1 介绍
提示调优只使用冻结的语言模型来调优连续的提示,这大大减少了每次任务的存储和训练时的内存使用。然而,在NLU的背景下,先前的工作表明,对于正常大小的预训练模型,即时调优并不能很好地执行。还发现,现有的提示调优方法无法处理硬序列标记任务,这表明缺乏通用性。论文提出了一个新的经验发现,即适当优化的prompt tuning可以在广泛的模型规模和NLU任务中普遍有效。它与微调的性能相匹配,同时只有0.1%-3%的微调参数。P-Tuning v2是针对NLU优化和调整的深度提示调整(Li和Liang,2021;Qin和Eisner,2021)的实现。
预训练语言模型(Radford等人,2019;Devlin等人,2018;Yang等人,2019年;Raffel等人,2019)提高了在各种自然语言理解(NLU)任务中的表现。一种广泛使用的方法,即微调,更新目标任务的整个模型参数集
。虽然微调可以获得良好的性能,但在训练过程中会消耗内存,因为必须存储所有参数的梯度和优化器状态。此外,在推理过程中为每个任务保留模型参数的副本是不方便的,因为预训练的模型通常很大。
Prompting。提示冻结预训练的模型的所有参数,并使用自然语言提示来查询语言模型(Brown et al.,2020)。例如,对于情感分析,可以将一个样本(例如,“Amazing movie!”)与提示“This movie is[MASK]”连接起来,并要求预训练的语言模型预测掩码标记为“good”和“bad”的概率,以决定样本的标签。提示根本不需要训练,并且只存储一个模型参数的副本。然而,与微调相比,离散提示(Shin等人,2020;Gao等人,2020)在许多情况下可能导致次优性能。
Prompt tuning。提示调整是一种只调整连续提示的想法。具体而言,Liu等人(2021);Lester等人(2021)建议在输入词嵌入的原始序列中添加可训练的连续嵌入(也称为连续提示)。只有持续提示在训练期间才会更新。虽然在许多任务中,提示调整优于提示(Liu等人,2021;Lester等人,2021;Zhong等人,2021),但当模型规模不大,特别是小于100亿个参数时,它仍然表现不佳(Lester等人(2021)。此外,如实验所示,与在几个硬序列标记任务(如提取式问答)上的微调相比,prompt tuning表现不佳(参见第4.2节)。
在本文中的主要贡献是一项新的经验发现,即适当优化的即时调整可以与在各种模型尺度和NLU任务中普遍进行的微调相媲美。与先前工作中的观察结果相比,论文的发现揭示了NLU快速调整的普遍性和潜力。
从技术上讲,P-tuning v2在概念上并不新颖。它可以被视为针对生成和知识探索而设计的深度提示调节(Li和Liang,2021;Qin和Eisner,2021)的优化和适应性实现。最显著的改进源于对预训练模型的每一层应用连续提示,而不仅仅是输入层。深度提示调整增加了连续提示的能力,并缩小了在各种设置之间进行微调的差距,尤其是对于小模型。此外,还介绍了优化和实现的一系列关键细节,以确保对可比性能进行微调。
