1、B+树基本概念
B+树的语言定义比较复杂,简单的说是为磁盘存取设计的平衡二叉树
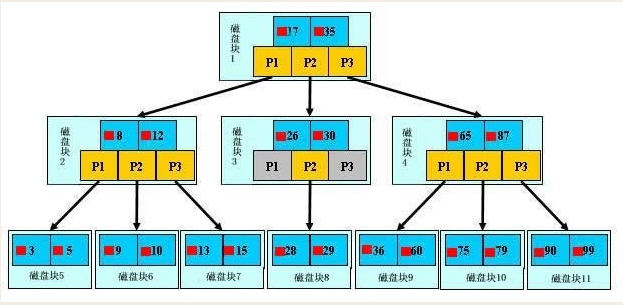
网上经典图,黄色p1 p2 p3代表指针,蓝色的代表磁盘,里面包含数据项,第一层17,35,p1就代表小于17的,p2就代表17-35之间的,p3就代表大于35的,可是需要注意的是,第三层才是真实的数据,17、35都不是真实数据,只是用来划分数据的!
2、为什么使用B+树
B+树有什么好处我们非要使用它呢?那就先要来看看mysql的索引
2.1mysql索引
试想一下在mysql中有200万条数据,在没有建立索引的情况下,会全部进行扫描读取,这个时间消耗是非常恐怖的,而对于大型一点的网站来说,达到这个数据量很容易,不可能这样去设计
在我们创建数据库表的时候,大家都知道一个东西叫做主键,一般来讲数据库会自动在主键上创建索引,这叫做主键索引,来看看索引的分类吧
a.主键索引:int优于varchar
b.普通索引(INDEX):最基本的索引,没有限制,加速查找
c.唯一索引(UNUQUE):听名字就知道,要求所有类的值是唯一的,但是允许有空值
d.组合索引:
1 CREATE INDEX name_age_address_Index ON `student`(`name`, `age`, `address`);
在这里实际上包含三个索引,说到组合索引,一定要讲最左前缀原则
最左前缀原则:
我们现在创建了索引x,y,z,Index:(x,y,z),只会走x,xy,xyz的查询,例如:
1 select * from table where x='1' 2 select * from table where x='1' and b='1' 3 select * from table where x='1' and b='1' and c='1'
如果是x,z,就只会走x,注意一种特殊情况,select * from table where x='1' and y>'1' and z='1',这里只会走xy,因为在经历xy的筛选后,z不能保证是有序的,可索引是有序的,因此不会走z
e.全文索引(FULLTEXT):用于搜索内容很长的文章之类的很好用,如果创建普通的索引,在遇到 like='%xxx%'这种情况索引会失效
1 ALTER TABLE tablename ADD FULLTEXT(col1, col2) 2 SLECT * FROM tablename WHERE MATCH(col1, col2) AGAINST(‘x′, ‘y′, ‘z′)
这样就可以将col1和col2里面包含x,y,z的记录全部取出来了
索引的删除:DORP INDEX IndexName ON `TableName`
索引的优缺点:
1、在数据量特别庞大的时候,建立索引有助于我们提高查询效率
2、在操作表的时候,维护索引会增加额外开销
3、不泛滥使用索引,创建多了索引文件会膨胀很快
2.2B+树的优点
了解上面的模型后,试想一下,200W条数据,假如没有建立索引,会全部进行扫描,B+树仅仅用三层结构可以表示上百万的数据,只需要三次I/O!这提升是真的巨大啊!
因为B+树是平衡二叉树,在不断的增加数据的时候,为了保持平衡可能需要做大量的拆分操作,因此提供了旋转的功能,不知道旋转建议去补一下树的基础知识
B+树插入动画(来自https://www.cnblogs.com/vincently/p/4526560.html)

3、索引优化
1、最佳左前缀原则
2、不要在索引的列上做操作
3、like会使索引失效变成全表扫描
4、字符串不加单引号会导致索引失败
5、减少使用select *

参照这里,写的很好 https://www.cnblogs.com/zhaobingqing/p/7071331.html
总结:
sql语句怎么用,没有规定必须怎么查,对于数据量小,有时候不需要新建立索引,根据一定的实际情况来考虑