介绍
词汇表征的相似性超越了简单的句法规则。使用单词偏移技术,在单词向量上执行简单的代数运算,例如向量(”King”) - 向量(”Man”) + 向量(”Woman”)生成的向量最接近单词 Queen 的向量表示
在本文中,我们尝试通过开发新的模型体系结构来最大化这些向量操作的准确性,该体系结构保留了字之间的线性规律。此外,我们还讨论了训练时间和准确性如何依赖于词向量的维数和训练数据的数量
一种非常流行的神经网络语言模型 (NNLM) 估计模型结构,该结构使用一个带有线性投影层和非线性隐藏层的前馈神经网络来联合学习词向量表示和统计语言模型。
其中单词向量首先使用单一隐藏层的神经网络学习。然后使用向量这个词来训练 NNLM。因此,即使不构造完整的 NNLM,也可以学习单词向量。
为了比较不同的模型架构,我们首先将模型的计算复杂度定义为能够完全训练模型的参数数量。接下来,我们将尝试最大化准确性,同时最小化计算复杂性。
Feedforward Neural Net Language Model(NNLM)
由于投影层中的值密集,NNLM 架构在投影和隐藏层之间的计算变得复杂。
在我们的模型中,我们使用层次化 softmax,其中词汇表被表示为霍夫曼二叉树。 这是根据先前的观察结果得出的,即在神经网络语言模型中,用词频获取类别非常有效
霍夫曼树将短的二进制代码分配给频繁的单词,这进一步减少了需要评估的输出单元的数量
Recurrent Neural Net Language Model(RNNLM)
递归神经网络的语言模型来克服前馈NNLM的某些限制,例如需要指定上下文长度(模型 N 的顺序),因为理论上 RNN 可以比浅层神经网络更有效地表示更复杂的模式
RNN 模型没有投影层。 仅有输入、隐藏和输出层。 这种类型的模型的特殊之处在于递归矩阵,它使用延时连接将隐藏层与其自身相连。 这允许循环模型形成某种短期记忆,因为过去的信息可以由隐层状态表示,该隐层状态根据当前输入和上一步时间的隐层状态进行更新。
新的对数线性模型
提出了两种新的模型体系结构,用于学习单词的分布式表示形式,以尽量减少计算复杂性。 上一节的主要观察结果是,大多数复杂性是由模型中的非线性隐藏层引起的。 虽然这是使神经网络如此吸引人的原因,但我们决定探索更简单的模型,这些模型可能无法像神经网络那样精确地表示数据,但可能可以有效地训练更多的数据。
首先,使用简单的模型学习连续的词向量,然后在这些词的分布式表示之上训练 N-gram NNLM。