实验结果表明,P-tuning v2在300M到10B参数的不同模型尺度上以及在提取问答和命名实体识别等各种序列标记任务上的微调性能相匹配。与微调相比,P-tuning v2每个任务具有0.1%至3%的可训练参数,这大大降低了训练时间内存成本和每个任务的存储成本。
2 准备工作
NLU任务。在这项工作中,将NLU挑战分为两类:简单分类任务和序列标记任务。简单分类任务涉及标签空间上的分类。GLUE(Wang et al.,2018)和SuperGLUE(Wang et al.,2019)的大多数数据集都属于这一类。序列标记任务涉及对tokens序列的分类,例如命名实体识别和抽取式问答。
Prompt Tuning。设V是语言模型M的词汇表,设e是M的嵌入层。在离散提示的情况下(Schick和Schütze,2020),提示标记{“It”、“is”、“[MASK]”}⊂V可以用于对影评进行分类。例如,给定输入文本x=“Amazing movie!”,输入嵌入序列被公式化为[e(x),e(“It”),e(“is”),e(“[MASK]”)]。
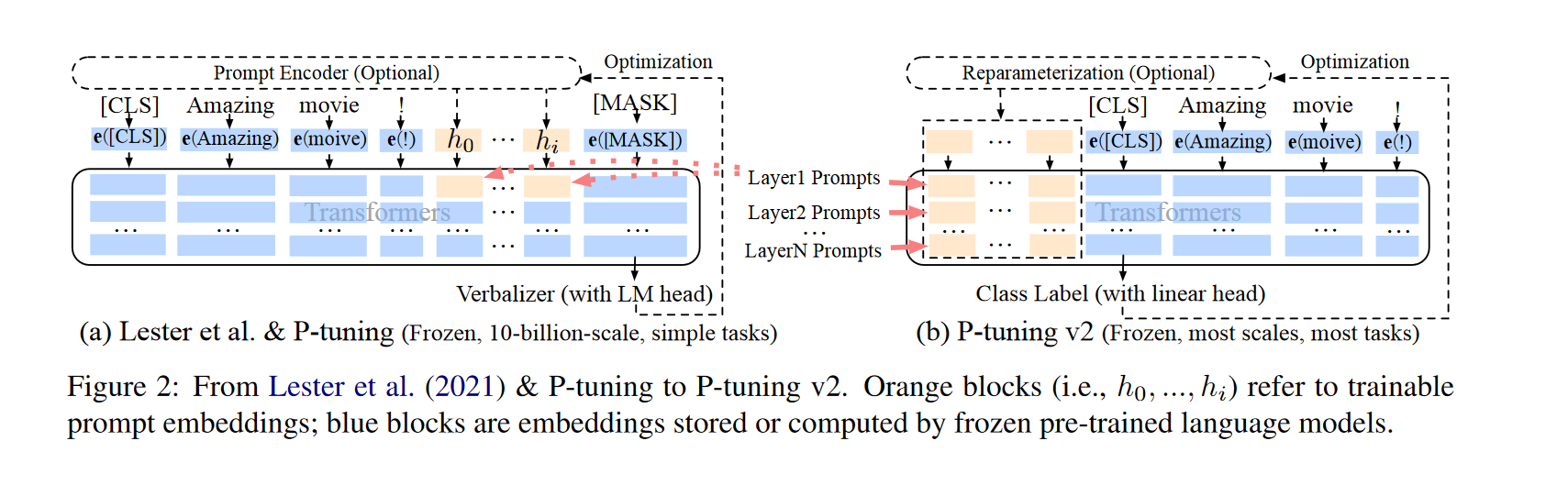
Lester等人(2021)和Liu等人(2021)引入了可训练的连续提示,以取代自然语言提示,并冻结了预处理语言模型的参数。给定可训练的连续嵌入[h0,…,hi],输入嵌入序列被写成[e(x),h0,..,hi,e(“[MASK]”)],如图2所示。对于简单分类任务,Prompt tuning已被证明与100亿参数模型的微调相当(Lester等人,2021;Kim等人,2021;Liu等人,2021)。
3 P-Tuning v2
3.1 缺乏普遍性
Lester等人(2021);Liu等人(2021)已被证明在许多NLP应用中相当有效(Wang等人,2021a,b;Chen等人,2021;Zheng等人,2021;Min等人,2021),但由于缺乏通用性,在替换微调方面仍存在不足,如下所述。
缺乏跨尺度的普遍性。Lester等人(2021)表明,当模型的参数扩展到100亿以上时,快速调整可以与微调相媲美。然而,对于广泛使用的中型模型(从100M到1B),prompt tuning的性能要比微调差得多。
缺乏跨任务的通用性。尽管Lester等人(2021);Liu等人(2021)在一些NLU基准测试中表现出了优越性,快速调整硬序列标记任务的有效性尚未得到验证。序列标记预测每个输入标记的标签序列,这可能更难,并且与动词化符不兼容(Schick和Schütze,2020)。在实验中(参见第4.2节和表3),表明Lester等人(2021);与微调相比,Liu等人(2021)在典型序列标记任务中表现不佳。
考虑到这些挑战,建议使用Ptuning v2,它采用deep prompt tuning(Li和Liang,2021;Qin和Eisner,2021),作为跨尺度和NLU任务的通用解决方案。
3.2 Deep Prompt Tuning
在(Lester等人,2021)和(Liu等人,2021)中,连续提示仅插入到输入嵌入序列中(参见图2(a))。这导致了两个挑战。首先,由于序列长度的限制,可调参数的数量是有限的。其次,输入嵌入对模型预测具有相对间接的影响。
为了应对这些挑战,P-tuning v2采用了deep prompt tuning的思想(Li和Liang,2021;Qin和Eisner,2021)。如图2所示,不同层中的提示被添加为前缀标记。一方面,P-tuning v2具有更多可调的任务特定参数(从0.01%到0.1%-3%),以允许更多的每任务容量,同时具有参数效率;另一方面,添加到更深层次的提示对模型预测有更直接的影响。
3.3 优化与实现
有一些关于优化和实现的有用细节,以实现最佳性能。
重参数化:之前的工作通常利用重参数化编码器,如MLP(Li and Liang,2021;Liu et al.,2021)来转换可训练嵌入。然而,对于NLU,发现它的有用性取决于任务和数据集。对于一些数据集(例如RTE和CoNLL04),MLP带来了一致的改进;对于其他人,MLP对结果的影响最小甚至是负面的(例如,BoolQ和CoNLL12)。
Prompt Length。提示长度在P-Tuning v2中起着至关重要的作用。发现,不同的NLU任务通常在不同的提示长度下实现最佳性能。一般来说,简单的分类任务更喜欢较短的提示(少于20个)。序列标记任务更喜欢较长的任务(大约100个)。
多任务学习。在对单个任务进行微调之前,多任务学习通过共享的连续提示联合优化多个任务。多任务对于P-Tuning v2是可选的,但可以通过提供更好的初始化来进一步提高性能(Gu等人,2021)。
Classification Head。使用语言模型头预测verbalizers(Schick和Schütze,2020)一直是prompt tuning的核心(Liu等人,2021),论文发现在全数据环境中没有必要,并且与序列标记不兼容。P-tuning v2将随机初始化的分类头应用于tokens之上,如BERT中所示(Devlin等人,2018)(参见图2)。

为了阐明P-调优v2的主要贡献,在表1中对现有的即时调优方法进行了概念比较。
4 实验
在不同的常用预训练模型和NLU任务上进行了广泛的实验,以验证P-tuning v2的有效性。在本工作中,除微调外,所有方法均使用冻结语言模型主干进行,这符合(Lester等人,2021)的设置,但不同于(Liu等人,2021)的tuned设置。
任务特定参数的比率(例如,0.1%)是通过比较连续提示的参数和Transformer的参数得出的。另一件需要注意的事情是,实验都是在完全监督的环境中进行的,而不是在few-shot
NLU任务。首先,包括SuperGLUE(Wang et al.,2019)的数据集,以测试P-tuning v2的一般NLU能力。此外,引入了一系列序列标记任务,包括命名实体识别(Sang和De Meulder,2003;Weischedel等人,2013;Carreras和Màrquez,2004)、抽取式问答(Rajpurkar等人,2016)和语义角色标注(Carreras and Màr quez,2005;Pradhan等人,2012)。
