LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-into Attention论文解读
Introduction
作者之处最近大语言模型获得了学术界与工业界广泛的关注,LLMs展现出了很不错的能力。用指令或者提示可以生成专业的、复合上下文的对话,然而 instruction- f following的 models 受限于 闭源的数据与算力。
Alpaca是一个用self- instruction 生成的数据通过完全微调LLaMA得到的模型。它只需要175个qa数据,通过self-instruction生成了52k对qa数据,它的性能接近于gpt3.5。
作者指出完全微调LLaMA仍然消耗时间,不支持多模态,对不同的下游任务十分臃肿。
在这篇文章,作者在模型的higher layers添加了一个可学习adaption prompts 作为prefix 注入到 new instruction。为了避免在训练初期的噪声,修改插入层的普通注意机制为零初始注意力,有一个可学习的门控因素。
总之,它有如下优点:
- 1.2M的参数达到了与Alpaca完全微调类似的能力。
- 1小时的微调时间。
- 灵活的的切换下游任务。
- 支持多模态。
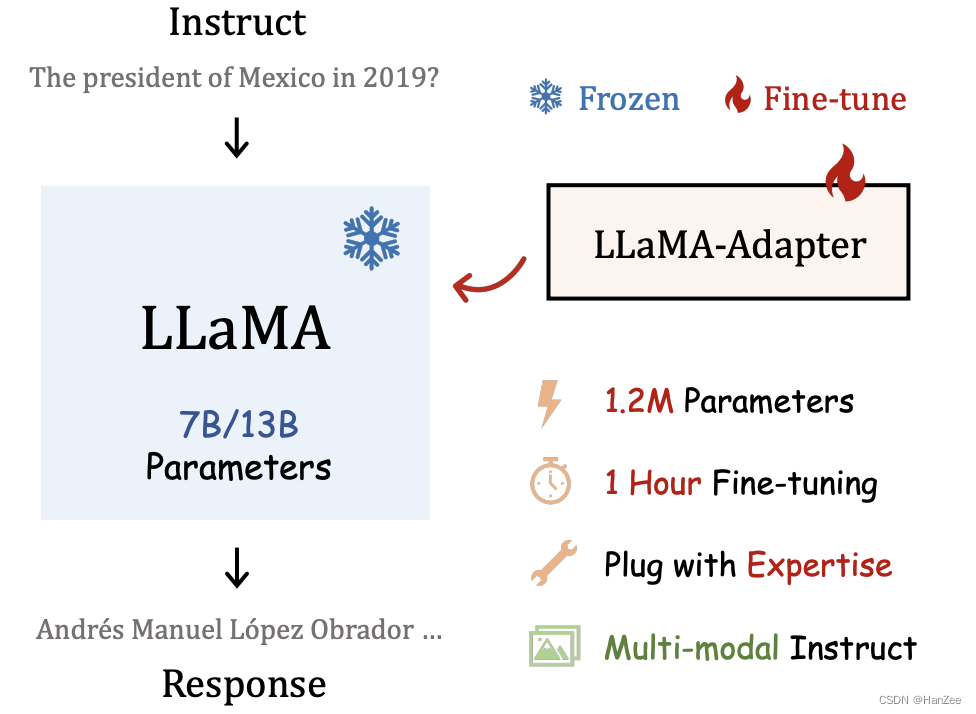
LLaMA-Adapter
