1、Hash索引的效率比树索引效率高,为什么不使用Hash索引?
1)Hash索引仅仅能够满足“=”,“IN”和“<=>”查询,不能使用范围查询。
由于Hash索引比较的是进行Hash运算之后的Hash值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的Hash算法处理之后的Hash值得大小关系,并不能保证和Hash运算前完全一样。
2)Hash索引无法被用来避免数据的排序操作。
由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值得大小关系并不一定和Hash运算之前的值完全一致,所以数据库无法利用索引的数据来避免任何排序运算。
3)Hash索引不能利用部分索引键查询。
对于组合索引,Hash索引在计算Hash值的时候是组合键合并后再一起计算Hash值,而不是单独计算Hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash索引也无法被利用。
4)Hash索引在任何时候都不能避免表扫描。
前面都已经知道,Hash索引是将索引键通过Hash运算之后,将Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使取满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的真实数据进行相应的比较,并得到相应的结果。
5)Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
2、为什么不使用二叉查找树?
二叉查找树也称为有序二叉查找树,满足二叉查找树的一般性质,是指一棵空树具有如下性质:
1)任意节点左子树不为空,则左子树的值均小于根节点的值;
2)任意节点右子树不为空,则右子树的值均大于于根节点的值;
3)任意节点的左右子树也分别是二叉查找树;
4)没有键值相等的节点;

二叉查找树的平均查找速度比顺序查找来得更快,但是某些情况就可能退化为线性表。

3、为什么不使用AVL树?
AVL树是带有平衡条件的二叉查找树,一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡,左右子树树高不超过1,和红黑树相比,它是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过1).不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转是非常耗时的,由此我们可以知道AVL树适合用于插入删除次数比较少,但查找多的情况。
由于维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树.当然,如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树.
4、为什么不使用红黑树?
红黑树是每个节点都带有颜色属性的二叉查找树,颜色或红色或黑色。在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
- 性质1. 节点是红色或黑色。
- 性质2. 根节点是黑色。
- 性质3 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 性质4. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
这些约束强制了红黑树的关键性质: 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。它是一种弱平衡二叉树(由于是若平衡,可以推出,相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,它的旋转次数变少,所以对于搜索、插入、删除操作多的情况下,我们就用红黑树。
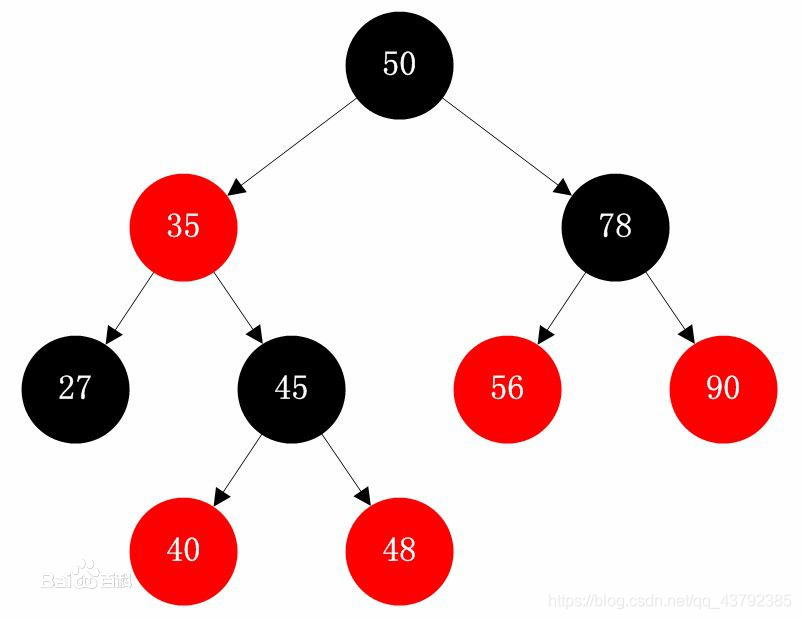
红黑树这种弱平衡结构,他的深度h还是比较深。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),因此他的性能不是很好。
广泛用于C++的STL中,Map和Set都是用红黑树实现的;
著名的Linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块,进程的虚拟内存区域都存储在一颗红黑树上,每个虚拟地址区域都对应红黑树的一个节点,左指针指向相邻的地址虚拟存储区域,右指针指向相邻的高地址虚拟地址空间;
IO多路复用epoll的实现采用红黑树组织管理sockfd,以支持快速的增删改查;
Nginx中用红黑树管理timer,因为红黑树是有序的,可以很快的得到距离当前最小的定时器;
Java中TreeMap的实现;
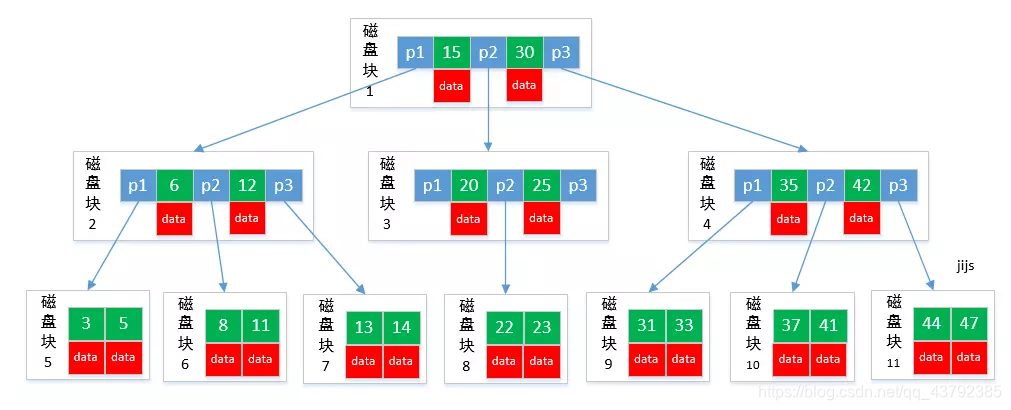
5、为什么不使用B树?
