两种思路:
以SVM为例
1.one-versus-rest
思想:
假设一共有1,2,3,4,5个类别的数据
对于第1类,训练一个分类器:第1类是正样本,其余类的样本都是负样本
对于第2类,训练一个分类器:第2类是正样本,其余类的样本都是负样本
以此类推,一共训练出五个分类器
在预测阶段,对于输入的待分类样本,分别从第一个分类器开始询问是否属于该类别,该分类器“承认”,就将该样本判别为该类
存在的问题:
分类重叠现象:某个待分类样本被多个分类器“认领”(可以计算该样本与这些分类器对应超平面的距离,选择距离最远的)
不可分类现象:所有分类器都不“认领“”某个待分类样本(设置一个“其他类,专门用来存放异常类”,容易造成数据集偏斜问题???)
ps:这种方式会有数据集偏斜问题(因为是一对多),影响分类面划分的准确性,如下图:
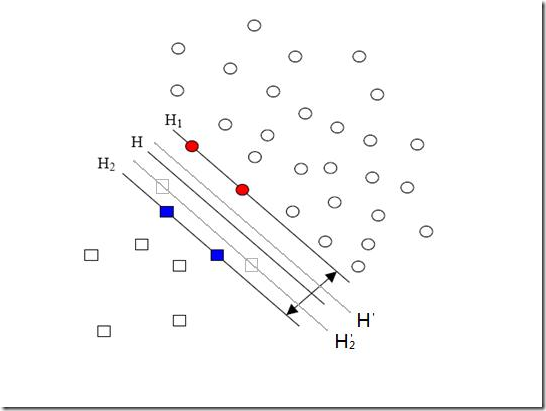

数据集偏斜问题:在分类问题中某一类的样本数量与其他样本数据量相差较大(在分类的时候,数量多的正类可以把分类面向负类的方向“推”,因而影响了结果的准确性。)
解决方案:用“惩罚因子”让分类器对于样本数少的那一类的样本更加重视(软间隔的时候不能忽略,因为本来就少)
在确定惩罚因子的时候可以根据两种类别的数量或者利用超球的体积来衡量样本的空间分布
参考链接:https://blog.csdn.net/qq_26898461/article/details/50481792
2.one-versus-one
思路:
对于五分类问题
每一个分类器只负责分类两个类别,避免了数据集的偏斜问题,但是k个类别就要训练k*(k-1)/2个分类器
例如:
第一个分类器:负责二分类1,2
第二个分类器:负责二分类1,3
第二个分类器:负责二分类1,4.....以此类推,要想得到五分类器,需要训练10个分类器
待分类样本询问每一个分类器所属的类别,然后进行投票,票数最多的那个类别就作为预测类别
还是会存在分类重叠的问题,但是不会有不可分类问题(不可能所有类别的票数都为0)
改进的方法:
按照下图的方式组织one-vs-rest二分类器:
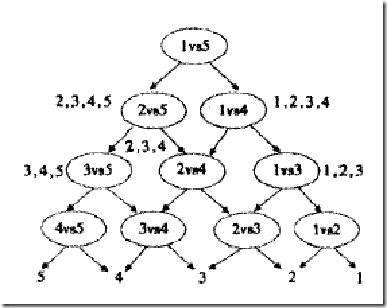 (有向无环图,因此这种方法也叫做DAG SVM)
(有向无环图,因此这种方法也叫做DAG SVM)
这样在分类时,我们就可以先问分类器“1对5”(意思是它能够回答“是第1类还是第5类”),如果它回答5,我们就往左走,再问“2对5”这个分类器,如果它还说是“5”,我们就继续往左走,这样一直问下去,就可以得到分类结果。好处在哪?我们其实只调用了4个分类器(如果类别数是k,则只调用k-1个),分类速度飞快,且没有分类重叠和不可分类现象!
缺点在哪?假如最一开始的分类器回答错误(明明是类别1的文章,它说成了5),那么后面的分类器是无论如何也无法纠正它的错误的(因为后面的分类器压根没有出现“1”这个类别标签),其实对下面每一层的分类器都存在这种错误向下累积的现象
解决方法:
根节点的选取:(也就是如何选第一个参与分类的分类器),我们总希望根节点少犯错误为好,因此参与第一次分类的两个类别,最好是差别特别特别大,大到以至于不太可能把他们分错;或者我们就总取在两类分类中正确率最高的那个分类器作根节点,或者我们让两类分类器在分类的时候,不光输出类别的标签,还输出一个类似“置信度”的东东,当它对自己的结果不太自信的时候,我们就不光按照它的输出走,把它旁边的那条路也走一走
参考链接:https://blog.csdn.net/qq_26898461/article/details/50481803