Spark的核心是建立在统一的抽象RDD之上,使得Spark的各个组件可以无缝进行集成,在同一个应用程序中完成大数据计算任务。
RDD设计背景
在实际应用中,存在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘工具,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。
但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。虽然,类似Pregel等图计算框架也是将结果保存在内存当中,但是,这些框架只能支持一些特定的计算模式,并没有提供一种通用的数据抽象。
RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销。
RDD概念
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。
RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用,比如Web应用系统、增量式的网页爬虫等。正因为这样,这种粗粒度转换接口设计,会使人直觉上认为RDD的功能很受限、不够强大。但是,实际上RDD已经被实践证明可以很好地应用于许多并行计算应用中,可以具备很多现有计算框架(比如MapReduce、SQL、Pregel等)的表达能力,并且可以应用于这些框架处理不了的交互式数据挖掘应用。
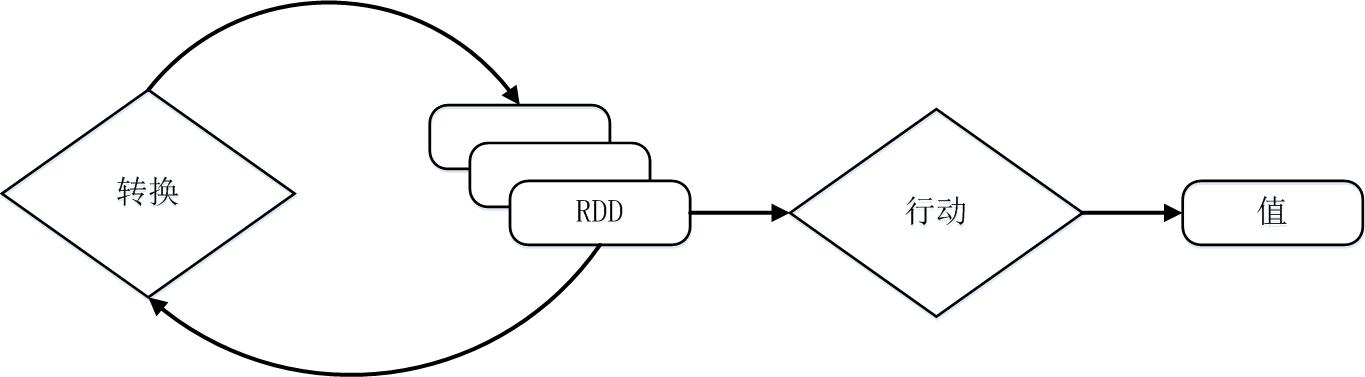
Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作。RDD典型的执行过程如下:
- RDD读入外部数据源(或者内存中的集合)进行创建;
- RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
- 最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标量)。
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中(如图9-8所示),真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
RDD特性
总体而言,Spark采用RDD以后能够实现高效计算的主要原因如下:
- 高效的容错性。现有的分布式共享内存、键值存储、内存数据库等,为了实现容错,必须在集群节点之间进行数据复制或者记录日志,也就是在节点之间会发生大量的数据传输,这对于数据密集型应用而言会带来很大的开销。在RDD的设计中,数据只读,不可修改,如果需要修改数据,必须从父RDD转换到子RDD,由此在不同RDD之间建立了血缘关系。所以,RDD是一种天生具有容错机制的特殊集合,不需要通过数据冗余的方式(比如检查点)实现容错,而只需通过RDD父子依赖(血缘)关系重新计算得到丢失的分区来实现容错,无需回滚整个系统,这样就避免了数据复制的高开销,而且重算过程可以在不同节点之间并行进行,实现了高效的容错。此外,RDD提供的转换操作都是一些粗粒度的操作(比如map、filter和join),RDD依赖关系只需要记录这种粗粒度的转换操作,而不需要记录具体的数据和各种细粒度操作的日志(比如对哪个数据项进行了修改),这就大大降低了数据密集型应用中的容错开销;
- 中间结果持久化到内存。数据在内存中的多个RDD操作之间进行传递,不需要“落地”到磁盘上,避免了不必要的读写磁盘开销;
- 存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化开销。
RDD运行过程
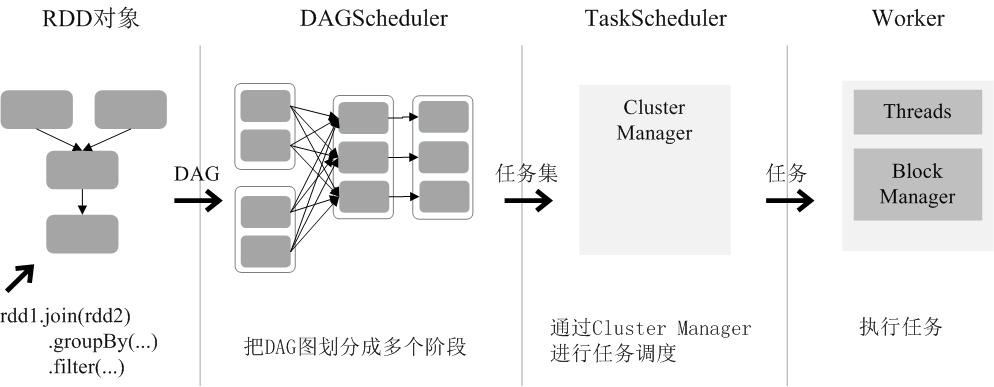
通过上述对RDD概念、依赖关系和阶段划分的介绍,结合之前介绍的Spark运行基本流程,这里再总结一下RDD在Spark架构中的运行过程(如图9-12所示):
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。