B/B+树是为了磁盘或其它存储设备而设计的一种平衡多路查找树(相对于二叉,B树每个内节点有多个分支),与红黑树相比,在相同的的节点的情况下,一颗B/B+树的高度远远小于红黑树的高度(在下面B/B+树的性能分析中会提到).B/B+树上操作的时间通常由存取磁盘的时间和CPU计算时间这两部分构成,而CPU的速度非常快,所以B树的操作效率取决于访问磁盘的次数,关键字总数相同的情况下B树的高度越小,磁盘I/O所花的时间越少。
B树的性质:
定义任意非叶子结点最多只有M个儿子;且M>2;
根结点的儿子数为[2, M];
除根结点以外的非叶子结点的儿子数为[M/2, M];
每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
非叶子结点的关键字个数=指向儿子的指针个数-1;
非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
所有叶子结点位于同一层;
人类对于性能的追求是无止境的,B树相比二叉树虽好,但还是存在以下问题:
1)每个节点中既要存索引信息,又要存其对应的数据,如果数据很大,那么当树的体量很大时,每次读到内存中的树的信息就会不太够。
2)B树遍历整个树的过程和二叉树本质上是一样的,B树相对二叉树虽然提高了磁盘IO性能,但并没有解决遍历元素效率低下的问题。
6、MySql选择B+树
B+tree 是 B-tree 的变种,B+tree 数据只存储在叶子节点中。这样在B树的基础上每个节点存储的关键字数更多,树的层级更少所以查询数据更快,所有指关键字指针都存在叶子节点,所以每次查找的次数都相同所以查询速度更稳定。
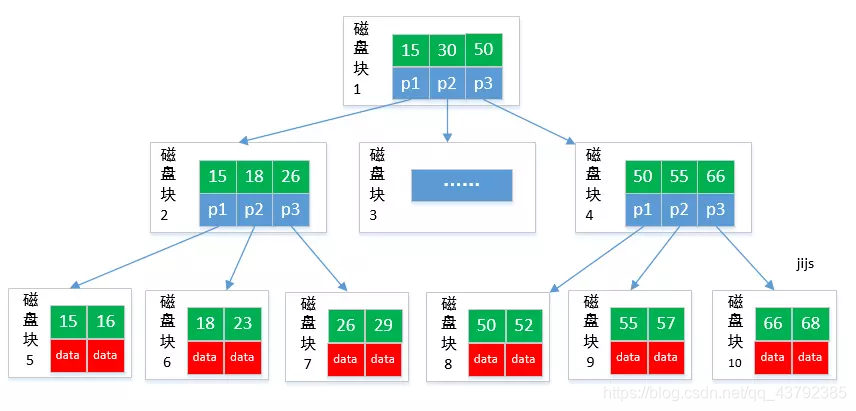
总结一下B+树的优点:
(1) B+树的磁盘读写代价更低
B+的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部 结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的 关键字也就越多。相对来说IO读写次数也就降低了。
(2)B+树的数据信息遍历更加方便
B+树只要遍历叶子节点就可以实现整棵树的遍历,而B树不支持这样的操作(或者说效率太低),而且 在数据库中基于范围的查询是非常频繁的,所以数据库索引基本采用B+树
