BiDAF(Bi-Directional Attention Flow)机器阅读理解模型
内容
- SQuAD数据介绍
- 详细讲解Bi-Directional Attention Flow (BiDAF)。
- 作业讲解,各种版本的代码
数据介绍:
SQuAD
斯坦福大学自然语言计算组发布SQuAD数据集,诸多团队参与其中.
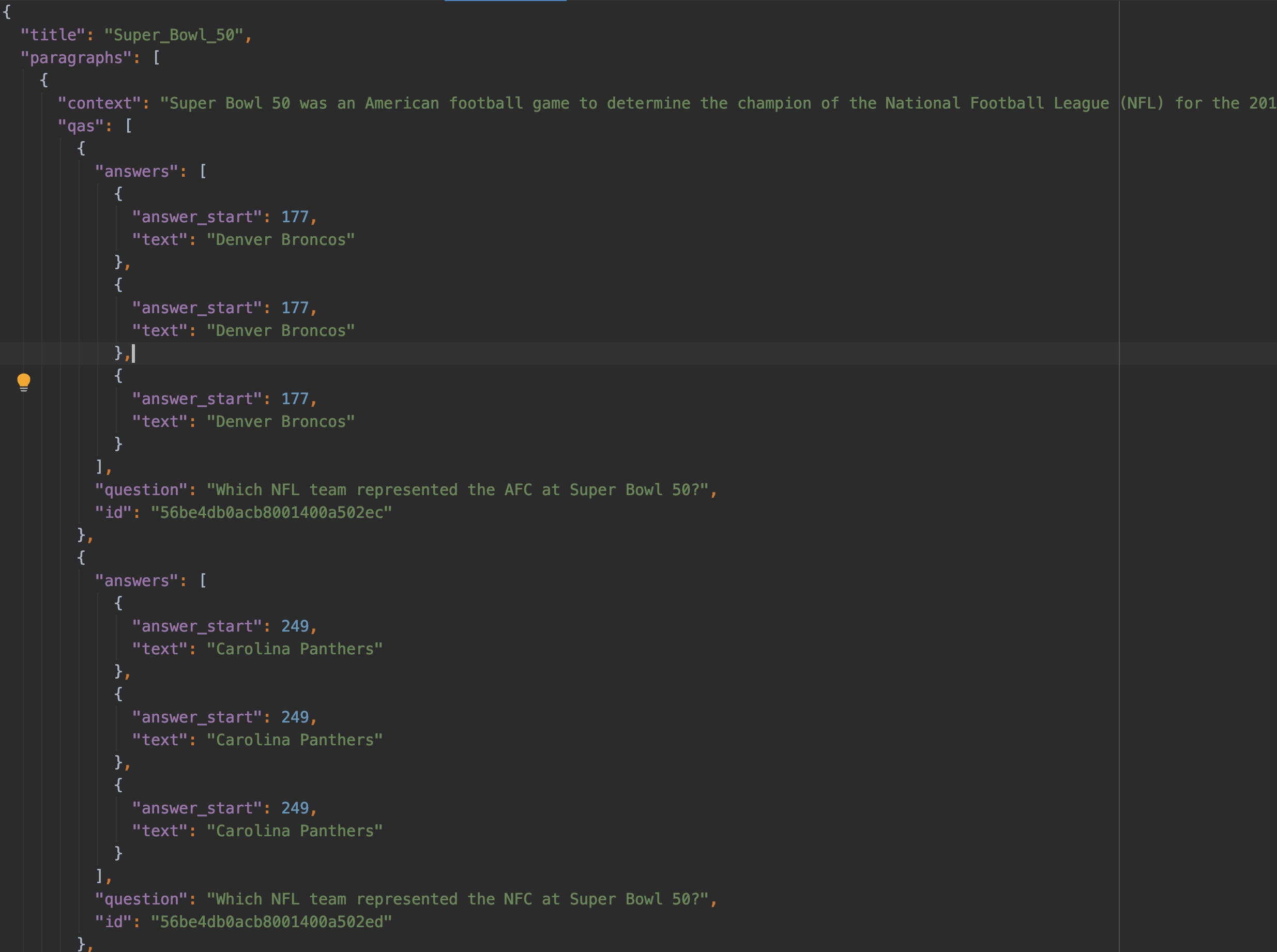
- 先介绍一下SQuAD数据集的特点,SQuAD数据集包含10w个样例,每个样例大致由一个三元组构成(文章Passage, 相应问题Question, 对应答案Answer), 以下皆用(P,Q,A)表示。
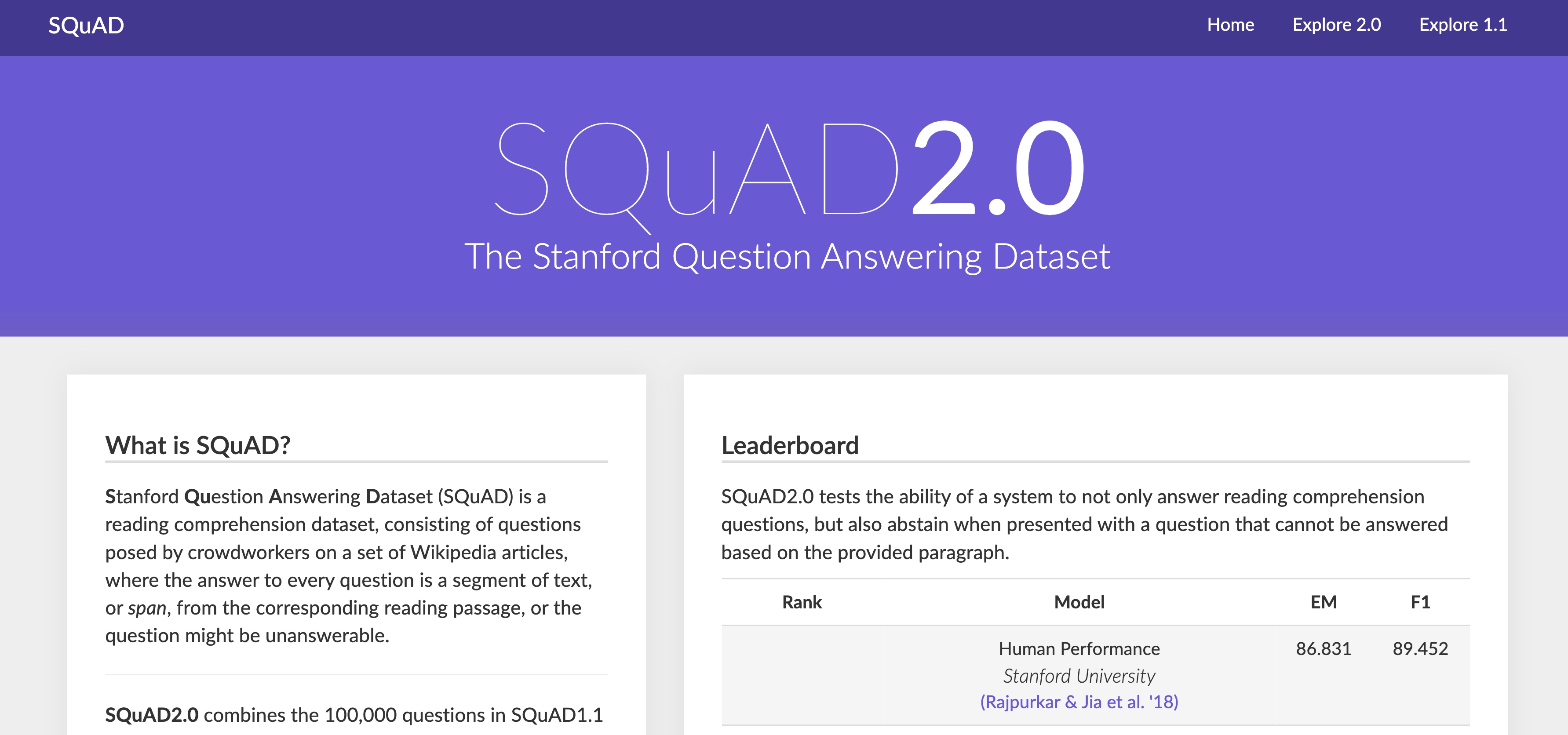
SQuAD2.0
BiDAF
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fU7prODu-1609993735683)(media/15974749961031/15974875807392.jpg)]
效果
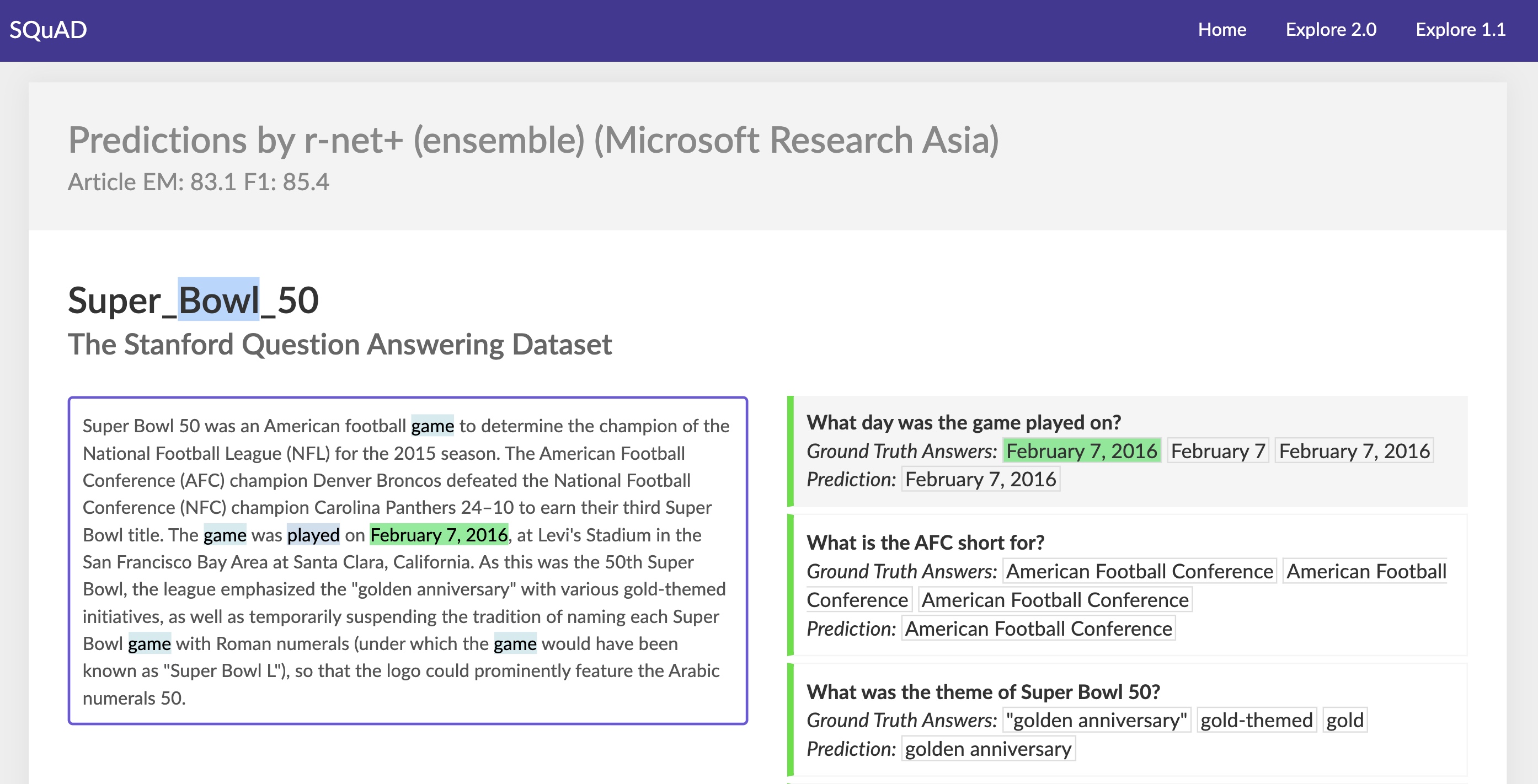
0x00 简介
2016年, 华盛顿大学的团队公布了BiDAF模型,在随后的几周占据斯坦福QA问答数据集(SQuAD)的榜首,虽然BiDAF已经被其他模型超过,但是他依然影响着Q&A领域,这项技术指导更新的ELMo和BERT模型被提出来,才渐渐被取代。
如果你是没有太多NLP经验的小白,或者对相关模型不是很了解的话,直接去读原始论文,可能会被复杂的模型弄的晕头转向。
BiDAF的模型结构类似于一种了GloVe, CNN, LSTM 和 Attention的一种复合的结构。要全面的了解BiDAF结构,我们需要去了解模型的block的构建和各个block直接是如何combined。模型错综复杂的连接,是影响我们理解模型的障碍。
