LeNet5
LeNet-5卷积神经网络模型
LeNet-5:是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。
LenNet-5共有7层(不包括输入层),每层都包含不同数量的训练参数,如下图所示。
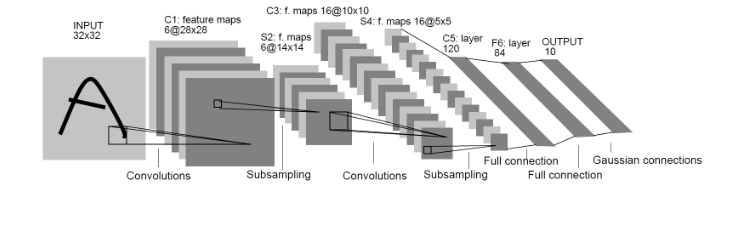
LeNet-5中主要有2个卷积层、2个下抽样层(池化层)、3个全连接层3种连接方式
使用LeNet5识别MNIST
初试版本:
import torch
import torchvision
import torch.nn as nn
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
# 先定义一个绘图工具
def plot_curve(data):
fig = plt.figure()
plt.plot(range(len(data)),data,color = 'blue')
plt.legend(['value'],loc = 'upper right')
plt.xlabel('step')
plt.ylabel('value')
plt.show()
device=torch.device('cuda' if torch.cuda.is_available() else "cpu")
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(1,6,5,1,2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2)
)
self.conv2=nn.Sequential(
nn.Conv2d(6,16,5),
nn.ReLU(),
nn.MaxPool2d(2,2)
)
self.fc1=nn.Sequential(
nn.Linear(16*5*5,120),
nn.ReLU()
)
self.fc2=nn.Sequential(
nn.Linear(120,84),
nn.ReLU()
)
self.fc3=nn.Linear(84,10)
# self.model=nn.Sequential(
# nn.Conv2d(1,6,5,1,2),
# nn.ReLU(),
# nn.MaxPool2d(2,2),
# nn.Conv2d(6,16,5),
# nn.ReLU(),
# nn.MaxPool2d(2,2),
# nn.Flatten(),
# nn.Linear(16*5*5,120),
# nn.ReLU(),
# nn.Linear(120,84),
# nn.ReLU(),
# nn.Linear(84,10)
# )
def forward(self, x):
x=self.conv1(x)
x=self.conv2(x)
# nn.Linear()的输入输出都是维度为1的值,所以要把多维度的tensor展平或一维
x=x.view(x.size()[0], -1)
x=self.fc1(x)
x=self.fc2(x)
x=self.fc3(x)
# x=self.model(x)
return x
epoch=8
batch_size=64
lr=0.001
traindata=torchvision.datasets.MNIST(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),download=True)
testdata=torchvision.datasets.MNIST(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True)
trainloader=DataLoader(traindata,batch_size=batch_size,shuffle=True)
testloader=DataLoader(testdata,batch_size=batch_size,shuffle=False)
