论文链接:
https://openreview.net/forum?id=H1cWzoxA-
论文目的:
Learn a context-aware representation foreach token from the input sequence.
简单说明:
可以理解成一个token信息编码问题。解决这一问题常用的有三种基本结构为CNN、RNN、SAN (self-attenstion networks)。文中指出了CNN、RNN在该问题上的一些固有问题(如其他论文一样)及SAN对于两两token进行信息相似性编码导致性能较低的问题,并思考在SAN
的基础上进行改进的方案。
该种方法(称BloSA)较SAN有两方面不同。一方面是升维,即将token的embedding看成一个向量后,attension的加权使用方式是针对向量的每一个维度进行的,得到的也是一个向量,而非标量(这种设定符合编码表示的需求);另一方面是降维,即将SAN中的整个句子两两token编码变为,先将句子划分成若干子句,后对每一个子句执行attension加权操作,再将每个子句的编码矩阵降维成一个local context 编码向量(每一个相当于代表了子句的local语义),再对这些若干local语义进行 attension,这时对应之前local context的编码后向量就涵盖了当前子句与其他子句的语义关系,再进行”broadcast” 及与输入语义信息的若干融合(fusion)后,就得到了编码后向量。(一些细节参见原论文)


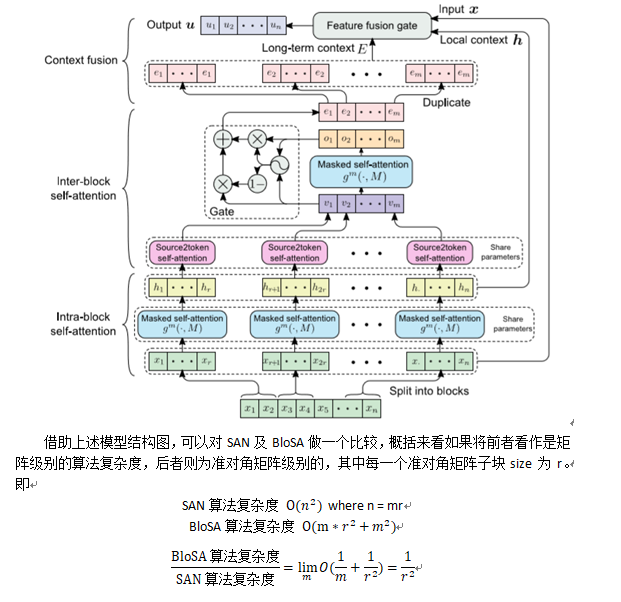
这里略去了Mask及双向的设定。(在实现上)
由于该模型编码特性,其可以作为多种模型的前项特征提取层用于替换RNN、CNN,下面分别对
DeepLearning for Extreme Multi-label Text Classification 实现 及
BI-DIRECTIONALATTENSION FLOW FOR MACHINE COMPREHENSION 论文阅读及实现
中的极度多标签分类及QA数据集进行特征提取替换实践。(相应数据集说明及预处理参见上两篇博文)
多标签分类实践:(替换模型图中红圈部分)
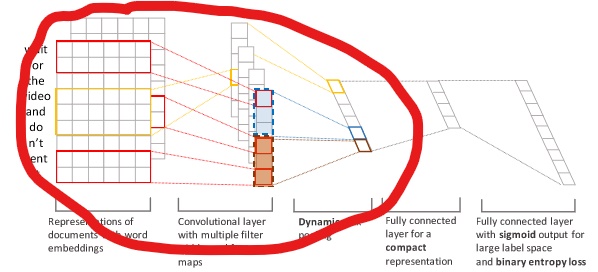
BloSA中的子句分块也执行了类似Dynamicmax pooling的操作。
数据导出:
import tensorflow as tf
import numpy as np
import pickle
with open("embed_and_idx.pkl", "rb") as f:
d = pickle.load(f)
word2idx = d["word2idx"]
tag2idx = d["tag2idx"]
embed_array = d["embed_array"]
padding_idx_s = str(word2idx["<pad>"])
def data_generator(gen_type = "train" ,batch_num = 32 * 2 * 2, padding_size = 500, tag_num = 1000,
category_limit = False):
assert gen_type in ["train", "test"]
def generate_int_array(input_str):
input_list = input_str.split(" ")[:padding_size]
return np.array(input_list + [padding_idx_s] * (padding_size - len(input_list))).astype(np.int32)
def generate_tag_array(input_str):
input_list = list(map(int, input_str.split(" ")))
req = [0] * tag_num
for tag in input_list:
req[tag] = 1
return np.array(req).astype(np.float32)
start_idx = 0
q_batch_array = np.zeros(shape=[batch_num, padding_size]).astype(np.int32)
a_batch_array = np.zeros(shape=[batch_num, padding_size]).astype(np.int32)
t_batch_array = np.zeros(shape=[batch_num, padding_size]).astype(np.int32)
tag_batch_array = np.zeros(shape=[batch_num, tag_num]).astype(np.float32)
times = 0
with open("classifier_{}.txt".format(gen_type)) as f:
while True:
line = f.readline()
if not line:
return
fs, s, t, ff = line[:-1].split("\t")
tag_array = generate_tag_array(ff)
if category_limit:
if np.sum(tag_array) > 1 or np.argmax(tag_array) not in [0, 1]:
continue
else:
sum_tag_array = np.sum(tag_array).astype(np.float32)
tag_array = tag_array / sum_tag_array
q_batch_array[start_idx] = generate_int_array(fs)
a_batch_array[start_idx] = generate_int_array(s)
t_batch_array[start_idx] = generate_int_array(t)
tag_batch_array[start_idx] = tag_array
start_idx += 1
if start_idx == batch_num:
times += 1
if times == 1e10:
return
yield (q_batch_array, a_batch_array, t_batch_array, tag_batch_array)
start_idx = 0
q_batch_array = np.zeros(shape=[batch_num, padding_size]).astype(np.int32)
a_batch_array = np.zeros(shape=[batch_num, padding_size]).astype(np.int32)
t_batch_array = np.zeros(shape=[batch_num, padding_size]).astype(np.int32)
tag_batch_array = np.zeros(shape=[batch_num, tag_num]).astype(np.float32)
模型构建:
class BDBSA(object):
def __init__(self, word_size = len(word2idx), word_embed_size = 10, seq_len = 500, r = 50, padding_idx = int(padding_idx_s),
batch_size = 32 * 2 * 2, c = 10, n_class = 1000, dnn_layer_dim = 100):
assert padding_idx in range(word_size)
self.word_size = word_size
self.word_embed_size = word_embed_size
self.seq_len = seq_len
self.r = r
self.batch_size = batch_size
self.c = c
self.n_class = n_class
self.dnn_layer_dim = dnn_layer_dim
with tf.device("/cpu:0"), tf.name_scope("word_embedding"):
self.word_W = tf.Variable(
tf.random_uniform([self.word_size, self.word_embed_size], -1.0, 1.0),
name="word_W"
)
self.q_seq = tf.placeholder(dtype=tf.int32, shape=[None, self.seq_len], name="q_deq")
self.a_seq = tf.placeholder(dtype=tf.int32, shape=[None, self.seq_len], name="a_seq")
self.t_seq = tf.placeholder(dtype=tf.int32, shape=[None, self.seq_len], name="t_seq")