在接下来的内容里,我讲带着大家通过大量的图片和示例图,来一步一步去理解和消化模型的结构。
本章分为四个部分:
- 提供
BiDAF模型的基本概括。 - 讲解
Embedding层。 - 讲解
Attention层。 - 讲解
Output层,并且串讲整个BiDAF结构,如果你有一定的基础,可以直接跳过前面几章,直接跳转到第四章。
0x1 Bi DAF相对于其他的QA模型
在深入研究BiDAF之前,让我们先宏观的了解下问答模型。问答模型可以通过几种方法进行分类。这里有一些励志:
-
Open-domain与Closed-domain。一个开放的领域模型是什么意思呢,举个例子,当我们在查询(Query)一个答案(answer)的时候,会去访问一个已有的访问知识库,并且去查询相关的内容,这样的模型我们就称为Open-domain。一个很出名案例就是IBM Watson。相反,Closed-domain形式的模型则不依赖于已有知识。而是,这种模型需要结合上下文来回答问题。 -
Abstractive与Extractive。一个摘要模型返回的答案往往是Context内容的片段。换句话说,始终可以在上下文中一字不差的找到答案。一个抽取式模型,则是将相关的片段进行整合,转述成可读的答案。 -
准确答案的非因果性查询。事实型查询,其答案是简短的事实陈述。大多数以
“who”,“where”和“when”开头的查询都是事实查询,因为他们期望简明的事实作为答案。非事实型查询,简单地说,是不是改编过的所有问题。非拟事实阵营非常广泛,包括需要逻辑和推理的问题(例如,大多数“为什么”和“如何”问题)以及涉及数学计算,排名,排序等的问题。

上面是Watson简单介绍,回归正题,那么BiDAF在这些分类方案中适合什么地方?
BiDAF是一种封闭域(Closed-domain)的摘要型(Abstractive)的问答模型,只能回答事实问题。这些特征意味着BiDAF需要上下文来回答查询。BiDAF返回的答案始终是提供的上下文的子串。
以下是Context、Query和Answer的示例。

另一个快速提示:您可能已经注意到,我一直将“Context”s“Query”和“Answer”一词大写。这是为了来表示专有名词。好了,有了以上这些知识,我们现在就可以来探索一下BiDAF的结构。
0x3 BiDAF结构概述
BiDAF之所以能够在上下文中查找出答案的位置,原因在于其层(Layer)的设计。这些层中的每一层都可以看作是一个转换模块,可以单词转换成向量表示。每次转换都会包含一些新的信息。
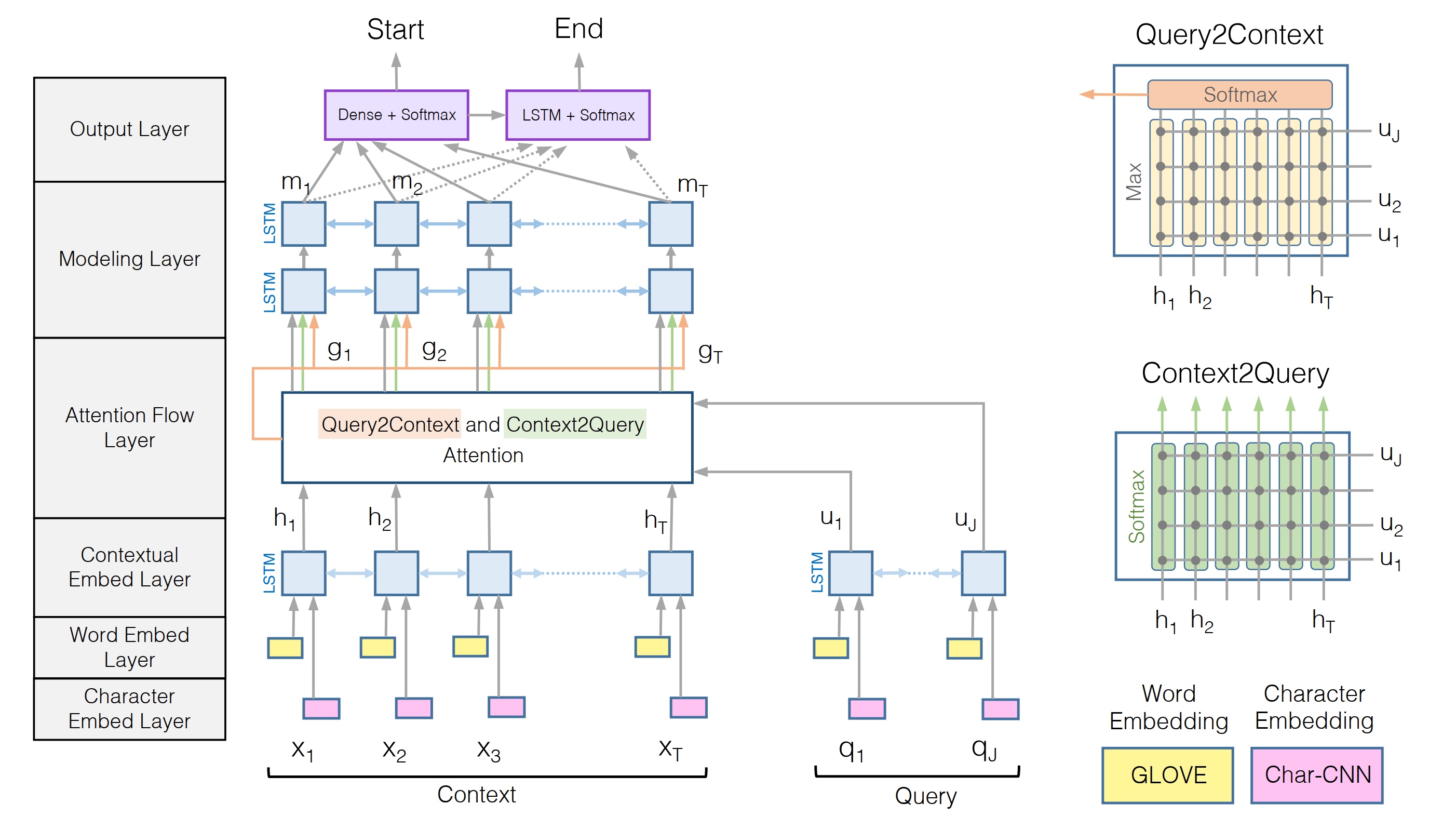
BiDAF论文将模型描述为具有6层:
- Character Embedding Layer
- Word Embedding Layer
- Contextual Embedding Layer
- Attention Flow Layer
- Modeling Layer
- Output Layer
但是其实可以将BiDAF视为具有3个部分。下面简要介绍这3个部分及其功能。
1. 嵌入层(Embedding Layers)
BiDAF具有3个嵌入层(Embedding),其功能是将Query和Context中的单词表示形式从字符串转换为向量。
2. 注意力层(Attention and Modeling Layers)
这些Query和Context表示然后进入Attention和Modeling层。这些层使用几种矩阵运算来融合Query和Context中包含的信息。这些步骤的输出是Context的另一种表示形式,其中包含来自Query的信息。该输出在本文中称为"查询感知上下文表示"(Query-aware Context representation)。
3. 输出层(Output Layer)
然后将具有Query的Context表示形式传递到Output层,该Output层会一堆概率值。这些概率值将用于确定答案的开始和结束位置。
下面提供了描述BiDAF体系结构的简化图:
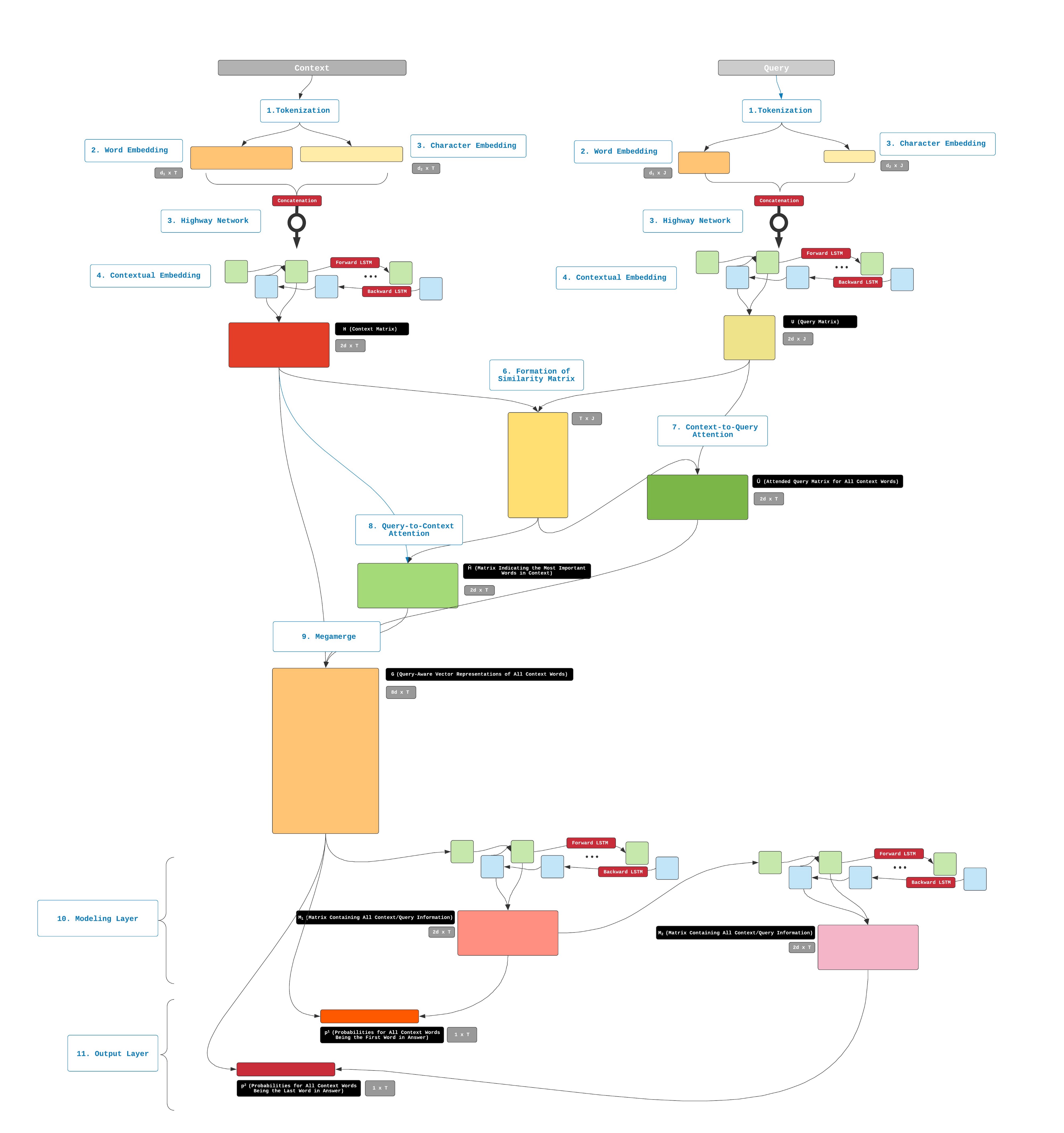
下面我们将用11个步骤来详细讲解这3个部分的实现。
#0x4 Embedding
综上所述,BiDAF是一个Closed-domain, ExtractiveQ&A模型。可以去Query Answer。BiDAF需要上下文信息。任务是从答案中获取最匹配的子串,模型将参考Answer去Query
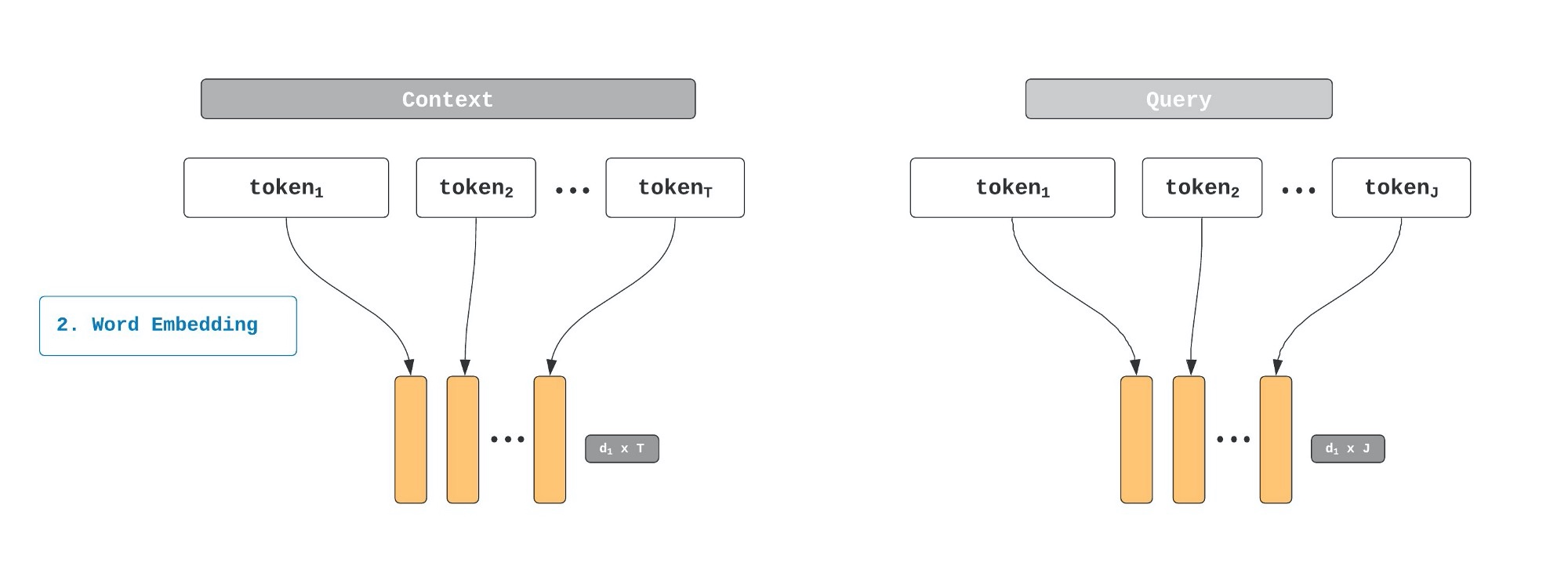
1. Tokenization

2. Word Level Embedding
BiDAF将使用GloVe作为预训练的词向量,来表示在Query和Context中的词。
3. Character Level Embedding
之前有说过,使用Character是为了解决OOV问题,在GloVe中,若输入的词不在词表中,则被认为是OOV词,这时候会分配一个随机的向量来表示,如果在我们的算法中忽略这一点,而不去处理,则会影响模型的效果. 因此就需要另外的Embedding机制来处理,Character Embedding使用一维的卷积神经网络来取表达词的含义.
-
首先将字符序列转换成向量

-
在通过一维的卷积核,顺着序列方向进行卷积.

-
然后对矩阵中的数进行求和缩放
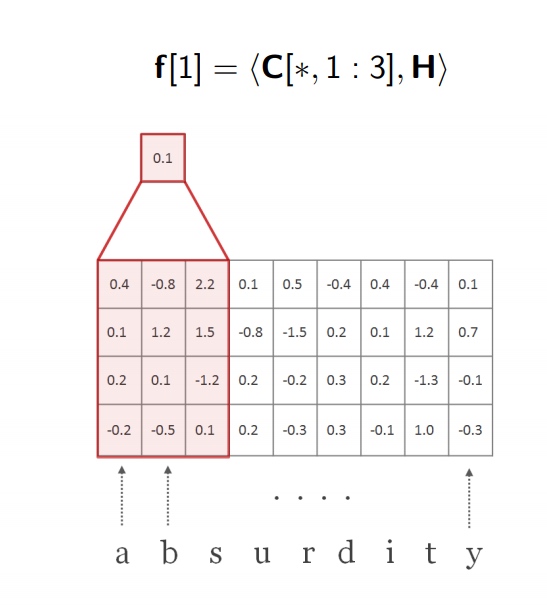
-
重复如上步骤
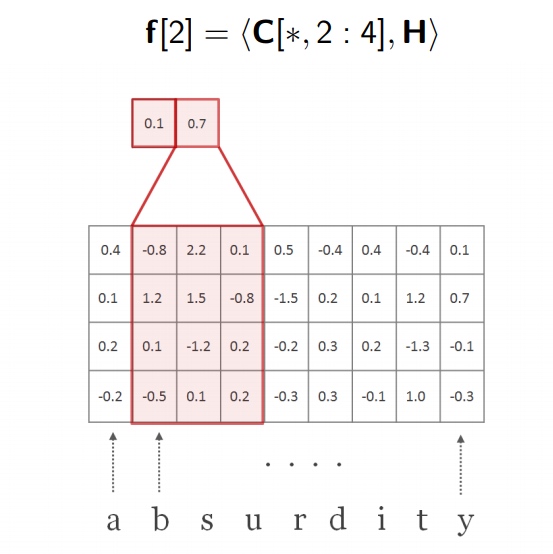
-
直到序列全部进行提取
-
我们记录最大值f , 在图中,最大值是
0.7,这个操作在代码中叫做max-pooling

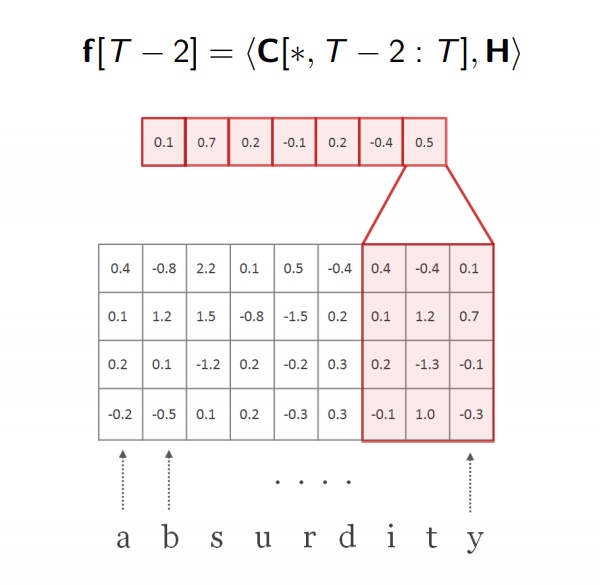
-
重复上述步骤,使用另外一个卷积核进行卷积.卷积核的宽度换成了
2.

-
重读卷积核池化操作,使用多个不动维度的卷积核进行卷积,获取最大池化后的特征.
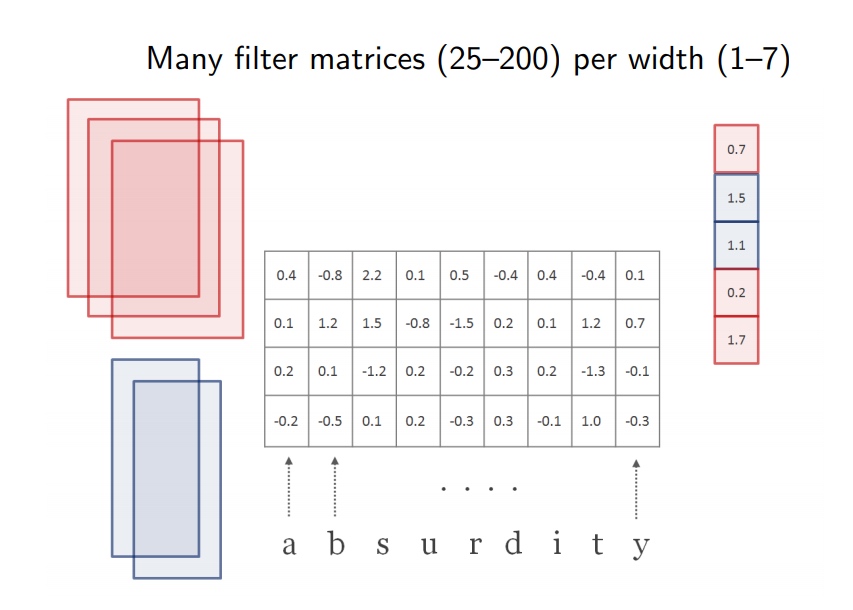
4. Highway Network
我们获取了两种的Embedding,维度为d,d1表示Word Embedding,d2表示Character Embedding。 然后累加d1和d2。

我们把这个称为highway network,与前馈神经网络十分相似.
y将于W相乘,然后加上偏置,然后加上一个非线性变换g。例如ReLU或者Tanh这种。

在highway network, 只有少数输入会经过这3个步骤, 其他部分可以不经过这个线性变换, 直接输出。对于这个变换,我们可以通过门来控制,设置一个t用于控制是否进行变换操作。这个t的值通常使用sigmoid来计算,所以会在0~1之间,具体公式如下:

我们可以将上述的公式,描述如下结构。

highway network’s是为了去调整权重关系word embedding和character embedding。比如在处理OOV词misunderestimate,我们增加1D-CNN 的重要性,应为GloVe输出的word embedding都是随机.另外当我们去处理一个正常词的时候,word和character可能会有一个相似的重要性。
highway network的输出也是两个矩阵Context matrix和Query matrix。用来表示从Query和Context考了Word和Character Embedding之后调整出来的向量表达。
5.Contextual Embedding
对于我们要处理的任务,以上操作依然不能满足.因为Word的表示,并不能很好的把握上下文的意思,当我们仅仅依靠Word和Character Embedding,一词多义的词无法把握,因为他们会分配一个相同的词向量,这样就会迷惑你的模型。
这样就需要一个额外的Embedding来理解这个Context中的词.我们把它称为Contextual Embedding Layer。我们使用LSTM来表示这个Contextual Embedding结构.
因为LSTM能够对每一个时间步的数据的关系进行表达,所以我们使用LSTM输出来表示上下文的关系.
BiDAF使用双向的LSTM(bi-LSTM),Word和Character Embedding经过LSTM处理后的输出被称为Contextual Embedding ,对于Context和Query的输出分别使用H和U来表示.


