文章目录
一、evasion attack
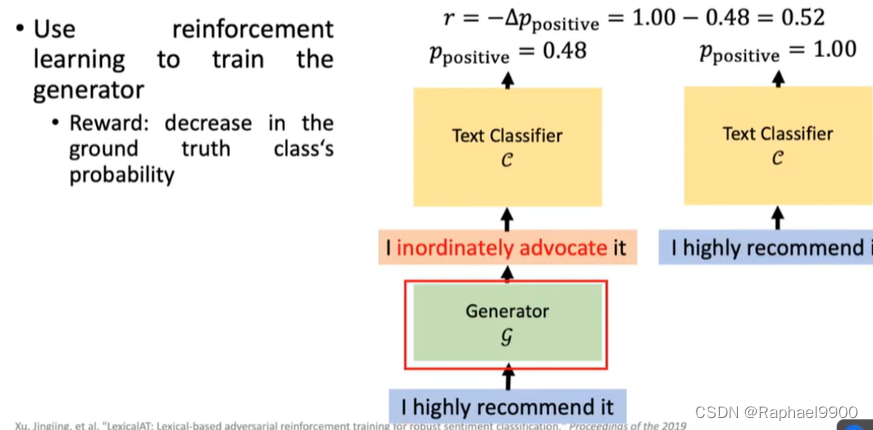
训练生成器(自动编码器)生成对抗样本
生成器的目标:使文本分类器预测错误(攻击)
分类器的目标:正确预测(防御)
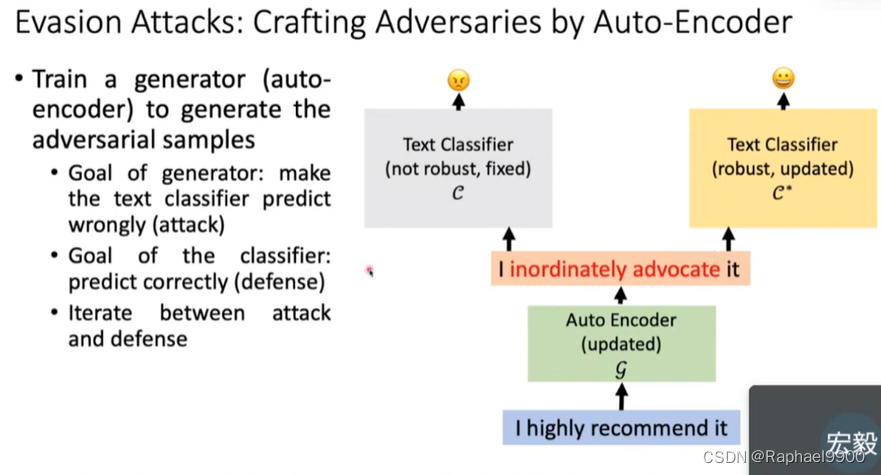
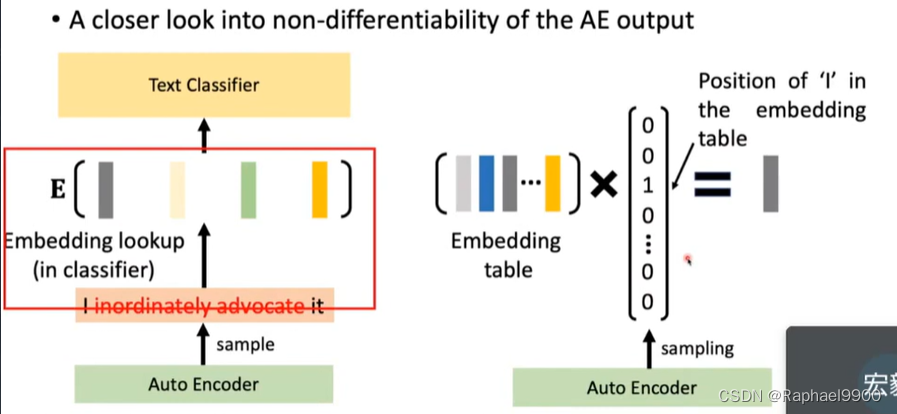
这个分类器不会更新,是已经训练好的;更新G

这个步骤会更新G和C*
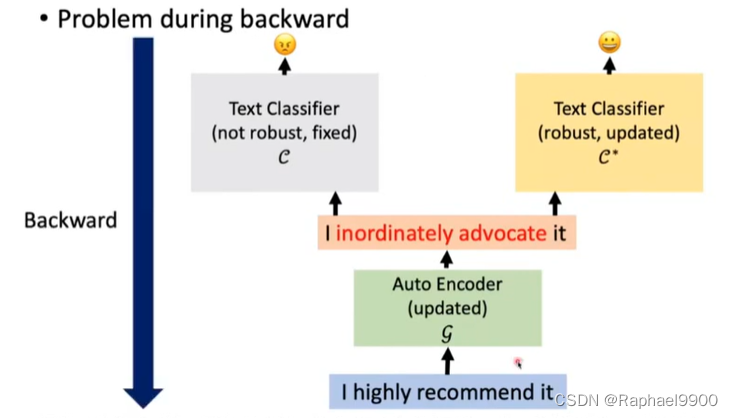
backward的时候G不能微分。
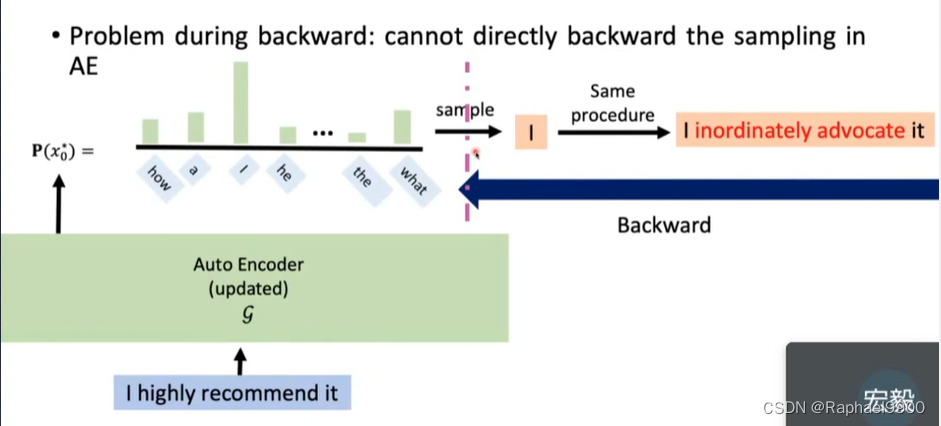
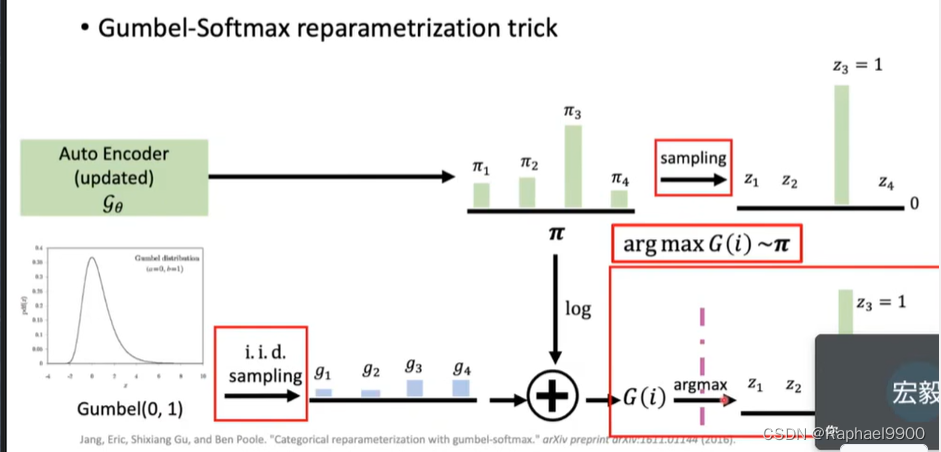
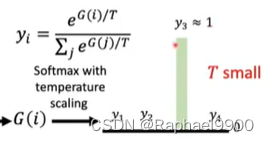
1、Gumbel-Softmax
Gumbel-Softmax重新参数化技巧
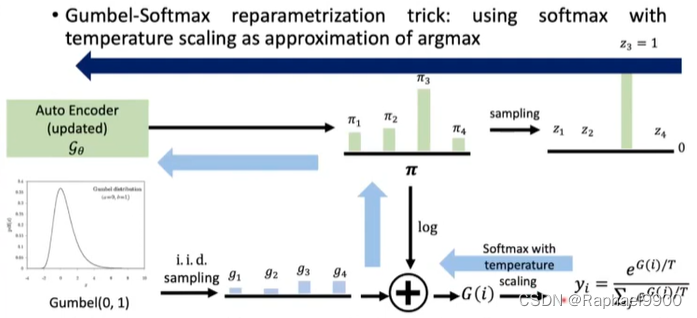
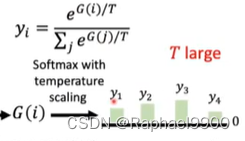
但是还是不能微分
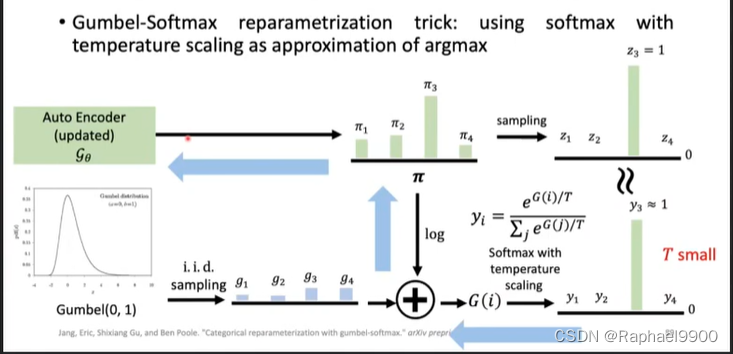
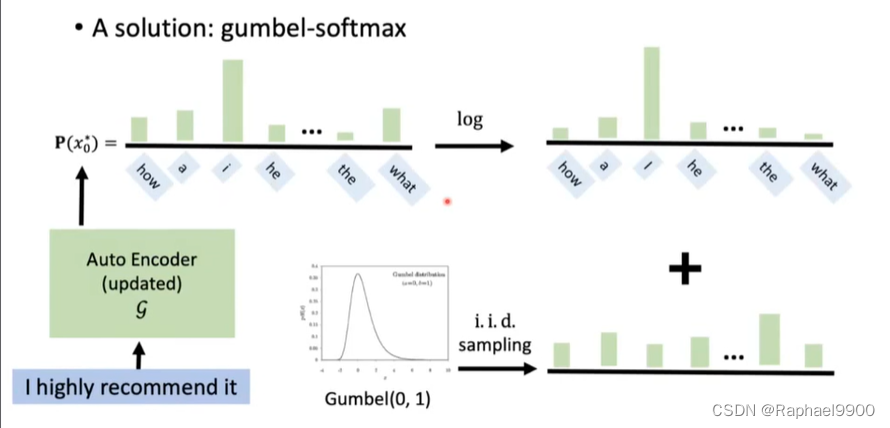
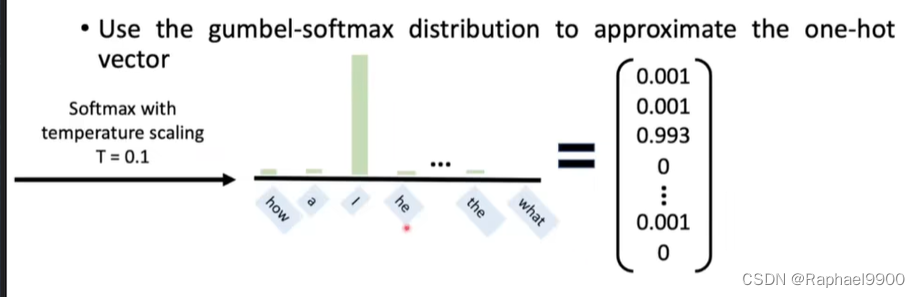
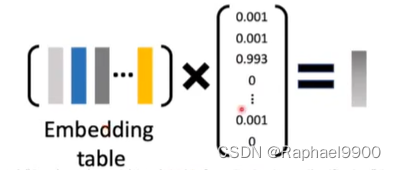
