基于MNIST实现
1 数据集概况
1.1 数据组成
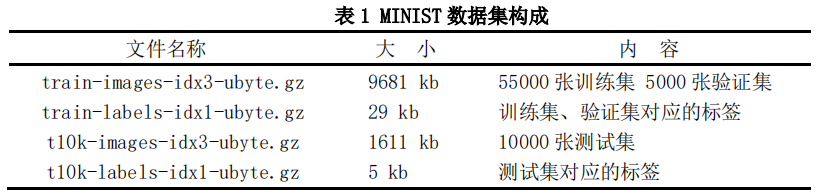
MINIST 数据集总共包含 7 万张手写数字图片,按照 6:1 的比例划分为训练集与测试集。 图片的大小为 28x28,通道数为1,每张图片都是黑底白字,黑底在张量中用 0 表示,白字用0-1 之间的浮点数表示。
具体的数据集及对应标签如表 1 所示。
1.2 数据可视化
使用 showdata.py 查看每一批 batch 中的图片及标签,如图 1。

showdata.py代码:
import torch
from torchvision import datasets, transforms
import torchvision
from torch.utils.data import DataLoader
import cv2
# 下载训练集
# transforms.ToTensor将尺寸为[H*W*C]且位于(0,255)的所有PIL图片或者np.uint8的Numpy数组转化为尺寸为(C*H*W)且位于(0.0,1.0)的Tensor
train_dataset = datasets.MNIST(root='.\dataset\mnist',
train=True,
transform=transforms.ToTensor(),
download=True)
# 下载测试集
test_dataset = datasets.MNIST(root='.\dataset\mnist',
train=False,
transform=transforms.ToTensor(),
download=True)
# 装载训练集
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=64,
shuffle=True)
# 装载测试集
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=64,
shuffle=True)
# [batch_size,channels,height,weight]
images, labels = next(iter(train_loader))
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1, 2, 0)
img = img*255
label=list(labels)
for i in range(len(label)):
print(label[i],end="\t")
if (i+1)%8==0:
print()
cv2.imwrite('1.png', img)
2 LeNet与LeNet5网络结构详解
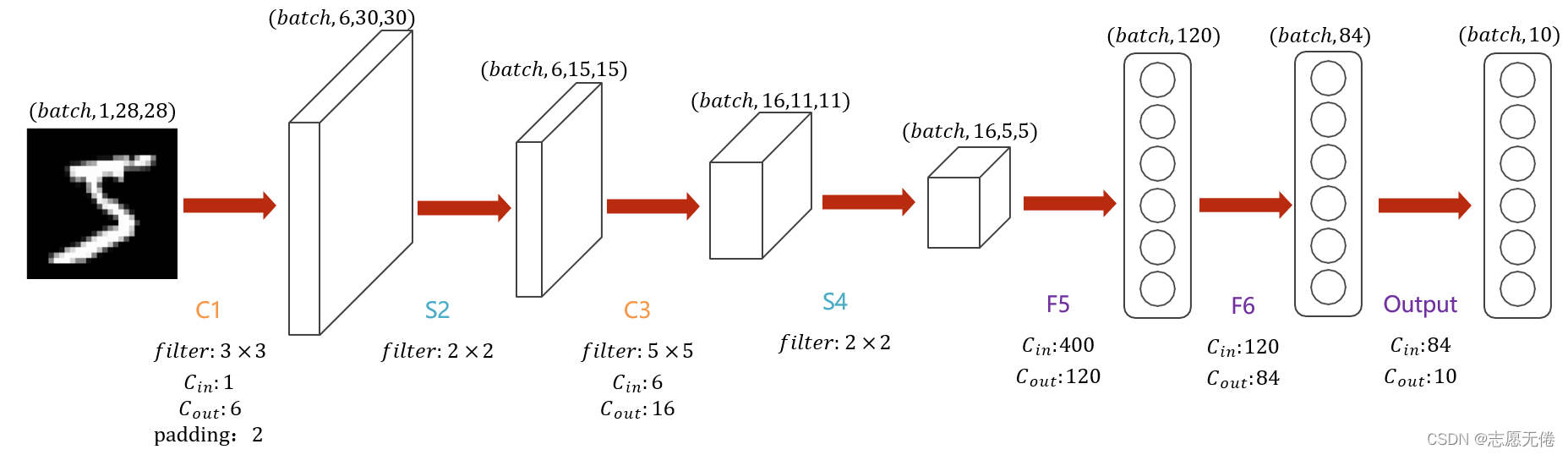
LetNet-5是一个较简单的卷积神经网络。上图显示了其结构:输入的二维图像(单通道),先经过两次卷积层到池化层,再经过全连接层,最后为输出层。
整体上是:input layer->convulational layer->pooling layer->activation function->convulational layer->pooling layer->activation function->convulational layer->fully connect layer->fully connect layer->output layer.