Continuous Bag-of-Words Model
第一个提出的体系结构类似于前馈 NNLM,其中非线性隐藏层被删除,投影层共享所有单词(不仅仅是投影矩阵) ,因此,所有单词被投影到相同的位置(它们的向量被平均)。我们称这种结构为词袋模型。因为历史文字顺序并不影响投影。
此外,我们还使用来自未来的单词,通过构建四个未来单词和四个历史单词的对数线性分类器。
我们将该模型进一步表示为 CBOW,因为与标准的词袋模型不同,它使用了上下文的连续分布式表示。模型架构如图1所示。请注意,对于所有单词位置,输入和投影层之间的权重矩阵与 NNLM 中的方式相同。
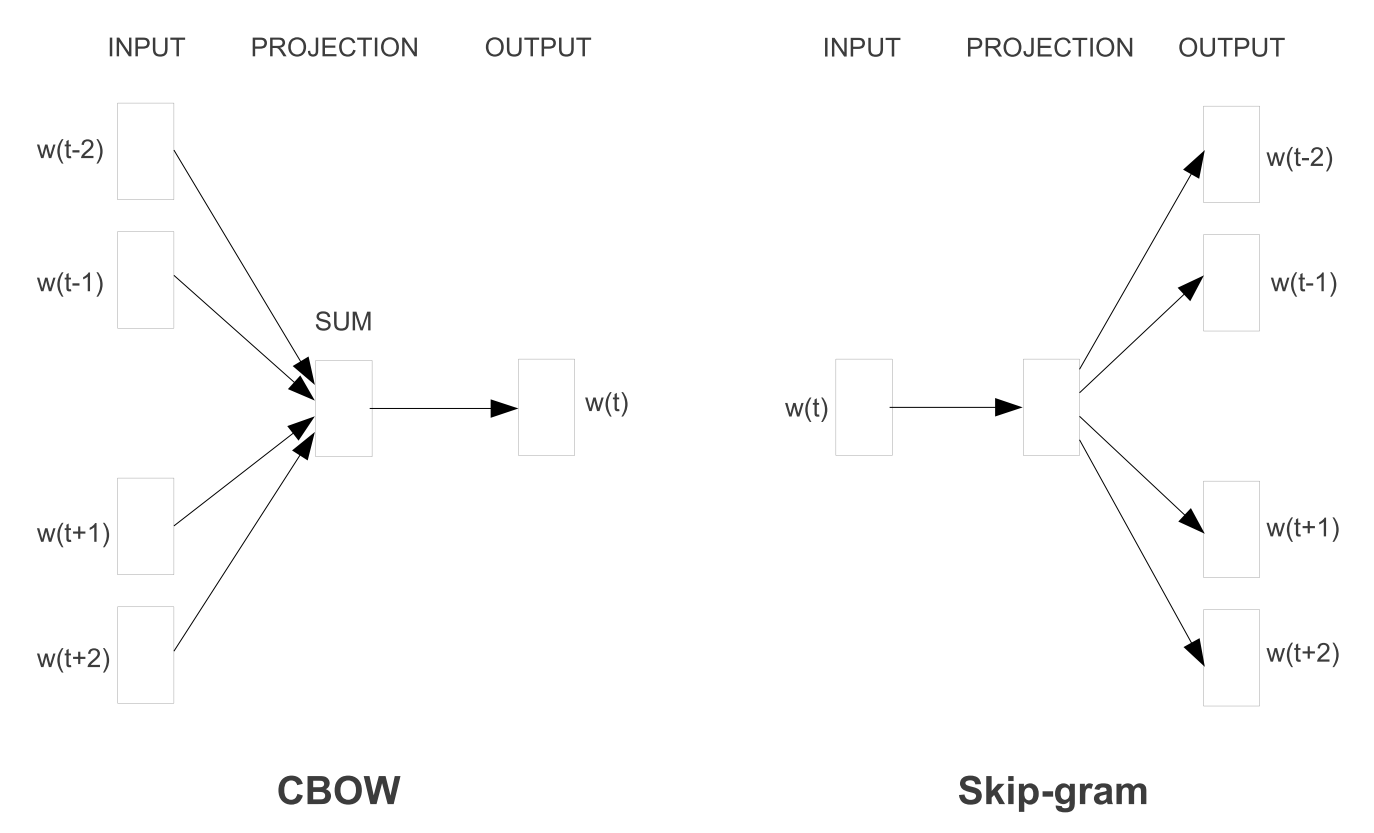
Continuous Skip-gram Model
第二个体系结构类似于 CBOW,我们将每个当前词作为具有连续投影层的对数线性分类器的输入,并预测当前词之前和之后一定范围内的词。我们发现,增加范围提高了结果词向量的质量,但也增加了计算复杂度。
由于较远的单词与当前单词的相关性通常低于与当前单词接近的单词,我们从这些单词中抽取较少的样本,从而减少了较远单词的权重。