掺杂其他词
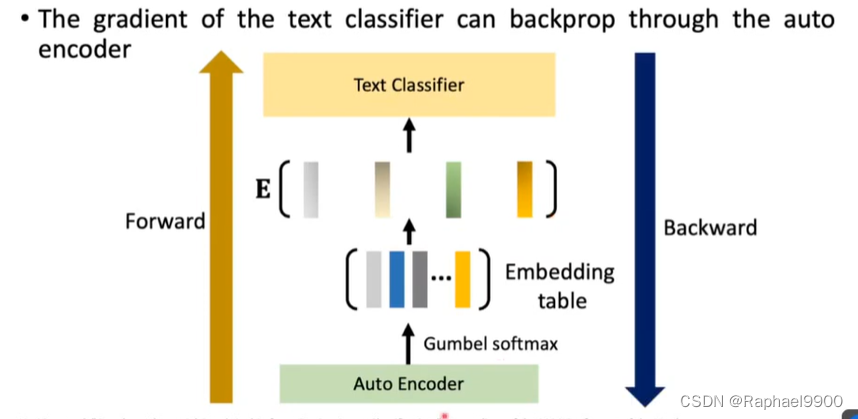

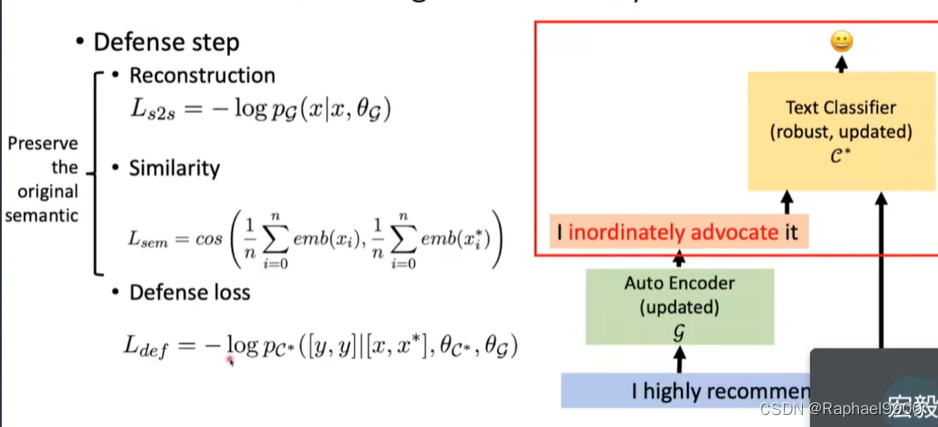
2、defense
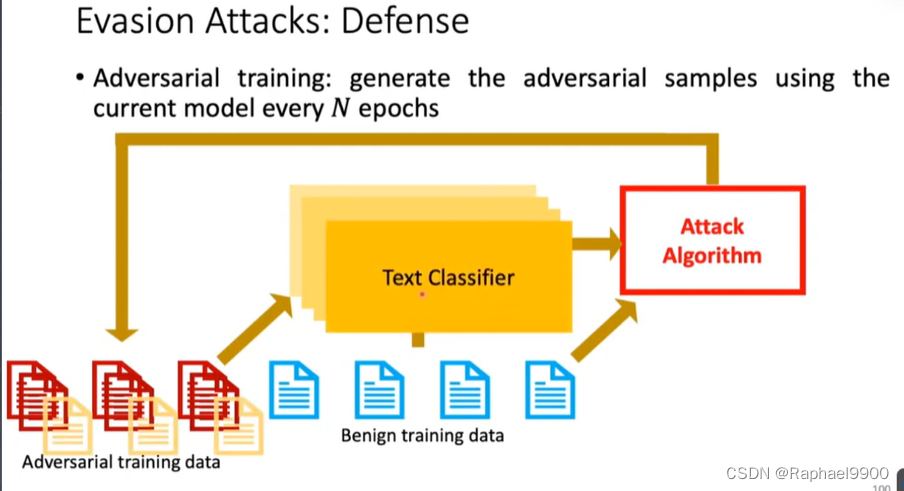
对抗性训练:每N个时期生成一个当前模型使用的对立样本
E-ball在单词嵌入空间中的对抗性训练
动机:一个词的同义词可能在它的邻域内

(1)ASCC-defense
ASCC-defense(对抗性稀疏凸组合):对抗性训练在单词嵌入空间中由凸包形式由同义词集合构成
集合A的凸包:包含A的最小凸集

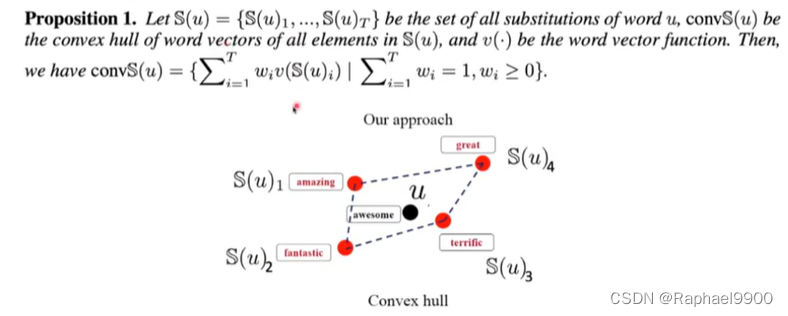
找到嵌入在凸包中的对手就是找到线性组合的系数
