本文提出了一个比较有趣的 Z S D A ZSDA ZSDA(zero-shot domain adaptation) 的学习策略。
- 假如现在我们有两个 U I T ( S t y l e T r a n s f e r ) UIT(Style~Transfer) UIT(Style Transfer) 的任务,
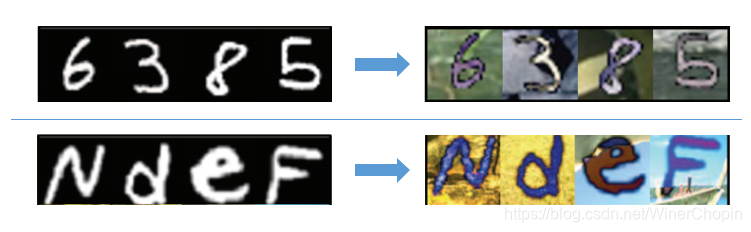
- 原本我们可以构建两个 C y c l e G A N CycleGAN CycleGAN 就可以解决上面的问题,或者把数据混合在一起,训练一个更高鲁棒性的 C y c l e G A N CycleGAN CycleGAN.
- 但实际上,有时候我们并没有右下角的目标域的图像,这时候我们希望基于上面的 g r a y n u m . gray~num. gray num. 和 c o l o r n u m . color~num. color num. 数据集训练一个 U I T UIT UIT 模型,它也能够应用到下面的 g r a y l e t t e r → c o l o r l e t t e r gray~letter \rightarrow color~letter gray letter→color letter,但现实中,本质上仍旧是统计学的深度学习算法并不能有这样的泛化能力。
- 但如果我们知道了 g r a y n u m . ∼ g r a y l e t t e r gray~num.\sim gray~letter gray num.∼gray letter 之间的某种对应关系 A l i g n s Align_s Aligns,那么, c o l o r n u m . ∼ c o l o r l e t t e r color~num.\sim color~letter color num.∼color letter 之间也必然存在某种对应关系 A l i g n t Align_t Alignt。