整个 LeNet 网络总共包括7层(不含输入层),LeNet与LeNet5的主要区别在于通道由6->16过程中的卷积操作。
2.1 输入层
输入层(INPUT)是28x28 像素的图像,注意通道数为1。
2.2 C1层
C1 层是卷积层,使用 6 个 3×3 大小的卷积核,padding=2,stride=1进行卷积,得到 6 个 30×30大小的特征图:28+4-3+1=30。
参数个数
(3x3+1)x6=60,其中3x3为卷积核的9个参数w,1为偏置项b。
连接数
60x30x30=54000,其中60为单次卷积过程连线数,30x30为输出特征层,每一个像素都由前面卷积得到,即总共经历30*30次卷积。
2.3 S2层
S2 层是降采样层,使用 6 个 2×2 大小的卷积核进行池化,padding=0,stride=2,得到 6 个 15×15 大小的特征图:30/2=15。
参数个数
(1+1)x6=12,其中第一个 1 为池化对应的 2*2 感受野中最大的那个数的权重 w,第二个 1 为偏置 b。
连接数
(2x2+1)x6x15x15= 6750,虽然只选取 2x2 感受野之和,但也存在 2x2 的连接数,1 为偏置项的连接,15x15 为输出特征层,每一个像素都由前面卷积得到,即总共经历 15x15 次卷积。
2.4 C3层
LeNet中的C3只是结构图中所示的卷积,没有对不同特征图的处理,这里不再赘述
LeNet5对不同的特征图采取不同的卷积操作,下面主要介绍LeNet5
C3 层是卷积层,使用 16 个 5×5 大小的卷积核,padding=0,stride=1 进行卷积,得到 16 个 11×11 大小的特征图:15-5+1=11。
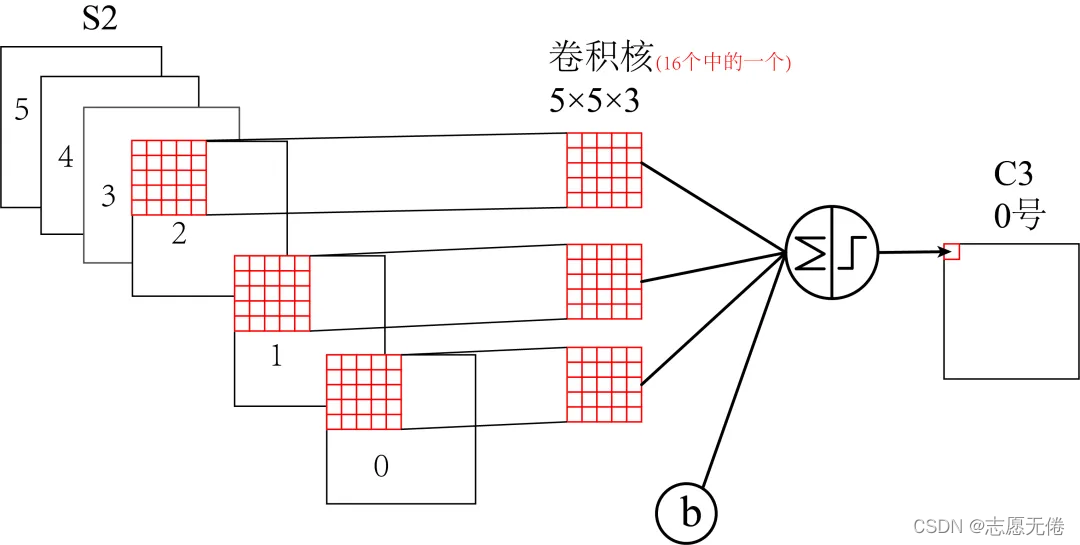
16 个卷积核并不是都与 S2 的 6 个通道层进行卷积操作
如下图所示,C3 的前六个特征图(0,1,2,3,4,5)由 S2的相邻三个特征图作为输入,对应的卷积核尺寸为:5x5x3;
接下来的 6 个特征图(6,7,8,9,10,11)由 S2的相邻四个特征图作为输入对应的卷积核尺寸为:5x5x4;
接下来的 3 个特征图(12,13,14)号特征图由 S2间断的四个特征图作为输入对应的卷积核尺寸为:5x5x4;
最后的 15 号特征图由 S2 全部(6个)特征图作为输入,对应的卷积核尺寸为:5x5x6。

值得注意的是,卷积核是 5×5 且具有 3 个通道,每个通道各不相同,这也是下面计算时 5*5 后面还要乘以3,4,6的原因。这是多通道卷积的计算方法。
2.5 S4 层
S4 层与 S2 一样也是降采样层,使用 16 个 2×2 大小的卷积核进行池化,padding=0,stride=2,得到 16 个 5×5 大小的特征图:11/2=5。
2.6 F5 层
C5 层是卷积层,使用 120 个 5×5x16 大小的卷积核,padding=0,stride=1进行卷积,得到 120 个 1×1 大小的特征图:5-5+1=1。即相当于 120 个神经元的全连接层。
值得注意的是,与C3层不同,这里120个卷积核都与S4的16个通道层进行卷积操作。
参数个数
(5516+1)*120=48120。
连接数
4812011=48120。
2.7 F6层
F6 是全连接层,共有 84 个神经元,与 C5 层进行全连接,即每个神经元都与 C5 层的 120 个特征图相连。计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过 sigmoid 函数输出。
2.8 Output层
最后的 Output 层也是全连接层,是 Gaussian Connections,采用了 RBF 函数(即径向欧式距离函数),计算输入向量和参数向量之间的欧式距离(目前已经被Softmax 取代)。
Output 层共有 10 个节点,分别代表数字 0 到 9。假设x是上一层的输入,y 是 RBF的输出,则 RBF 输出的计算方式是:
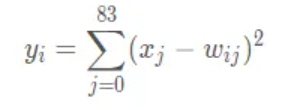
上式中 i 取值从 0 到 9,j 取值从 0 到 7*12-1,w 为参数。RBF 输出的值越接近于 0,则越接近于 i,即越接近于 i 的 ASCII 编码图,表示当前网络输入的识别结果是字符 i。
3 LeNet5源码
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# 卷积层使用 torch.nn.Conv2d
# 激活层使用 torch.nn.ReLU
# 池化层使用 torch.nn.MaxPool2d
# 全连接层使用 torch.nn.Linear
class LeNet(nn.Module):
def __init__(self,num_classes=10):
super(LeNet, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=6,kernel_size=3,stride=1,padding= 2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2))
# 第一组卷积核
self.conv2_1_1=nn.Sequential(nn.Conv2d(in_channels=3,out_channels=1,kernel_size=5)
,nn.ReLU())
self.conv2_1_2=nn.Sequential(nn.Conv2d(in_channels=4,out_channels=1,kernel_size=5)
,nn.ReLU())