结果
以前的论文通常使用一个表格来展现示例单词及其最相似的单词,很容易显示单词 France 与 Italy 相似,也许还与其他一些国家相似,
单词之间可以有许多不同类型的相似之处,例如,单词 BIG类似于 Bigger,在相同的意义上,Small 类似于 Small。另一种类型的关系的示例可以是词对 big-biggest 和 small-smallest。我们进一步将两对具有相同关系的词作为一个问题。
因为我们可以问:“在最大类似于大的相同意义上,什么词类似于小?“
这些问题可以通过对单词向量执行简单的代数运算来回答。要找到与“最大”与“大”意义相同的与“小”相似的单词,我们只需计算 X=向量(“最大”)−向量(“大”)+向量(“小”)。
然后在向量空间中搜索通过余弦距离测量最接近 X 的单词,并将其用作问题的答案(在此搜索过程中,我们将丢弃输入的问题单词)。当词向量训练得很好时,可以使用此方法找到正确答案(词最小)
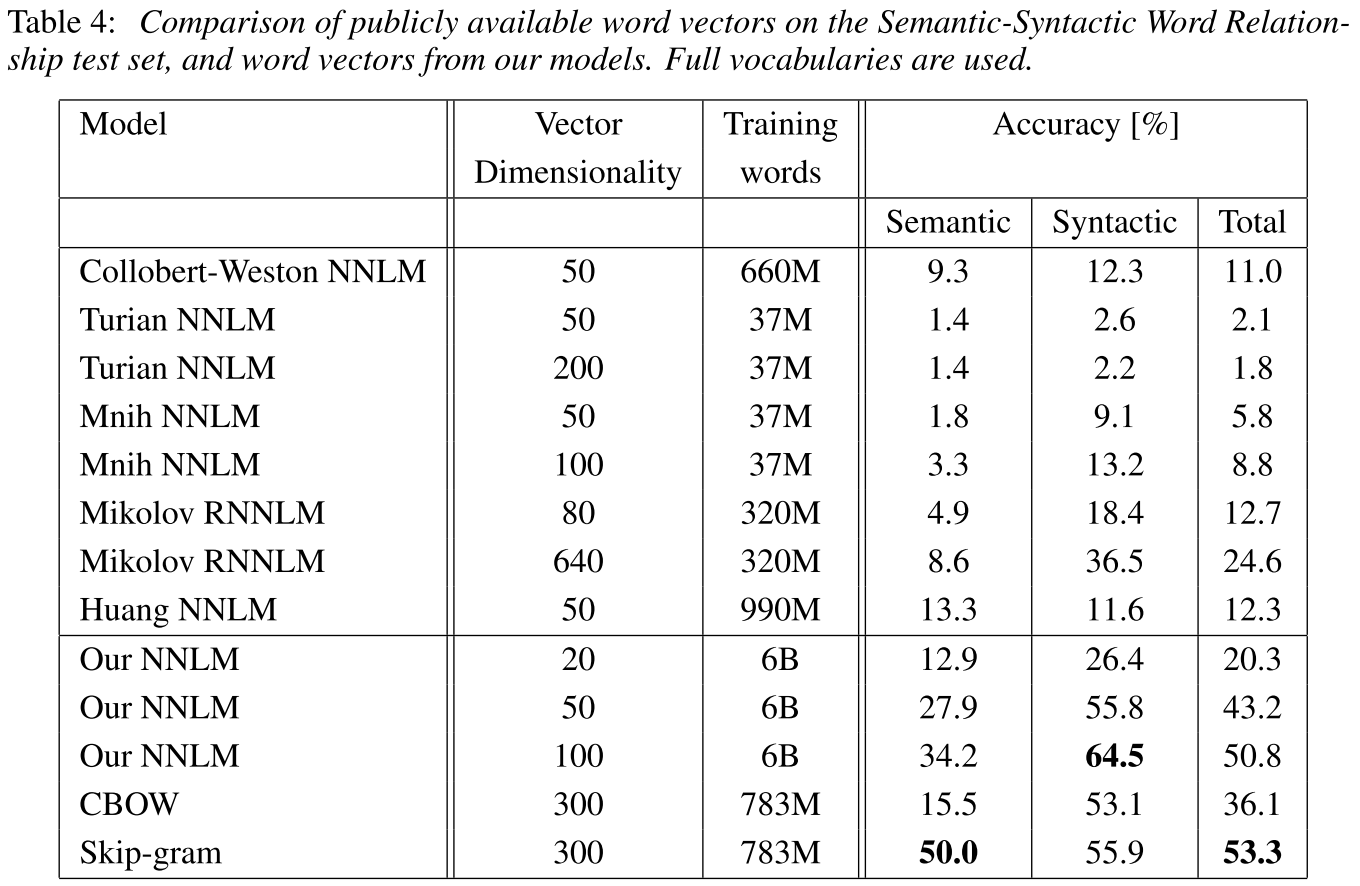
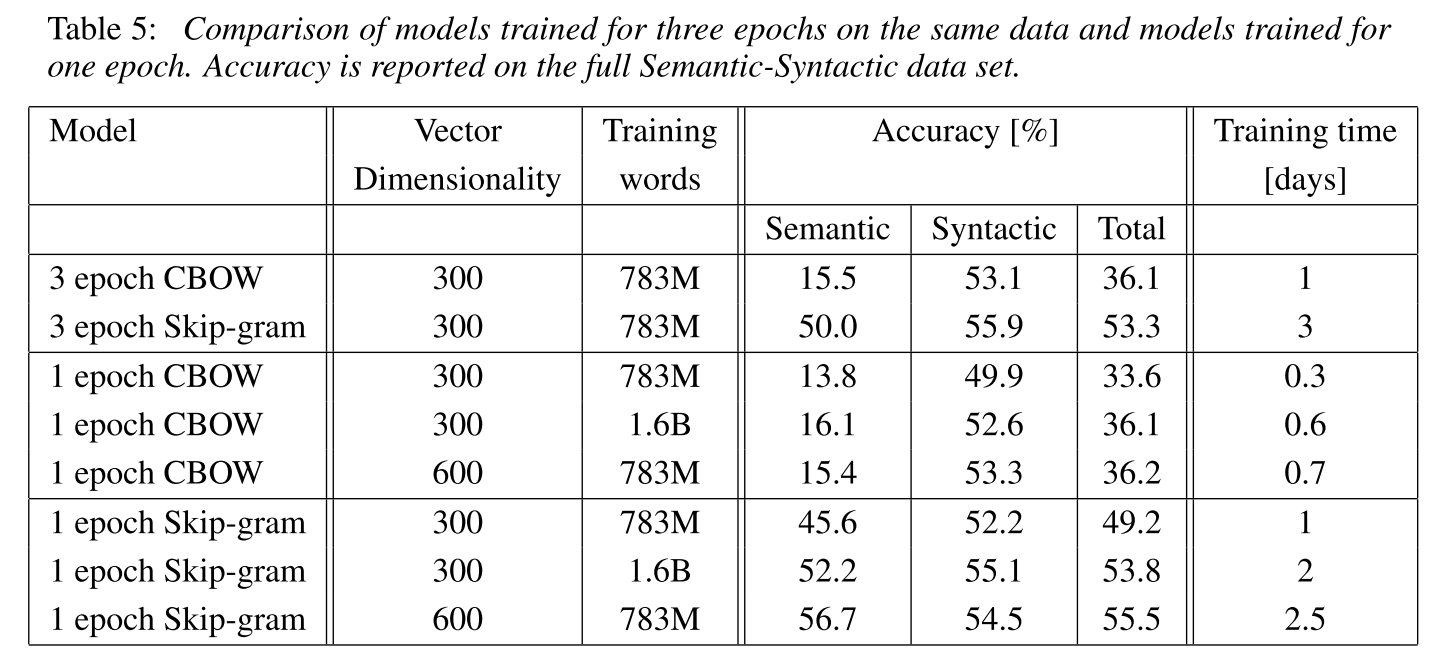
实验结果上 Skip-gram 是比较好的