我们可以利用这样的对应关系来作为监督信息,代替缺失的 c o l o r l e t t e r color~letter color letter 数据。因为存在: [ g r a y l e t t e r ] → [ A l i g n s ] → [ g r a y n u m . ] → [ U I T ] → [ c o l o r n u m . ] → [ A l i g n t ] → [ c o l o r l e t t e r ] [gray~letter]\rightarrow [Align_s] \rightarrow [gray~num.]\rightarrow [UIT]\rightarrow[color~num.]\rightarrow[Align_t]\rightarrow[color~letter] [gray letter]→[Aligns]→[gray num.]→[UIT]→[color num.]→[Alignt]→[color letter]
所以,理论上,这两个对应关系的限制是充分的。
1. CoCoGAN
首先,我们需要了解 CoGAN。
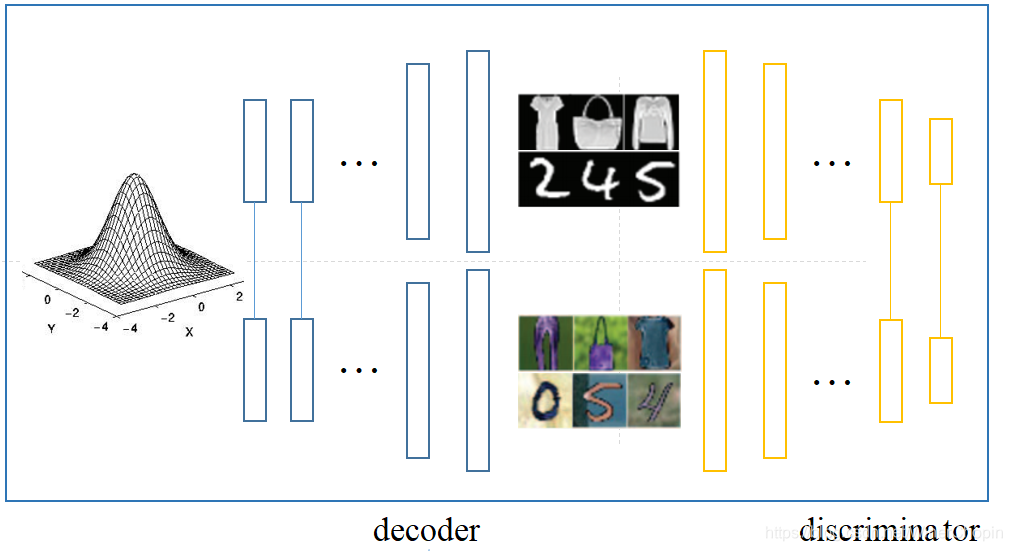
- 其基本思想是,除去样式,两个域在 content 方面是共享的,因此有两个生成器,起始于同一个 content latent space,同时两个网络共享底层(深层特征 content),异于高层(浅层特征 appearance);同样有两个鉴别器,异于底层,共享高层。
- 因此,其目标函数为:
max g 1 , g 2 min f 1 , f 2 V ( f 1 , f 2 , g 1 , g 2 ) ≡ E x 1 ∼ p x 1 [ − log f 1 ( x 1 ) ] + E z ∼ p z [ − log ( 1 − f 1 ( g 1 ( z ) ) ) ] + E x 2 ∼ p x 2 [ − log f 2 ( x 2 ) ] + E z ∼ p z [ − log ( 1 − f 2 ( g 2 ( z ) ) ) ] \max_{g_1,g_2} \min_{f_1,f_2} V(f_1,f_2,g_1,g_2)\equiv \Bbb E_{x_1\sim p_{x_1}}[-\log f_1(x_1)]+\Bbb E_{z\sim p_z}[-\log (1-f_1(g_1(z)))] + \Bbb E_{x_2\sim p_{x_2}}[-\log f_2(x_2)]+\Bbb E_{z\sim p_z}[-\log (1-f_2(g_2(z)))] g1,g2maxf1,f2minV(f1,f2,g1,g2)≡Ex1∼px1[−logf1(x1)]+Ez∼pz[−log(1−f1(g1(z)))]+Ex2∼px2[−logf2(x2)]+Ez∼pz[−log(1−f2(g2(z)))] 其中, g i g_i gi 是生成器/解码器, f i f_i fi 是鉴别器, i = 1 , 2 i=1,2 i=1,2。
其次,我们可以理解 CoCoGAN
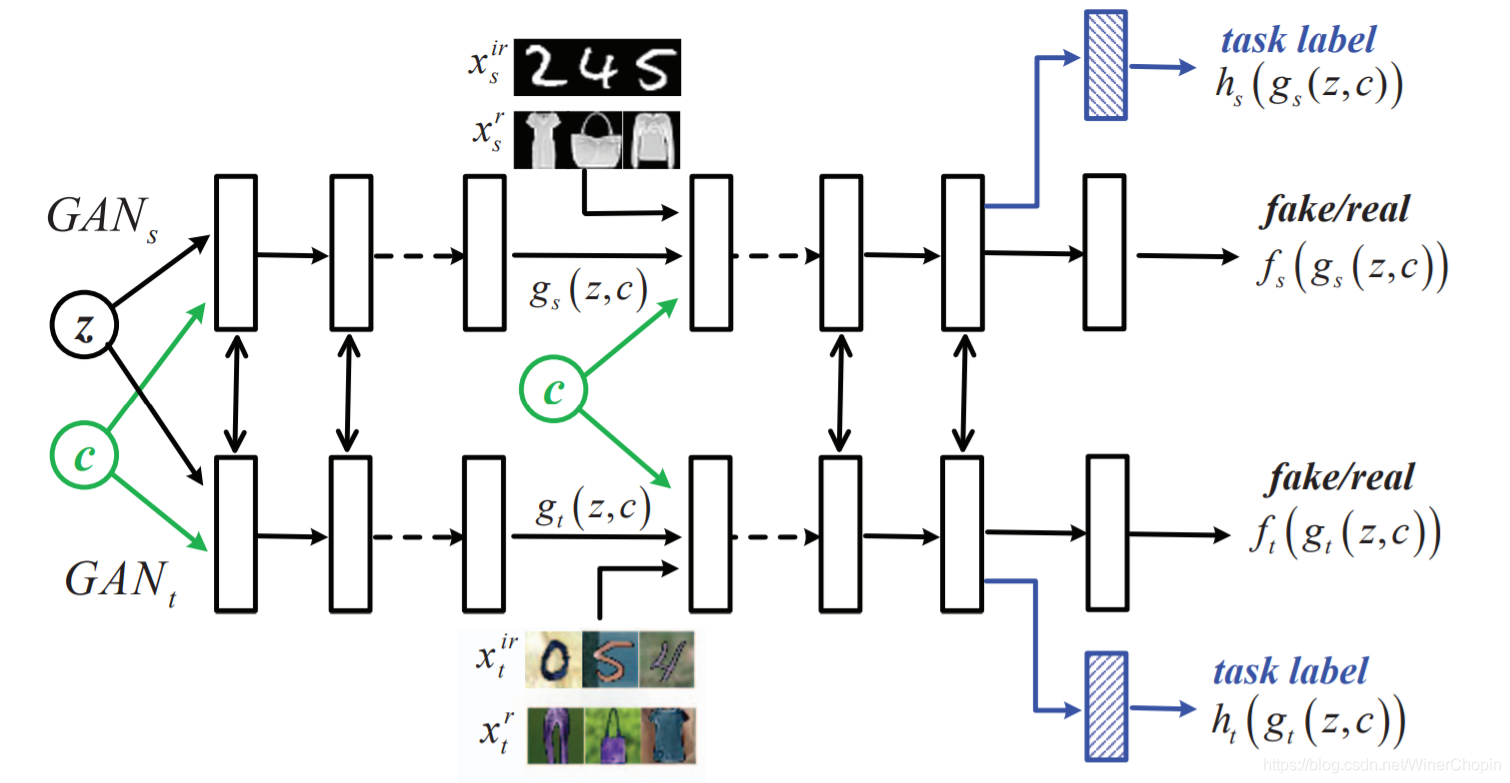
同样的,所谓的 C o n d i t i o n a l Conditional Conditional 是指加了一个 c c c 用于决定让模型处理哪一个任务。
- 我们称 g r a y n u m . → c o l o r n u m . gray~num.\rightarrow color~num. gray num.→color num. 是一个(与目标任务)无关的任务(irrelevant task/ I R IR IR)
- 我们称另一个 g r a y l e t t e r → c o l o r l e t t e r gray~letter\rightarrow color~letter gray letter→color letter 是目标/相关任务(relevant task/ R R R)
- c = 0 c=0 c=0 时,处理 I R IR IR; c = 1 c=1 c=1 时,处理 R R R.
假如我们四个域的图像数据都有: X s i r , X t i r , X s r , X t r {X_s^{ir},X_t^{ir},X_s^r,X_t^r} Xsir,Xtir,Xsr,Xtr,那么可以直接使用 CoGAN 的对抗 loss,即,我们使用
max g s , g t min f s , f t V ( f s , f t , g s , g t ) ≡ E x s ∼ p x s [ − log f s ( x s , c ) ] + E z ∼ p z [ − log ( 1 − f s ( g s ( z , c ) , c ) ) ] + E x t ∼ p x t [ − log f t ( x t , c ) ] + E z ∼ p z [ − log ( 1 − f t ( g t ( z , c ) , c ) ) ] \max_{g_s,g_t} \min_{f_s,f_t} V(f_s,f_t,g_s,g_t)\equiv \Bbb E_{x_s\sim p_{x_s}}[-\log f_s(x_s,c)]+\Bbb E_{z\sim p_z}[-\log (1-f_s(g_s(z,c),c))] + \Bbb E_{x_t\sim p_{x_t}}[-\log f_t(x_t,c)]+\Bbb E_{z\sim p_z}[-\log (1-f_t(g_t(z,c),c))] gs,gtmaxfs,ftminV(fs,ft,gs,gt)≡Exs∼pxs[−logfs(xs,c)]+Ez∼pz[−log(1−fs(gs(z,c),c))]+Ext∼pxt[−logft(xt,c)]+Ez∼pz[−log(1−ft(gt(z,c),c))] 但实际上,第三项 E x t ∼ p x t [ − log f t ( x t , c ) ] E_{x_t\sim p_{x_t}}[-\log f_t(x_t,c)] Ext∼pxt[−logft(xt,c)] 只能取到 c = 0 c=0 c=0,那么这样的训练是不充分的,结果是 g t g_t gt 过分偏向于 g r a y n u m . → c o l o r n u m . gray~num.\rightarrow color~num. gray num.→color num.,对于 c = 1 c=1 c=1 的时候,要么 g t ( z , 1 ) g_t(z,1) gt(z,1) 也是 彩色数字,要么就什么也不是,而不是理想的彩色字母。
因此,我们需要增加新的限制——
2. Representation Alignment
在高层表征中,如 e n c o d e r encoder encoder 和 d e c o d e r decoder decoder 之间。
r s ( X s i r , c = 0 ) ≡ r t ( X t i r , c = 0 ) ⏟ r e a l d a t a ≈ r t ( T ( X s i r ) , c = 0 ) ⏟ f a k e d a t a \underbrace{r_s(X_s^{ir},c=0) \equiv r_t(X_t^{ir},c=0)}_{real~data} ~~~~~~~~\approx \underbrace{r_t(T(X_s^{ir}),c=0)}_{fake~data} real data
rs(Xsir,c=0)≡rt(Xtir,c=0) ≈fake data
rt(T(Xsir),c=0) r s ( X s r , c = 1 ) ≡ r t ( X t r , c = 1 ) ⏟ r e a l d a t a ≈ r t ( T ( X s r ) , c = 1 ) ⏟ f a k e d a t a \underbrace{r_s(X_s^{r},c=1) \equiv r_t(X_t^{r},c=1)}_{real~data} ~~~~~~~~ \approx \underbrace{r_t(T(X_s^{r}),c=1)}_{fake~data} real data