以上就是BiDAF的Embedding层,在经过Word和Character Embedding变换,结合转换层Contextual Embedding之后,得到了我们Embedding的输出。接下来将进行Attention的操作。
0x5. Attention
其实在BiDAF中的Attention与Seq2Seq中的是类似的,所以我们先回顾Seq2Seq中是如何实现的.
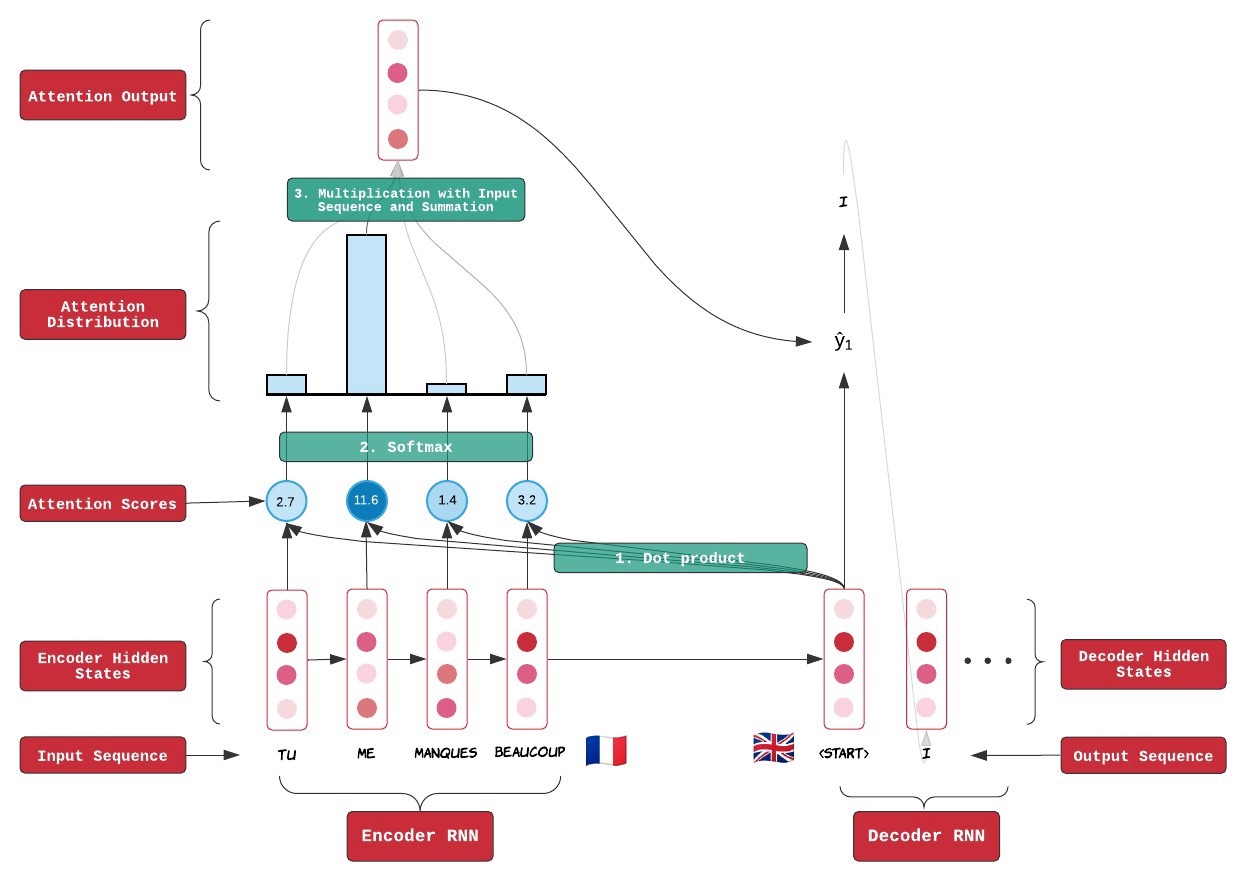
1. 序列比较和Attention分数计算
在decoder过程中,每一个时间步计算都需要与全部的encoder hidden states进行比较,这个过程可以通过任何的函数来讲这两个输出进行比较,比如简单的就可以通过点乘来完成dot,这个操作之后的数值输出被称为attention score
2. Attention分数转换成Attention分布
我们使用softmax去计算所有的分值,最后输出一个概率分布,这个分布被称为attention distribution,这里获取的是一个跟输入序列相关的分布.图上是一个法语转换成英语的例子,其中蓝色柱形条就是attention distribution
3. 获取Attention Output
Multiplying Attention Distribution与Encoder Hidden States去获取Attention Output
6. 生成相似矩阵
之前讲到, contextual embedding步骤将生成两个矩阵.分别是H和U.这两个矩阵是根据Query和Context的信息.
通过议论上述的Attention操作之后,将会生成一个矩阵S,我们把它称为相似矩阵.大小是T*J,J是词的数量.如上所述的seq2seq attention的机制,需要应用一个函数来对H和U的列做比较。矩阵S的t行和j列中的值表示第t个上下文词(Context)和第j个查询词(Query)的相似性。
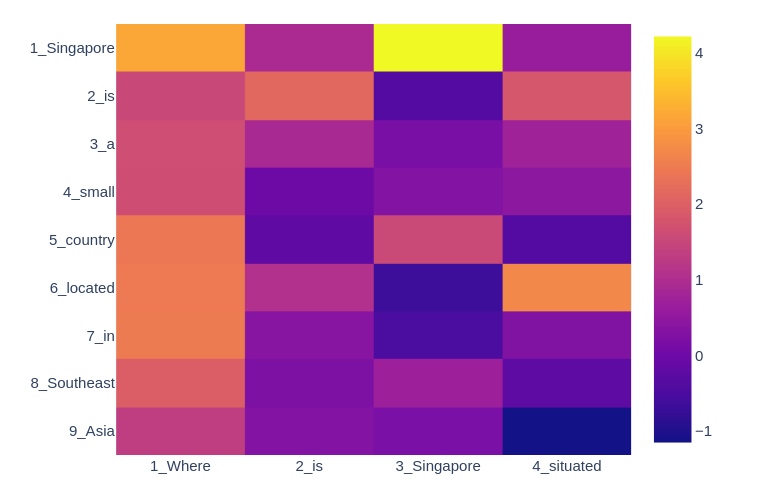
下图是一个相似矩阵S的例子:
- Context: “Singapore is a small country located in Southeast Asia.” (T = 9)
- Query: “Where is Singapore situated?” (J = 4)
由上面的Query/Context产生的相似度矩阵S如下所示:
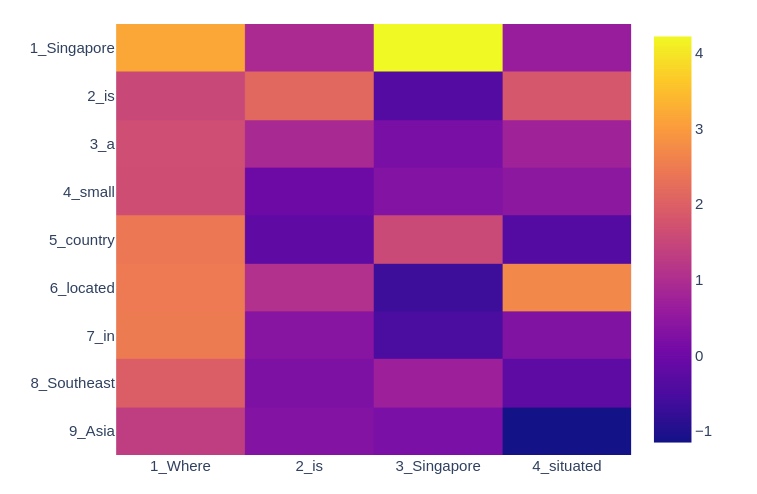
我们能观察到一些信息:
- 如我们所料,矩阵的尺寸为9 x 4,9为Context(T)的长度,4为查询(J)的长度。
- 第1列第3列中的单元格包含一个较高的值,如其亮黄色所示。 这意味着与此坐标关联的查询词和上下文词非常相似。 这些单词竟然是完全相同的单词-“Singapore”-因此它们的向量表示形式非常相似是有道理的。
- 仅仅因为上下文词和查询词是相同的,并不一定意味着它们的向量表示非常相似! 查看第2行第2列中的单元格-该单元格编码上下文词“is”和相同的查询词“is”的相似性。 但是,它的价值不及上述“Singapore”水平。 这是因为这些向量表示形式还包含了周围短语的信息。 对于诸如“is”之类的小系动词,这种情境贡献尤其重要。
- 另一方面,我们可以看到两个具有相似的语义和语法意义的不同单词(例如“situated”和“located”)的相似度值相对较高。 这要归功于我们的单词和字符嵌入层,它可以生成向量表示,从而非常准确地反映出单词的含义。
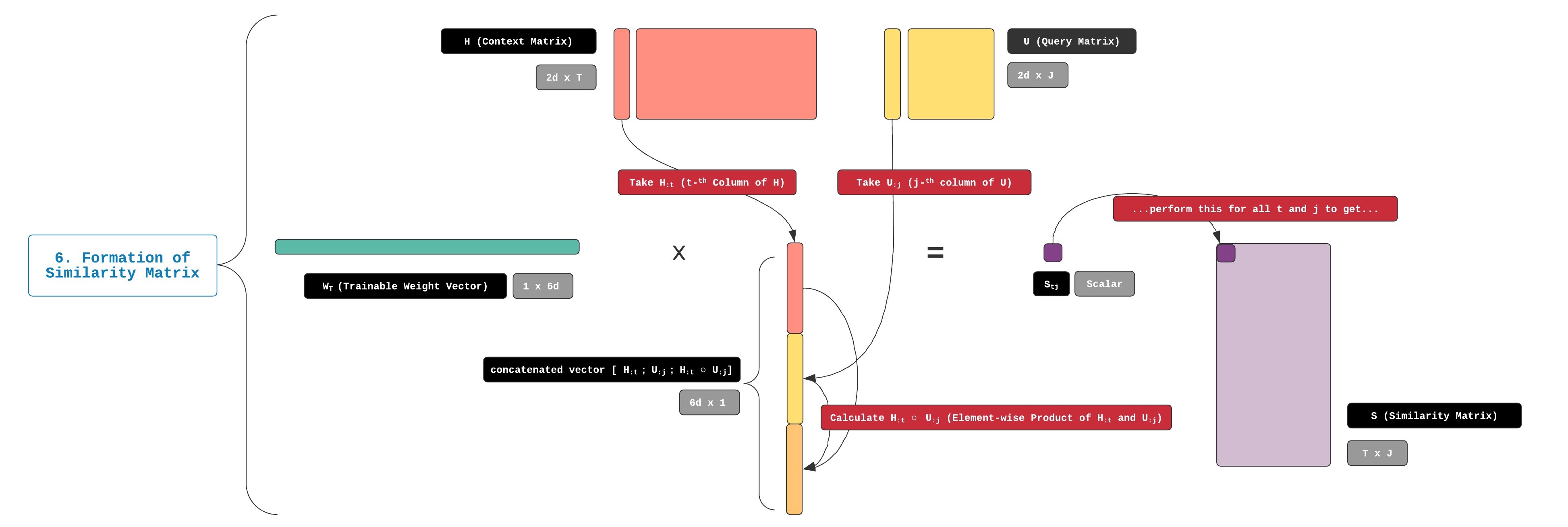
现在让我告诉您我们如何计算S中的值。用于执行此计算的比较函数称为α。 α比seq2seq中使用的点积复杂。 这是α的方程式:


由于函数α包含行向量和大小相等的列向量的乘积,因此它始终返回标量。下图显示了此步骤中执行的所有矩阵运算。
7. Context-to-Query Attention (C2Q)
相似度矩阵S用作以下两个步骤的输入:C2Q和Q2C。
在本节中,我们将重点介绍C2Q。 此步骤的目标是找到与每个上下文词最相关的查询词。
执行C2Q与执行Seq2Seq注意的第二步和第三步相似。 首先,我们使用S中的标量值来计算注意力分布。 这是通过采用S的按行softmax完成的。结果是另一个矩阵。BiDAF论文未明确命名此矩阵,但我们将其称为矩阵A。
维度A与S相同的矩阵A指示哪些查询字与每个上下文字最相关。 让我们看一个A的例子:

通过观察上面的图,我们可以得出以下结论:
-
语义相似性极大地促进了相关性。 我们看到,对于上下文词
[“Singapore”,“ is”,“located”],最相关的查询词是[“Singapore”,“ is”,“situated”]。 这些词也具有很强的 -
语义相似性。上下文词“理解”查询词所请求的信息。 我们看到查询词“Where”是与上下文词
[“ a”,“small”,“ country”,“ in”,“Southeast”,“ Asia”]– 与地理位置相关的词最相关的查询词。
然后,我们使用A的每一行来获得注意力分布At:其维度为1×J。 在:反映每个查询词对第t个上下文词的相对重要性。
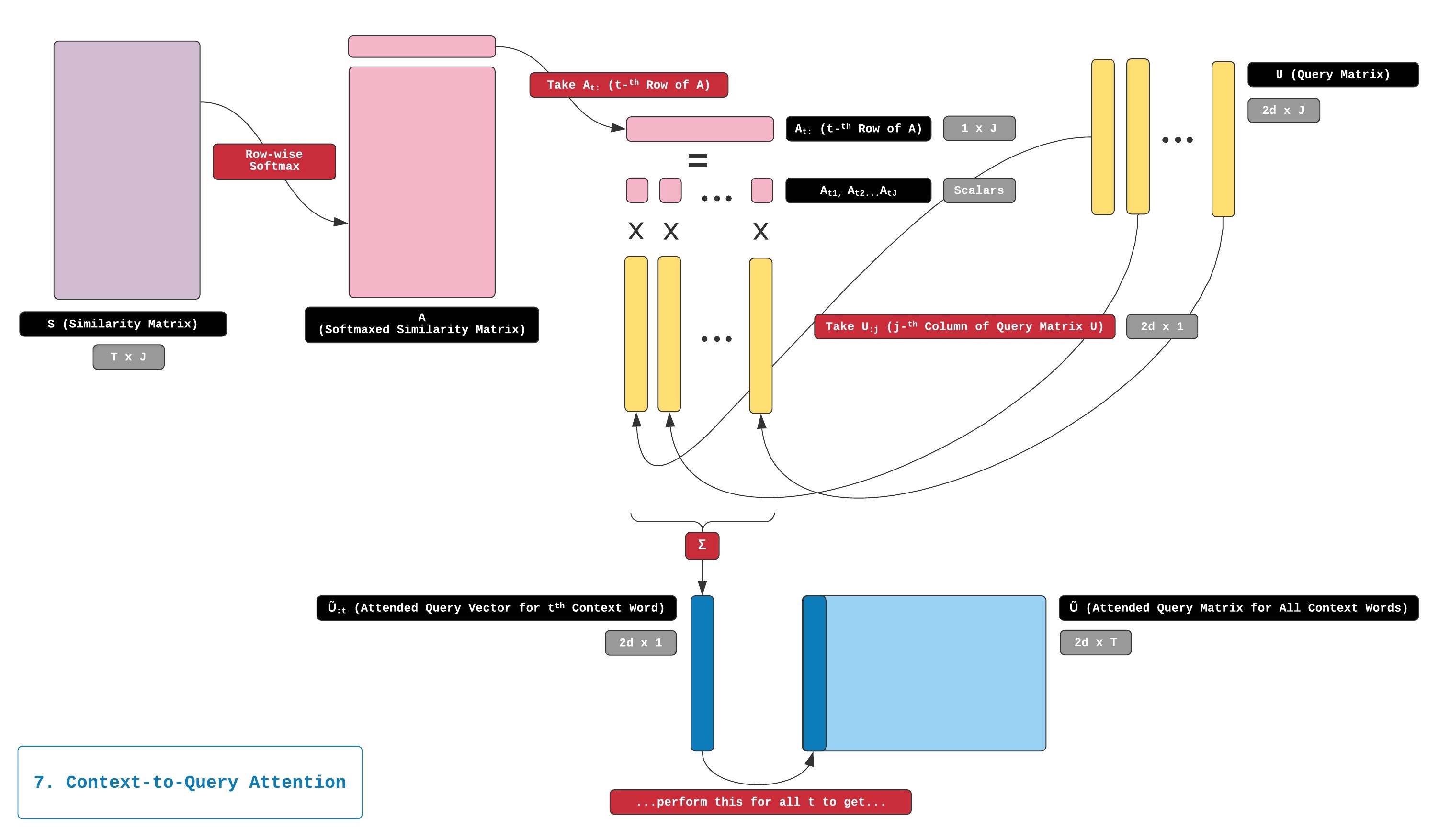
然后,我们针对注意力分布At:中的每个元素计算查询矩阵U的加权和。 此步骤的结果是称为matrix的注意力输出矩阵(attention output matrix),并且称为 U ~ \tilde{\mathbf{U}} U~, 它是一个2d-T矩阵。
U ~ \tilde{\mathbf{U}} U~与 H H H相似,是Context的矩阵表达, U ~ \tilde{\mathbf{U}} U~与 H H H不同的信息, H H H表达的是语义,语法和上下文上的含义. U ~ \tilde{\mathbf{U}} U~表示的是每一个query word与 Context word的相关性.
从 S S S和Query矩阵 U U U生成 U ~ \tilde{\mathbf{U}} U~的过程如下图所示:
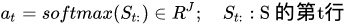
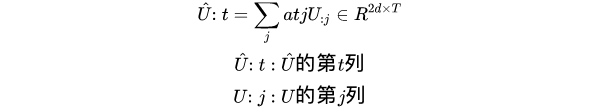
8. Query-to-Context (Q2C) Attention
下一步是
Q2C,与C2Q一样,它也从相似矩阵S开始。在这一步中,我们的目标是找到哪个Context词与Query word最相似,因此对于Answer查询至关重要。
我们首先采用相似矩阵S的最大值来获取列向量。 该列向量在本文中未明确命名,所以我们称其为z。
我们的相似度矩阵S记录了每个Context Word和每个Query Word之间的相似性,例子如下:
现在,我们将注意力集中在此矩阵的第四行,该行对应于上下文单词“small”。 可以看到这一行没有任何明亮的单元格! 这表明查询中没有与上下文单词“small”相似的单词。 当我们在这一行取最大值时,获得的最大值将接近零。
将其与单词“Singapore”和“situated”进行对比,在行中我们确实发现至少一个明亮的单元格,表明存在与这些单词相似的查询单词。 当我们取这两行的最大值时,这些行的向量z中的对应值也将相对较高。
最终获取到的z如下图:

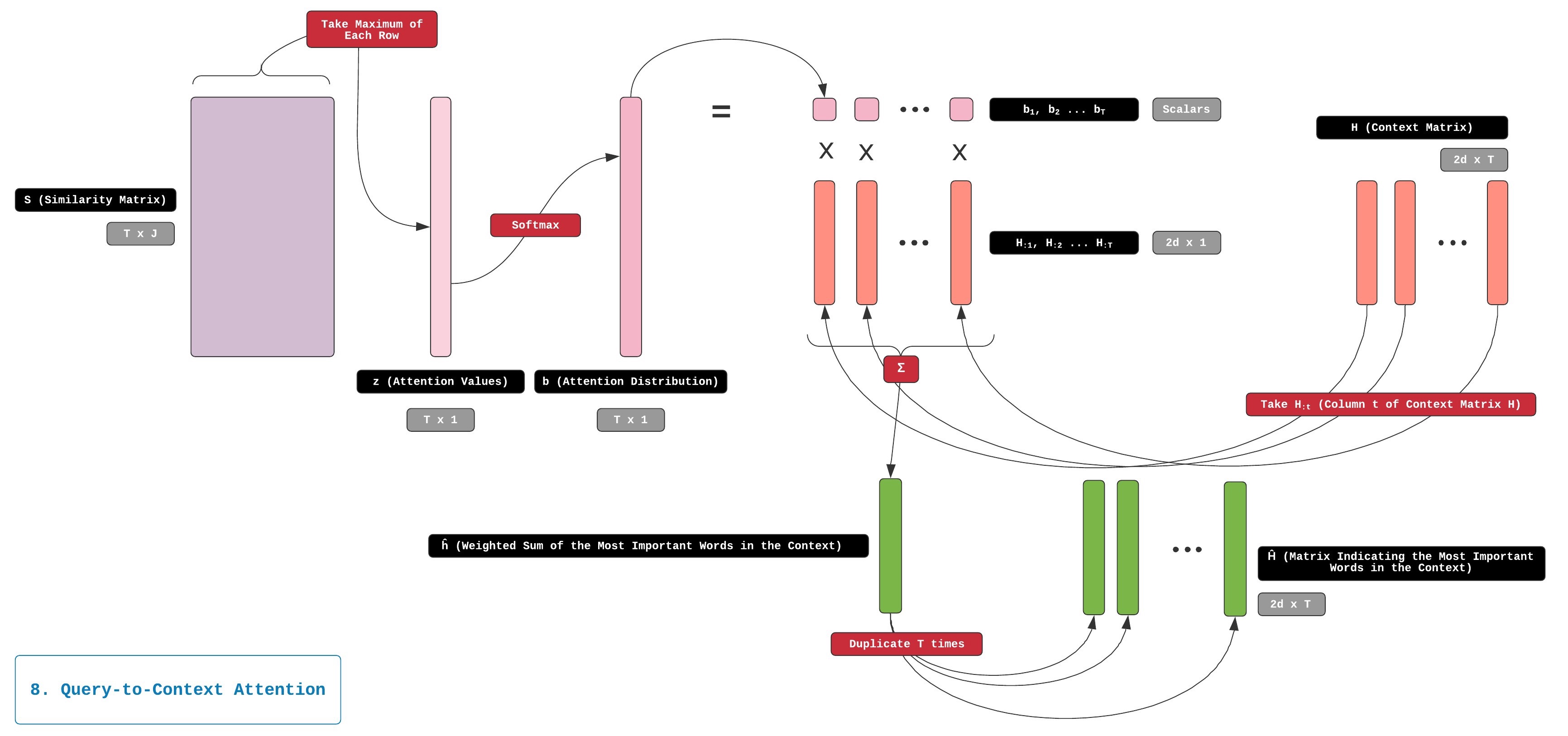
在Q2C中,z中的值就是我们的关注值。 我们在z上应用softmax以获得注意力分布称为b。 然后,我们使用b来获取上下文矩阵H的加权和。结果的注意力输出是称为 h ^ \hat{\mathbf{h}} h^的2dx1列向量。
Q2C的最后一步是复制和粘贴 h ^ \hat{\mathbf{h}} h^T次,并将这些副本组合到称为 H ^ \hat{\mathbf{H}} H^的2dxT矩阵中。 H ^ \hat{\mathbf{H}} H^还表达了一些其他信息,包括Context中的非常重要的词,考虑Query之后Context中的重要单词信息。
b = softmax ( max c o l ( S ) ) ∈ R T b=\operatorname{softmax}\left(\max _{c o l}(S)\right) \in R^{T} b=softmax(maxcol(S))∈RT
h ^ = ∑ t b t H : t ∈ R 2 d \hat{h}=\sum_{t} b_{t} H_{: t} \in R^{2 d} h^=∑tbtH:t∈R2d
H ^ ∈ R 2 d × T \hat{H} \in R^{2 d \times T} H^∈R2d×T
从 S S S和query矩阵 U U U生成 H ~ \tilde{\mathbf{H}} H~的过程如下图所示:
9. Megamerge
通过Combined上面5, 7 和 8步骤的输出,可以构建一个大的矩阵G,具体操作如下:
H:原始的Context matrix- U ~ \tilde{\mathbf{U}} U~:
Query word与每一个Context word的相关性表示。 - H ~ \tilde{\mathbf{H}} H~:关于
Query在Context中的最重要的单词信息。

我们定义这个G矩阵为 t = β ( H : t , U ~ : t , H ^ : t ) \mathbf{t}=\beta(\mathbf{H}:\mathbf{t}, \tilde{\mathbf{U}}:t, \hat{\mathbf{H}}:\mathbf{t}) t=β(H:t,U~:t,H^:t)
其中 G : t \mathbf{G}:\mathbf{t} G:t指的是G中的第t列向量,它对应于第t个上下文词。G的尺寸为8dx7。
使用 H H H, U ~ \tilde{\mathbf{U}} U~和 H ~ \tilde{\mathbf{H}} H~生成 G G G的过程如下图所示:
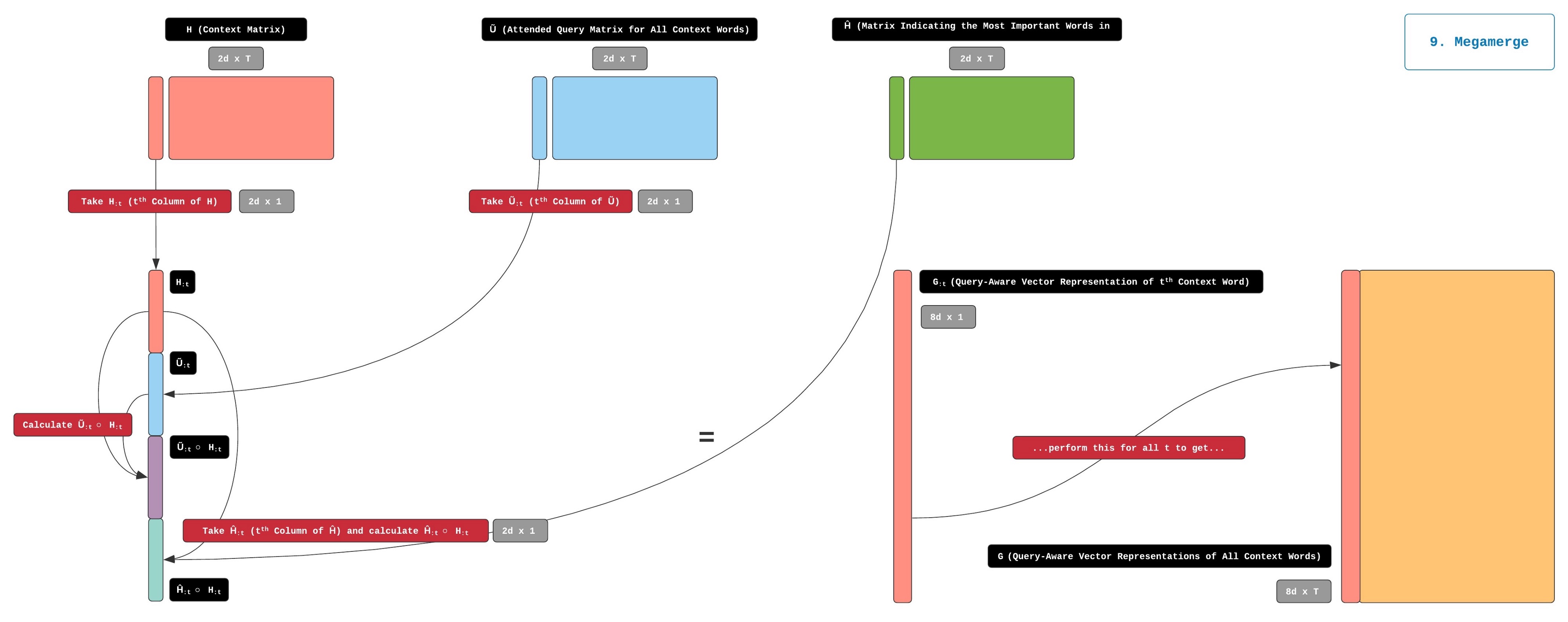
在这个巨大的矩阵 G G G中包含了所有 H H H, U ~ \tilde{\mathbf{U}} U~和 H ~ \tilde{\mathbf{H}} H~的信息.也就是说,您可以将G中的每个列向量是将Query和Context已经他们的相关性信息的一个综合表示
10. Modeling Layer

在以上的步骤中我们获得了一个矩阵G,每一列向量的大小为 8 d x 1 8dx1 8dx1,d是词向量的维度.
下么我们通过一个例子来回顾整个过程.
我们假设每一个词是一个小黄人.

每一个小黄人的大脑可以存储信息.我们需要去找叫“Singapore”的小黄人

刚开始小黄人的大脑是空的,他并不知道自己是谁.所以我们需要去教他们去学习去他们自己的身份。Teacher就是Word Embedding,文中我们使用的GloVe作为预训练的词向量。通过词向量学习后,小黄人现在就能区分自己了。

随后小黄人有参加了"Contextual Embedding"的课程,小黄人不得不在Bi-LSTM的促使下进行交谈,Bi-LSTM使得他们能够了解他们周围小黄人的身份.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bIR33QFZ-1609993735709)(https://miro.medium.com/max/1000/0*hfo4osImRi7Unequ.gif)]
现在再去扫描小黄人的大脑,识别小黄人的身份,他会知道更多.

好的,然后记者Mr. Query来到了小黄人的学校.

他迫切的希望收集一些信息进行写作,比如他想知道“where is Singapore situated.”他知道这些信息在小黄人那里能找到.

