一。B-树 : 一种多路搜索树(并不是二叉树)
- 非叶子节点最多可以有大于M个儿子; 且M > 2
- 根节点的儿子数为[2, M]
- 根节点之外的非叶子节点的儿子数为[M/2, M]
- 每个节点存放至少M/2 - 1 (取上整) 和之多M-1个关键字;(至少2个关键字)
- 非叶子节点的关键字个数=指向儿子的指针个数-1
- 非叶子节点的关键字:K[1], K[2], … , K[M-1]; 且K[i] < K[i+1]
- 非叶子节点的指针: P[1], P[2], … , P[M]; 其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
如:M=3的B-树如下图:
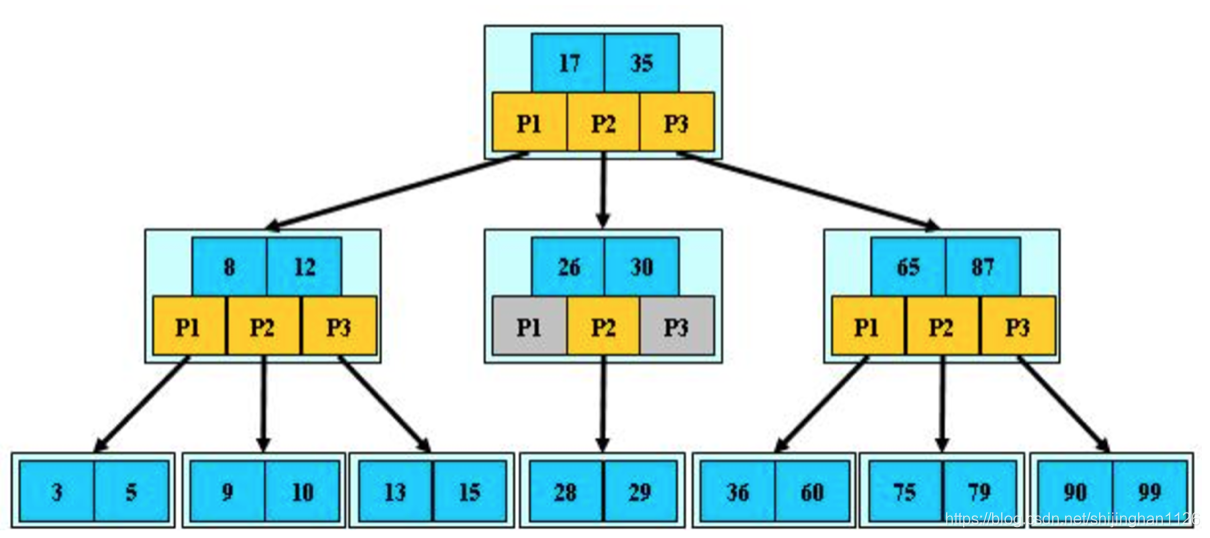
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
二。B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
当M=3时,B+树如下图:
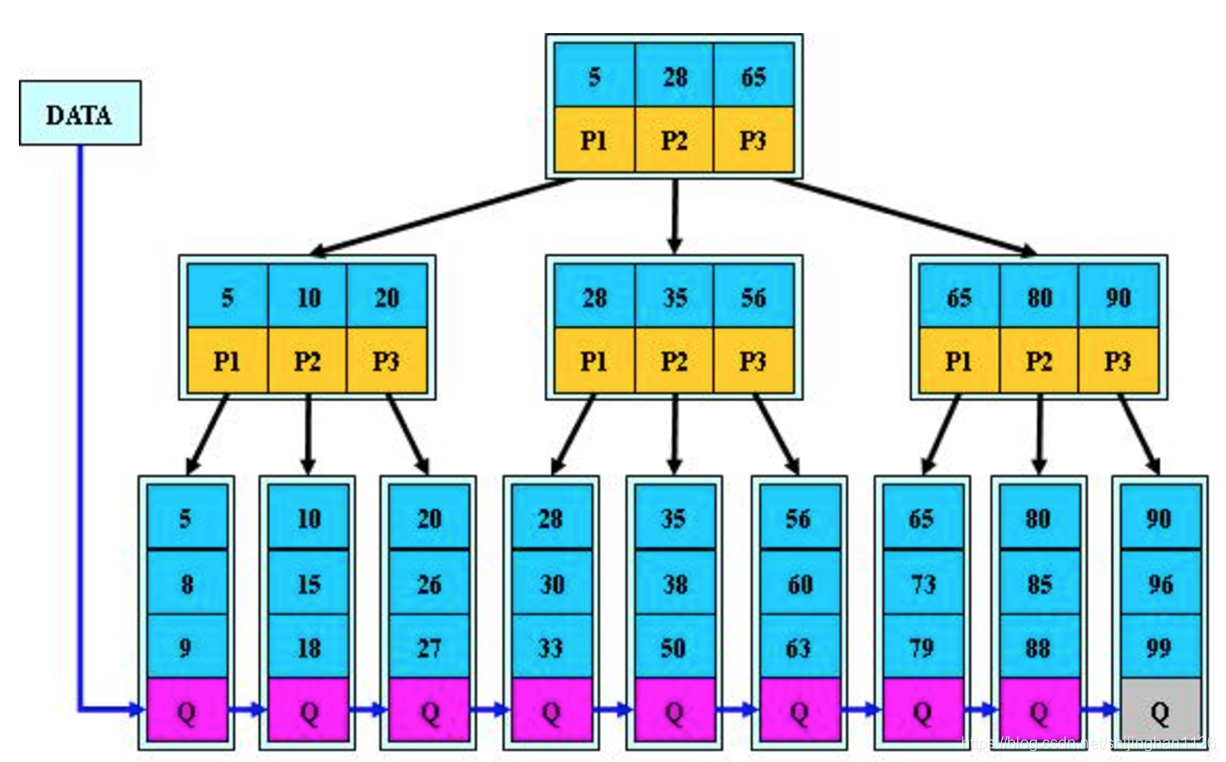
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
三。MySQL中的索引
MySQL为什么使用B+Tree来做索引?
一般来说,索引本身占用空间也很大,不能全部存储在内存中,因此索引往往以文件的形式存储在磁盘上。这样,索引查找的过程就要产生磁盘IO, 相比对内存的存取,磁盘IO存取的消耗要高几个数量级。所以评价一个数据结构作为所有的优劣主要看在查找过程中磁盘IO操作次数的时间复杂度。换句话说,索引要尽量减少查找过程中磁盘IO的存取次数。
1)内存读过程:内存由一系列的存储单元组成,每个单元存储固定大小的数据,且有一个唯一的地址。当读内存时,将地址放到地址总线上传给内存,内存解析信号后定位到存储单元,然后把该存储单元上的数据放到数据总线上,回传。