rs(Xsr,c=1)≡rt(Xtr,c=1) ≈fake data
rt(T(Xsr),c=1) 假如我们认为下面的对齐存在: r s ( X s i r , c = 0 ) ∼ r s ( X s r , c = 1 ) r_s(X_s^{ir},c=0) \sim r_s(X_s^{r},c=1) rs(Xsir,c=0)∼rs(Xsr,c=1) 则必然会有: r t ( X t i r , c = 0 ) ∼ r t ( X t r , c = 1 ) r_t(X_t^{ir},c=0) \sim r_t(X_t^{r},c=1) rt(Xtir,c=0)∼rt(Xtr,c=1) 即在两个源域 I R S IR_S IRS 和 R S R_S RS 以某种方式对齐,则其对应的目标域 I R T IR_T IRT 和 R T R_T RT 必定也以某种方式对齐。
但是由于我们没有: r t ( X t r , c = 1 ) r_t(X_t^{r},c=1) rt(Xtr,c=1),所以需要近似地在合成图像 f a k e d a t a fake~data fake data 上去对齐
那如果我们现在希望用 t a s k c l a s s i f i e r \rm task~classifier task classifier 去表达这种限制,可以有:
令 l ( . ) l(.) l(.) 为 logistics 函数
在源域上有: max h s L s ≡ E x s ∼ p X s i r [ l ( h s ( x s ) ) ] + E x s ∼ p X s r [ l ( h s ( x s ) ) ] ⏟ A l i g n : r e a l d a t a i n S + E z ∼ p z [ l ( h s ( g s ( z , c = 0 ) ) ) ] + E z ∼ p z [ l ( h s ( g s ( z , c = 1 ) ) ) ] ⏟ A l i g n : f a k e d a t a i n S \max_{h_s} L_s \equiv \underbrace{ {\Bbb E}_{x_s\sim p_{X_s^{ir}}}[l(h_s(x_s))] + {\Bbb E}_{x_s\sim p_{X_s^{r}}}[l(h_s(x_s))] }_{ {\rm Align}:~real~data~in~S} + \underbrace{ {\Bbb E}_{z\sim p_z}[l(h_s(g_s(z,c=0)))] + {\Bbb E}_{z\sim p_z}[l(h_s(g_s(z,c=1)))]}_{ {\rm Align}:~fake~data~in~S} hsmaxLs≡Align: real data in S Exs∼pXsir[l(hs(xs))]+Exs∼pXsr[l(hs(xs))]+Align: fake data in S Ez∼pz[l(hs(gs(z,c=0)))]+Ez∼pz[l(hs(gs(z,c=1)))] 同时,在目标域上有: max h t L t ≡ E x t ∼ p X t i r [ l ( h t ( x t ) ) ] ⏟ A l i g n : r e a l d a t a i n T + E z ∼ p z [ l ( h t ( g t ( z , c = 0 ) ) ) ] + E z ∼ p z [ l ( h t ( g t ( z , c = 1 ) ) ) ] ⏟ A l i g n : f a k e d a t a i n T \max_{h_t} L_t \equiv \underbrace{ {\Bbb E}_{x_t\sim p_{X_t^{ir}}}[l(h_t(x_t))]}_{ {\rm Align}:~real~data~in~T} + \underbrace{ {\Bbb E}_{z\sim p_z}[l(h_t(g_t(z,c=0)))] + {\Bbb E}_{z\sim p_z}[l(h_t(g_t(z,c=1)))]}_{ {\rm Align}:~fake~data~in~T} htmaxLt≡Align: real data in T Ext∼pXtir[l(ht(xt))]+Align: fake data in T Ez∼pz[l(ht(gt(z,c=0)))]+Ez∼pz[l(ht(gt(z,c=1)))]
这里有个疑问,既然在这里有 a × b ≤ a 2 + b 2 2 ≤ a + b 2 a\times b \le { {a^2+b^2}\over{2}} \le { {a+b}\over{2}} a×b≤2a2+b2≤2a+b,不应该是最大化 a b ab ab 则必然 最大化 a + b a+b a+b?为什么这里使用的是加法而不是乘法?
此外就是,上面的两条式子是为了好看,实际上只有 A l i g n : r e a l d a t a i n S {\rm Align}:~real~data~in~S Align: real data in S 和 A l i g n : f a k e d a t a i n T {\rm Align}:~fake~data~in~T Align: fake data in T 是起作用的。这就是我们要对齐的东西。
这里也给出了,当我们试图对齐两个分布的时候,可以通过引入 task classifier 来拉近,目标是让两个分布的输入趋近于同一个值(在这里是 logistics 值都 → 1 \rightarrow 1 →1),
但是这样会容易导致分类器对任何输入都输出是 1 1 1 ,这是不对的,从作者的设置来看,这个分类器的 loss 是不对的,只用在了鉴别器的优化。即:
( f s ^ , f t ^ , h s ^ , h t ^ ) = arg min f s , f t , h s , h t V ( f s , f t , g s ^ , g t ^ ) − ( L s + L t ) (\hat{f_s},\hat{f_t},\hat{h_s},\hat{h_t})=\argmin_{f_s,f_t,h_s,h_t} V(f_s,f_t,\hat{g_s},\hat{g_t})-(L_s+L_t) (fs^,ft^,hs^,ht^)=fs,ft,hs,htargminV(fs,ft,gs^,gt^)−(Ls+Lt) ( g s ^ , g t ^ ) = arg max g s , g t V ( f s ^ , f t ^ , g s , g t ) (\hat{g_s},\hat{g_t})=\argmax_{g_s,g_t} V(\hat{f_s},\hat{f_t},g_s,g_t) (gs^,gt^)=gs,gtargmaxV(fs^,ft^,gs,gt) 但无论如何,本文提出了一个比较好的 D A DA DA 的学习策略,通过另外一组无关的任务,构建一个 a l i g e m e n t aligement aligement 来作为额外的限制。
这一节我们带大家系统认识一下几个手写数据集:
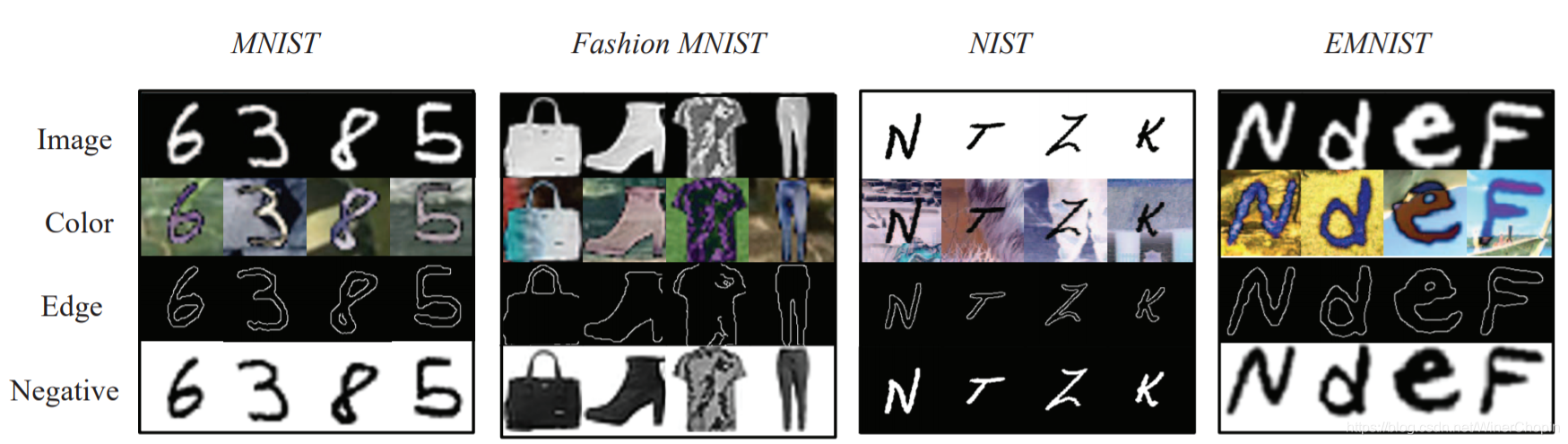
总共四个数据集( { D M , D F , D N , D E } \{ D_M,D_F,D_N,D_E \} {