self.keep_prob = tf.placeholder(dtype=tf.float32, name="keep_prob")
self.input_text = tf.concat([self.q_seq, self.a_seq, self.t_seq], axis = -1, name="input_seq")
self.sum_seq_len = int(self.input_text.get_shape()[-1])
self.input_tag = tf.placeholder(tf.float32, [self.batch_size, self.n_class])
a, b = divmod(self.sum_seq_len, self.r)
if b:
p = self.r - b
input = tf.concat([self.input_text, tf.convert_to_tensor(np.full(shape=[self.batch_size, p], fill_value=padding_idx),
)], axis=-1)
else:
input = self.input_text
self.m, rr = divmod(int(input.get_shape()[-1]), self.r)
assert rr == 0
self.batch_embed_seq = tf.nn.embedding_lookup(self.word_W, input, name="embed_seq")
self.batch_u = self.model_construct(self.batch_embed_seq)
self.opt_construct(self.batch_u)
def opt_construct(self, batch_u):
with tf.name_scope("low_rank"):
W = tf.get_variable(
"low_W",
shape=[self.r * self.m * self.word_embed_size, self.dnn_layer_dim],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[self.dnn_layer_dim]), name="low_b")
self.dnn_layer_out = tf.nn.xw_plus_b(tf.reshape(batch_u, [-1, self.r * self.m * self.word_embed_size]), W, b)
with tf.name_scope("dropout"):
self.dropout_layer_out = tf.nn.dropout(self.dnn_layer_out, keep_prob=self.keep_prob, name="drop_keep_prob_layer")
with tf.name_scope("final_layer"):
W = tf.get_variable(
"final_W",
shape=[int(self.dropout_layer_out.get_shape()[-1]), self.n_class],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[self.n_class]), name="final_b")
self.final_layer = tf.nn.xw_plus_b(self.dropout_layer_out, W, b)
self.softmax_pred = tf.nn.softmax(self.final_layer, dim = -1)
self.predictions = tf.argmax(self.softmax_pred, 1, name="predictions")
self.loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=self.input_tag, logits=self.final_layer))
self.opt = tf.train.AdamOptimizer(0.001)
self.train_op = self.opt.minimize(self.loss)
with tf.name_scope("accuracy"):
self.tag_eval = tf.cast(self.input_tag > 0, tf.float32)
self.tag_row_sum = tf.reduce_sum(self.tag_eval, axis=1)
self.pred_onehot = tf.one_hot(self.predictions, depth=self.n_class)
greedy_correct_predictions = tf.reduce_prod(tf.cast(tf.subtract(self.tag_eval, self.pred_onehot) >= 0, tf.float32), axis=1)
self.greedy_accuracy = tf.reduce_mean(tf.cast(greedy_correct_predictions, "float"), name="accuracy")
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_tag, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
def model_construct(self, embed_seq):
index_list = list(range(0, self.sum_seq_len, self.r))
if self.sum_seq_len not in index_list:
index_list.append(self.sum_seq_len)
x_slice_list = []
for i in range(len(index_list) - 1):
start = index_list[i]
slice_val = tf.slice(embed_seq, [0 ,start, 0], [-1 ,self.r ,-1], name="slice_{}".format(i))
x_slice_list.append(slice_val)
block_vs_list = []
h_slice_list = []
for block_idx ,block in enumerate(x_slice_list):
with tf.variable_scope("mask_self_attension", reuse=tf.AUTO_REUSE):
req_block = tf.transpose(block, [0, 2, 1])
x_slice_list[block_idx] = req_block
hs = self.mask_self_attension_layer(req_block, n = self.r)
h_slice_list.append(hs)
with tf.variable_scope("source2token", reuse=tf.AUTO_REUSE):
vs = self.source2token_self_attension_layer(hs, n = self.r)
block_vs_list.append(tf.expand_dims(vs, -1))
print("block {} end".format(block_idx))
m = len(block_vs_list)
v = tf.concat(block_vs_list, axis=-1, name="v")
with tf.variable_scope("second_mask_self_attension"):
o = self.mask_self_attension_layer(v, n = m)
de = self.word_embed_size
Wg1 = tf.get_variable(
"Wg1",
shape=[de, de],
initializer=tf.contrib.layers.xavier_initializer())
Wg2 = tf.get_variable(
"Wg2",
shape=[de, de],
initializer=tf.contrib.layers.xavier_initializer())
bg = tf.get_variable( shape=[de], name="bg", initializer=tf.contrib.layers.xavier_initializer())
o = tf.reshape(tf.transpose(o, [0, 2, 1]), [-1, de])
v = tf.reshape(tf.transpose(v, [0, 2, 1]), [-1, de])
G = tf.nn.sigmoid(
tf.nn.bias_add(
tf.matmul(o, Wg1) +
tf.matmul(v, Wg2)
, bg), name="G")
e = tf.add(tf.multiply(G, o), tf.multiply(1 - G, v), name="e")
# batch_num, m, de
e = tf.reshape(e, [-1, m, de])
e_list = tf.unstack(e, axis=-2)
E_list = []
for e_ele in e_list:
E_list.extend([tf.expand_dims(e_ele, -1)] * self.r)
# batch_num, de, sum_seq_len
E = tf.concat(E_list, axis = -1, name="E")
x = tf.concat(x_slice_list, axis=-1, name="x")
h = tf.concat(h_slice_list, axis=-1, name="h")
# [batch_num ,3de, n]
xhE = tf.concat([x, h, E], axis = 1, name="xhE")
n = self.r * self.m
Wf1 = tf.get_variable(
"Wf1",
shape=[3 * de, de],
initializer=tf.contrib.layers.xavier_initializer())
Wf2 = tf.get_variable(
"Wf2",
shape=[3 *de, de],
initializer=tf.contrib.layers.xavier_initializer())
bf1 = tf.get_variable(shape=[de], name="bf1", initializer=tf.contrib.layers.xavier_initializer())
bf2 = tf.get_variable(shape=[de], name="bf2", initializer=tf.contrib.layers.xavier_initializer())
xhE = tf.reshape(tf.transpose(xhE, [0, 2, 1]), [-1, 3 * de])
x = tf.reshape(tf.transpose(x, [0, 2, 1]), [-1 ,de])
F = tf.nn.relu(tf.nn.bias_add(tf.matmul(xhE, Wf1), bf1), name="F")
G = tf.nn.sigmoid(tf.nn.bias_add(tf.matmul(xhE, Wf2), bf2), name="G")
u = tf.add(G * F, (1-G) * x, name="u")
# batch_num, de, n
u = tf.transpose(tf.reshape(u, [-1, n, de]), [0, 2, 1])
return u
# input [batch_num, de, sql_len or n] output [batch_num, de, sql_len or n]
def mask_self_attension_layer(self, input, n):
de = self.word_embed_size
W1 = tf.get_variable(
"W1",
shape=[de, de],
initializer=tf.contrib.layers.xavier_initializer())
W2 = tf.get_variable(
"W2",
shape=[de, de],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable(shape=[de], name="b1", initializer=tf.contrib.layers.xavier_initializer())
X = tf.reshape(tf.transpose(input, [0, 2, 1]) , [-1, de], name="X")
XW1 = tf.reshape(tf.transpose(tf.reshape(tf.nn.bias_add(tf.matmul(X, W1, name="XW1"), b1), [-1, n ,de]), [0, 2, 1]), [-1, n])
XW2 = tf.reshape(tf.transpose(tf.reshape(tf.matmul(X, W2, name="XW2"), [-1, n, de]), [0, 2, 1]), [-1, n])
fW1 = tf.tile(XW1, [n, 1])
fW2 = tf.tile(tf.expand_dims(tf.concat(tf.unstack(XW2, axis=-1), axis=0), -1), [1, n])
# [n * dn, n] dn = batch_num * sum_seq_len
f = self.c * tf.nn.tanh(tf.div(fW1 + fW2, self.c))
X = tf.reshape(tf.transpose(tf.reshape(X, [-1, n, de]), [0, 2, 1]), [-1, n])
X = tf.tile(tf.expand_dims(tf.concat(tf.unstack(X, axis=-1), axis=0), -1), [1, n])
f = tf.nn.softmax(f, dim=-1)
# [dn, n]
s = tf.transpose(tf.reshape(tf.reduce_mean(f * X, axis=-1), [n, -1]), [1, 0])
s = tf.reshape(s, [-1, de, n])
return s
# input [batch_num, de, sql_len or n] output [batch_num, de]
def source2token_self_attension_layer(self, input, n):
de = self.word_embed_size
W3 = tf.get_variable(
"W3",
shape=[de, de],
initializer=tf.contrib.layers.xavier_initializer())
W4 = tf.get_variable(
"W4",
shape=[de, de],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.get_variable(shape=[de], name="b2", initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.get_variable(shape=[de], name="b3", initializer=tf.contrib.layers.xavier_initializer())
def f(x):
return tf.nn.bias_add(tf.matmul(tf.nn.relu(tf.nn.bias_add(tf.matmul(x, W3), b2)), W4), b3)
X = tf.reshape(tf.transpose(input, [0, 2, 1]), [-1 ,de])
fX = tf.reshape(f(X), [-1, n, de])
P = tf.nn.softmax(fX, dim=1)
X = tf.reshape(X, [-1, n, de])
return tf.squeeze(tf.reduce_sum(P * X, axis=-2))
@staticmethod
def train():
bdbsa_ext = BDBSA()
tg = data_generator(gen_type="train")
ttg = data_generator(gen_type="test")
num_epoch = 100
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for now_epoch in range(num_epoch):
step = 0
while True:
try:
q_batch_array, a_batch_array, t_batch_array, tag_batch_array = tg.__next__()
except:
tg = data_generator(gen_type="train")
ttg = data_generator(gen_type="test")
print("epoch {} end".format(now_epoch))
break
_, loss, accuracy, greedy_accuracy = sess.run([bdbsa_ext.train_op ,bdbsa_ext.loss, bdbsa_ext.accuracy, bdbsa_ext.greedy_accuracy
],
feed_dict={
bdbsa_ext.q_seq: np.zeros(q_batch_array.shape).astype(np.float32),
bdbsa_ext.a_seq: np.zeros(q_batch_array.shape).astype(np.float32),
bdbsa_ext.t_seq: t_batch_array,