self.conv2_1_3=nn.Sequential(nn.Conv2d(in_channels=4,out_channels=1,kernel_size=5)
,nn.ReLU())
self.conv2_1_4=nn.Sequential(nn.Conv2d(in_channels=6,out_channels=1,kernel_size=5))
self.conv3=nn.Sequential(nn.ReLU(),
nn.MaxPool2d(kernel_size=2))
self.fc1 = nn.Sequential(nn.Linear(16 * 5 * 5, 120),
#数据归一化处理
nn.BatchNorm1d(120),
nn.ReLU())
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.BatchNorm1d(84),
nn.ReLU(),
nn.Linear(84, num_classes))
# 最后的结果一定要变为 10,因为数字的选项是 0 ~ 9
def forward(self, x):
# print(x.shape)
x = self.conv1(x)
# print(x.shape)
x_0,x_1,x_2,x_3,x_4,x_5=x.split(1,dim=1)
# print(x_0.shape)
out_1_0=self.conv2_1_1(torch.cat((x_0,x_1,x_2),1))
out_1_1=self.conv2_1_1(torch.cat((x_1,x_2,x_3),1))
out_1_2 = self.conv2_1_1(torch.cat((x_2, x_3, x_4), 1))
out_1_3 = self.conv2_1_1(torch.cat((x_3, x_4, x_5), 1))
out_1_4 = self.conv2_1_1(torch.cat((x_4, x_5, x_0), 1))
out_1_5 = self.conv2_1_1(torch.cat((x_5, x_0, x_1), 1))
out_1=torch.cat((out_1_0,out_1_1,out_1_2,out_1_3,out_1_4,out_1_5),1)
# print("第一组操作结束时维度:",out_1.shape)
out_2_0=self.conv2_1_2(torch.cat((x_0,x_1,x_2,x_3),1))
out_2_1 = self.conv2_1_2(torch.cat((x_1, x_2, x_3, x_4), 1))
out_2_2 = self.conv2_1_2(torch.cat((x_2, x_3, x_4, x_5), 1))
out_2_3 = self.conv2_1_2(torch.cat((x_3, x_4, x_5, x_0), 1))
out_2_4 = self.conv2_1_2(torch.cat((x_4, x_5, x_0, x_1), 1))
out_2_5 = self.conv2_1_2(torch.cat((x_5, x_0, x_1, x_2), 1))
out_2=torch.cat((out_2_0,out_2_1,out_2_2,out_2_3,out_2_4,out_2_5),1)
# print("第二组操作结束时维度:", out_2.shape)
out_3_0=self.conv2_1_3(torch.cat((x_0,x_1,x_3,x_4),1))
out_3_1 = self.conv2_1_3(torch.cat((x_1, x_2, x_4, x_5), 1))
out_3_2 = self.conv2_1_3(torch.cat((x_2, x_3, x_5, x_0), 1))
out_3=torch.cat((out_3_0,out_3_1,out_3_2),1)
# print("第三组操作结束时维度:", out_3.shape)
out_4=self.conv2_1_4(x)
# print("第四组操作结束时维度:", out_4.shape)
x=torch.cat((out_1,out_2,out_3,out_4),1)
# print(x.shape)
x=self.conv3(x)
# print(x.shape)
x = x.view(x.size()[0], -1)
# print(x.shape)
x = self.fc1(x)
# print(x.shape)
x = self.fc2(x)
# print(x.shape)
return x
4 训练代码
import time
import os
from tqdm import tqdm
import logging
from models import LeNet
from torchvision import datasets, transforms
from tensorboardX import SummaryWriter
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
import warnings
# 忽略Warning
warnings.filterwarnings('ignore')
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
Batch_size=8
Save_path="saved/"
Save_model="LeNet"
Summary_path=r'.\runs\LeNet5'
Num_classes=10
if not os.path.exists(Summary_path):