DM,DF,DN,DE}),但是,实际上每个数据集只有 G r a y Gray Gray 版本,我们称之为 G − D o m a i n G-Domain G−Domain(第1行),我们需要制作不同 style 的其他 3 个 版本/domains。
- 制作 C o l o r Color Color 版本(第2行) C − D o m a i n C-Domain C−Domain
对于每一张灰度图 I ∈ R h × w × 1 I\in\Bbb R^{h\times w\times 1} I∈Rh×w×1,从彩色图像数据集
BSDS500中选择一张图像,随机 crop 出一个块 P ∈ R m × n × 3 P\in \Bbb R^{m\times n\times3} P∈Rm×n×3,然后合并: I c = ∣ I − P ∣ I_c=|I-P| Ic=∣I−P∣。
- 制作 E d g e Edge Edge 版本(第3行) E − d o m a i n E-domain E−domain
对彩色图像使用 Canny edge detector
I e = c a n n y ( I c ) I_e=canny(I_c) Ie=canny(Ic)
- 制作 N e g a t i v e Negative Negative 版本(第4行) N − D o m a i n N-Domain N−Domain
I n = 255 − I I_n=255-I In=255−I
这一节我们介绍实验
1. baseline
- Z D D A ZDDA ZDDA 这是另外一个唯一使用 DL 于 ZSDA 任务的方法
- C o C o G A N w / o T CoCoGAN~w/o~T CoCoGAN w/o T 不使用对应关系作为额外限制的 C o C o G A N CoCoGAN CoCoGAN
2. 模型评价指标
同样以最开始的例子讲述:
- 得到训练后的模型 g s , g t g_s, g_t gs,gt
- 让 c = 1 c=1 c=1,随机采取一些随机数 z z z,获取 x ~ s r = g s ^ ( z , c = 1 ) \widetilde{x}_s^r=\hat{g_s}(z,c=1) x sr=gs^(z,c=1) 和 x ~ t r = g t ^ ( z , c = 1 ) \widetilde{x}_t^r=\hat{g_t}(z,c=1) x tr=gt^(z,c=1),我们认为 x ~ s r , x ~ t r \widetilde{x}_s^r,\widetilde{x}_t^r x sr,x tr 是同一个字母。
- 利用已有的 X s r X_s^r Xsr 的数据集训练一个字母分类器 C s ( x s r ) C_s(x_s^r) Cs(xsr)
- 用这个分类器 C s ( x s r ) C_s(x_s^r) Cs(xsr) 去对 { x ~ s r } \{\widetilde{x}_s^r\} { x sr} 做识别,也就得到了 { x ~ t r } \{\widetilde{x}_t^r\} { x tr} 的标签
- 用这些标签信息去训练一个字母分类器 C t ( x ~ t r ) C_t(\widetilde{x}_t^r) Ct(x tr)
- 用这个鉴别器去对 X t r X_t^r Xtr 作分类,根据该数据集本身的 G T GT GT 计算 C t ( x t r ) C_t(x_t^r) Ct(xtr) 分类的准确度
3. 实验结果
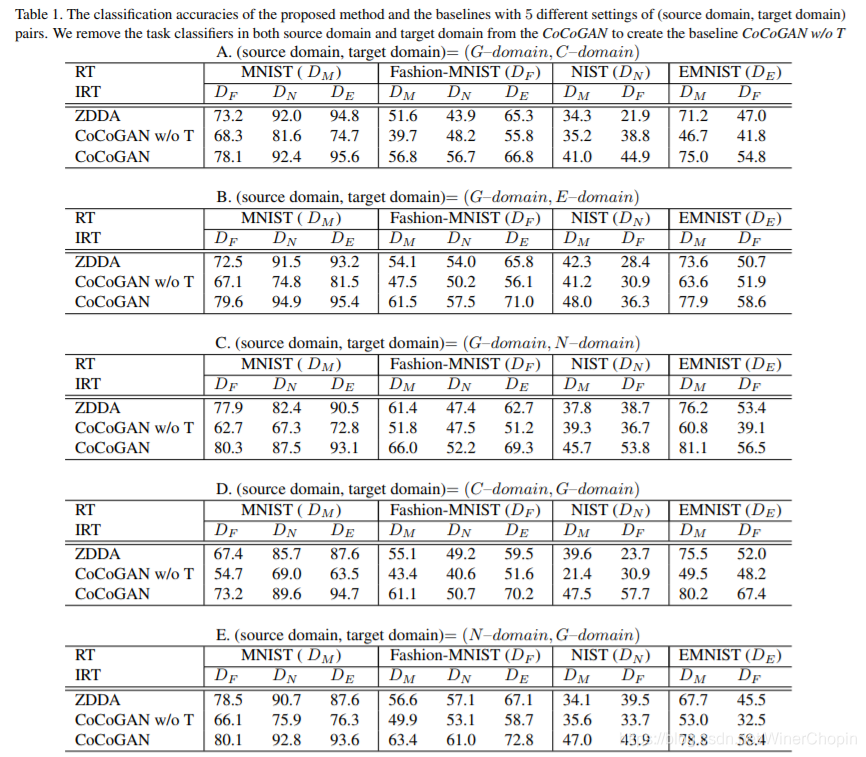
结果当然是碾压对方其他两个 b a s e l i n e s baselines baselines.