小黄人尽自己的最大努力来帮助Mr. Query。为此,他们需要选择团队中的几名成员与Query先生会面并提供他所寻求的信息。这些相关的小黄人将派遣给Mr. Query,在这里我们把他们成为Answer Gang。
现在他们需要集体决定让那些小黄人去参加这个Answer Gang。因为选择的小黄人太多,Mr. Query的工作了太大, 这种情况被称为Low Precision。太少又可能Mr. Query得到的信息不够,被称为Low Recall。所以Mr. Query希望有一个适当数量的信息.
问题来了,我们应该如何决定这个数量呢?
答案就是通过组织几次聚会会议来决定,我们把它称为“Attention”。在这些会议中,每个小黄人都要分别与Query先生交谈并了解他的需求。 换句话说,“Attention”会议允许小黄人衡量其对Query先生问题的重要性。
这是“Singapore”小黄人离开Attention会议时的大脑的扫描得到的信息。

正如我们所看到的,我们的小黄人的大脑现在已经很满了。 有了小黄人的最新知识,他们现在可以开始选择Answer Gang的成员了吗?
答案是,不! 他们仍然缺少一条关键信息。 我们每个小黄人都知道他对Query先生的重要性。 但是,在做出这一重要决定之前,他们还需要了解彼此对Query先生的重要性。
您可能已经猜到了,这意味着小黄人必须第二次互相交谈!很容易想到,继续使用Bi-LSTM操作一波。

这种通过Bi-LSTM进行的对话是我们当前文章的重点。 现在让我们详细了解这一步!
Modeling Layer
短暂离开小黄人这个例子,我们看下这个公式的操作.
建模层相对简单。 它由两层bi-LSTM组成。 如上所述,建模层的输入为G。第一个bi-LSTM层将G转换为称为M1的2dxT矩阵。
然后,M1充当第二个bi-LSTM层的输入,该第二bi-LSTM层将其转换为另一个称为M2的2dxT矩阵。
由G形成M1和M2的情况如下所示。

M1和M2是上下文词的另一种矩阵表示形式。M1和M2与上下文单词的先前表示形式之间的区别是M1和M2已在其中嵌入了有关整个Context段落以及Query的信息。用小黄人讲,这意味着我们的小黄人现在拥有决定谁应该在Answer Gang中所需的所有信息。

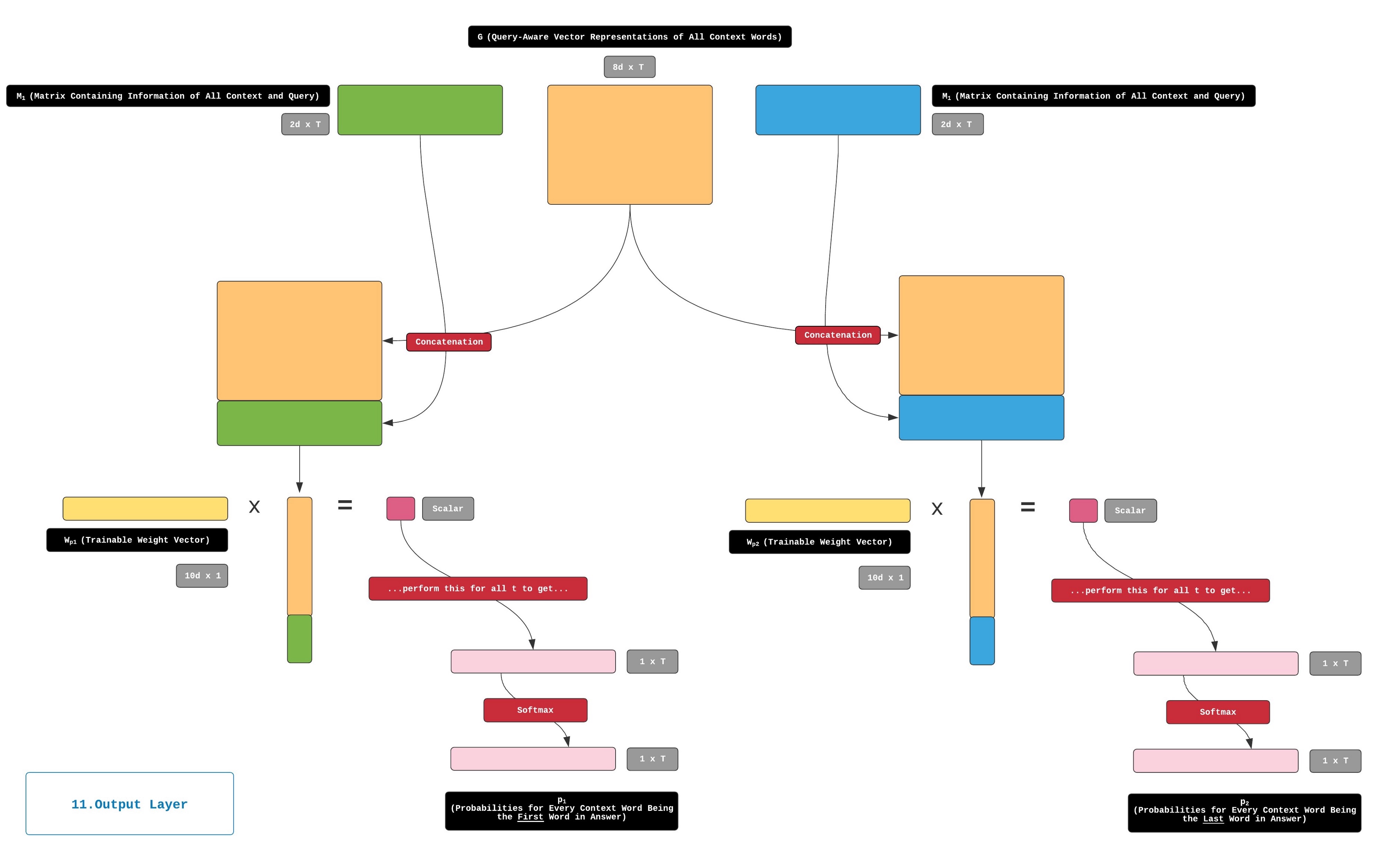
11.Output Layer
好的,现在我们到了结局! 再走一步,我们就完成了!
对于上下文中的每个单词,我们都可以使用两个向量来对Word’s与Query的相关性进行编码。 我们需要的最后一件事是将这些向量转换为两个概率值,以便我们可以比较所有Context word的Query相关性。 而这正是输出层所做的。
在输出层中,首先将M1和M2与G垂直串联以形成[G; M1]和[G; M2]。 两者[G;M1]和[G;M2]的尺寸为10d×T。
然后,通过以下步骤获得p1,即整个上下文中起始索引的概率分布:

类似地,我们通过以下步骤获得p2,即结束索引的概率分布:

下图描述了获取p1和p2的步骤:
然后使用p1和p2查找最佳答案范围。 最佳答案范围只是上下文中具有最高得分的子字符串。 反过来,span分数只是该跨度中第一个单词的p1分数与span中最后一个单词的p2分数的乘积。 然后,我们将返回具有最高得分的spon作为答案。一个例子将使这一点变得清楚。如您所知,我们目前正在处理以下Query/Context对:
- Context: “Singapore is a small country located in Southeast Asia。” (T = 9)
- Query: “Where is Singapore situated?” (J = 4)
通过BiDAF运行此Query/Context对之后,我们获得了两个概率向量 p1和p2。
上下文中的每个单词都与一个p1值和一个p2值相关联。 p1值指示单词成为答案范围的起始单词的概率。 以下是我们示例的p1值:

我们看到该模型认为答案范围最可能的起始词是“Southeast”。
p2值指示单词成为答案范围的最后一个单词的概率。 以下是我们示例的p2值:
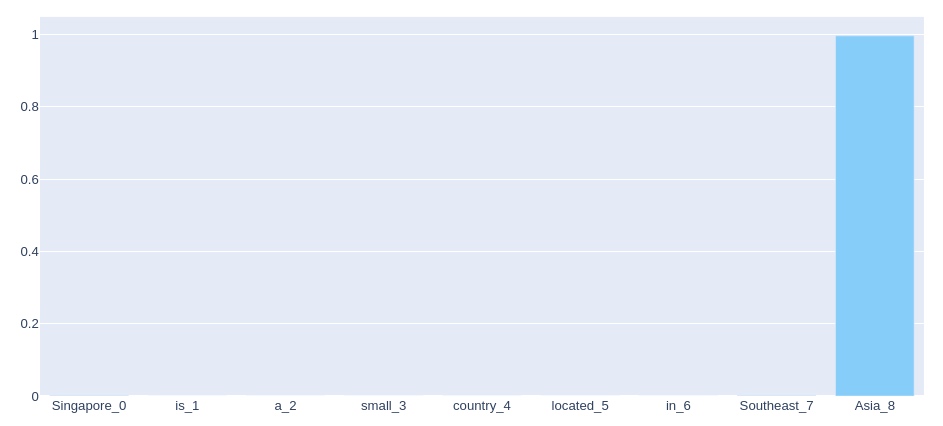
我们看到,我们的模型非常确定,几乎可以100%地确定,答案范围最可能的结尾词是“Asia”。
如果在原始上下文中,具有最高p1的单词排在具有最高p2的单词之前,那么我们已经拥有了最佳的答案范围 - 它只是一个以前者开头,以后者结尾的单词。 在我们的示例中就是这种情况。 因此,模型返回的答案将仅仅是“Southeast Asia”。
就是这样,最终,经过11个步骤,我们获得了查询的答案!

好的,在结束本系列文章之前,请注意。 在假设最高p1的上下文单词排在最高p2的上下文单词之后的情况下,我们还有很多工作要做。 在这种情况下,我们需要生成所有可能的答案范围,并为每个答案范围计算得分。 以下是一些Query/Context对可能的答案范围的示例:
- Possible answer span: “Singapore” ; span score: 0.0000031
- Possible answer span: “Singapore is” ; span score: 0.00000006
- Possible answer span: “Singapore is a” ; span score: 0.0000000026
- Possible answer span: “Singapore is a small” ; span score: 0.0000316
然后,我们以序列得分最高的作为答案。