背景
在优化慢接口的时候,遇到一个问题,在通过索引查询数据库表的时候根据时间区间去扫描表的时候,开始时间时表扫描的其实位置吗?或者说根据时间日期B+索引能一次性定位到具体的时间位置吗?是的不能。那为什么不能呢? 接下来我们来看看b+树索引的底层数据结构。
InnoDB索引概述
- innoDB存储引擎支持的索引有:
B+树索引
全文索引
哈希索引
- 在这需要注意的是InnoDB存储引擎支持的hash索引是自适应的,innoDB会根据表的情况自动生成hash索引,不能人为的干预是否在一张表中生成hash索引。
- B+树索引就是传统意义上的索引,底层数据结构就是根据平衡点二叉树数据结构演化而来,但是他并不是一个二叉树,之所以其中的B指的是Balance而不是binary。
- 还有一个比较容易忽略的问题就是B+树索引只能定位到所在行的数据页,而不能定位到具体的数据value值。
B+树的数据结构和算法
-
检索的算法是二分查找法,使用二分查找法的前提条件是有序的排列,在查找过程中进行折半查找(这里不细说了)。
-
二叉查找树,左子树的键值总是小于根的键值,右子树的键值总是大于根节点。因此他的中序遍历可以得到建值的排序输出。但是在实际情况中会遇到一个极端情况,那就是所有的右子树大于根节点,且都偏向了右子树如下图。拿这种情况就很特殊了,他通过二分查找和顺序查找的时间复杂度一样。

-
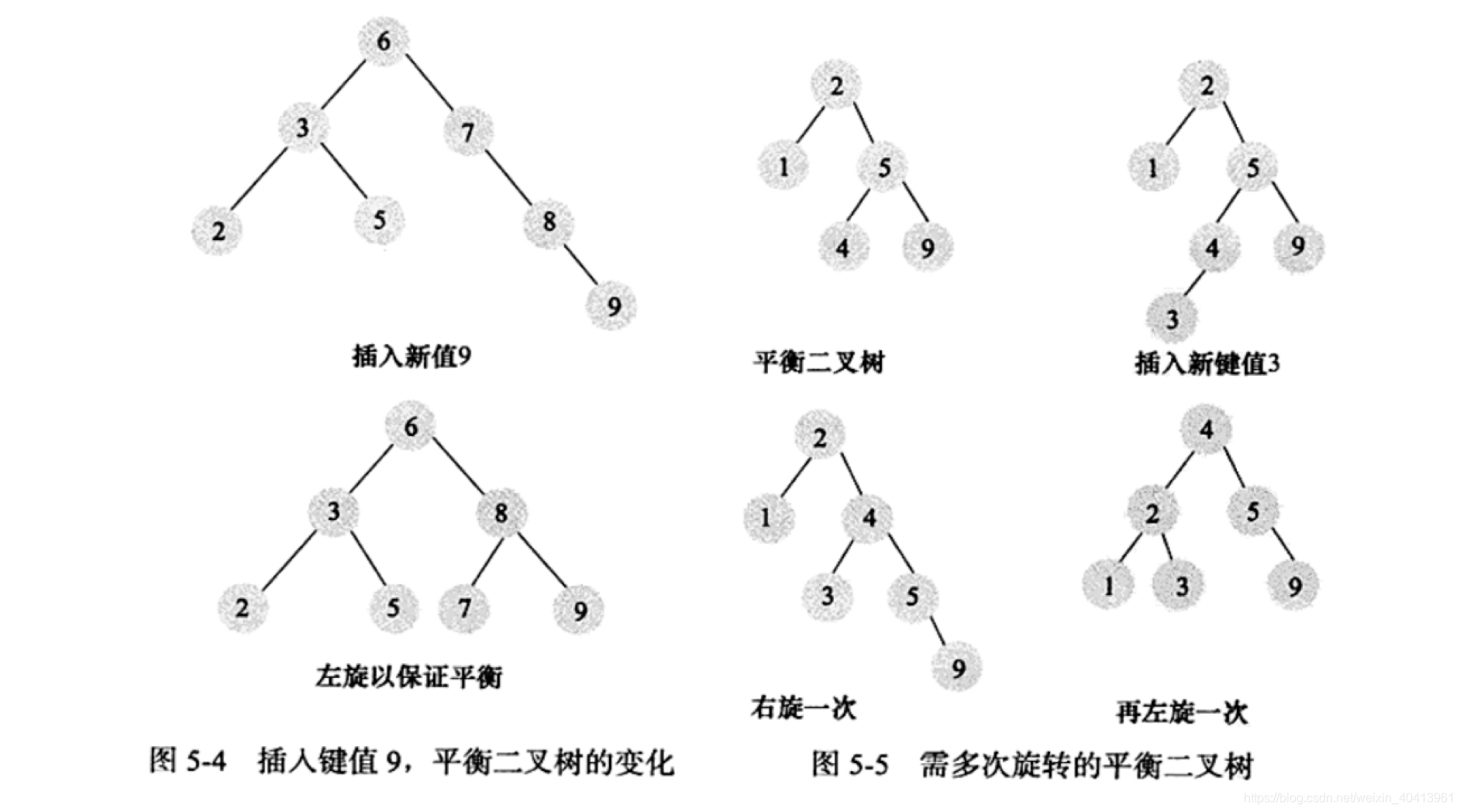
