一、简介
索引就像是书籍的目录,它给了我们查询数据提供了便利,使查询更有效率。
可以边阅读边在这个网址进行可视化模拟:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
二、常见索引
二叉树
地址:二叉树模拟
随便插入一些数据,可以得到下图。
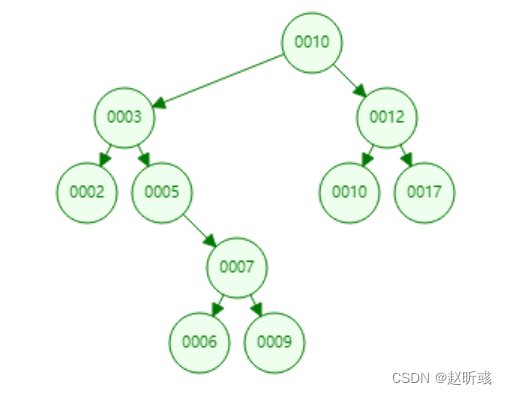
由图可以看到,任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。
那么,当我们查询0002这个节点时,不需要全部查询,只需要以下几步:
1)从根节点0010开始,0002比0010小,所以向左查询。
2)对比0003和0002,0003大,所以依旧向左。
3)找到0002节点。
那么,当出现顺序的情况下,二叉树就暴露了劣势。
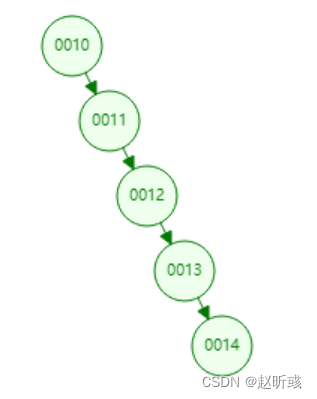
如图,这样一来,二叉树成了链表,此时再查询就等于是全盘查询了。于是就需要使用到平衡二叉树了。
平衡二叉树(AVL)
地址:平衡二叉树
平衡二叉树在满足二叉查找树特性的基础上,要求每个节点的左右子树的高度差不能超过1,如下图所示。
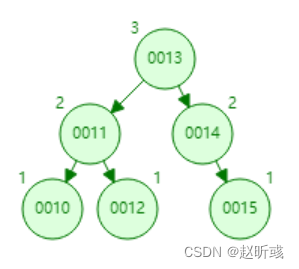
平衡二叉树保证了树的构造是平衡的,当我们插入或删除数据导致不满足平衡二叉树不平衡时,平衡二叉树会进行调整树上的节点来保持平衡。
此时,另一个问题浮现,那就是AVL树非常严格,在插入和删除时会进行很多的旋转从而消耗掉时间,所以在要求不那么严苛的时候,就会使用到红黑树。
红黑树
地址:红黑树
红黑树放弃了追求完全平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。
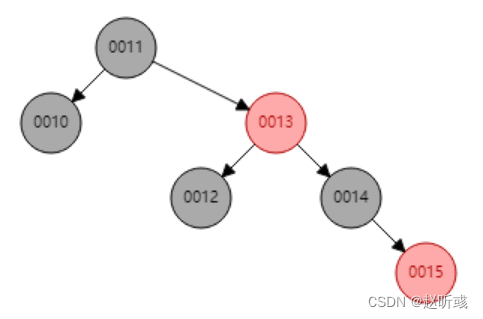
对于红黑树,有几点要求:
(1)结点非红即黑
(2)根结点是黑色的
(3)每个叶子节点(NULL节点)是黑色的
(4)每个红色节点的两个子节点都是黑色的。(不能有两连续的红色节点)
(5)从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
注意:性质5保证红黑树的最长路径不超过最短路径的两倍。
B树
地址:B树
海量数据下,二叉树的节点将会非常多,高度也会非常高,我们查找数据时也会进行很多次磁盘IO,我们查找数据的效率将会非常低。所以,需要寻找一种单个节点可以存储多个键值和数据的平衡树,也就是B树。
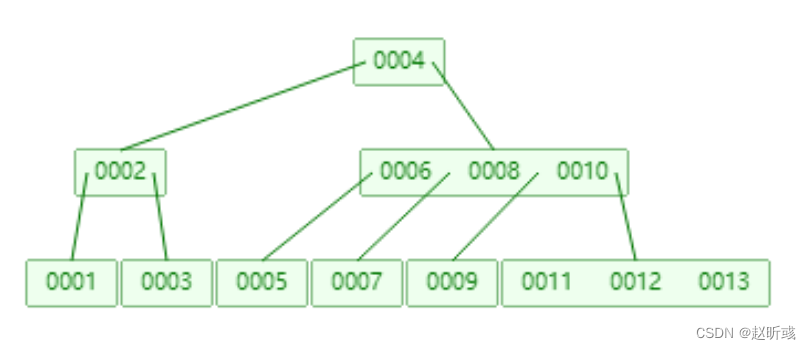
由图可以看到,一个节点种存储了更多的数据,并且一个父节点也有了更多的子节点。基于这个特性,B树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衡二叉树高。
B+树
地址:B+树
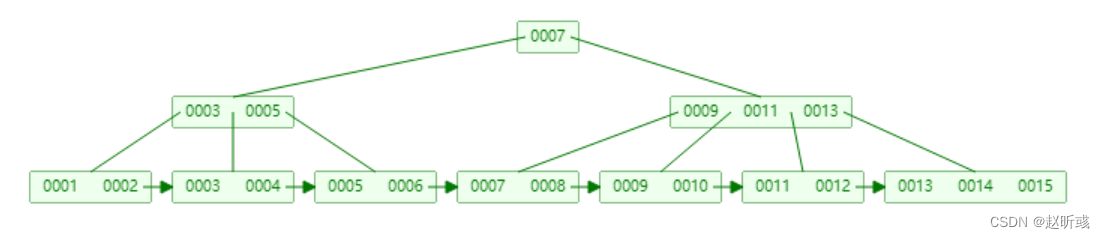
B+树相比B树有着不同的地方:
1)B+树非叶子节点上是不存储数据的,仅存储键值。
2)B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。
3)B+树中各个页之间是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的。
聚集索引和非聚集索引
聚集索引(聚簇索引):以innodb作为存储引擎的表,表中的数据都会有一个主键,即使不创建主键,系统也会帮你创建一个隐式的主键。这是因为innodb是把数据存放在B+树中的,而B+树的键值就是主键,在B+树的叶子节点中,存储了表中所有的数据。这种以主键作为B+树索引的键值而构建的B+树索引,我们称之为聚集索引。
非聚集索引(非聚簇索引):以主键以外的列值作为键值构建的B+树索引,我们称之为非聚集索引。
区别:聚集索引与非聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。