Minimum Class Confusion for Versatile Domain Adaptation
关键词:域适应(Domain Adaptation,DA)
本篇论文出自ECCV 2020《Minimum Class Confusion for Versatile Domain Adaptation》[^1]
1 动机阐明
现有的DA方法往往针对特定的问题进行设计,对于特定的场景表现不佳。本文设计了一种多功能域适应,旨在一个方法不经过的境况下处理多种DA问题,具体如下图所示:
- Unsupervised Domain Adaptation (UDA);
- Partial Domain Adaptation (PDA);
- Multi-Source Domain Adaptation (MSDA);
- Multi-Target Domain Adaptation (MTDA);
- Multi-Source Partial Domain Adaptation (MSPDA);
- Multi-Target Partial Domain Adaptation (MTPDA)
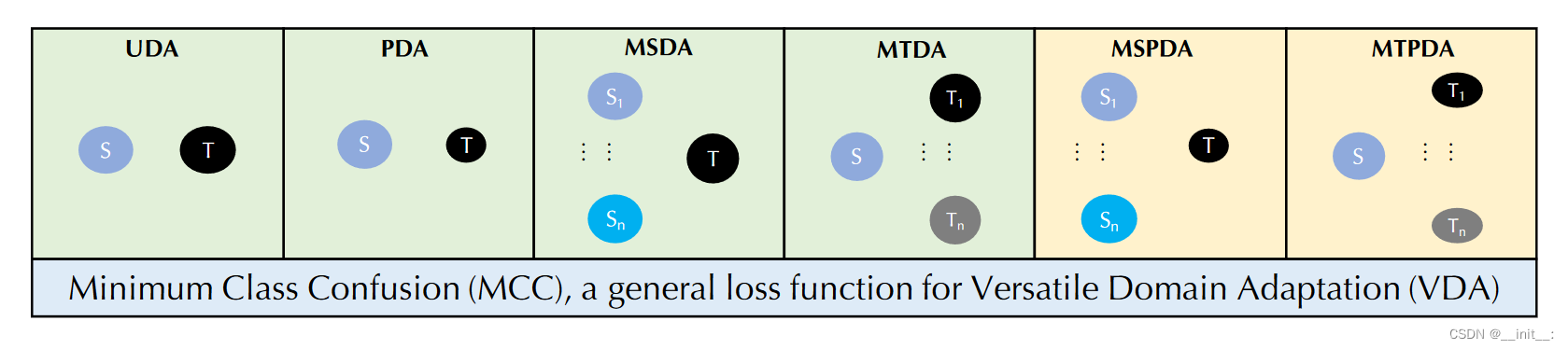
这里简单说一下个人的理解:常规的UDA方法都在feature space空间上做文章,但是对于不同的上述问题而言,label space是不同的,不能直接套用。本文的思路就是从class confusion出发,因为类别间的混淆程度无论是在源域还是目标域都是一致的。
类混淆:分类器混淆目标域上正确类和歧义类之间的预测的趋势
2 方法介绍
先引入几个简单符号:
- y i ⋅ \mathbf{y}_{i \cdot} yi⋅:第i行
- y ⋅ j \mathbf{y}_{\cdot j} y⋅j:第j列
- Y i j \mathbf{Y}_{i j} Yij:矩阵 Y \mathbf{Y} Y的第(i,j)个元素
对于 Y ^ = G ( F ( X ) ) ∈ R B × ∣ C ∣ \hat{\mathbf{Y}}=G(F(\mathbf{X})) \in \mathbb{R}^{B \times |C|} Y^=G(F(X))∈RB×∣C∣,其中 B B B为batch size, ∣ C ∣ |C| ∣C∣为源域数据类别数, F F F为特征提取器, G G G为分类器。这里可以理解 Y ^ \hat{\mathbf{Y}} Y^为分类器对于一个batch中样本的预测结果。
概率缩减
由于我们更希望关注于分类器的预测信息,使得预测结果不会偏向于其中几类,这里采用了temperature rescaling:
Y ^ i j = exp ( Z i j / T ) ∑ j ′ = 1 ∣ C ∣ exp ( Z i j ′ / T ) \widehat{Y}_{i j}=\frac{\exp \left(Z_{i j} / T\right)}{\sum_{j^{\prime}=1}^{|\mathcal{C}|} \exp \left(Z_{i j^{\prime}} / T\right)} Y
ij=∑j′=1∣C∣exp(Zij′/T)exp(Zij/T)
其中, Y ^ i j \hat{Y}_{ij} Y^ij表示第 i i i个样本属于 j j j类别的概率。 Z Z Z为分类器输出的结果。 T T T为温度系数,可作为超参进行调整。显然当 T = 1 T=1 T=1时,上式即为为softmax函数。
类相关性
由于 Y ^ i j \hat{Y}_{ij} Y^ij揭示了第i个实例和第j个类之间的关系,文中将两个类 j j j和 j ′ j^′ j′之间的类相关性定义为
C j j ′ = y ^ ⋅ j ⊤ y ^ ⋅ j ′ C_{jj^′}=\hat{\mathbf{y}}_{\cdot j}^{\top}\hat{\mathbf{y}}_{\cdot j^′} Cjj′=y^⋅j⊤y^⋅j′
而这也是对类混淆的粗略估计。直观上来说, y ^ ⋅ j \hat{\mathbf{y}}_{\cdot j} y^⋅j表示每个batch中 B B B个样本来自第 j j j类的概率,而这种类别相关性衡量分类器同时将 B B B个样本分为第 j j j类和第 j ′ j^′ j′类的概率。值得一提的是,这样定义的好处在于,对于一个具有较高置信度的错误预测,对应的类相关性仍然较低。也就是说,高置信度的错误预测对类别相关性的影响可以忽略不计。
不确性度量
由于不同类别的样本给出的信息量是不同的,因而对于类相关性的贡献也是不同的,对于一个样本 i i i,文中采用信息熵作为其不确定性度量:
H ( y ^ i ⋅ ) = − ∑ j = 1 ∣ C ∣ Y ^ i j log Y ^ i j H(\hat{\mathbf{y}}_{i \cdot})=-\sum_{j=1}^{|C|} { \hat{Y}}_{ij} \log{\hat{Y}_{ij}} H(y^i⋅)=−j=1∑∣C∣Y^ijlogY^ij
由于我们更希望得到的是一个概率分布,使得对于具有更大确定性的样本,能够相应给出给更高的预测置信度。这里采用了类似于softmax的处理方式:
W i i = B ( 1 + exp ( − H ( y ^ i . ) ) ) ∑ i ′ = 1 B ( 1 + exp ( − H ( y ^ i ′ . ) ) ) W_{i i}=\frac{B\left(1+\exp \left(-H\left(\widehat{\mathbf{y}}_{i .}\right)\right)\right)}{\sum_{i^{\prime}=1}^{B}\left(1+\exp \left(-H\left(\widehat{\mathbf{y}}_{i^{\prime} .}\right)\right)\right)} Wii=∑i′=1B(1+exp(−H(y
i′.)))B(1+exp(−H(y
i.)))
其中 W i i W_{ii} Wii是量化第 i i i个样本对类混淆建模的重要性的概率, W W W为相应的对角矩阵。这里加1是在做一次Laplace Smoothing,使之形成一个重尾分布( h e a v i e r − t a i l e d heavier-tailed heavier−tailed weight distribution),即能够更突出具有高确信度的样本,同时避免过度惩罚其他样本。为了更好地缩放,每个大小为B的批次中的示例的概率被重新缩放为总和为B,使得每个样本呢的平均权重为1。
由此能够得到类混淆度的一个初步形式:
C j j ′ = y ^ ⋅ j ⊤ W y ^ ⋅ j ′ \mathbf{C}_{j j^{\prime}}=\widehat{\mathbf{y}}_{\cdot j}^{\top} \mathbf{W} \widehat{\mathbf{y}}_{\cdot j^{\prime}} Cjj′=y
⋅j⊤Wy
⋅j′
类正则化
上式还存在一个问题就是,当类别数很多的时候,在一个batch中可能存在样本不均衡问题,这里采用了一种随机游走的策略:
C ~ j j ′ = C j j ′ ∑ j ′ ′ = 1 ∣ C C j j ′ ′ \widetilde{\mathbf{C}}_{j j^{\prime}}=\frac{\mathbf{C}_{j j^{\prime}}}{\sum_{j^{\prime \prime}=1}^{\mid C} \mathbf{C}_{j j^{\prime \prime}}} C
jj′=∑j′′=1∣CCjj′′Cjj′
即如果两个类有较高的类混淆,则有可能从一个类走到另一个(导致错误的分类)。
直观上来看,两个类混淆度较为相似,则得到的 C ~ j j ′ \widetilde{\mathbf{C}}_{j j^{\prime}} C jj′也十分接近。
最小化类混淆度
由于 C ~ j j ′ \widetilde{\mathbf{C}}_{j j^{\prime}} C
jj′已经能够很好的衡量两个类间的混淆度,这里只需要最小化跨类别的混淆度即可(即 j ≠ j ′ j \neq j^{\prime} j=j′),最终得到损失函数的具体形式Minimum Class Confusion(MCC):
L M C C ( Y ^ t ) = 1 ∣ C ∣ ∑ j = 1 ∣ C ∣ ∑ j ′ ≠ j ∣ C ∣ ∣ C ~ j j ′ ∣ L_{\mathrm{MCC}}\left(\widehat{\mathbf{Y}}_{t}\right)=\frac{1}{|\mathcal{C}|} \sum_{j=1}^{|\mathcal{C}|} \sum_{j^{\prime} \neq j}^{|\mathcal{C}|}\left|\widetilde{\mathbf{C}}_{j j^{\prime}}\right| LMCC(Y
t)=∣C∣1j=1∑∣C∣j′=j∑∣C∣∣
∣C
jj′∣
∣
即理想情况下,同一样本不会属于不同类别。而最小化类间混淆度意味着最大化类内混淆度。
参考文献
[^1]:Jin等, 《Minimum class confusion for versatile domain adaptation》.