net=LeNet().to(device)
loss_fn=nn.CrossEntropyLoss().to(device)
optimizer=torch.optim.SGD(net.parameters(),lr=lr,momentum=0.9)
train_loss=[]
accuracy=[]
train_step=0
for epoch in range(epoch):
sum_loss=0
for data in trainloader:
inputs,labels=data
inputs,labels=inputs.to(device),labels.to(device)
optimizer.zero_grad()
outputs=net(inputs)
loss=loss_fn(outputs,labels)
loss.backward()
optimizer.step()
train_step+=1
sum_loss+=loss.item()
if train_step % 100==99:
print("[epoch:{},轮次:{},sum_loss:{}".format(epoch+1,train_step,sum_loss/100))
train_loss.append(sum_loss/100)
sum_loss=0
with torch.no_grad():
correct=0
total=0
for data in testloader:
images, labels=data
images,labels=images.to(device),labels.to(device)
outputs=net(images)
_,predicted=torch.max(outputs.data,1)
total+=labels.size(0)
correct+=(predicted==labels).sum()
accuracy.append(correct)
print("第{}个epoch的识别准确率为:{}".format(epoch+1,correct/total))
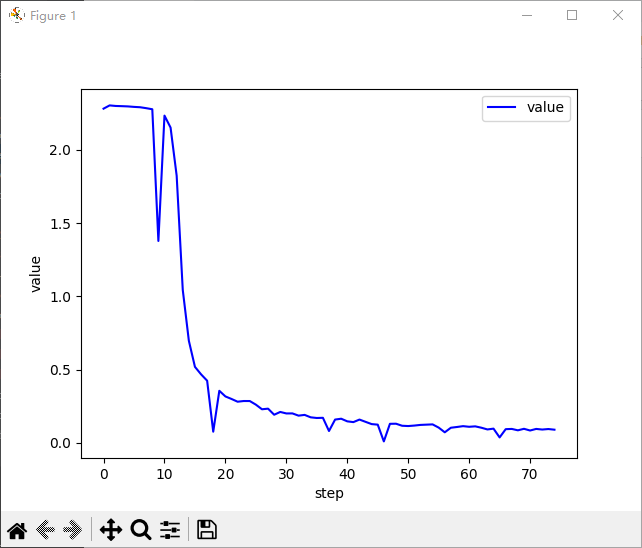
plot_curve(train_loss)
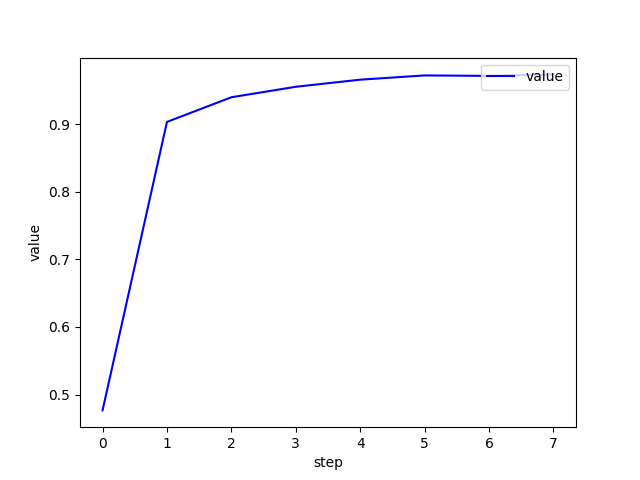
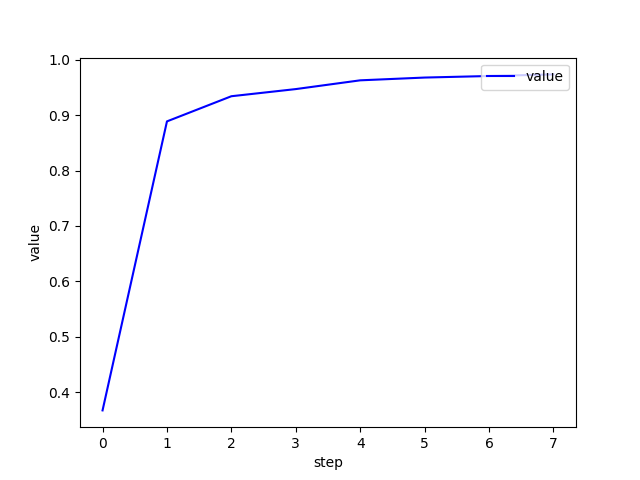
plot_curve(accuracy)
运行结果:识别准确率还是不错的
每一步的训练损失值变化:
每轮测试集的识别准确率:
代码优化一下:
import torch
import torchvision
import torch.nn as nn
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
# 先定义一个绘图工具
def plot_curve(data):
fig = plt.figure()
plt.plot(range(len(data)),data,color = 'blue')
plt.legend(['value'],loc = 'upper right')
plt.xlabel('step')
plt.ylabel('value')
plt.show()
device=torch.device('cuda' if torch.cuda.is_available() else "cpu")
# 定义LeNet网络
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.model=nn.Sequential(
# MNIST数据集大小为28x28,要先做padding=2的填充才满足32x32的输入大小
nn.Conv2d(1,6,5,1,2),
nn.ReLU(),
nn.MaxPool2d(2,2),
nn.Conv2d(6,16,5),
nn.ReLU(),
nn.MaxPool2d(2,2),
nn.Flatten(),
nn.Linear(16*5*5,120),