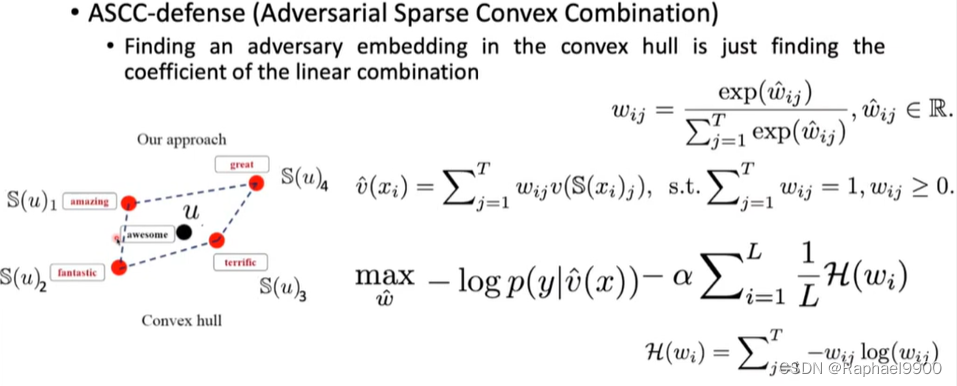
右边项很像one-hot vector,需要最小化。
使得线性组合的系数更稀疏。
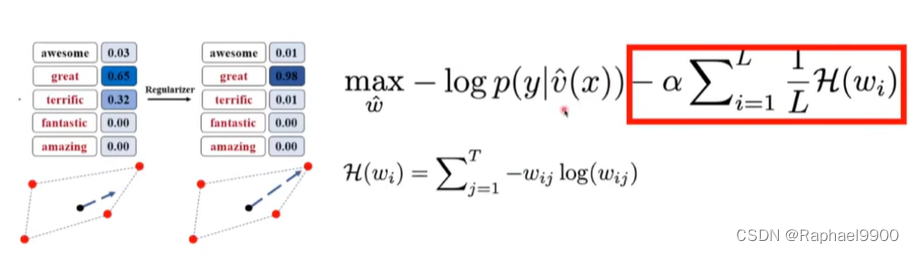
(2)对抗性数据增强
对抗性数据增强:使用经过训练的(非鲁棒性)文本分类器预先生成对抗性样本,然后将它们添加到训练数据集中,以训练新的文本分类器
3、规避攻击:检测对手
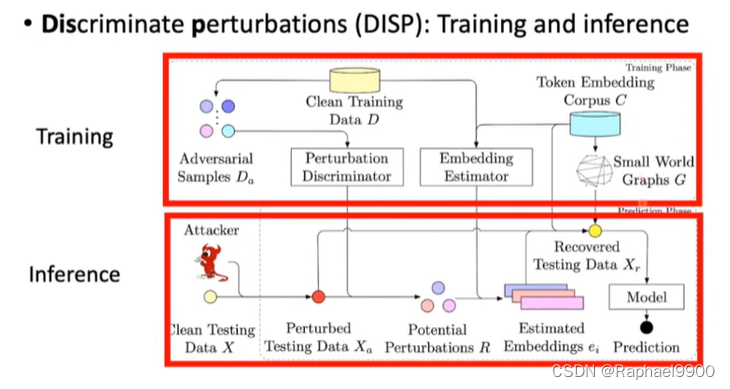
(1)辨别扰动(DISP)
辨别扰动(DISP):检测敌对样本,并将其转化为良性样本
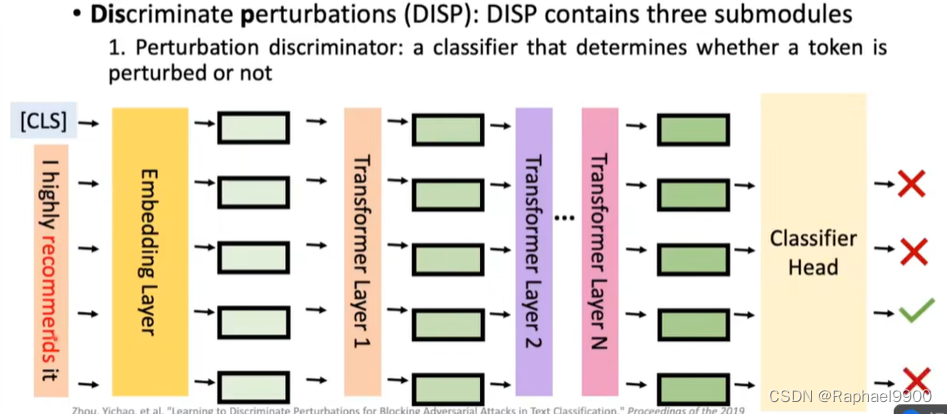
1.扰动鉴别器:确定token是否被扰动的分类器