os.mkdir(Summary_path)
writer = SummaryWriter(log_dir=Summary_path, purge_step=0)
def train():
# train配置
device = torch.device('cuda:0')
model = LeNet(num_classes=Num_classes)
# model = nn.DataParallel(model, device_ids=[0, 1])
model.to(device)
logger = initLogger("Mnist_LeNet")
# loss
criterion = nn.CrossEntropyLoss()
# train data
train_dataset = datasets.MNIST(root='.\mnist',
train=True,
transform=transforms.ToTensor(),# 数据类型预处理,变成张量并归一化(/255)
download=True)
# 下载测试集
val_dataset = datasets.MNIST(root='.\mnist',
train=False,
transform=transforms.ToTensor(),
download=True)
# 装载训练集
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=Batch_size,
shuffle=True)
# 装载验证集
val_loader = torch.utils.data.DataLoader(dataset=val_dataset,
batch_size=Batch_size,
shuffle=True)
# optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001, weight_decay=0.0001)
#最优val准确率,根据这个保存模型
val_max_OA = 0.0
for epoch in range(100):
# lr
model.train()
loss_sum = 0.0
correct_sum = 0.0
total=0
# train_loader为可迭代对象,ncols为自定义的进度条长度
tbar = tqdm(train_loader, ncols=120)
for batch_idx, (data, target) in enumerate(tbar):
data=data.cuda()
target=target.cuda()
# data, target = data.to(device), target.to(device)
optimizer.zero_grad()# 清除梯度
output = model(data)
loss = criterion(output, target)
loss_sum += loss.item()
loss.backward()# 反向传播,计算张量的梯度
optimizer.step()# 根据梯度更新网络参数
# torch.max(x,dim=?) dim=0时返回每一列中最大值的那个元素的值和索引,dim=1时返回每一行中最大值的那个元素值和索引
# 值无用,需要的是索引,也即0-9的标签,不用转化正好时标签
# out输出10个类各自的概率,所以需要从每一条数据中取出最大的
_,predicted=torch.max(output,1)
correct_sum += (predicted == target).sum()
total += Batch_size
oa=correct_sum.item()/total*1.0
# 轮次、损失总值、正确率
tbar.set_description('TRAIN ({}) | Loss: {:.5f} | OA {:.5f} |'.format(
epoch, loss_sum/((batch_idx+1)*Batch_size),oa))
# 使用TensorBoard记录各指标曲线
writer.add_scalar('train_loss', loss_sum / ((batch_idx + 1) * Batch_size), epoch)
writer.add_scalar('train_oa', oa, epoch)
# 每一轮次结束后记录运行日志
logger.info('TRAIN ({}) | Loss: {:.5f} | OA {:.5f}'.format(
epoch, loss_sum/((batch_idx+1)*Batch_size),oa))
# val
model.eval()
loss_sum = 0.0
correct_sum = 0.0
total=0
tbar = tqdm(val_loader, ncols=120)
class_precision=np.zeros(Num_classes)
class_recall=np.zeros(Num_classes)
class_f1=np.zeros(Num_classes)
# val_list=[]
# data, target = data.to(device), target.to(device)
with torch.no_grad():
#混淆矩阵
conf_matrix_val = np.zeros((Num_classes,Num_classes))
for batch_idx, (data, target) in enumerate(tbar):
data=data.cuda()
target=target.cuda()
output = model(data)
