1. 概述
介绍:去年(2022年)大家都在卷各式各样的view-transfer,到了今年就沉寂了不少,鲜有新的view-transfer提出,也有一些对于行业更加工程实际的paper出来了。这篇文章便是通过从domain-adaption和distillation技术角度去缓解BEV感知方案部署的痛点问题。当训练时的数据分布与实际部署时的训练分布不一致,如白天与黑夜或晴天与雨天,或是训练时使用的传感器数量与部署时使用的数量不一致,便会存在性能下降的情况。这些都是算法量产过程中实际会遇到的问题,而这篇文章从域迁移和知识蒸馏两个角度对这些工程实际问题给出一些启发式的引导。
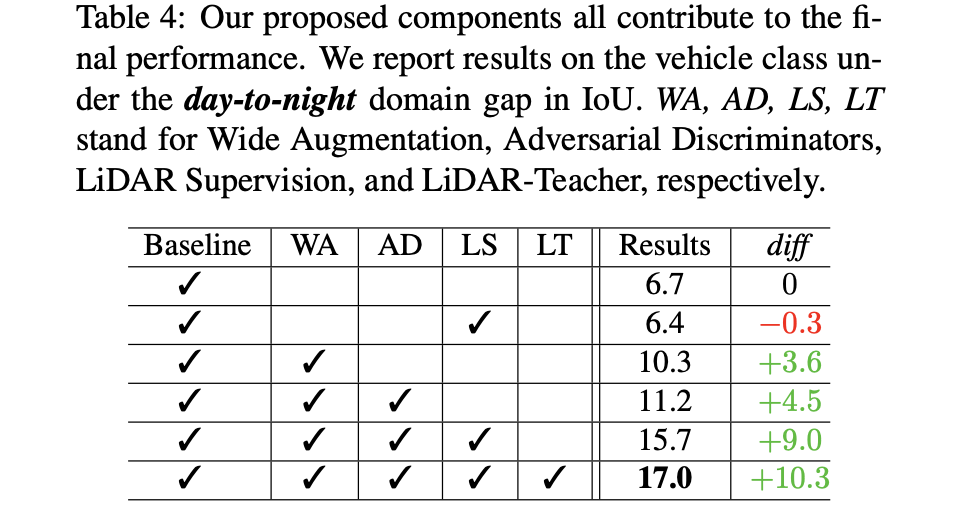
车端感知算法训练和实际部署中可能会存在一些gap,这可能是训练集不完备(不过也很难做到完备)、传感器失效、模型训练和实际部署的平台不一致等原因导致的。在这篇文章中将这些与训练情况不一致的情况划分为cross-domain、cross-modality或是两者的结合,如下图所示:
后续内容将说说如何从上文提到的两个技术角度去缓解这样的实际问题的。
2. 方法设计
2.1 整体架构
文章整体的架构如下图:

在上图中定义了两个网络:由lidar和camera组成的teacher网络,以及只使用camera数据的student网络。这里student网络中BEV特征生成使用的是LSS的那套方案,则其中有显式估计深度的步骤,那么就可以很方便用lidar的数据进行监督。用这两个网络模拟不同工况天气、缺失lidar等情况,并用蒸馏和域迁移实现性能弥补。
2.2 cross model场景
这里teacher和student输入的camera数据是一致的,只是一个有lidar数据输入一个没有,则这里主要使用蒸馏的方式实现信息的传递。这里信息的传递主要在3个层面上:使用lidar显式深度监督、BEV特征蒸馏、感知结果蒸馏。
深度估计监督:
深度估计监督的GT是来自于Lidar数据,这里Lidar数据是通过投影的方式到图像空间,没有备投影到的区域不会参与到loss的计算中,对于那些重复投影的区域那就去均值作为该处的GT了,则这部分的损失为:
L d p ( α ˉ s , α s ) = − ∑ i = 1 H ∑ j = 1 Y ∑ k = 1 N d α s ( i , j , k ) l o g α ˉ s ( i , j , k ) L_{dp}(\bar{\alpha}^s,\alpha^s)=-\sum_{i=1}^H\sum_{j=1}^Y\sum_{k=1}^{N_d}\alpha^s(i,j,k)log\bar{\alpha}^s(i,j,k) Ldp(αˉs,αs)=−i=1∑Hj=1∑Yk=1∑Ndαs(i,j,k)logαˉs(i,j,k)
BEV特征蒸馏:
这部分是对生成的BEV特征进行蒸馏,使用的是L2范数约束。
感知结果蒸馏:
这里采用同深度估计约束中类似的损失函数
L G T ( y ˉ s , y s ) = − ∑ i = 1 H ∑ j = 1 Y ∑ c = 1 C y s ( i , j , c ) l o g y ˉ s ( i , j , c ) L_{GT}(\bar{y}^s,y^s)=-\sum_{i=1}^H\sum_{j=1}^Y\sum_{c=1}^{C}y^s(i,j,c)log\bar{y}^s(i,j,c) LGT(yˉs,ys)=−i=1∑Hj=1∑Yc=1∑Cys(i,j,c)logyˉs(i,j,c)
2.3 cross domain场景
这个发生在student网络的内部,其输入的是两个场景的图片,其中有一个场景是常见的场景,对应另外一个就是不常见的。那么目标就是使得网络在不常见的场景下也能获取不错的感知结果,对此这里采用domain-adapter方法中常用的判别网络作为约束,而且这里采用了多个特征层次的约束,也就是image-view和bev-view层面进行约束。对应网络结构中的 D 1 , D 2 D_1,D_2 D1,D2。
3. 实验结果
文中两种优化方法的效果:
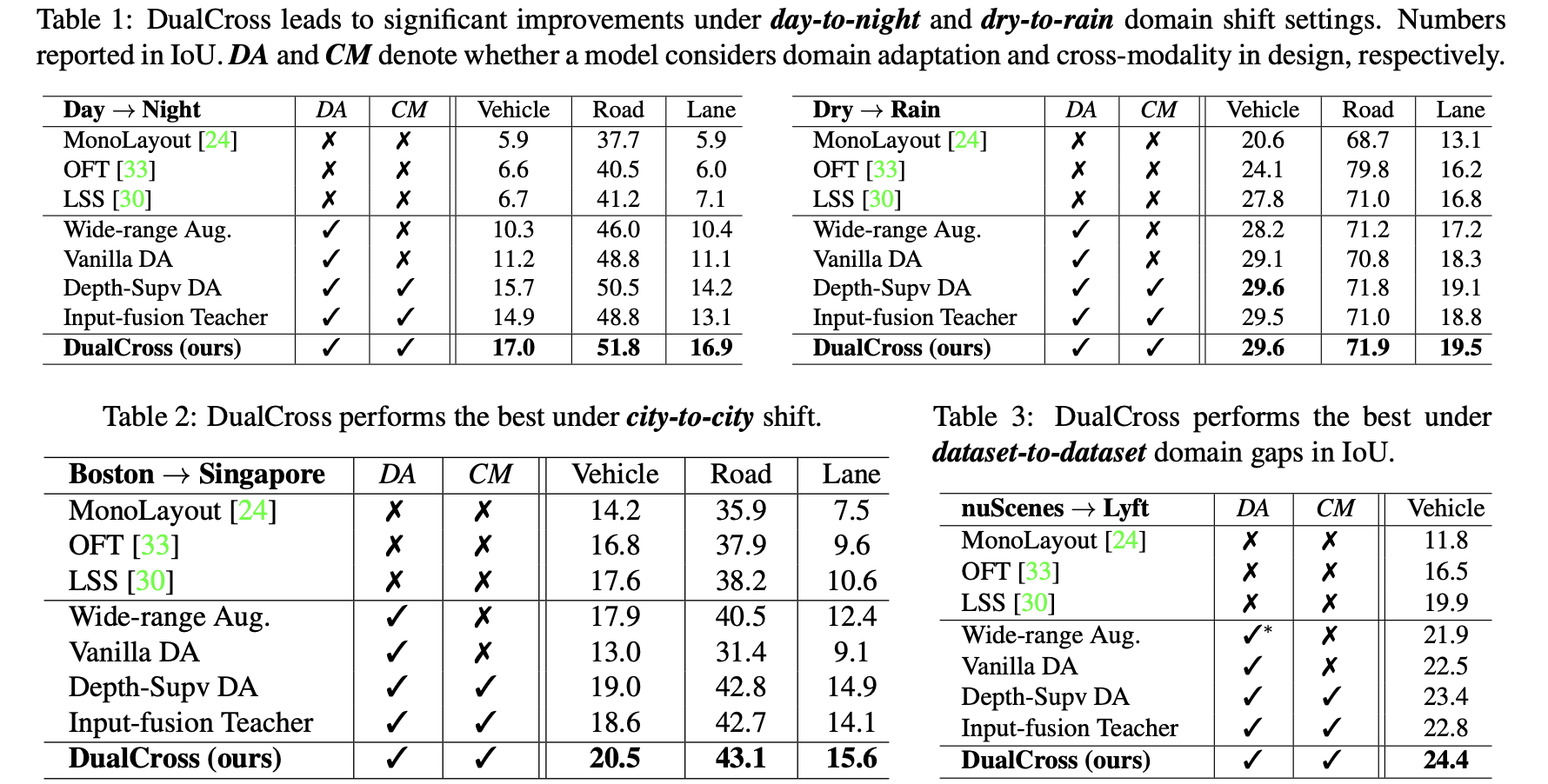
对应到网络中的细节层面,其中的一些模块对性能的影响见下表: