M3P:通过多任务多语言多模态预训练学习通用表征
摘要
我们提出了多任务多语言多模式预训练模型M3P,该模型通过多任务预训练将多语言预训练和多模式预训练结合到一个统一的框架中。我们的目标是学习通用表示法,将以不同方式出现的对象或以不同语言表达的文本映射到一个共同的语义空间。此外,为了明确鼓励图像和非英语语言之间的细粒度对齐,我们还提出了多模态代码切换训练(MCT),通过代码切换策略将单语预训练和多模态预训练结合起来。在MSCOCO和Multi30K两个基准数据集上对多语言图像检索任务进行了实验。M3P可以实现英语的可比结果,以及非英语语言的最新结果。
1.导言
最近,我们见证了一种新的自然语言处理范式(NLP)的兴起,即通过自我监督的预训练从原始文本中学习一般知识,然后通过特定于任务的微调将其应用于下游任务。现在,这些最先进的单语预训练语言模型,如BERT [7], RoBERTa [23] and GPT-2 [28],已经扩展到多语言场景,如多语言伯特[7]、XLM/XLM-R[5,4]、Unicoder[13]。
然而,将这些预先训练好的模型扩展到多语言多模式场景仍然具有挑战性。多语言预先训练的语言模型不能直接处理视觉数据(如图像或视频),而许多预先训练的多模态模型是在英语语料库上训练的,因此在非英语语言上不能表现得很好。因此,高质量的多语种多模态训练语料库对于多语种预训练和多模态预训练的结合至关重要。然而,目前只有少数多语种的多模态语料库存在,而且它们的语言覆盖率也很低(可用的多语言数据集比较少并且语言不全)。此外,依赖高质量的机器翻译引擎从英语多模态语料库生成此类数据既耗时又计算昂贵(机器翻译又很费时费力)。缺乏在预训期间学习视觉语言和非英语语言之间的明确对齐。
为了解决这些问题,本文提出了M3P模型,即多任务多语言多模态预训练模型。该模型旨在学习通用表示,可以将不同语言表达的不同形式或文本映射到一个共同的语义空间。 为了缓解多模态预训练缺乏足够的非英语标记数据的问题,我们引入多模态代码转换训练(MCT)来加强图像和非英语语言之间的显式对齐。
目标是
(i)通过多语言预培训,学习使用多语言语料库(例如,维基百科中涵盖100种语言的句子)表示多语言数据,
(ii)学习多语言多模态表示通过用多模态语料库中其他语言的翻译随机替换一些英语单词(例如,用英文标注的图像标题对 )
(iii)通过多任务学习,将这些表示推广到处理多语言多模态任务。
总之,本文的主要贡献是:
- 我们介绍了M3P,这是第一个将多语言预培训和多模式预培训结合到一个统一框架中的已知成果。
- 我们提出了一种新的多模式代码切换训练(MCT)方法,这是一种在零样本和少样本设置下提高M3P多语言传输能力的有效方法
- 我们在非英语语言的Multi30K和MSCOCO上实现了多语言图像文本检索任务的最新成果,大大优于现有的多语言方法。与最先进的单语多模态模型相比,该模型还可以在这两个数据集上获得英语的可比结果。
- 最后但并非最不重要的一点是,我们进行了广泛的实验和分析,以深入了解使用多模式代码转换训练(MCT)和每个训练前任务的有效性。
2. Related Work
多语预训练模型
多语BERT(M-BERT)[7]表明,通过对102种语言共享词汇和权重的多语语料库进行蒙面语言建模,可以在15种语言的跨语言自然语言推理(XNLI)[6]任务中取得令人惊讶的好结果。XLM[5]和Unicoder[13]通过引入新的基于双语语料库的训练前任务,进一步提高了多语BERT。然而,所有这些适用于模型自然语言处理任务,并不能很好地设计用于多模态任务,如多语言图文检索或多模态机器翻译
多模态预训练模型