bdbsa_ext.input_tag: tag_batch_array,
bdbsa_ext.keep_prob: 0.7
})
if step % 10 == 0:
print("step: {}, train loss: {} acc: {} gred_acc: {}".format(step ,loss, accuracy, greedy_accuracy))
if step % 100 == 0:
try:
q_batch_array, a_batch_array, t_batch_array, tag_batch_array = ttg.__next__()
except:
ttg = data_generator(gen_type="test")
q_batch_array, a_batch_array, t_batch_array, tag_batch_array = ttg.__next__()
loss, accuracy, greedy_accuracy = sess.run([bdbsa_ext.loss, bdbsa_ext.accuracy, bdbsa_ext.greedy_accuracy],
feed_dict={
bdbsa_ext.q_seq: np.zeros(q_batch_array.shape).astype(np.float32),
bdbsa_ext.a_seq: np.zeros(q_batch_array.shape).astype(np.float32),
bdbsa_ext.t_seq: t_batch_array,
bdbsa_ext.input_tag: tag_batch_array,
bdbsa_ext.keep_prob: 1.0
})
print("test loss: {} acc: {} gred_acc: {}".format(loss, accuracy, greedy_accuracy))
step += 1
从实测结果而言,其与之前使用的CNN在精度及速度上是类似的。
QA数据集实现(替换模型图中红圈部分)
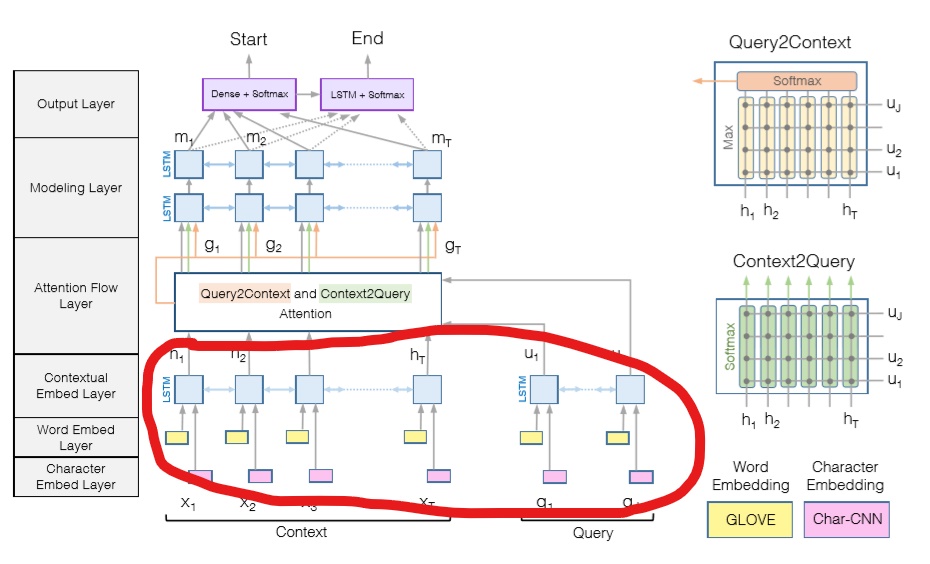
数据导出:
import tensorflow as tf
from tensorflow.contrib import rnn
import numpy as np
import pickle
with open("idx.pkl", "rb") as f:
d = pickle.load(f)
word2idx = d["word2idx"]
char2idx = d["char2idx"]
padding_idx_s = str(word2idx["<pad>"])
padding_char_idx = len(char2idx)
def data_generator(gen_type = "n" ,batch_num = 64,
T = 100, J = 10, word_length = 10):
assert gen_type in ["n", "t"]
def split_word(word_join_str, word_padding):
input_list = list(map(int, word_join_str.split(" ")))[:word_padding]
return np.array(input_list + [padding_idx_s] * (word_padding - len(input_list))).astype(np.int32)
def split_char(char_join_str, char_padding, word_padding):
def char_nest_process(char_inner_str):
input_list = char_inner_str.split("_")[:char_padding]
return input_list + [padding_char_idx] * (char_padding - len(input_list))
input_split = char_join_str.split(" ")[:word_padding]
req = np.array(list(map(char_nest_process ,input_split))).astype(np.int32)
trail = np.full(shape=[word_padding - len(input_split), char_padding], fill_value=padding_char_idx)
req = np.append(req, trail, axis=0).astype(np.int32)
return req
start_idx = 0
c_word_batch = np.zeros(shape=[batch_num, T]).astype(np.int32)
c_char_batch = np.zeros(shape=[batch_num, T, word_length]).astype(np.int32)
q_word_batch = np.zeros(shape=[batch_num, J]).astype(np.int32)
q_char_batch = np.zeros(shape=[batch_num, J, word_length]).astype(np.int32)
p1_fake_batch = np.zeros(shape=[batch_num, T]).astype(np.int32)
p2_fake_batch = np.zeros(shape=[batch_num, T]).astype(np.int32)
times = 0
with open("cqt{}.txt".format(gen_type)) as f:
while True:
line = f.readline()
if not line:
return
qtw, qtc, ttw, ttc, tw = line[:-1].split("\t")
tw = split_word(tw, 1)
qtw = split_word(qtw, T)
if tw[0] not in qtw:
continue
else:
p1idx = qtw.tolist().index(tw[0])
if p1idx == (T - 1):
continue
qtc = split_char(qtc, word_length, T)
ttw = split_word(ttw, J)
ttc = split_char(ttc, word_length, J)
p1, p2 = [0] * T, [0] * T
p1[p1idx] = 1
p2[p1idx + 1] = 1
p1 = np.array(p1).astype(np.int32)
p2 = np.array(p2).astype(np.int32)
c_word_batch[start_idx] = qtw
c_char_batch[start_idx] = qtc
q_word_batch[start_idx] = ttw
q_char_batch[start_idx] = ttc
p1_fake_batch[start_idx] = p1
p2_fake_batch[start_idx] = p2
start_idx += 1
if start_idx == batch_num:
times += 1
if times == 1e10:
return
yield (c_word_batch,
c_char_batch,
q_word_batch,
q_char_batch,
p1_fake_batch,
p2_fake_batch)
start_idx = 0
c_word_batch = np.zeros(shape=[batch_num, T]).astype(np.int32)
c_char_batch = np.zeros(shape=[batch_num, T, word_length]).astype(np.int32)
q_word_batch = np.zeros(shape=[batch_num, J]).astype(np.int32)
q_char_batch = np.zeros(shape=[batch_num, J, word_length]).astype(np.int32)
p1_fake_batch = np.zeros(shape=[batch_num, T]).astype(np.int32)
p2_fake_batch = np.zeros(shape=[batch_num, T]).astype(np.int32)
模型构建:
class BIDAF_BDBSA(object):
def __init__(self,
word_size = len(word2idx), word_embed_size = 40, T = 100, J = 10, batch_num = 64):
self.word_size = word_size
self.word_embed_size = word_embed_size
self.loss = None
self.p1_accuracy = None
self.p2_accuracy = None