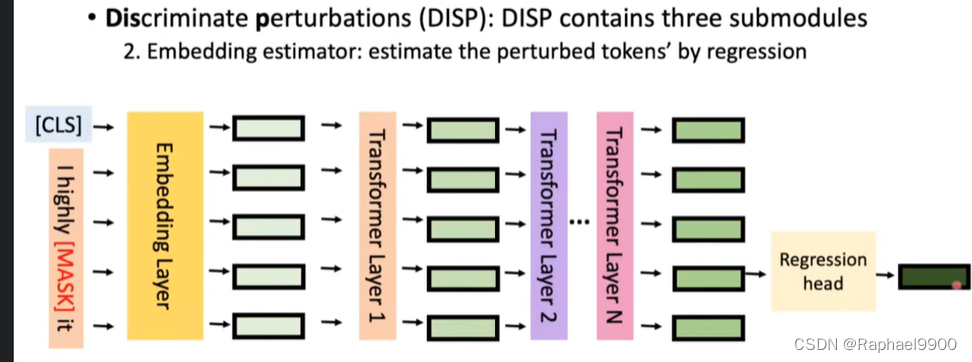
2.嵌入估计量:通过回归估计扰动符号
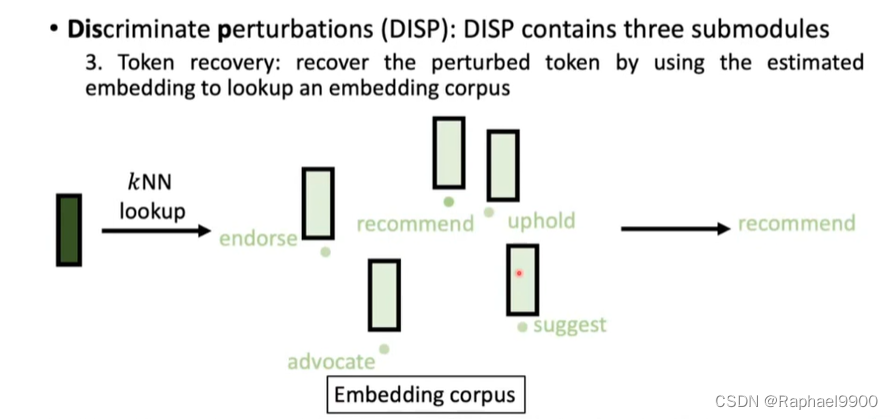
 3.token恢复:通过使用估计的嵌入来查找嵌入语料库,恢复被扰乱的token
3.token恢复:通过使用估计的嵌入来查找嵌入语料库,恢复被扰乱的token
(2)频率引导的单词替换(FGWS)
观察:自然语言处理中的回避攻击倾向于将高频词转换成低频词

步骤1:在输入中找到在训练数据中出现次数低于预定阈值o的单词

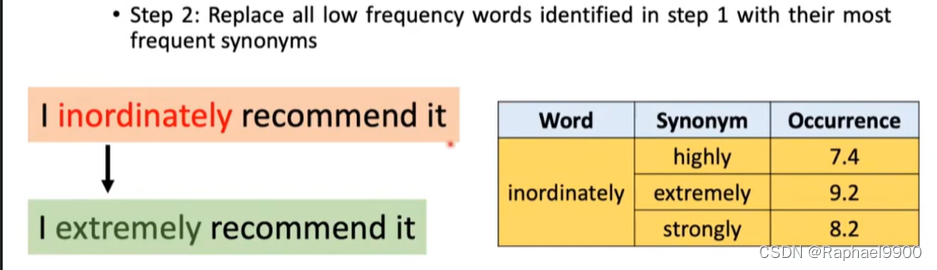
第二步:用最常用的同义词替换第一步中发现的所有低频词