最近,大量多模态预训练模型,如ViLBERT[24]、Unicoder VL[19]、UNITER[3]、VLP[37]和Oscar[21]被开发用于视觉语言任务,使用multi-
layer Transformer 作为主干。然而,由于多语言视觉语言训练数据不易收集到对齐良好的视觉语言训练数据,所有这些模型均仅基于单语多模态语料库进行英语预训练,如Conceptual Captions[29]、SBU Captions[26]、Visual Genome[17]和MSCOCO[2]。因此,将其应用于非英语输入的多模态任务是不可行的。
代码转换训练
代码切换训练[27][33]将原始训练语料库转换为代码切换语料库,这有助于模型明确地建模不同语言中对应单词之间的关系。(感觉是所有语言转换成一种计算机能识别的语言)现有的研究采用基于规则的词汇替换策略,通过双语词典将原单词随机替换为翻译单词。这种方法为低资源语言提供了显著的改进。 然而,现有的研究将代码转换用于纯文本任务,而忽略了其在多语言多模态场景下的多模态预训练模型中的应用。
3.M3P:多任务多语言多模式预训练
在本节中,我们将描述如何使用多语言-单模态语料库(例如,从维基百科中提取的句子)和单语言-多模态语料库(例如,英语图像-标题对)来训练M3P。
如图1所示,我们使用了BERT的自我关注变压器架构,并使用三种类型的数据流设计了两个预培训目标。在训练前阶段采用多任务训练,以同时优化所有训练前目标,从而获得更好的表现。我们在每次迭代中优化两个训练前目标的累积损失,使其具有相同的权重,以轮流训练

图1:M3P中使用的三个数据流和四个训练前任务。蓝色块表示英文文本,黄色、绿色和橙色块表示非英文文本。
多模态单语流
多模态代码转换流
单模多语流
3.1. 数据流
我们分别从多语言语料库和多模态语料库中选取两种基本数据流,即多语言单模态流和单语言多模态流。 我们还设计了多模态码切换流来同时利用多语言数据和多模态数据。下面将介绍有关这三个数据流的细节。
Multilingual Monomodal Stream(多语言单模态流)
为了应用多语言预训练,我们使用多语言单峰流作为模型输入。给定任何语言的输入文本 w [ l i ] w^{[l_i]} w[li],我们首先通过语句片段将其标记化为一系列BPE标记[18]。(需要去看看这个论文怎么标记的) 然后将文本嵌入和每个BPE标记的位置嵌入相加,得到文本表示序列。此外,在每个标记中添加嵌入[5]的语言,以指示其语言属性。具体来说,输入数据定义为:
(首先通过Sentence Piece将其转换为BPE token序列。然后将每个BPEtoken的文本嵌入和位置嵌入相加,得到一个文本表示序列。此外,还要向每个token添加语言嵌入,以指示其语言属性。输入数据定义为:)
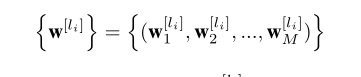
其中,M表示w的长度 w [ l i ] w^{[l_i]} w[li], l i l_i li表示语言集合l中的一种语言。我们将该流表示为 D [ X ] D^{[X]} D[X]。
单语多模态流
为了应用多模态预训练,我们使用单语多模态流作为模型输入。
给定一对英文文本和图像 ( w [ E N ] , v ) (w^{[EN]},v) (w[EN],v),得到 w [ E N ] w^{[EN]} w[EN]的文本表示序列,类似于我们在多语单模态流部分中描述的,其中英语被用作语言嵌入。
对于图像v,我们使用 Faster-RCNN[12]来检测图像区域,并使用每个区域中相应的视觉特征作为视觉特征序列。
我们还为每个视觉token添加了一个空间嵌入,这是一个5-D向量,基于其标准化的左上角、右下角坐标和所覆盖图像区域的分数。 我们使用两个完全连接(FC)层将这两个向量投影到文本表示的同一维度。
因此,将图像中每个区域的投影视觉特征向量和空间嵌入向量相加,得到图像表示序列。此外,我们在图像区域序列的开头添加一个流标记[IMG],以分离文本标记和图像标记,并将它们连接起来形成一个输入流:
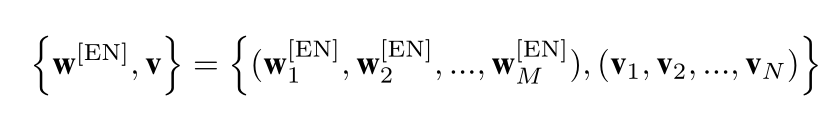
我们将该流表示为 D [ E N ] D^{[EN]} D[EN]
多模代码切换流
我们通过代码切换方法从单语多模态流生成多模态代码切换流,给定英语文本和图像对 ( w [ E N ] , v ) (w^{[EN]},v) (w[EN],v),代码切换语言C={ c 1 , c 2 , … , c k c_1,c_2,…,c_k c1,c2,…,ck}集,以及可以将一个单词从英语翻译成任何语言 c i c_i ci的双语词典。
在[27]之后,对于英文文本 w i [ E N ] w^{[EN]}_i wi[EN]中的每个单词 w [ E N ] w^{[EN]} w[EN],我们有β的概率将其替换为翻译单词。 如果一个单词有多个翻译,我们会随机选择一个。
与多语言单语流类似,我们在保持原始语言嵌入的同时,以相同的方式获得代码切换文本 w [ C ] w^{[C]} w[C]的文本表示序列* (我们试图改变代码交换流中的语言嵌入,但没有获得显著的收益。 )
与单语多模态流类似,文本和图像表示序列被连接为最终输入流:
{ ( w 1 [ d 1 ] , w 2 [ d 2 ] , . . . , w M [ d M ] ) , ( v 1 , v 2 , . . . , v N ) } {\{ (w^{[d_1]} _1 , w^{[d_2]} _2 , ..., w^{[d_M]} _M ), (v_1, v_2, ..., v_N ) }\} { (w1[d1],w2[d2],...,wM[dM]),(v1,v2,...,vN)}
这里 d i d_i di是{EN}∪ C中的一种随机语言,我们将输入序列简化为:
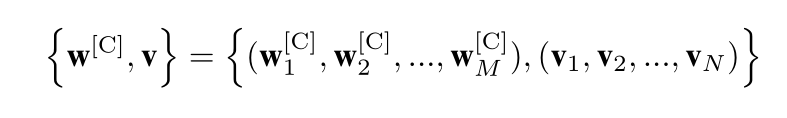
我们把这个流表示为 D [ C ] D^{[C]} D[C]。
3.2. 预训练目标
为了在多语言多模式场景下对M3P进行预训练,我们设计了两种类型的预训练目标。多语言训练 的目的是从结构良好的多语言句子中学习语法或句法。多模态代码转换训练(MCT) 旨在通过共享的视觉模态学习不同的语言,从而进行视觉和非英语文本之间的对齐。
3.2.1多语言训练
多语言屏蔽语言建模(xMLM)
与多语言BERT、XLM和Unicoder类似,该任务基于多语言语料库执行掩蔽语言建模(MLM)。在每次迭代中,每个Batch的数据由从不同语言中采样的句子组成。语言 l i l_i li的抽样概率定义为 λ l i = p l i α ∑ l i p l i α {\lambda _{ {l_i}}} = \frac{ {p_{_{ {l_i}}}^\alpha }}{ {\sum\nolimits_{ {l_i}} {p_{_{ {l_i}}}^\alpha } }} λli=∑lipliαpliα,其中 p l i {p_{_{l_i}} } pli是整个多语言语料库 l i l_i li中语言的百分比,平滑因子α设置为0.3。
(i)用特殊符号[MASK]替换它们,(ii)用随机标记替换它们,或(iii)保持它们不变
我们只使用多语单峰流D[X],因为我们不需要使用代码切换来将其扩展到多语语料库。