2)内存写过程:系统将要写入的数据和单元地址分别放到数据总线和地址总线上,内存读取这两个总线的内容,做相应的写操作。
3)总结:内存的存取效率,跟次数相关:先读取A数据还是后读取A数据不会影响存取效率。
1)磁盘存取:而磁盘存取却不同:磁盘IO设计机械操作。磁盘是由大小相同且同轴的圆形盘片组成,磁盘可以转动(各个磁盘必须同时转动)。磁盘的一侧有磁头支架,磁头支架固定了一组磁头,每个磁头负责存取一个磁盘的内容。磁头不同,磁盘转动,但磁臂可以前后动,用于读取不同磁道上的数据。磁道就是以盘点为中心划分出来的一些列同心环。磁道又划分为一个个小段,叫扇区,是磁盘的最小存储单元。
磁盘读取时,系统将数据逻辑地址传给磁盘,磁盘的控制电路会解析出物理地址,即哪个磁道哪个扇区。于是磁头需要前后移动到对应的磁道,这个过程消耗的时间叫寻道时间,然后磁盘选择将对应的扇区转到磁头下,消耗的时间叫做旋转时间。所以,适当的操作顺序和数据存放可以减少磁道时间和旋转时间。
为了尽量减少IO操作,磁盘读取每次都会预读,大小通常为页的整数倍,即使只需要读取一个字节,磁盘也会读取一页的数据(通常为4K)放入内存,内存与磁盘以页为单位交换数据。因为局部性原理认为,通常一个数据被用到,其附近的数据也会立马被用到。
B-Tree: 如果一次检索需要访问4个节点,数据库系统设计者利用磁盘预读原理,把节点的大小设计为一个页,那么读取一个节点只需要一次IO操作,完成这次检索操作,最多需要3次IO(根节点常驻内存)。数据记录越小,每个节点存放的数据就越多,树的高度也就越小,IO操作就少了,检索效率也就上去了。
B+Tree: 非叶子节点只存key, 大大地减少了非叶子节点的大小,那么每个节点就可以存放更多的记录,树更矮了,IO操作更少了,所以B+Tree可以比B-Tree获得更高的性能。