一、各种概念
分类中 有很多分类任务种类,每种概念任务都有不一样的处理方式
单类别: 二分类、多分类 多类别:
二、二分类(binary class classification)
就是类别中只有两个类,是 or 否,且只有一个类别,即一个label为0或者1.
比如异常与否
import numpy as np
y = np.asarray(['normal', 'anomaly'])可以通过sklearn的LabelEncoder转换为数字
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_encoder = le.fit_transform(y)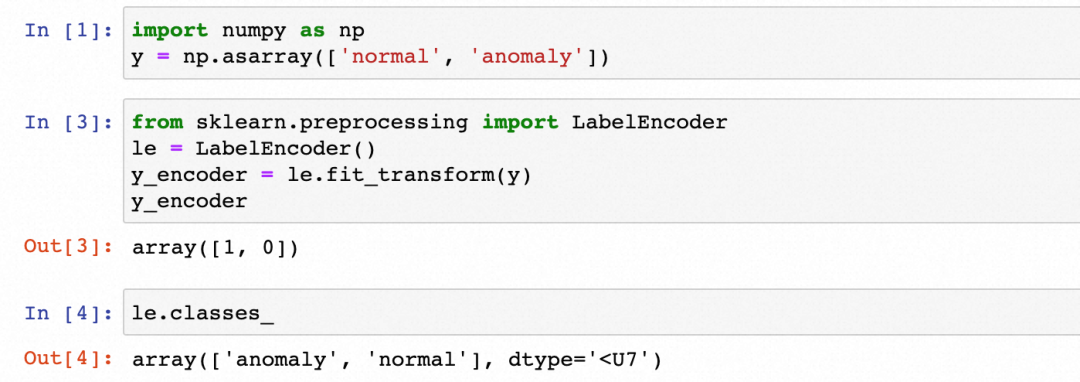
label的形式为(row_dim, col_dim), 其中row_dim为数据的length维度,col_dim=1, label数值为0或者1
一般用logloss来当作目标函数
logloss:
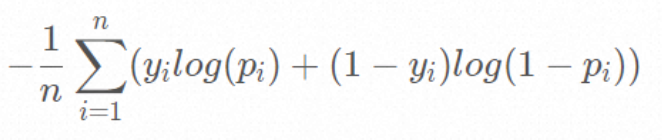
其中yi 为输入数据 xi 的真实类别(即0或者1), pi 为预测 xi 属于类别 1 的概率。
对所有样本的对数损失表示对每个样本的对数损失的平均值(即每个样本logloss的累加的平均)。
该logloss的推导可以看我之前写的文章:
标题:【算法岗求职笔记】逻辑回归(Logistic Regession,LR) · 十问十答 章节: https://www.zhihu.com/column/c_1492838352466890752
一般来说都配合着sigmoid使用
二、多分类(multiclass classification)
就是类别中要多于两个类,class1、class2、class3...,只有一个类别,但这个label为0,1,2...
比如ai的分类为CV、NLP、RL...
import numpy as np
from sklearn.preprocessing import LabelEncoder
y = np.asarray(['CV', 'NLP', 'RL', 'time series'])
le = LabelEncoder()
y_encoder = le.fit_transform(y)
y_encoder
多分类一般用交叉熵损失(cross entropy Loss)作为目标函数
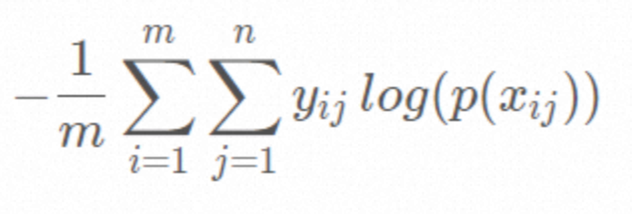
m为样本数、n为类别的个数,yij代表样本i归属于类别j, p(xij)代表样本i被预测属于分类j的概率
logloss可以理解为cross entropy Loss 特殊形式
一般配合softmax使用
三、 多类别(multilabel classification)
最常举的例子就是游戏或者电影的标签归属。
比如游戏来说:
情节、幽默、单双人,这就是三个标签(label1, label2, label3) 即multi-label
如果用多分类(multi class)的例子来举例,利用sklearn的MultiLabelBinarizer进行label encoding
from sklearn.preprocessing import MultiLabelBinarizer
y = np.asarray(['CV', 'NLP', 'RL', 'time series'])
mlb = MultiLabelBinarizer()
print(y)
print(y[:, None])
print(mlb.fit_transform(y[:, None]))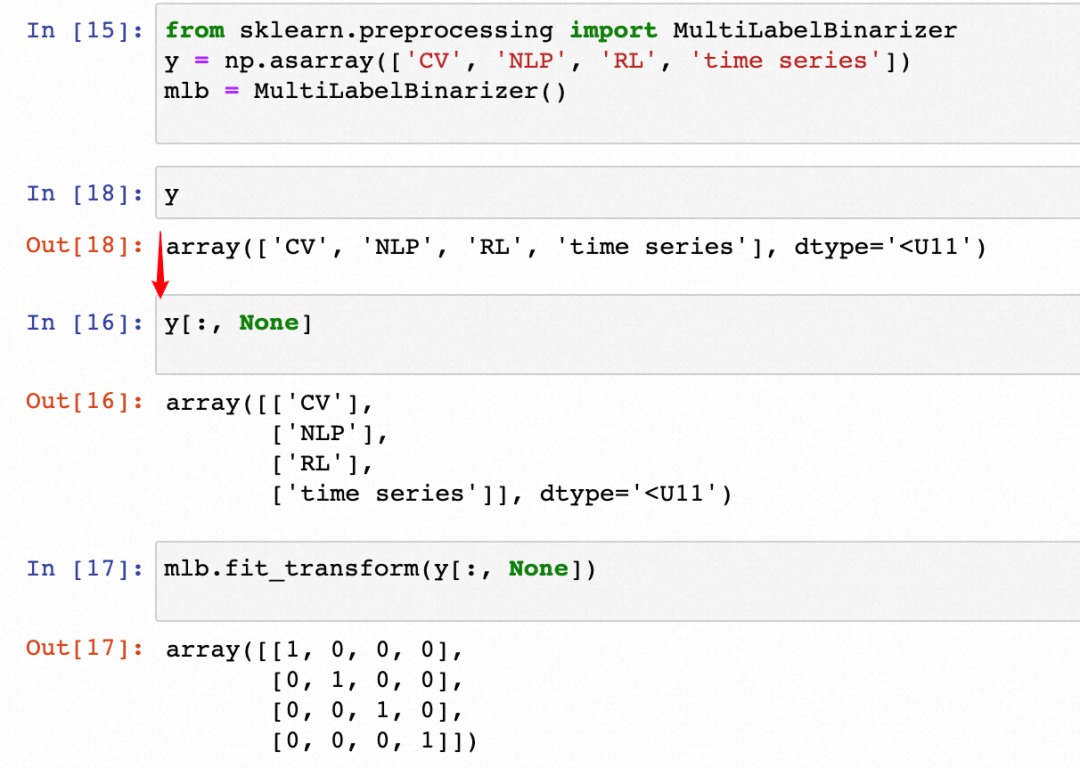
如图所示,很好理解, muliclass情况下,label是一维数组,而multilabel情况下,label是一个二维数组
比如有的任务涉及到CV和时序的,那这个样本的label就应该是[1 0 0 1],即每个样本可能不只有一个标签,通过MultiLabelBinarizer的y也应该是二维的label数组。

这种情况下主要有两种常见的情况。
有几个标签,比如标签1有或者没有,标签2是或者不是,每个标签单独都是0或者1, 但这种没法用MultiLabelBinarizer,因为这个主要是为第二种场景
和上述例子一样,都是一个group里面有很多标签,每个样本归属于标签的个数组合不一样
这种 每个label为0-1的还叫做:binary multi-label 如果每一个label的取值大于1,则可以称为:multi-class multi-label
如下:
binary multi-label:
y_true = np.arr([[0, 1, 1],
[0, 0, 1],
[1, 1, 0]])
multi-class multi-label:
y_true = np.arr([[2, 1, 0],
[0, 2, 1],
[1, 2, 4]])总结
二分类,label就是1或者0, 多分类label大于1,多标签分类,label是二维的数组也分为binary和multi class
二分类主要用logloss,配合sigmoid,多分类主要用cross entropy Loss,配合softmax
多分类和binary的多标签都可以用sklearn中的工具来完成label转换
多标签之外还有multi-task任务,浅浅来看,多标签还是同样的损失函数,而多任务更像是用一个网络不同的损失函数,但共用网络结构和权重参数,完成两个不同的task
不过有的时候做任务也不需要局限于这些概念,这些概念也都是人为创作的,只要网络的输出是我们想要的,损失函数可以计算并反向推理更新参数就可以的,但是明确任务的细节可以帮助去查阅很多参考资料
后面有时间总结下multi-task的玩法
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书