self.accuracy = None
self.batch_num = batch_num
self.T = T
self.J = J
self.c_word = tf.placeholder(dtype=tf.int32, shape=[None, T], name="c_word")
self.q_word = tf.placeholder(dtype=tf.int32, shape=[None, J], name="q_word")
self.p1_seq = tf.placeholder(dtype=tf.int32, shape=[None, T], name="p1_seq")
self.p2_seq = tf.placeholder(dtype=tf.int32, shape=[None, T], name="p2_seq")
self.model_construct()
self.opt_construct()
def model_construct(self):
with tf.variable_scope("BDBSA") as scope:
self.H = BDBSA(self.c_word, word_embed_size=self.word_embed_size, seq_len = self.T, r = 30, batch_size=self.batch_num).batch_u
self.H = tf.transpose(tf.concat([self.H] * 2, axis = 1), [0, 2, 1])
scope.reuse_variables()
self.U = BDBSA(self.q_word, word_embed_size=self.word_embed_size, seq_len = self.J, r = 3, batch_size=self.batch_num).batch_u
self.U = tf.transpose(tf.concat([self.U] * 2, axis = 1), [0, 2, 1])
self.T = int(self.H.get_shape()[-2])
self.J = int(self.U.get_shape()[-2])
# Similarity layer
# [batch_num, T, J]
self.S = self.similarity_layer(self.H, self.U)
# Context_to_query attension
self.A = tf.nn.softmax(self.S, dim=-1, name="A")
d = int(self.U.get_shape()[-1]) / 2
self.U_bar_list = []
for i in range(self.batch_num):
A = tf.squeeze(tf.slice(self.A, [i, 0, 0], [1, -1, -1]))
U = tf.squeeze(tf.slice(self.U, [i, 0, 0], [1, -1, -1]))
self.U_bar_list.append(tf.expand_dims(tf.matmul(A, U), 0))
self.U_bar = tf.concat(self.U_bar_list, axis=0)
# Query_to_context attension
self.b = tf.nn.softmax(tf.reduce_max(self.S, axis=-1), dim=-1, name="b")
self.h_bar_list = []
for i in range(self.batch_num):
b = tf.slice(self.b, [i, 0], [1, -1])
H = tf.squeeze(tf.slice(self.H, [i, 0, 0], [1, -1, -1]))
self.h_bar_list.append(tf.matmul(b, H))
self.h_bar = tf.concat(self.h_bar_list, axis=1)
self.H_bar = tf.reshape(tf.tile(self.h_bar, [1 ,self.T]), [-1 ,self.T, int(2 * d)])
# G layer
self.G = self.G_layer(self.H, self.H_bar, self.U_bar)
# second lstm layer
self.M = self.second_bilstm_layer(self.G)
# third lstm layer
self.M2 = self.third_bilstm_layer(self.M)
# p1 layer
GM = tf.concat([self.G, self.M], axis = -1)
Pw1 = tf.get_variable(
"Pw1",
shape=[10 * d, 1],
initializer=tf.contrib.layers.xavier_initializer())
self.p1 = tf.reshape(tf.matmul(tf.reshape(GM, [-1, int(10 * d)]), Pw1), [-1, self.T], name="p1")
# p2 layer
GM2 = tf.concat([self.G, self.M2], axis = -1)
Pw2 = tf.get_variable(
"Pw2",
shape=[10 * d, 1],
initializer=tf.contrib.layers.xavier_initializer())
self.p2 = tf.reshape(tf.matmul(tf.reshape(GM2, [-1, int(10 * d)]), Pw2), [-1, self.T], name="p2")
def opt_construct(self, use_single_p = True):
self.softmax_p1 = tf.nn.softmax(self.p1)
self.softmax_p2 = tf.nn.softmax(self.p2)
self.p1_labels = tf.cast(self.p1_seq, tf.float32)
self.p2_labels = tf.cast(self.p2_seq, tf.float32)
self.p1_labels = tf.concat([self.p1_labels, tf.fill([self.batch_num, self.T - int(self.p1_labels.get_shape()[1])],
0.0)], axis = 1)
self.p2_labels = tf.concat([self.p2_labels, tf.fill([self.batch_num, self.T - int(self.p2_labels.get_shape()[1])],
0.0)], axis = 1)
p1_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.p1, labels=self.p1_labels), name="p1_loss")
p2_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=self.p2, labels=self.p2_labels), name="p2_loss")
if use_single_p:
self.loss = p1_loss
else:
self.loss = p1_loss + p2_loss
self.opt = tf.train.AdamOptimizer(learning_rate=0.001)
self.train_op = self.opt.minimize(self.loss)
self.pred_p1 = tf.argmax(self.softmax_p1, 1, name="pred_p1")
self.pred_p2 = tf.argmax(self.softmax_p2, 1, name="pred_p2")
# Accuracy
with tf.name_scope("accuracy"):
correct_pred_p1 = tf.equal(self.pred_p1, tf.argmax(self.p1_labels, 1))
correct_pred_p2 = tf.equal(self.pred_p2, tf.argmax(self.p2_labels, 1))
correct_pred = tf.multiply(tf.cast(correct_pred_p1, tf.float32), tf.cast(correct_pred_p2, tf.float32))
if use_single_p:
self.p1_accuracy = self.p2_accuracy = self.accuracy = tf.reduce_mean(tf.cast(correct_pred_p1, "float"), name="p1_accuracy")
else:
self.p1_accuracy = tf.reduce_mean(tf.cast(correct_pred_p1, "float"), name="p1_accuracy")