步骤3:如果原始输入和交换输入之间的原始预测类别的概率差大于预定义的阈值γ,则将输入作为敌对输入进行拍打

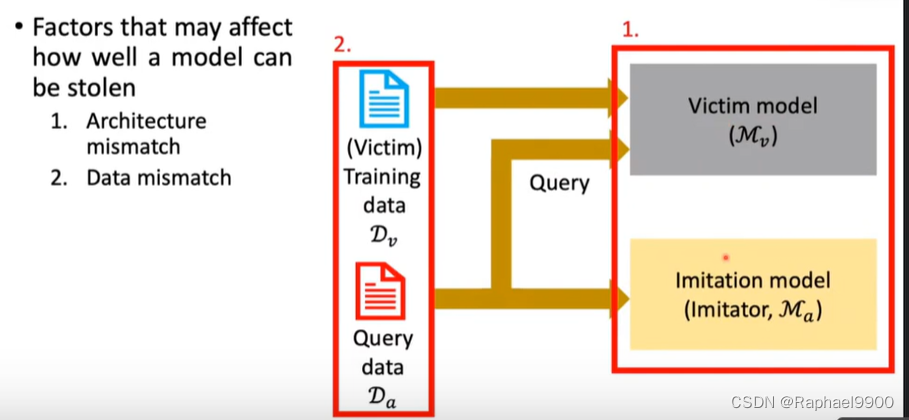
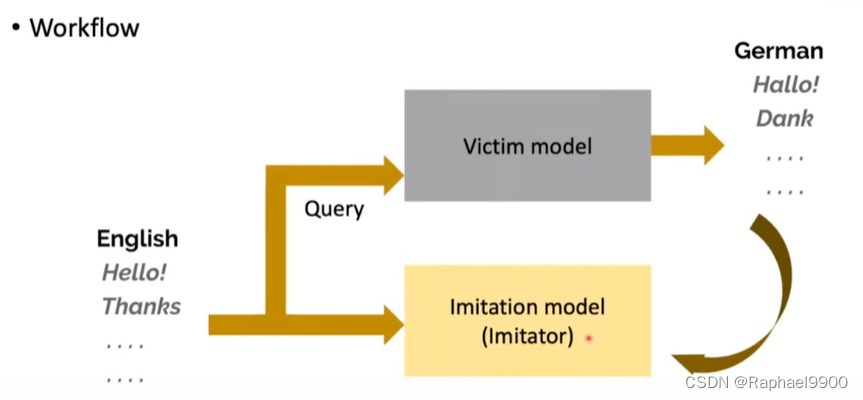
二、模仿攻击imitation attack
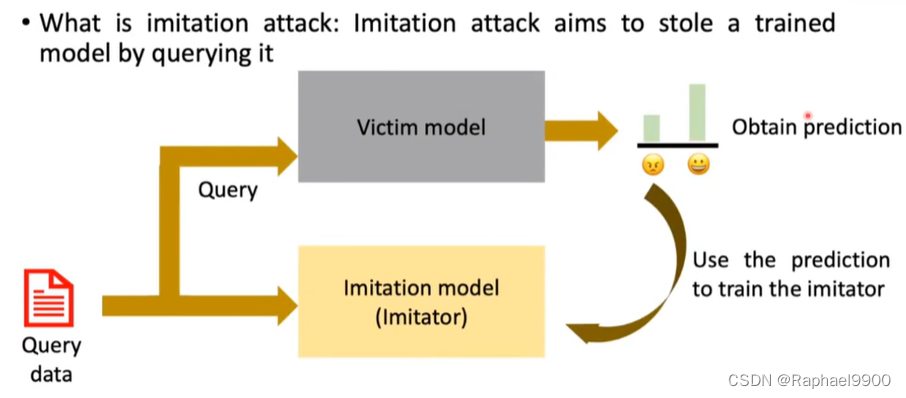
什么是模仿攻击:模仿攻击的目的是通过查询一个训练好的模型来窃取它
为什么模仿攻击?
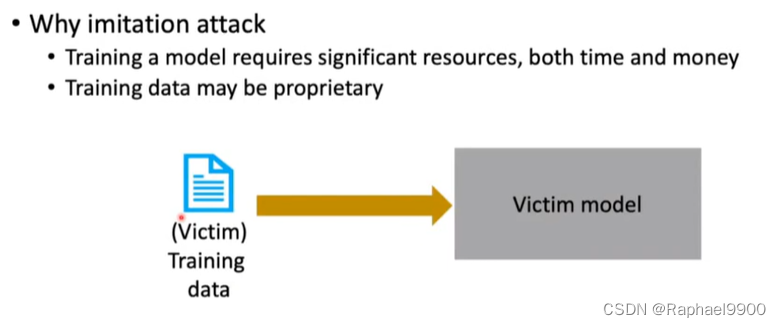
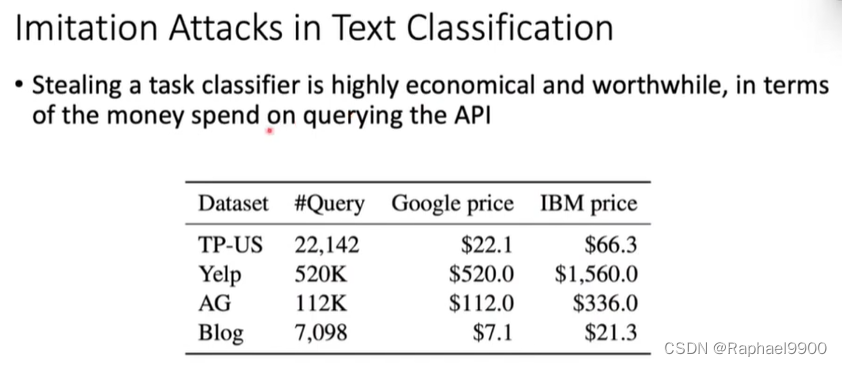
训练一个模型需要大量的资源,包括时间和金钱;
训练数据可能是专有的。
就查询API所花费的金钱而言,窃取任务分类器是非常经济和值得的
