tensorflow部分基础以及lenet5CNN实现图片分类模型简要介绍
lenet5项目地址
关于tensorflow的基础
此处不介绍tensorflow的来源和各种历史,直接说明tensorflow的运行流程。
前向传播
设想你是一名道路设计者,前向传播好比你修建一条运输线路,(在tensorflow里叫作图),至于这条路上跑什么车,跑多少车,你都是不知道的,(这里车就是数据),在前向传播中没有数据的计算,此时你能做到的只是确定让道路正确,没有让人迷惑的死路口或者岔路口
前向传播类似与自己写了一个数学公式,举个前向传播的栗子, 假如你想从一堆数据中找到y = kx + b的关系,你手头上有数据x和对应的y,那么你想确定k和b的近似值之前,要在tensorflow(以下简称tf)中搭建一个这样的数学公式,其中x和y是你想往里面放数据的接口(喂入数据),k和b是待求的变量,那么你可以这样搭建
import tensorflow as tf
X = tf.placeholder(tf.float32) #输入参数x的接口, placeholder表示使用占位符,tf.float表示数据类型, 32为浮点型
Y = tf.placeholder(tf.float32) #输入参数y的接口, 使用占位符
k = tf.Variable(tf.ones([1])) #斜率k,Variable表示使用变量,这个变量在模型在是要被训练的,tf.ones表示使用1组成的张量,[1]表示维度是1维,只有一个元。k暂时使用数据1,当然可以用别的,反正都是要训练改变的
b = tf.Variable(tf.ones([1])) #截距b, 使用变量
yout = tf.multiply(X ,k) #tf.multiply表示两数相乘 相乘的还有tf.matmul,表示二维张量相乘,这个步骤就是搭建了y = kx + b的模型,yout表示真实训练中出来的值
损失函数
损失函数是在训练过程中,得到的输出值与理想输出值的差距,这里有很多中衡量的标准,还以上边的栗子进行解释,我们可以用均方误差的方法,也就是输出值和理想值的方差来表示
loss = tf.reduce_mean(tf.square(yout - Y))
优化器
优化器以损失函数为优化依据,进行参数调节,具体原理不解释,方法有多种,此处用梯度下降法
learning_rate = 0.001
optimizer= tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
其中learning_rate表示学习率,其实就相当于显微镜上的焦螺旋,越小参数变得越慢
执行训练
执行训练的过程就是让已有的输入和输出数据一次又一次的填入模型中,根据数据进行训练。什么时候进行呢?那就是需要搭建一个平台,让它们在这个平台上运行,这个平台叫作会话,tf.Session()。就好比你修好了路,当然不作为摆设,你要在某个时间段内开始通车。
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(1000):
sess.run(optimizer, feed_dict = {X : x, Y : y})
其中x,y是准备好的训练集。
代码总结
这里准备了一段简单的代码供参考
# -*- coding: utf-8 -*-
"""
@author wwe
简单的训练模型,并储存模型
"""
import tensorflow as tf
import numpy as np
x = np.linspace(-1, 1, 100)
y = 2 * x + np.random.randn(100) * 0.3
x = np.reshape(x, [100, 1])
y = np.reshape(y, [100,1])
print(x.shape,y.shape)
X = tf.placeholder(tf.float32, [None, 1])
Y = tf.placeholder(tf.float32, [None, 1])
global_step = tf.Variable(0, trainable = False)
w = tf.Variable(tf.constant(1.0))
b = tf.Variable(tf.constant(1.0))
yout = tf.multiply(X ,w) + b
loss = tf.reduce_mean(tf.square(Y -yout))
optimizer = tf.train.GradientDescentOptimizer(0.01).minimize(loss, global_step = global_step)
saver = tf.train.Saver(max_to_keep = 1)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(1000):
start = 10 * i % 100
end = start + 10
sess.run(optimizer, feed_dict = {X : x[start: end], Y : y[start: end]})
if i % 100 == 0:
print("loss", sess.run(loss, feed_dict = {X: x, Y : y}))
saver.save(sess,"log\model", global_step = global_step)
# -*- coding: utf-8 -*-
"""
@author wwe
使用模型
"""
import tensorflow as tf
tf.reset_default_graph()
X = tf.placeholder(tf.float32, [None, 1])
Y = tf.placeholder(tf.float32, [None, 1])
w = tf.Variable(tf.constant(1.0))
b = tf.Variable(tf.constant(1.0))
yout = tf.multiply(X ,w) + b
saver = tf.train.Saver(max_to_keep = 1)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver.restore(sess, "log\model-901")
print("y=", sess.run(yout, feed_dict = {X: [[1]]}))
卷积神经网络
卷积
在图片中,我们直接处理需要的参数很多,举个栗子,在全连接网络中2828的灰度图使用500个隐藏层节点和十个分类输出节点需要近4万个数据,我们常将原始图片的相邻像素组成的块变成新的小块,卷积提供了一个非常好的方案,借用网络上一张图片

从左到右依次为图片、卷积核、输出层,可将55的图片选取特征后变成3*3的图片
池化
池化和卷积类似,只不过是选取图片某个范围内的像素的特定数据特征,此处再借用网络上的图片
 这里左边是平均池化,右边是最大池化,平均池化突出背景特征,最大池化突出轮廓特征,分别是取正方形内的均值和最大值作为新的像素点。
这里左边是平均池化,右边是最大池化,平均池化突出背景特征,最大池化突出轮廓特征,分别是取正方形内的均值和最大值作为新的像素点。
lenet5的构成
lenet5的构成如下图

模型介绍
我搭建的模型使用了5*5的卷积核,全部全零填充,最大池化进行训练
模型结果
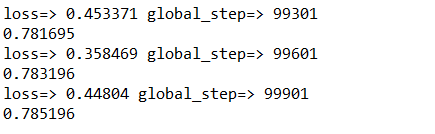
取自于cifar的数据集,图片是32*32的分辨率,3通道RGB图片,由于算力问题,我只选择了前四类进行四分类训练。训练一共进行了十万次,再前三万次左右准确率在40%作用,五万次大约70%,最终准确率在78,在最终测试的四个图片中,也准确通过,代码传至github,有条件的可以更改参数进行十分类训练,识别十种图片

总结
lenet5能较好的解决图片分类,是一个经典的CNN模型,个人觉得值得新手开始学习。
我也是刚刚入门这一方向,第一篇博客,很有纪念意义,希望我能在这条路上顺利的向前!同时也希望我能给那位爱我的人一个美好的未来~