平衡二叉树AVL树,符合二叉查找树的定义的是两个子树间高度差最大为1。平衡二叉树查询速度是很快,但是维护一个平衡二叉树是复杂的。在某种情况下需要通过对树的旋转而达到平衡。
-
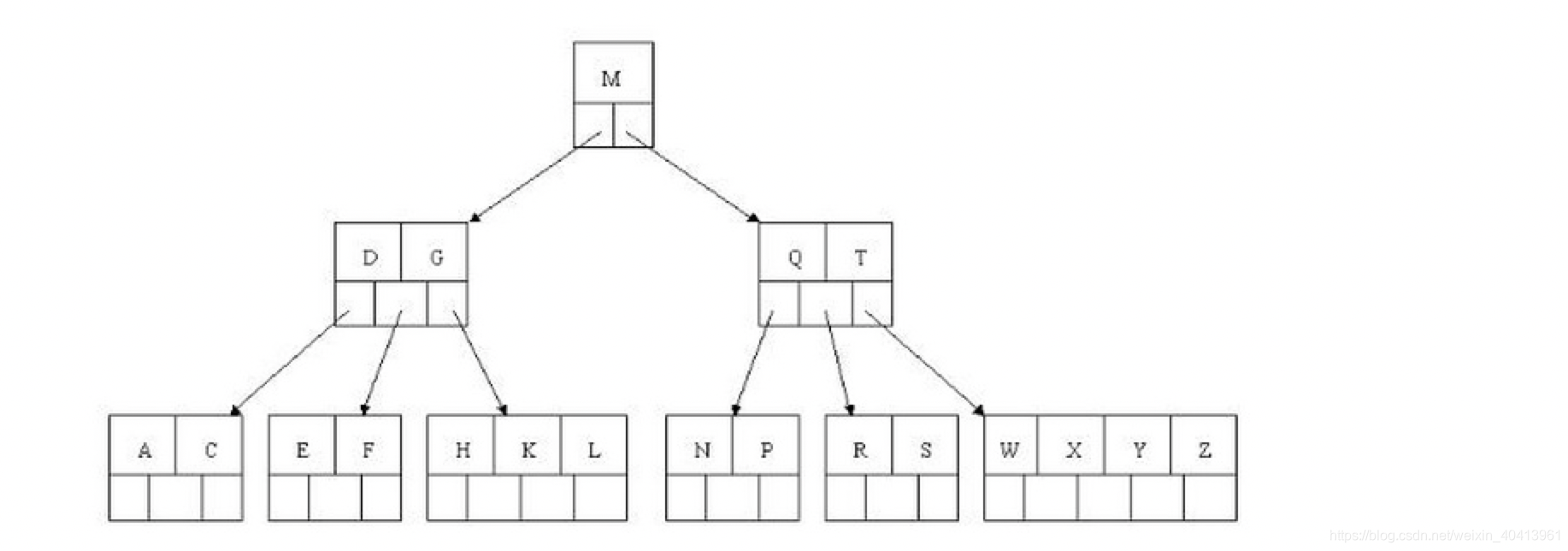
B树 (多路查找树)B树的由来很明确,当我们计算机在处理一个大于内存的数据的时候那该怎么办,那就只能借助磁盘来处理了。通过多次IO磁盘来进行查找数据,然后分批处理。这个时候也就有了B树这个数据结构。可想而知使用AVL树的话由于其一个节点只能存储一个元素,在元素非常多的时候导致树层非常的高,还有树的度也非常的大,子树也非常的多。导致IO次数非常的频繁。于是多路查找树的每个子节点都可以有大于两个孩子的节点,且每一个节点可以存储多个元素。且元素间存在某种特定的排序关系。 其中树的子节点数和可以存储的元素数是很重要的。其中又有一个概念就是节点最大的孩子数目称为B树的阶
-
-
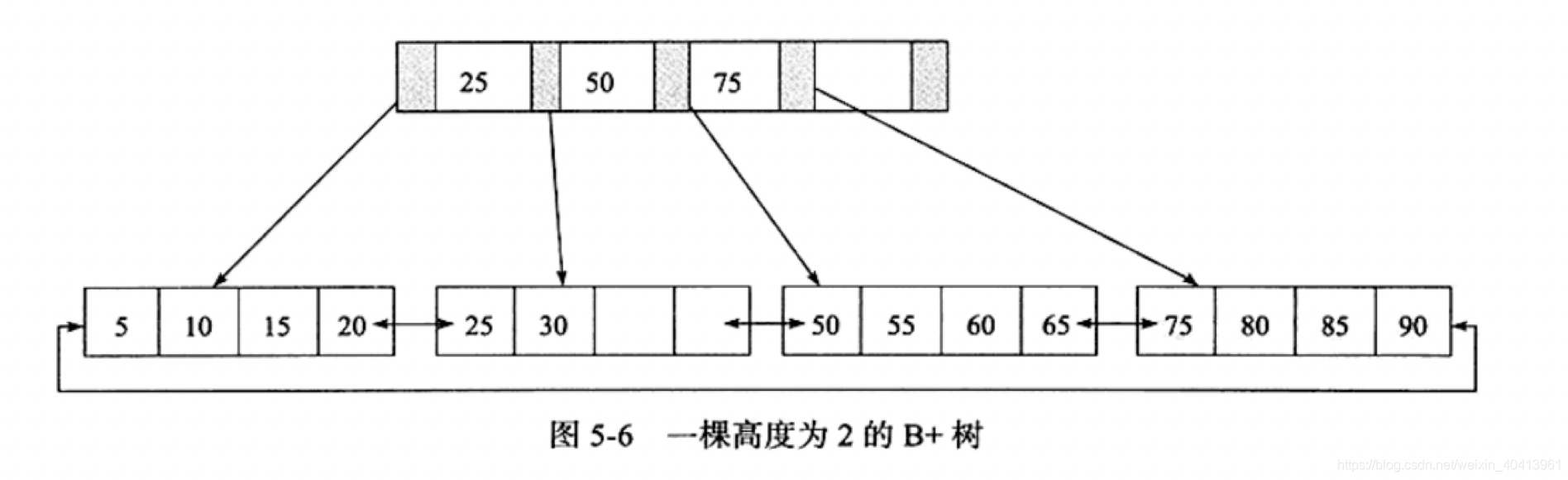
B+树是由B树和索引顺序访问方法演化而来,此时B+树已经和树的数据结构的关系不是很大了。在B树中每一个元素只能出现一次,有可能在叶子节点,也有可能在分支节点上,但是在B+树中 ,出现在分支节点中的元素会被当作他们在该分支节点位置的中序后继者(叶子结点)中再次列出。并且每一个叶子结点都会保存一个指向后一叶子节点的指针。下图为B+树
