交叉熵
期望:
期望就是所有随机变量的均值。
E(X)=X1*P(X1)+X2*P(X2)+X3*P(X3)
熵:
熵表示所有信息量的期望。
信息量如何计算呢?
概率值取Log,然后加个负号,就是信息量
I(X0)=-log(P(X0))
I(X0)代表信息熵
公式理解:概率越小,信息越大,概率越大,信息越小。
与正常思考反着来,因为概率大,所以这条信息重要性越小,因为都知道。所以信息量小。
因为概率小,所以这条信息很重要,因为概率小不确定,所以包含的信息量大
熵的公式:
熵就是在信息量的基础上求一个期望,(也就是先乘概率值再累计求和)熵的公式定义如下
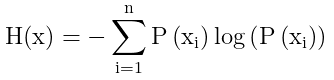
以上的log函数全部底为2
举例:
对于二项分布,只有两种可能的情况,一个发生的概率为P(x),另一个发生的概率为1-P(x),此时的信息量计算过程如下
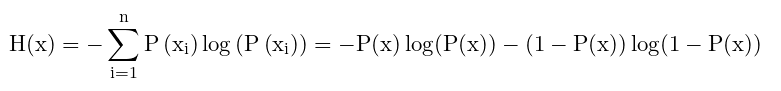
在这里不要把这个看成二分类交叉熵。
交叉熵就是损失函数。信息量是各种情况熵的期望。熵的公式里面填的数字都是概率值。两种情况的事件,概率值只有两种,P(x) 和 1-P(x) ,带进去如上。
相对熵(KL散度)
KL散度的定义:
同一个随机变量X,有两个单独的概率分辨P(x)和Q(x)。用KL散度来衡量P(x)和Q(x)两个独立分辨之间的差异。KL散度值越小,表示P和Q的分布越接近。
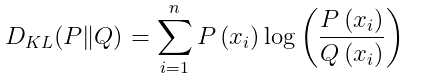
直观理解:
KL之所以说是对比两个分布之间的差异。应该是相减 。但是体现在log里面的相除。log拆分开来的话不就是相减了吗!
交叉熵 Cross Entropy
交叉熵是做为损失函数来使用的。
表示对于数据预测分类情况的类别和真实类别情况之间的距离。
此时P(X)代表真实样本,Q(X)代表预测样本(注意这句话!!!!下面第三步要用的到)
我们使用梯度下降优化的目的,就是使得预测分类的结果尽可能的逼近真实的分类结果。也就是KL散度的值越小越好。
第一步:
带入KL散度公式,
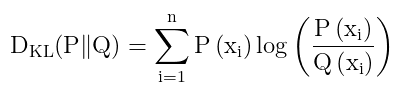
第二步简化:
最右边这个P(xi)/Q(xi)拆开,从除变成减,两边都有P(xi),求和符号也带着
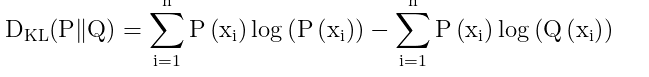
现在设 
因为在上面已经提到熵的定义 公式。可以往上面翻翻看。所以
第三步
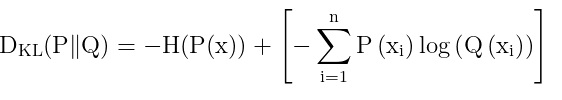
我们发现H(x)即是对P(x)进行求取熵,但是P(x)是一个真实的样本。那么他的初始值都已经固定了。P(X)也就是一个常数,而常数在接下来的LOSS中是没有任何意义的。那么就可以将这个去除。
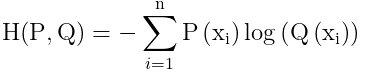
这就是交叉熵。
交叉熵的应用
交叉熵在分类中常被使用,通常和Softmax在一起使用,softmax获取概率,带入到交叉熵中。根据交叉熵的值,不断的调整。
BCE 二分类交叉熵损失函数。
对于在二分类损失函数中应用,交叉熵损失函数为以下形式。
![]()
SoftWare交叉熵损失函数。
交叉熵经常搭配softmax使用,将输出的结果进行处理,使其多个分类的预测值和为1,再通过交叉熵来计算损失。
参考
https://blog.csdn.net/Albert233333/article/details/127148805