self.p2_accuracy = tf.reduce_mean(tf.cast(correct_pred_p2, "float"), name="p2_accuracy")
self.accuracy = tf.reduce_mean(correct_pred, name="accuracy")
def similarity_layer(self, H, U):
d = int(H.get_shape()[-1]) / 2
h_dim = int(H.get_shape()[-2])
u_dim = int(U.get_shape()[-2])
print("similarity layer h_dim: {}, u_dim: {}".format(h_dim, u_dim))
Sw = tf.get_variable(
"Sw",
shape=[6 * d, 1],
initializer=tf.contrib.layers.xavier_initializer())
H = tf.reshape(tf.transpose(H, [0, 2, 1]), [-1 ,h_dim])
U = tf.reshape(tf.transpose(U, [0, 2, 1]), [-1 ,u_dim])
fH = tf.tile(H, [u_dim, 1])
fU = tf.tile(tf.expand_dims(tf.concat(tf.unstack(U, axis=-1), axis=0), -1), [1, h_dim])
fHU = fH * fU
fH = tf.reshape(fH, [-1 ,u_dim , int(2 * d) ,h_dim])
fU = tf.reshape(fU, [-1, u_dim, int(2 * d), h_dim])
fHU = tf.reshape(fHU, [-1, u_dim, int(2 * d), h_dim])
f = tf.concat([fH, fU, fHU], axis=2)
f = tf.reshape(tf.transpose(f, [0, 1, 3, 2]), [-1, int(6 * d)])
# [batch_num, T, J]
return tf.transpose(tf.reshape(tf.squeeze(tf.matmul(f, Sw)), [-1, u_dim, h_dim]), [0, 2, 1])
def G_layer(self, H, H_bar, U_bar):
d = int(H.get_shape()[-1]) / 2
def g(h, h_bar, u_bar):
return tf.concat([h, u_bar, h * u_bar, h * h_bar], axis=-1)
h_list = tf.unstack(H, axis=1, name="h_list")
h_bar_list = tf.unstack(H_bar, axis=1, name="h_bar_list")
u_bar_list = tf.unstack(U_bar, axis=1, name="u_bar_list")
g_list = []
for idx in range(len(h_list)):
h = h_list[idx]
h_bar = h_bar_list[idx]
u_bar = u_bar_list[idx]
g_ele = g(h, h_bar, u_bar)
g_list.append(g_ele)
return tf.transpose(tf.reshape(tf.concat(g_list, axis = -1), [-1, int(8 * d), self.T]), [0, 2, 1], name="G")
def second_bilstm_layer(self, input):
input_shape = input.get_shape()
d = int(int(input_shape[-1]) / 8)
with tf.name_scope("second_lstm_layer"):
fw_cell = rnn.BasicLSTMCell(d, forget_bias=1., state_is_tuple=True)
bw_cell = rnn.BasicLSTMCell(d, forget_bias=1., state_is_tuple=True)
rnn_outputs, _ = tf.nn.bidirectional_dynamic_rnn(
fw_cell, bw_cell, input, scope='second-bi-lstm',
dtype=tf.float32)
return tf.concat(rnn_outputs, axis=2, name='second_bilstm_output')
def third_bilstm_layer(self, input):
input_shape = input.get_shape()
d = int(int(input_shape[-1]) / 2)
with tf.name_scope("third_lstm_layer"):
fw_cell = rnn.BasicLSTMCell(d, forget_bias=1., state_is_tuple=True)
bw_cell = rnn.BasicLSTMCell(d, forget_bias=1., state_is_tuple=True)
rnn_outputs, _ = tf.nn.bidirectional_dynamic_rnn(
fw_cell, bw_cell, input, scope='third-bi-lstm',
dtype=tf.float32)
return tf.concat(rnn_outputs, axis=2, name='third_bilstm_output')
@staticmethod
def train():
from time import time
bidaf_ext = BIDAF_BDBSA()
print("model construct end :")
tg = data_generator(gen_type="n")
ttg = data_generator(gen_type="t")
num_epoch = 100
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for now_epoch in range(num_epoch):
step = 0
while True:
try:
c_word,c_char,q_word,q_char,p1_fake,p2_fake = tg.__next__()
except:
tg = data_generator(gen_type="n")
ttg = data_generator(gen_type="t")
print("epoch {} end".format(now_epoch))
break
_ , \
loss, \
p1_accuracy, \
p2_accuracy, \
accuracy, \
= sess.run([
bidaf_ext.train_op,
bidaf_ext.loss,
bidaf_ext.p1_accuracy,
bidaf_ext.p2_accuracy,
bidaf_ext.accuracy,
],
feed_dict={
bidaf_ext.c_word: c_word,
bidaf_ext.q_word: q_word,
bidaf_ext.p1_seq: p1_fake,
bidaf_ext.p2_seq: p2_fake
})
if step % 10 == 0:
print("train loss :{} p1_accuracy :{} p2_accuracy :{} accuracy :{}".
format(loss, p1_accuracy, p2_accuracy, accuracy))
if step % 100 == 0:
try:
c_word,c_char,q_word,q_char,p1_fake,p2_fake = ttg.__next__()
except:
ttg = data_generator(gen_type="t")
c_word,c_char,q_word,q_char,p1_fake,p2_fake = ttg.__next__()
loss, \
p1_accuracy, \
p2_accuracy, \
accuracy = sess.run([
bidaf_ext.loss,
bidaf_ext.p1_accuracy,
bidaf_ext.p2_accuracy,
bidaf_ext.accuracy,
],
feed_dict={
bidaf_ext.c_word: c_word,
bidaf_ext.q_word: q_word,
bidaf_ext.p1_seq: p1_fake,
bidaf_ext.p2_seq: p2_fake
})
print("test loss :{} p1_accuracy :{} p2_accuracy :{} accuracy :{}".