nn.ReLU(),
nn.Linear(120,84),
nn.ReLU(),
nn.Linear(84,10)
)
def forward(self, x):
x=self.model(x)
return x
epoch=8
batch_size=64
lr=0.001
# 导入数据集
traindata=torchvision.datasets.MNIST(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),download=True)
testdata=torchvision.datasets.MNIST(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True)
test_size=len(testdata)
# 加载数据集
trainloader=DataLoader(traindata,batch_size=batch_size,shuffle=True)
testloader=DataLoader(testdata,batch_size=batch_size,shuffle=False)
net=LeNet().to(device)
loss_fn=nn.CrossEntropyLoss().to(device)
optimizer=torch.optim.SGD(net.parameters(),lr=lr,momentum=0.9)
train_loss=[]
precision=[]
train_step=0
for epoch in range(epoch):
net.train()
sum_loss=0
for data in trainloader:
inputs,labels=data
inputs,labels=inputs.to(device),labels.to(device)
# 更新梯度
optimizer.zero_grad()
outputs=net(inputs)
loss=loss_fn(outputs,labels)
loss.backward()
optimizer.step()
train_step+=1
sum_loss+=loss.item()
if train_step % 100==99:
print("[epoch:{},轮次:{},sum_loss:{}]".format(epoch+1,train_step,sum_loss/100))
train_loss.append(sum_loss/100)
sum_loss=0
net.eval()
with torch.no_grad():
correct=0
# total=0
accuracy=0
for data in testloader:
images, labels=data
images,labels=images.to(device),labels.to(device)
outputs=net(images)
# _,predicted=torch.max(outputs.data,1)
# total+=labels.size(0)
# correct+=(predicted==labels).sum()
correct+=(outputs.argmax(1)==labels).sum()
accuracy=correct/test_size
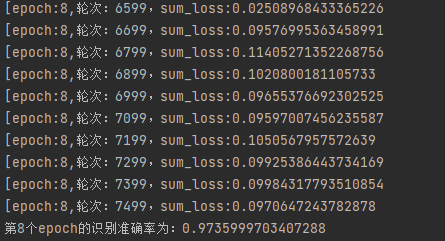
print("第{}个epoch的识别准确率为:{}".format(epoch+1,accuracy))
precision.append(accuracy.cpu())
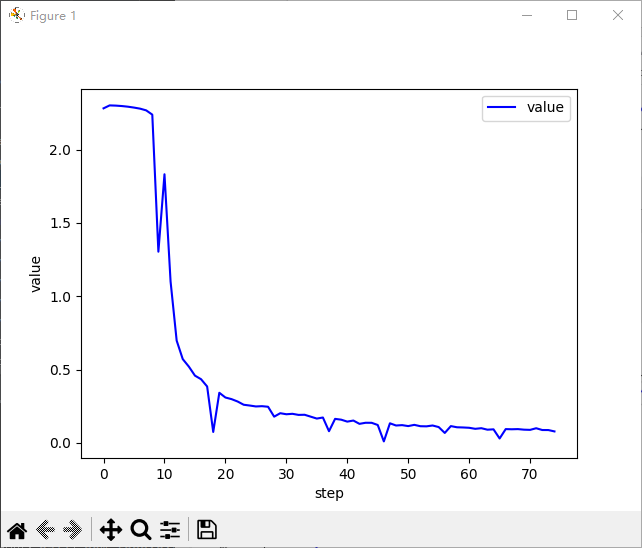
plot_curve(train_loss)
plot_curve(precision)
运行结果:
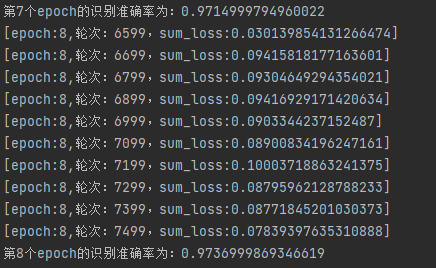
每一步的训练loss变化
测试集每一轮的准确率