预训练模型。包括Bert-Large(Devlin等人,2018年)、Roberta-Large(Liu等人,2019年)、Deberta-XLarge(He等人,2020年)、GLMXLarge/XXLarge(Du等人,2021年)进行评估。它们都是为NLU任务设计的双向模型,覆盖从大约300m到10b的各种尺寸。
多任务学习。对于多任务设置,将每个任务类型中数据集的训练集进行组合(例如,对语义角色标记的所有训练集进行梳理)。为每个数据集使用单独的线性分类器
4.1 P-tuning v2: Across Scales
表2展示了P-tuning v2在模型规模上的性能。在SuperGLUE中,Lester等人(2021)的性能和较小规模的P-tuning 可能相当差。相反,P-tuning v2以较小的规模匹配所有任务中的微调性能。P-tuning v2甚至显著优于RTE上的微调。

就GLM的大尺寸模型(2B到10B)而言(Du等人,2021),Lester等人(2021)之间的差距;Liu等人(2021)和微调逐渐缩小。在10B尺度上,有一个类似的观察结果,正如Lester等人(2021)所报告的那样,prompt tuning与微调之间存在竞争。也就是说,P-tuning v2总是可与所有尺度的微调相比较,但与微调相比,只需要0.1%的任务特定参数。
4.2 P-tuning v2:跨任务
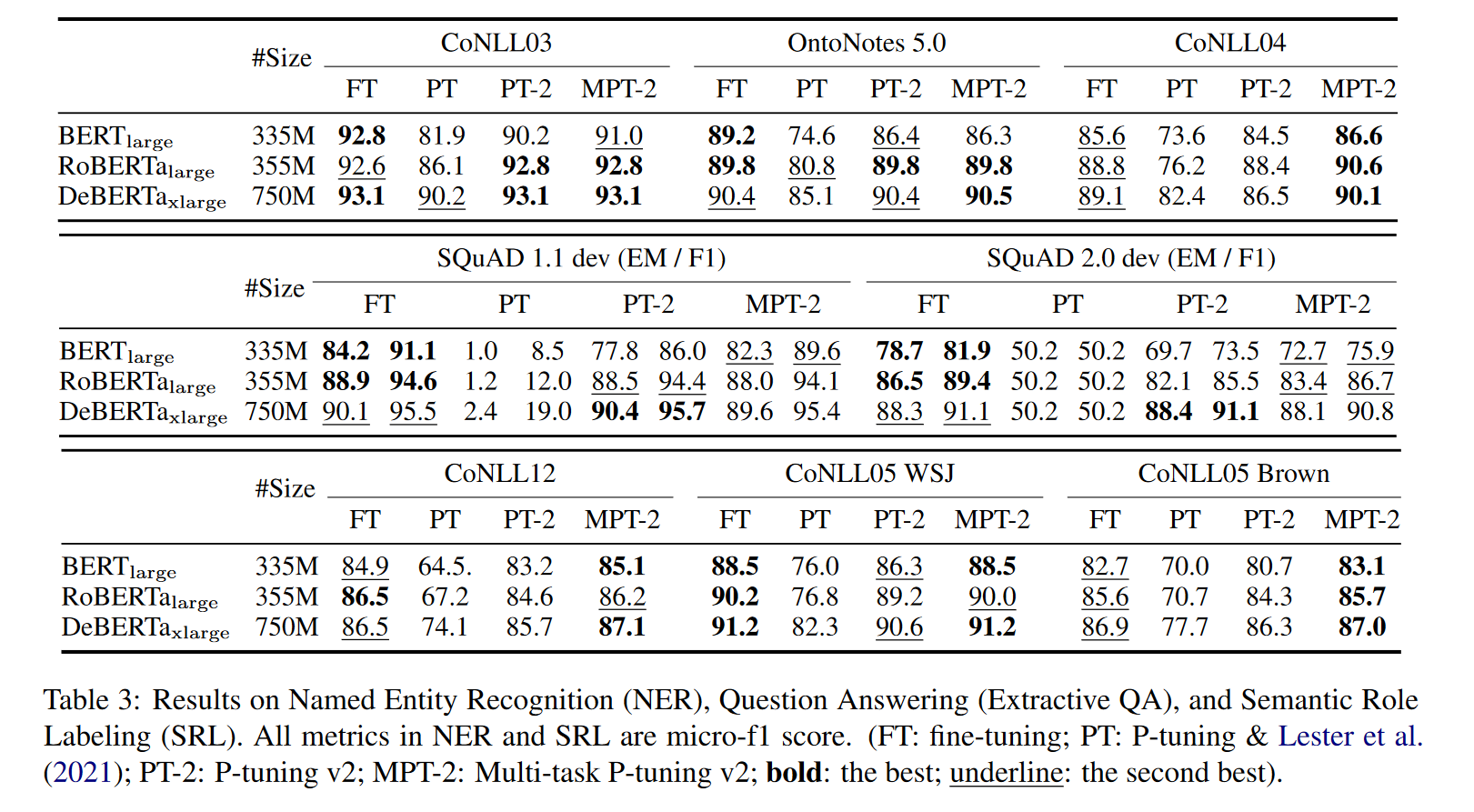
从表3中,观察到P-tuning v2通常可以与所有任务的微调相媲美。Ptuning和Lester等人(2021)的表现要差得多,尤其是在QA方面,这可能是三项任务中最具挑战性的。还注意到,Lester等人(2021)和SKuAD 2.0上的P-tuning有一些异常结果。这可能是因为SQuAD2.0包含无法回答的问题,这会给单层即时调优带来优化挑战。与除QA之外的大多数任务相比,多任务学习通常会给P-Tuning v2带来显著的改进。
4.3 消融研究

Verbalizer with LM head v.s. [CLS] label with linear head。在以前的提示调优方法中,带有LM头的描述器一直是一个核心组件。然而,对于监督设置中的P-tuning v2,可以用大约几千个参数来tuning线性头。在表4中给出了我们的比较,其中保留了其他超参数,只将带有线性头的[CLS]标签更改为带有LM头的动词化器。这里,为了简单起见,对SST-2、RTE和BoolQ使用“true”和“false”;CB的“true”、“false”和“neutral”。结果表明,描述器和[CLS]的性能没有显著差异。

Prompt深度。Lester等人(2021)之间的主要差异;(Liu等人,2021)和P-tuning v2是多层连续提示。为了验证其确切影响,给定一定数量的k层来添加提示,以升序和降序选择它们来添加提示。对于其余的图层,保持原样。如图3所示,对于相同数量的参数(即要添加提示的Transformer层的数量),按降序添加总是比按升序添加好。在RTE的情况下,仅向层17-24添加提示可以产生与所有层非常接近的性能。