依赖关系的划分,是DAG图

窄依赖
父级RDD只出一条线,生了一个儿子

宽依赖
父级出了多条线,生了多个儿子
shuffle洗牌操作时会出现宽依赖,例如hadoop中的shuffle,3个map机器,4个reduce任务,map出的结果往reduce上仍,用轮转法仍,每一个map出来都有可能扔到4个reduce上。
宽依赖存在一个问题:一旦子RDD发生损坏,通常来讲要追溯很多父级RDD,代价较高

Stage的划分
DAG图拆分,形成stage阶段


Stage的划分
涉及到一个算法,对DAG图进行解析,阶段生成算法有一篇论文,很复杂
https://www2.eecs.berkeley.edu/Pubs/TechRpts/2011/EECS-2011-82.pdf
改论文摘要
We found it both sufficient and useful to classify dependencies into two types: narrow dependencies, where each partition of the child RDD depends on a constant number of partitions of the parent (not proportional to its size), and wide dependencies, where each partition of the child can depend on data from all partitions of the parent.
论文总体思想如下:(林子雨教授整理)

Stage阶段划分实例

遇到窄依赖往里加,遇到宽依赖断开,窄依赖转换过程不需要经过同步等待开销启动下一个阶段,流水线的操作使得他的执行速度优于MapReduce
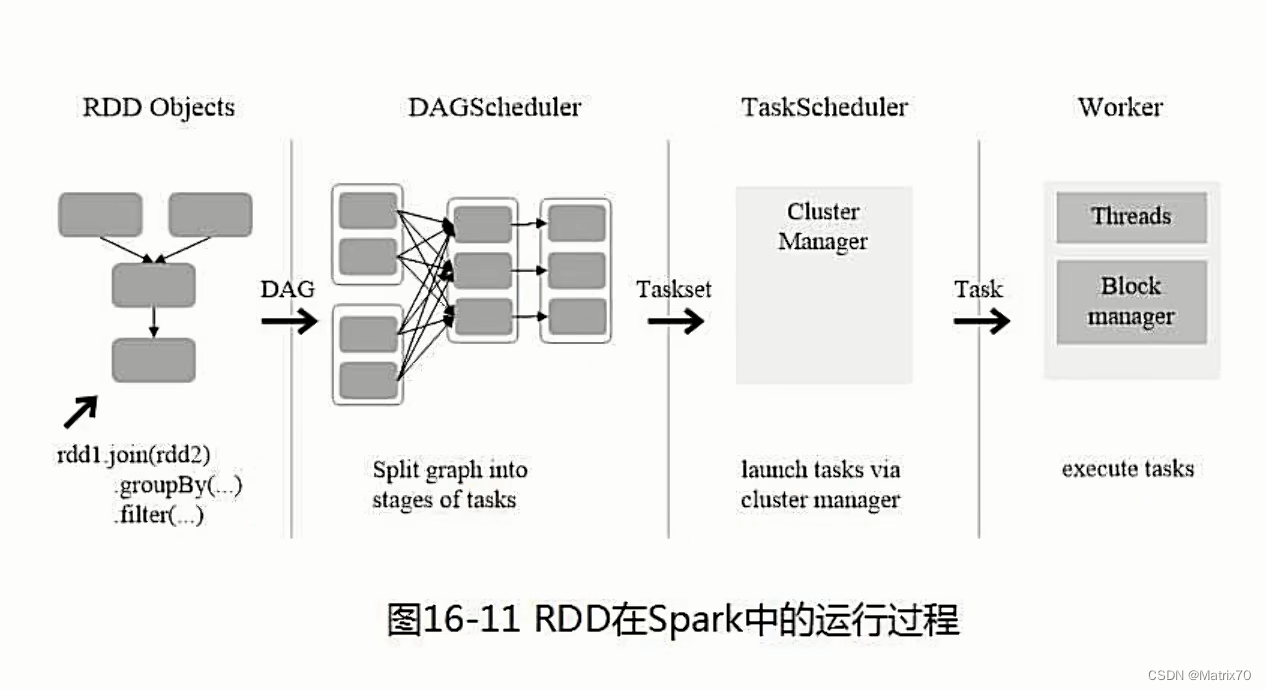
RDD运行过程

RDD基本运行原理