loss = criterion(output, target)
loss_sum += loss.item()
_,predicted=torch.max(output,1)
correct_sum += (predicted == target).sum()
total += Batch_size
oa=correct_sum.item()/total*1.0
c_predict=predicted.cpu().numpy()
c_target=target.cpu().numpy()
# 预测值为行标签、真值为列标签,类似两标签下的混淆矩阵
'''
预测值
真值 正 负
正 TP FN
负 FN TN
'''
for i in range(len(c_predict)):
conf_matrix_val[c_target[i],c_predict[i]] += 1
for i in range(Num_classes):
#每一类的precision
class_precision[i]=1.0*conf_matrix_val[i,i]/conf_matrix_val[:,i].sum()
#每一类的recall
class_recall[i]=1.0*conf_matrix_val[i,i]/conf_matrix_val[i].sum()
#每一类的f1
class_f1[i]=(2.0*class_precision[i]*class_recall[i])/(class_precision[i]+class_recall[i])
tbar.set_description('VAL ({}) | Loss: {:.5f} | OA {:.5f} '.format(
epoch, loss_sum / ((batch_idx + 1) * Batch_size),
oa))
# 保存最优oa对应的模型
if oa > val_max_OA:
val_max_OA = oa
best_epoch =np.zeros(2)
best_epoch[0]=epoch
best_epoch[1]=conf_matrix_val.sum()
if os.path.exists(Save_path) is False:
os.mkdir(Save_path)
torch.save(model.state_dict(), os.path.join(Save_path, Save_model+'.pth'))
np.savetxt(os.path.join(Save_path, Save_model+'_conf_matrix_val.txt'),conf_matrix_val,fmt="%d")
np.savetxt(os.path.join(Save_path, Save_model+'_best_epoch.txt'),best_epoch,fmt="%d")
writer.add_scalar('val_loss', loss_sum / ((batch_idx + 1) * Batch_size), epoch)
writer.add_scalar('val_oa', oa, epoch)
writer.add_scalar('Avarage_percision', class_precision.sum()/10, epoch)
writer.add_scalar('Avarge_recall', class_recall.sum()/10, epoch)
writer.add_scalar('Avarage_F1', class_f1.sum()/10, epoch)
logger.info('VAL ({}) | Loss: {:.5f} | OA {:.5f} |class_precision {}| class_recall {} | class_f1 {}|'.format(
epoch, loss_sum / ((batch_idx + 1) * Batch_size),
oa,toString(class_precision),toString(class_recall),toString(class_f1)))
def toString(IOU):
result = '{'
for i, num in enumerate(IOU):
result += str(i) + ': ' + '{:.4f}, '.format(num)
result += '}'
return result
def initLogger(model_name):
# 初始化log
logger = logging.getLogger()
logger.setLevel(logging.INFO)
rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time()))
log_path = r'logs'
if not os.path.exists(log_path):
os.mkdir(log_path)
log_name = os.path.join(log_path, model_name + '_' + rq + '.log')
logfile = log_name
fh = logging.FileHandler(logfile, mode='w')
fh.setLevel(logging.INFO)
formatter = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s")
fh.setFormatter(formatter)
logger.addHandler(fh)
return logger
if __name__ == '__main__':
train()