B+树索引的类别
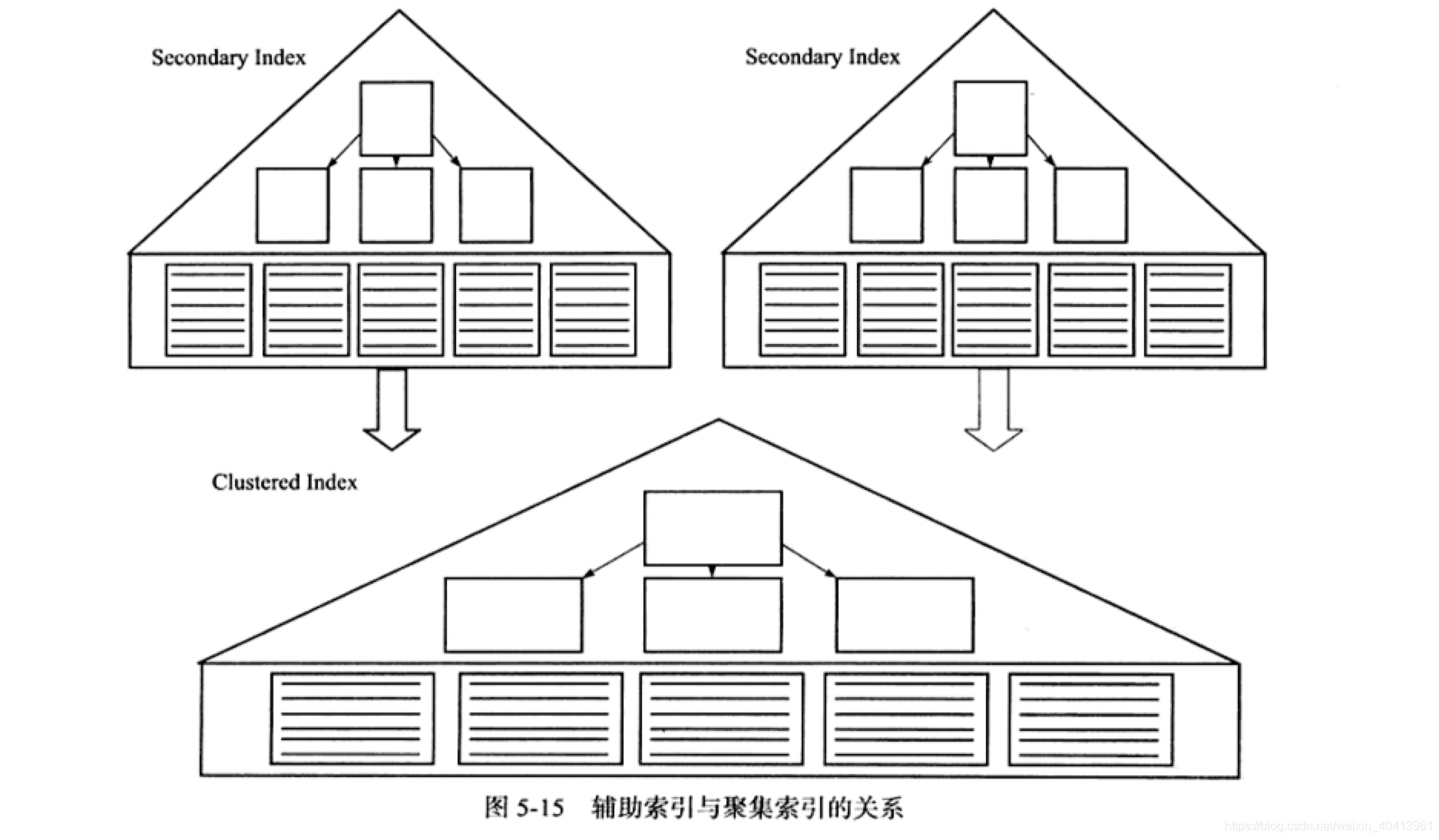
- B+树索引可以分为聚集索引和辅助索引。其聚集索引和辅助索引的区别在于叶子结点是否存放的是一整行的数据信息。
聚集索引
- 根据表的主键构造一棵B+树同时叶子结点存放的为整张表的行记录。也称每个叶子结点的数据为数据页。由于实际的数据页只能按照一棵B+树进行排序因此每张表都只有一个聚集索引。一般SQL的优化器优选选择聚集索引,因为他拥有整行的数据,也就是避免回表查询。
非聚集索引
- 叶子结点不包含行记录,包含对应索引创建的建值外还有一个book’mark,该书签用来告诉innoDB存储引擎哪里可以找到与索引相对应的行数据。也就是聚集索引键值
- 非聚集索引也就是我们平时创建的普通索引,如单列索引,符合索引等
innoDB对索引的管理
- 当我们想查看我们表中索引的信息的时候,我们就可以使用命令:
SHOW INDEX FROM tablename
- 每列的含义
| 列名 | 含义 |
|---|---|
| Table | 索引所在的表名 |
| Non_unique | 非唯一索引 |
| key_name | 索引的名字 |
| Seq_in_index | 索引中该列的位置 |
| Column_name | 索引该列的名称 |
| Collation | 列以什么方式存储在索引中。可以是A或BULL。B+树索引总是A,级排序 |