在我们训练了模仿者模型之后,我们可以(白盒)攻击模仿者模型以获得敌对样本,并使用这些样本攻击受害者模型
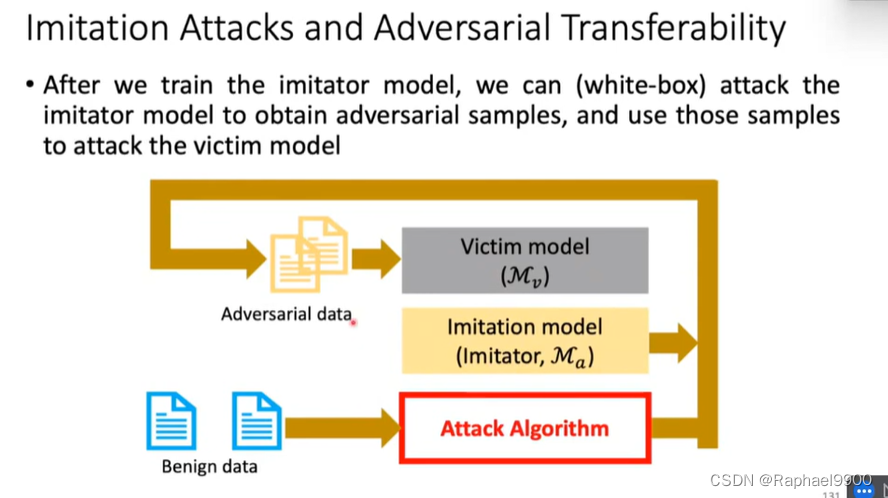
对模仿模型的攻击是有效的,对受害者模型的攻击也是有效的。
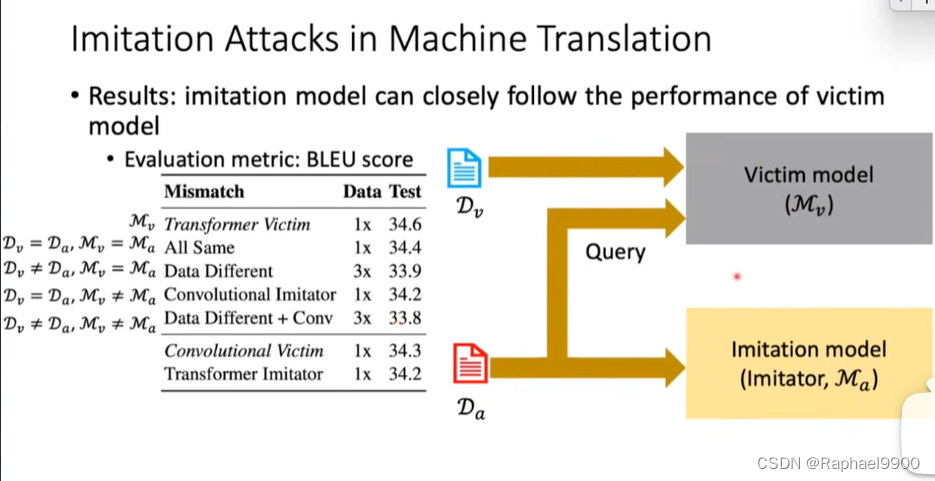
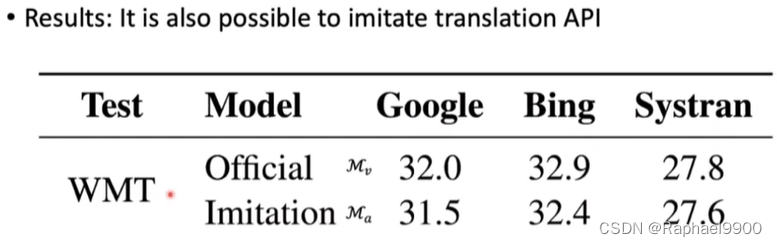
机器翻译中的对抗性可转移性(MT)
对立的例子可以成功转移到生产机器翻译系统

文本分类中的对抗性迁移
从模仿者模式转移可能比攻击受害者更强

文本分类中的防御
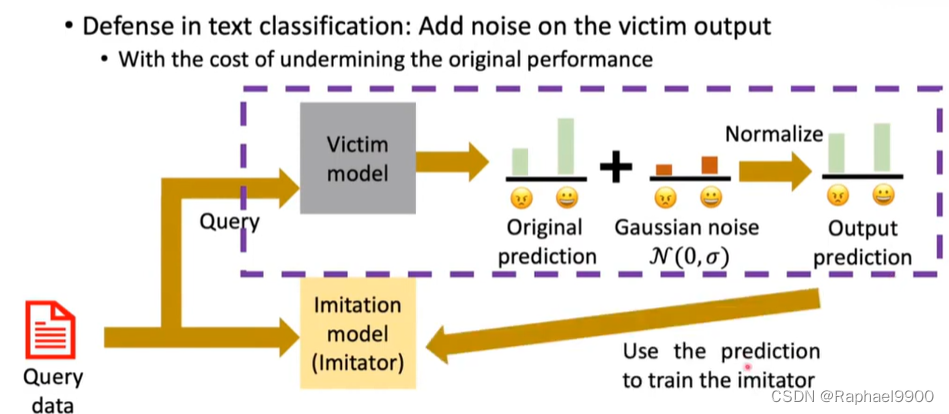
文本分类中的防御:在受害者输出中添加噪声