在每个Batch中,随机抽取15%的单词,并以80%,10%,10%的概率将单词设置为 token,随机的token和原来的token。作者只对用多语言单模态流数据进行xMLM任务。损失函数计算如下:
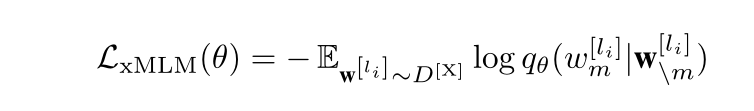
其中 w [ l i ] w^{[l_i]} w[li]是被mask的token, w / m [ l i ] w^{[l_i]}_{/m} w/m[li]为上下文
3.2.2多模式代码交换训练
由于缺乏非英语多模态的标记数据,该模型只能独立学习多语种和多模态。为了帮助模型在共享视觉模态下学习不同的语言表达,作者提出了三种多模态代码转换训练任务:MC-MLM、MC-MRM和MC-VLM。在训练这些任务时,作者用了 α 和 1-α 的比例混合多模态代码转换流 D [ C ] D^{[C]} D[C] 和单语言多模态流 D [ E N ] D^{[EN]} D[EN] ,为了简化符号,将混合数据流表示为D。并将掩码[EN]或[C]省略为[·]。
多模态代码交换掩蔽语言建模(MC-MLM)
与ViLBERT[24]和Unicoder VL[19]中的预训练任务不同,本任务旨在学习基于共享视觉模态的不同语言表示。(同一个视频不同的字幕caption) ,混合数据流D用于训练该目标。具体来说,该模型根据其周围的令牌 w m [ ⋅ ] w^{[·]}_{m} wm[⋅]和所有图像区域v,预测标题w[·]中的每个被屏蔽令牌 w / m [ ⋅ ] w^{[·]}_{/m} w/m[⋅]。
我们遵循xMLM中使用的相同屏蔽策略来屏蔽输入标题中的令牌。损失函数定义为: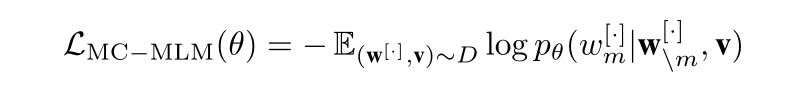
**多模式代码切换屏蔽区域建模(MC-MRM) **
本任务的目标是学习混合数据流d中以多语言文本为上下文的视觉表示方法。该模型基于剩余区域 v / n v_{/n} v/n和所有字幕token w [ ⋅ ] w^[·] w[⋅]重建每个mask图像区域 v / n v_{/n} v/n。
作者以15%的概率随机mask图像区域。每个mask图像区域的输入表示被设置为零或保持为原始值,概率分别为90%和10%。
使用FC层将每个mask区域的Transformer输出 v k v_k vk转换为具有和视觉特征 f ( v k ) f(v_k) f(vk)同维的向量 h θ ( v k ) h_\theta(v_k) hθ(vk)。然后使用交叉熵损失来预测每个mask区域的对象类别,们还应用另一个FC层来转换每个屏蔽区域vk的变压器输出,以预测K个对象类的分数,这些对象类进一步通过softmax函数转换为归一化分布gθ(vk)。
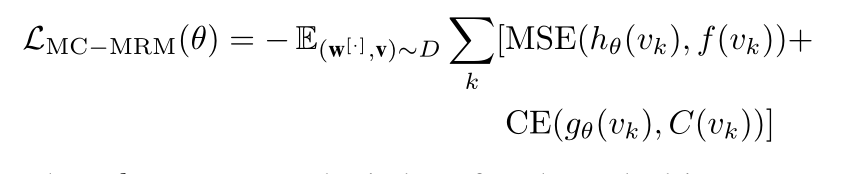
其中k为每个mask图像区域的索引, M S E ( h θ ( v k ) , f ( v k ) ) MSE(h_\theta(v_k),f(v_k)) MSE(hθ(vk),f(vk))表示将每个mask区域的Transformer输出回归到其视觉特征 f ( v k ) f(v_k) f(vk)的均方误差损失。
**多模态代码切换视觉语言匹配(MC-VLM) **
本任务旨在学习具有混合数据流D的多语言文本和图像之间的对齐。在[CLS]的Transformer输出上应用FC层 s θ ( w [ ⋅ ] , v ) s_θ(w^{[·]}, v) sθ(w[⋅],v),以预测输入图像v和输入的英语或代码切换文本 w [ ⋅ ] w^{[·]} w[⋅]是否语义匹配。
通过将匹配样本中的图像或文本替换为从其他样本中随机选择的图像或文本,可以创建负图像标题对,我们使用二元交叉熵作为损失函数:

其中,y∈{0,1}表示输入图文对是否匹配,BCE表示binary-cross-entropy loss。
4. 实验
在本节中,我们详细描述了M3P模型在预训练、微调和评估过程中的实验设置。
4.1. 数据集描述
如表1所示,我们基于多模态语料库Conceptual Captions[29]和多语言语料库Wikipedia构建了我们的训练前数据集。我们评估了M3P在Multi30K[9,8]和MSCOCO[2,25,20]两种数据集上的多语言图文检索任务。在多模态语码转换训练中,Panlex作为双语词典使用。

**4.1.3代码交换字典 **
语码转换培训使用的词汇级双语词典来自全球最大的开源词汇翻译数据库Panlex。我们将排名前50的英语提取到其他语言双语词典中。
4.2. 培训细节
与以前的视觉语言预训练模型类似,M3P模型使用与BERT[7]相同的模型架构。我们使用XLM-R[4]初始化M3P,并继续对我们的数据进行预训练。我们使用与XLM-R[4]相同的词汇表.
(i) w/o fine-tune:直接对所有测试集应用M3P,得到不需调优的评价结果。
(ii) w/ fine-tune on en:fine-tune M3P on English,然后将fine-tune模型应用于所有测试集。
(iii) w/ fine-tune on each:对每种语言的M3P进行微调,并将每种模型应用于该语言的测试集。
(iv) w/fine-tune on all:使用合并的标签数据对所有语言的M3P进行微调,然后将微调后的模型应用于所有测试集。
5. Results and Analysis

5.1。整体结果
从表2中,我们发现:
(1)我们的M3P模型在所有非英语语言中都得到了最先进的结果,显示了其令人兴奋的多语言多模态迁移能力。
(2)与Unicoder中报告的观察结果[13,22]类似,两种完全监督设置(iii) w/fine-tune on each和(iv) w/fine-tune on all可以得到最好的结果。这意味着用不同语言写的同一个句子可以捕捉到互补的信息,从而帮助提高表现。
(3)与仅使用英语图像-标题语料库(即概念标题)进行预训练的unicover - vl相比,M3P在英语测试集上表现较差。可能的原因是,M3P需要平衡其超过100多种语言的多语言能力,而不仅仅是英语。
(4)将多模态编码切换训练(Multimodal Code-switched Training, MCT)集成到M3P中,无论在w/ o微调设置还是在en上,都能在非英语数据集上取得显著的效果,说明在零镜头设置下,多模态编码切换训练具有良好的多语言迁移能力。由于M3P可以直接从标记的数据中学习图像和语言之间的对齐,因此预计在设置(iii)对每个数据进行/微调和设置(iv)对所有数据进行/微调时,这种增益会变得更小。
5.2.1 MCT的影响
为了验证多模态语码切换训练(Multimodal Code-switched Training, MCT)策略在不同的设置下是否能提供积极的效果,我们比较了在不同的微调设置下,不使用MCT的M3P策略和使用MCT的M3P策略的性能。

5.2.2 MCT中语言数量的影响

表展示了不同语言数量下训练的结果,可以看出en和cs在语言数量为5时能够达到比较好的性能。这意味着在更多语言上激活MCT会导致更多噪音,因为不准确翻译的概率更高。这种噪声可能会提高模型的鲁棒性,但会使模型更难得到良好的训练。
4.3.3. The Impact of Proposed Tasks

从表5中可以看出:
(1)MC-VLM在pre-training stage四个子任务中对模型的改善最为显著(+10.6 on en)。我们认为这是因为MC-VLM子任务成功地建模了图像和文本之间的关系。
(2)与英语结果相比,xMLM对非英语结果的影响较大,这说明xMLM将提高多语言能力。
(3) MC-MLM和MC-MRM对所有语言的结果都有很好的支持,这两个任务有助于模型学习多模态知识。
(4)当合并所有任务时,我们获得了所有语言中最高的收益。
5.3。将MCT扩展到微调

普通微调代表直接对英语数据进行微调,而MCT微调代表对语码转换的英语数据进行微调。
类似于MC-VLM,我们使用代码切换数据在Multi30K上微调M3P。表6的结果表明:
(1)多模态语码转换训练(Multimodal Code-switched Training, MCT)可以为非英语语言带来很大的优势,这可能是因为在训练前阶段或微调阶段缺乏标记图像的非英语字幕对。
(2)将MCT运用到模型的微调阶段,无论经过何种训练,都会使非英语成绩有较大的提高。
(3) MCT无限调音比MCT在训练前更有效,这可能是由于该模型可以在更具体的任务中学习多语。
(4)无论是在训练前阶段还是在微调阶段,MCT替代英语都能取得最好的效果。
5.4. MCT的定性研究
为了进一步探索多模式代码切换训练(MCT)对模型的影响,我们随机选择了一些由其生成的文本图像对。我们想找出为什么多模式代码转换培训对非英语语言非常有效,以及它是否有任何局限性。

图2:多模态语码转换训练的定性研究。每个表中的第一行是原始文本,每个表中的第二行是Code-switched文本。第三行Code-switched转换为英文的结果。。
如图2 (a)所示,多模态语码转换训练(Multimodal code-switched Training, MCT)生成的语码转换文本的意义与原文本几乎相同。虽然原始文本(第一行)和翻译成英语的生成文本(第三行)之间有一些小的差异,但这并不影响训练质量,这也说明了MCT能带来收益的原因。M3P中使用MCT的关键思想是让模型看到更多的代码转换文本和图像对,并直接从这些文本和图像对中学习联合多语言多模态表示。我们猜想,这有助于模型从多语言上下文中了解每个标记的更丰富信息。
我们不考虑用其他语言的单词翻译替换英语句子中的单词而生成的语码转换句子的语法或语法正确性。预先训练的模型可以从格式良好的多语言句子和英语字幕句子中学习这些知识。由于我们没有图像-标题对或高质量的机器翻译引擎来为大多数语言生成这样的数据,因此生成代码转换句子是让M3P直接看到非英语语言和图像之间更多对齐的最有效方法
因此,由于MCT翻译的准确性较高,在没有非英语多模态数据的情况下,多语言结果将显著增加。然而,当模型能够访问高质量的多语言多模态数据时,来自MCT的噪声可能会限制其性能。在图2 (b)中,我们展示了代码转换文本中的一个否定用例。MCT错误地改变了原文的意思。我们把这作为解决这个问题的未来工作。
6. 结论
作者在本文中提出了一个新的预训练模型M3P ,该模型通过多语言多模态场景的多任务预训练,将多语言预训练和多模态预训练结合到一个统一的框架中。此外,作者还提出了多模态代码转换训练(Multimodal Code-switched Training) ,以进一步缓解非英语多模态任务缺乏足够数据的问题。
从前的多模态和多语言的预训练模型通常只能在特定模态或者语言范围的任务中进行,而不能同时进行多模态和多语言的任务。为了解决这个问题,一个最直观的方式就是用多模态、多语言数据集进行预训练。
然而目前缺少这样的数据集,而直接将英语多模态数据集用翻译引擎转换成多语言多模态数据集又是非常耗时的。因此,作者提出了新的预训练方法,能够分别用多模态数据集和多语言数据集联合训练多模态、多语言模型 。