
将每个bbox的分布{
}回归到相对应的stage,而不是bbox的初始分布{
}。
Cascade R-CNN的回归器有以下三个特点:
- 级联回归(cascade regression)其实是重采样的过程,改变proposal的分布,也就是在每个stage改变proposal的IoU,从而能够被不同的stage处理;
- 因为training和inference都用到了级联的方式,因此在training和inference时的proposal分布是没有差异的;
- { }是对不同stage的重采样分布的优化。
Cascade 检测
- 如上图(d)所示,B0是RPN提出的最初的proposal,它们的IoU都很低;
- B0经过第一个回归器B1后,通过级联回归进行重采样,生成IoU更高的proposal,作为下一个stage的输入;
- 进行stage-by-stage的训练,每个stage的输出作为下一个阈值更高的stage的输入
通过这种方式,即使检测器的阈值增大,也可以将连续的proposal保持在大致恒定的大小,带来的结果如下:
- 不会出现过拟合的问题,因为每个stage的检测器都有足够满足阈值的样本;
- 更深的stage的检测器能够被更高的阈值优化。
- 在inference时,虽然初始RPN提出的proposal的IoU不是很高,但每经过一个stage后proposal的IoU都会提高,因此与拥有更高阈值的检测器之间不会有很严重的mismatch。
总结
Cascade R-CNN解决的是增大训练时的IoU阈值所带来的两个问题:
- mismatch问题。增大训练时的IoU阈值后,在inference时,输入的proposal的IoU大部分都很低,会与用来训练检测器的IoU阈值相差很多,造成严重的mismatch;
- 过拟合问题。由于增大训练时的IoU阈值,正样本的数量会减少,达不到拥有高阈值检测器所需要的正样本数量,造成过拟合问题。
那为什么还要提高训练时的IoU阈值呢?因为高阈值检测器在inference时处理IoU同样高的proposal时,检测性能会提高。Cascade R-CNN中的级联回归(cascade regression)就是通过stage-by-stage的方法,逐渐增大proposal的IoU,使它们的IoU与高阈值检测器的阈值相差无几,从而使高阈值检测器拥有足够数量的正样本,消除过拟合,并且提高检测性能。