| Cardinality | 非常关键的值,表示所以中唯一的值的的估计值。值越大越能说明这个缩阴的区分度很高 |
| SUb_part | 是否列的部分被索引。如果索引整个列那这个字段应为null |
| Packed | 关键字如何被压缩,如果没有压缩,就为null |
| Null | 是否索引的列含有NULL值,相对来说含有NULL值索引的性能能欠缺一点点 |
| Index_type | 索引的类型,innoDB只支持B+树索引是Btree |
| Comment | 注释 |
- CArdinaility的值非常重要,优化器在选择索引的时候会参考本值。但是由于本值是通过采样计算得来的,所以也有不准确的时候,所以在优化索引的时候可以通过命令
ANALYZE TABLE tablename
进行重新矫正参数
总结
- 通过对innoDB的索引的了解,哪我们刚开始的问题已经很明显地解决了。不会直接定位,会通过二分查找定位到数据页,数据页进行遍历查找得到对应的具体位置进行顺序查找得到这一个区间。
- innoDB的索引都是B+Tree索引,
- B+树为磁盘读取而生,他是由B树索引演化而来的,BTree是通过AVL树演化而来的
- innoDB的B+树索引分为聚集索引和非聚集索引,聚集索引每个表只有一个,非聚集索引可以有多个。
参考
《innoDB技术内幕》
《大话数据结构》