format(loss, p1_accuracy, p2_accuracy, accuracy))
step += 1
class BDBSA(object):
def __init__(self, input_text, word_size = len(word2idx), word_embed_size = 10, seq_len = 500, r = 50, padding_idx = int(padding_idx_s),
batch_size = 32 * 2 * 2, c = 10):
assert padding_idx in range(word_size)
self.word_size = word_size
self.word_embed_size = word_embed_size
self.seq_len = seq_len
self.r = r
self.batch_size = batch_size
self.c = c
with tf.device("/cpu:0"), tf.name_scope("word_embedding"):
self.word_W = tf.get_variable(
"word_W",
shape=[self.word_size, self.word_embed_size],
initializer=tf.random_normal_initializer())
self.input_text = input_text
self.sum_seq_len = int(self.input_text.get_shape()[-1])
a, b = divmod(self.sum_seq_len, self.r)
if b:
p = self.r - b
input = tf.concat([self.input_text, tf.convert_to_tensor(np.full(shape=[self.batch_size, p], fill_value=padding_idx),
)], axis=-1)
else:
input = self.input_text
self.m, rr = divmod(int(input.get_shape()[-1]), self.r)
assert rr == 0
self.batch_embed_seq = tf.nn.embedding_lookup(self.word_W, input, name="embed_seq")
self.batch_u = self.model_construct(self.batch_embed_seq)
def model_construct(self, embed_seq):
index_list = list(range(0, self.sum_seq_len, self.r))
if self.sum_seq_len not in index_list:
index_list.append(self.sum_seq_len)
x_slice_list = []
for i in range(len(index_list) - 1):
start = index_list[i]
slice_val = tf.slice(embed_seq, [0 ,start, 0], [-1 ,self.r ,-1], name="slice_{}".format(i))
x_slice_list.append(slice_val)
block_vs_list = []
h_slice_list = []
for block_idx ,block in enumerate(x_slice_list):
with tf.variable_scope("mask_self_attension", reuse=tf.AUTO_REUSE):
req_block = tf.transpose(block, [0, 2, 1])
x_slice_list[block_idx] = req_block
hs = self.mask_self_attension_layer(req_block, n = self.r)
h_slice_list.append(hs)
with tf.variable_scope("source2token", reuse=tf.AUTO_REUSE):
vs = self.source2token_self_attension_layer(hs, n = self.r)
block_vs_list.append(tf.expand_dims(vs, -1))
print("block {} end".format(block_idx))
m = len(block_vs_list)
v = tf.concat(block_vs_list, axis=-1, name="v")
with tf.variable_scope("second_mask_self_attension"):
o = self.mask_self_attension_layer(v, n = m)
de = self.word_embed_size
Wg1 = tf.get_variable(
"Wg1",
shape=[de, de],
initializer=tf.contrib.layers.xavier_initializer())
Wg2 = tf.get_variable(
"Wg2",
shape=[de, de],
initializer=tf.contrib.layers.xavier_initializer())
bg = tf.get_variable( shape=[de], name="bg", initializer=tf.contrib.layers.xavier_initializer())
o = tf.reshape(tf.transpose(o, [0, 2, 1]), [-1, de])
v = tf.reshape(tf.transpose(v, [0, 2, 1]), [-1, de])
G = tf.nn.sigmoid(
tf.nn.bias_add(
tf.matmul(o, Wg1) +
tf.matmul(v, Wg2)
, bg), name="G")
e = tf.add(tf.multiply(G, o), tf.multiply(1 - G, v), name="e")
# batch_num, m, de
e = tf.reshape(e, [-1, m, de])
e_list = tf.unstack(e, axis=-2)
E_list = []
for e_ele in e_list:
E_list.extend([tf.expand_dims(e_ele, -1)] * self.r)
# batch_num, de, sum_seq_len
E = tf.concat(E_list, axis = -1, name="E")
x = tf.concat(x_slice_list, axis=-1, name="x")
h = tf.concat(h_slice_list, axis=-1, name="h")
# [batch_num ,3de, n]
xhE = tf.concat([x, h, E], axis = 1, name="xhE")
n = self.r * self.m
Wf1 = tf.get_variable(
"Wf1",
shape=[3 * de, de],
initializer=tf.contrib.layers.xavier_initializer())
Wf2 = tf.get_variable(
"Wf2",
shape=[3 *de, de],
initializer=tf.contrib.layers.xavier_initializer())
bf1 = tf.get_variable(shape=[de], name="bf1", initializer=tf.contrib.layers.xavier_initializer())
bf2 = tf.get_variable(shape=[de], name="bf2", initializer=tf.contrib.layers.xavier_initializer())
xhE = tf.reshape(tf.transpose(xhE, [0, 2, 1]), [-1, 3 * de])
x = tf.reshape(tf.transpose(x, [0, 2, 1]), [-1 ,de])
F = tf.nn.relu(tf.nn.bias_add(tf.matmul(xhE, Wf1), bf1), name="F")
G = tf.nn.sigmoid(tf.nn.bias_add(tf.matmul(xhE, Wf2), bf2), name="G")
u = tf.add(G * F, (1-G) * x, name="u")
# batch_num, de, n
u = tf.transpose(tf.reshape(u, [-1, n, de]), [0, 2, 1])
return u
# input [batch_num, de, sql_len or n] output [batch_num, de, sql_len or n]
def mask_self_attension_layer(self, input, n):
de = self.word_embed_size
W1 = tf.get_variable(
"W1",
shape=[de, de],
initializer=tf.contrib.layers.xavier_initializer())
W2 = tf.get_variable(
"W2",
shape=[de, de],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable(shape=[de], name="b1", initializer=tf.contrib.layers.xavier_initializer())
X = tf.reshape(tf.transpose(input, [0, 2, 1]) , [-1, de], name="X")
XW1 = tf.reshape(tf.transpose(tf.reshape(tf.nn.bias_add(tf.matmul(X, W1, name="XW1"), b1), [-1, n ,de]), [0, 2, 1]), [-1, n])
XW2 = tf.reshape(tf.transpose(tf.reshape(tf.matmul(X, W2, name="XW2"), [-1, n, de]), [0, 2, 1]), [-1, n])
fW1 = tf.tile(XW1, [n, 1])
fW2 = tf.tile(tf.expand_dims(tf.concat(tf.unstack(XW2, axis=-1), axis=0), -1), [1, n])
# [n * dn, n] dn = batch_num * sum_seq_len
f = self.c * tf.nn.tanh(tf.div(fW1 + fW2, self.c))
X = tf.reshape(tf.transpose(tf.reshape(X, [-1, n, de]), [0, 2, 1]), [-1, n])
X = tf.tile(tf.expand_dims(tf.concat(tf.unstack(X, axis=-1), axis=0), -1), [1, n])
f = tf.nn.softmax(f, dim=-1)
# [dn, n]
s = tf.transpose(tf.reshape(tf.reduce_mean(f * X, axis=-1), [n, -1]), [1, 0])
s = tf.reshape(s, [-1, de, n])
return s
# input [batch_num, de, sql_len or n] output [batch_num, de]
def source2token_self_attension_layer(self, input, n):