以破坏原始性能为代价
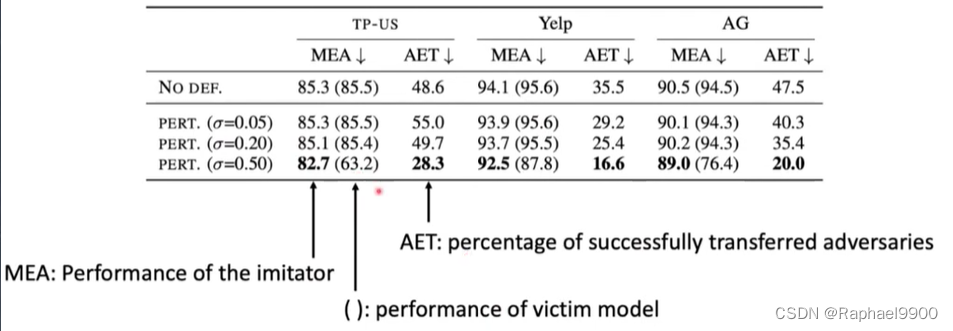 一种可能的防御:训练一个不可蒸馏的受害者模型
一种可能的防御:训练一个不可蒸馏的受害者模型
核心思想:训练一个讨厌的老师(模仿攻击中的受害者模型)模型,不能为蒸馏提供良好的监督
警告:我在NLP中没有看到任何这方面的应用
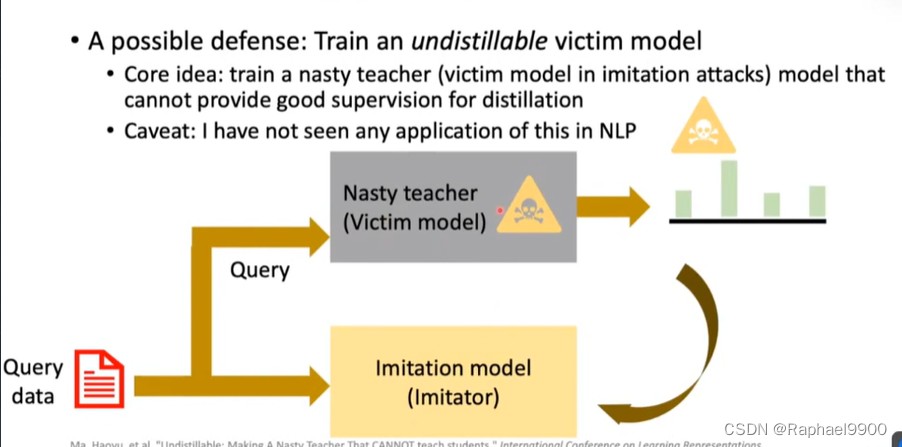
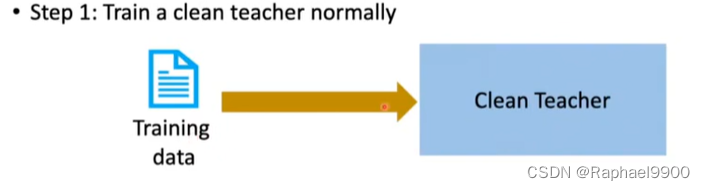
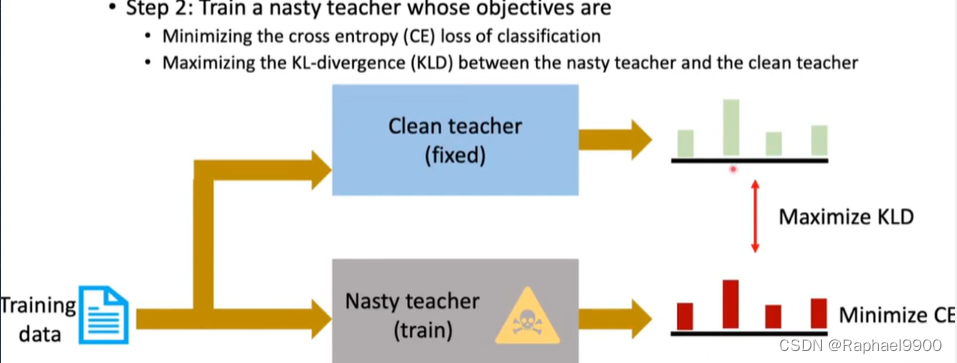
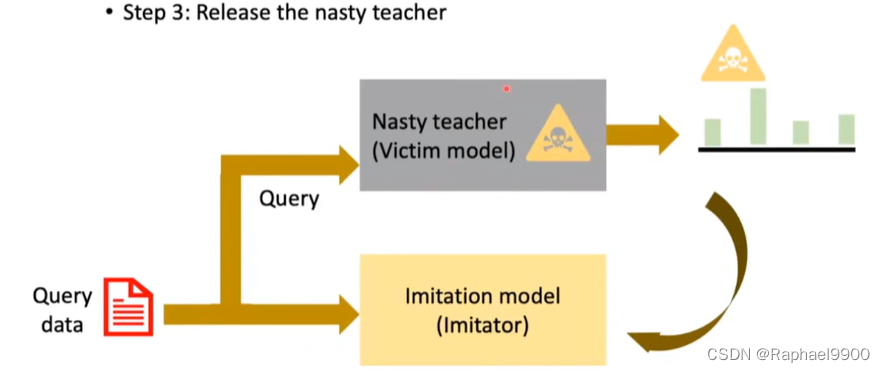
nasty teacher 算出来的模仿模型的结果会很差。