(3) B+树的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查 找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
简言之B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
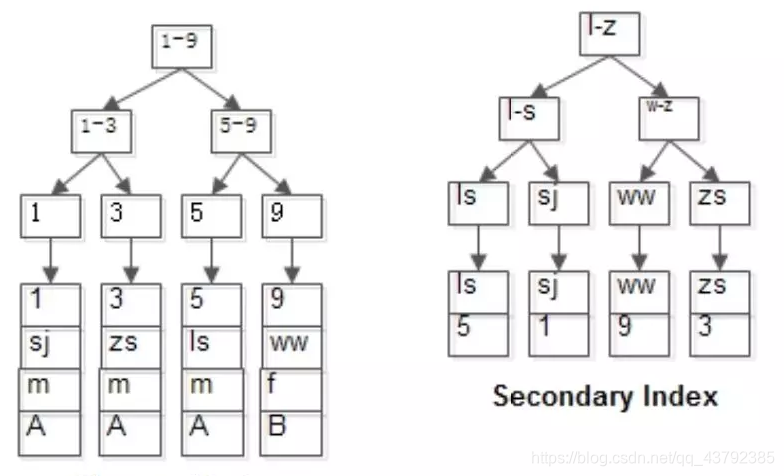
7、MyISAM与InnoDB的索引差异
MyISAM和InnoDB都使用B+树来实现索引:
MyISAM的索引与数据分开存储;
MyISAM的索引叶子存储指针,主键索引与普通索引无太大区别;
InnoDB的聚集索引和数据行统一存储;
InnoDB的聚集索引存储数据行本身,普通索引存储主键;
InnoDB一定有且只有一个聚集索引;
InnoDB建议使用趋势递增整数作为PK,而不宜使用较长的列作为PK。
MyISAM的索引与行记录是分开存储的,叫做非聚集索引(UnClustered Index):
有连续聚集的区域单独存储行记录;主键索引的叶子节点,存储主键,与对应行记录的指针;普通索引的叶子结点,存储索引列,与对应行记录的指针。主键索引与普通索引是两棵独立的索引B+树,通过索引列查找时,先定位到B+树的叶子节点,再通过指针定位到行记录。
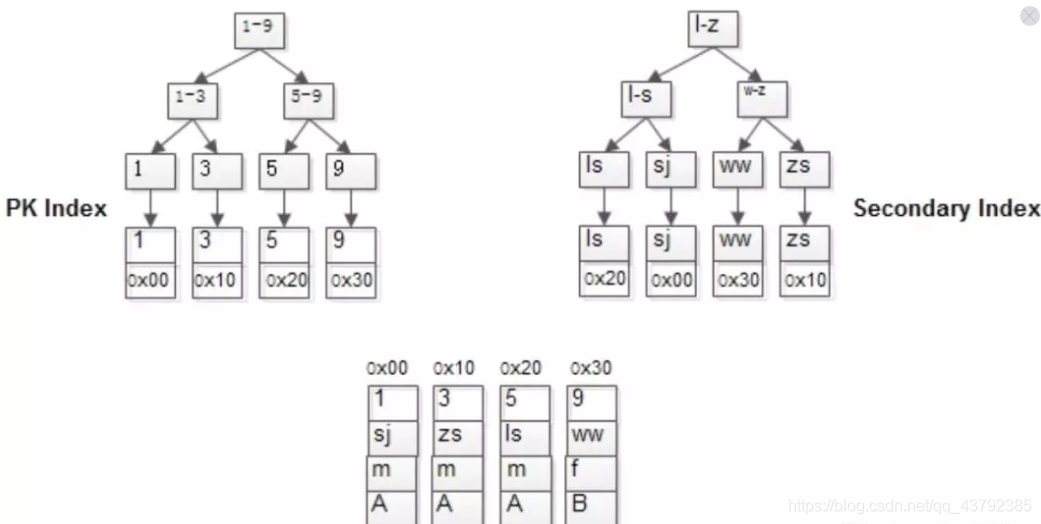
InnoDB的主键索引与行记录是存储在一起的,故叫做聚集索引(Clustered Index):
没有单独区域存储行记录;主键索引的叶子节点,存储主键,与对应行记录(而不是指针),因为这个特性,InnoDB的表必须要有聚集索引:
1)如果表定义了PK,则PK就是聚集索引;
2)如果表没有定义PK,则第一个非空unique列是聚集索引;
3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
聚集索引,也只能够有一个,因为数据行在物理磁盘上只能有一份聚集存储。
InnoDB的普通索引可以有多个,它与聚集索引是不同的:普通索引的叶子节点,存储主键(也不是指针)。主键注意点:
1)不建议使用较长的列做主键,例如char(64),因为所有的普通索引都会存储主键,会导致普通索引过于庞大;
2)建议使用趋势递增的key做主键,由于数据行与索引一体,这样不至于插入记录时,有大量索引分裂,行记录移动。