de = self.word_embed_size
W3 = tf.get_variable(
"W3",
shape=[de, de],
initializer=tf.contrib.layers.xavier_initializer())
W4 = tf.get_variable(
"W4",
shape=[de, de],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.get_variable(shape=[de], name="b2", initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.get_variable(shape=[de], name="b3", initializer=tf.contrib.layers.xavier_initializer())
def f(x):
return tf.nn.bias_add(tf.matmul(tf.nn.relu(tf.nn.bias_add(tf.matmul(x, W3), b2)), W4), b3)
X = tf.reshape(tf.transpose(input, [0, 2, 1]), [-1 ,de])
fX = tf.reshape(f(X), [-1, n, de])
P = tf.nn.softmax(fX, dim=1)
X = tf.reshape(X, [-1, n, de])
return tf.squeeze(tf.reduce_sum(P * X, axis=-2))
下面是测试集结果
test loss :0.6178147792816162 p1_accuracy :0.046875 test loss :0.046289555728435516 p1_accuracy :0.03125 test loss :0.043495941907167435 p1_accuracy :0.03125 test loss :0.043140389025211334 p1_accuracy :0.015625 test loss :0.04165690019726753 p1_accuracy :0.03125 test loss :0.04186602309346199 p1_accuracy :0.03125 test loss :0.04119220748543739 p1_accuracy :0.046875 epoch 0 end test loss :0.041014477610588074 p1_accuracy :0.046875 test loss :0.04127436503767967 p1_accuracy :0.046875 test loss :0.0412147119641304 p1_accuracy :0.046875 test loss :0.04267799109220505 p1_accuracy :0.046875 test loss :0.041090741753578186 p1_accuracy :0.078125 test loss :0.04108071327209473 p1_accuracy :0.046875 test loss :0.040521636605262756 p1_accuracy :0.078125 epoch 1 end test loss :0.04049374908208847 p1_accuracy :0.03125 test loss :0.04059961810708046 p1_accuracy :0.0625 test loss :0.04079672321677208 p1_accuracy :0.078125 test loss :0.04176585003733635 p1_accuracy :0.078125 test loss :0.04057670384645462 p1_accuracy :0.078125 test loss :0.03989981859922409 p1_accuracy :0.046875 test loss :0.0403367355465889 p1_accuracy :0.09375 epoch 2 end test loss :0.038122303783893585 p1_accuracy :0.125 test loss :0.03731720522046089 p1_accuracy :0.1875 test loss :0.03682134672999382 p1_accuracy :0.234375 test loss :0.03816920146346092 p1_accuracy :0.1875 test loss :0.034603431820869446 p1_accuracy :0.28125 test loss :0.03636084869503975 p1_accuracy :0.1875 test loss :0.03510065749287605 p1_accuracy :0.28125 epoch 3 end test loss :0.032242584973573685 p1_accuracy :0.3125 test loss :0.0318729430437088 p1_accuracy :0.328125 test loss :0.02979586459696293 p1_accuracy :0.375 test loss :0.030598562210798264 p1_accuracy :0.390625 test loss :0.026887277141213417 p1_accuracy :0.453125 test loss :0.030242258682847023 p1_accuracy :0.359375 test loss :0.02877185121178627 p1_accuracy :0.328125 epoch 4 end test loss :0.027105819433927536 p1_accuracy :0.4375 test loss :0.026495646685361862 p1_accuracy :0.421875 test loss :0.024277541786432266 p1_accuracy :0.53125 test loss :0.02482936531305313 p1_accuracy :0.453125 test loss :0.02124423161149025 p1_accuracy :0.59375 test loss :0.029167575761675835 p1_accuracy :0.453125 test loss :0.02458975277841091 p1_accuracy :0.453125 epoch 5 end test loss :0.025133104994893074 p1_accuracy :0.421875 test loss :0.02221926487982273 p1_accuracy :0.5625 test loss :0.021992143243551254 p1_accuracy :0.53125 test loss :0.022338127717375755 p1_accuracy :0.53125 test loss :0.018497373908758163 p1_accuracy :0.671875 test loss :0.028519216924905777 p1_accuracy :0.421875 test loss :0.023302048444747925 p1_accuracy :0.484375 epoch 6 end test loss :0.023546703159809113 p1_accuracy :0.484375 test loss :0.02009332925081253 p1_accuracy :0.609375 test loss :0.020808974280953407 p1_accuracy :0.578125 test loss :0.019952313974499702 p1_accuracy :0.578125 test loss :0.016939708963036537 p1_accuracy :0.703125 test loss :0.02772807888686657 p1_accuracy :0.453125 test loss :0.02281566709280014 p1_accuracy :0.484375 epoch 7 end test loss :0.022472070530056953 p1_accuracy :0.484375 test loss :0.018261931836605072 p1_accuracy :0.65625 test loss :0.019927937537431717 p1_accuracy :0.609375 test loss :0.01850111037492752 p1_accuracy :0.625 test loss :0.016126228496432304 p1_accuracy :0.6875 test loss :0.02656981348991394 p1_accuracy :0.515625 test loss :0.021761855110526085 p1_accuracy :0.5 epoch 8 end test loss :0.021878166124224663 p1_accuracy :0.515625 test loss :0.016794854775071144 p1_accuracy :0.703125 test loss :0.019649583846330643 p1_accuracy :0.609375 test loss :0.01743313856422901 p1_accuracy :0.609375 test loss :0.016686227172613144 p1_accuracy :0.65625 test loss :0.026073984801769257 p1_accuracy :0.53125 test loss :0.021257400512695312 p1_accuracy :0.546875 epoch 9 end test loss :0.020663630217313766 p1_accuracy :0.546875 test loss :0.015778791159391403 p1_accuracy :0.75 test loss :0.019048839807510376 p1_accuracy :0.609375 test loss :0.017042135819792747 p1_accuracy :0.640625 test loss :0.01689469814300537 p1_accuracy :0.65625 test loss :0.026288442313671112 p1_accuracy :0.515625 test loss :0.01991748809814453 p1_accuracy :0.578125 epoch 10 end test loss :0.020227832719683647 p1_accuracy :0.53125 test loss :0.015386402606964111 p1_accuracy :0.71875 test loss :0.0190621055662632 p1_accuracy :0.625 test loss :0.01730707474052906 p1_accuracy :0.671875 test loss :0.016485048457980156 p1_accuracy :0.703125 test loss :0.025981631129980087 p1_accuracy :0.53125 test loss :0.019282249733805656 p1_accuracy :0.59375
中的结果,在同一个epoch的收敛精度更高,收敛速度更快。(这里的word embedding维度还比上一种实现少)