Learnable Adaption Prompts
给定52k的qa数据,n层的PLM:LLaMA,定义对于L层transformer的prompt表示为:

其中K表示prompt的长度,C表示model的hidden_dimension。
L<N,L表示最多插入prefix的层,N表示模型的层数,作者表示这可以用高级语义更好地调整语言表示。
定义model原始每层 有M个token,两者结合表示为:
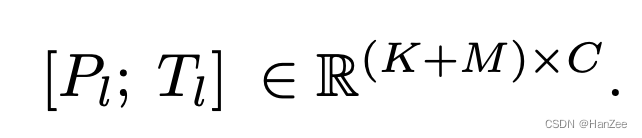
作者认为以这种方法,Pl可以高效的指导每层Tl的输出。(我感觉这里有点像P-tuningV2)。
Zero-init Attention
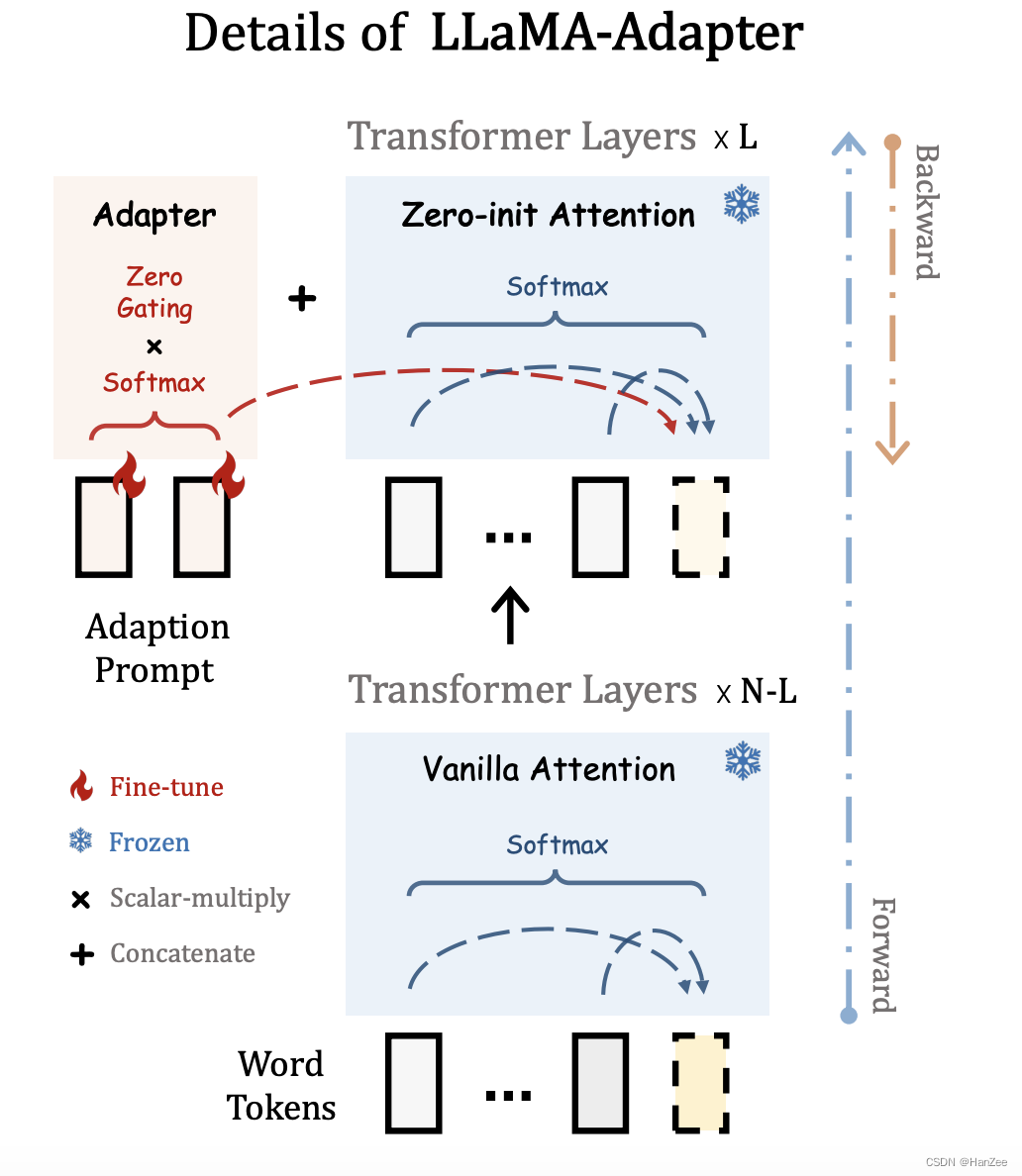
如上图,在原始方法中,预测黄色的token,需要考虑黄色与它的前面所有的token,当给这一层网络加上前缀后(采用随机初始化),在模型训练初期,可能会引入噪声,造成前期训练不稳定。
作者把原始的Vanilla Attention换成了 Zero-init Attention,为了减少噪声,作者引入了一个可学习的Zero Gating,把它初始化为零,与前缀做乘法。
第二点改进就是在计算attention score的时候会对所有token(方便说明,实际是根据是q*k的那个公式)计算softmax,作者把前缀与原有的token分别计算。
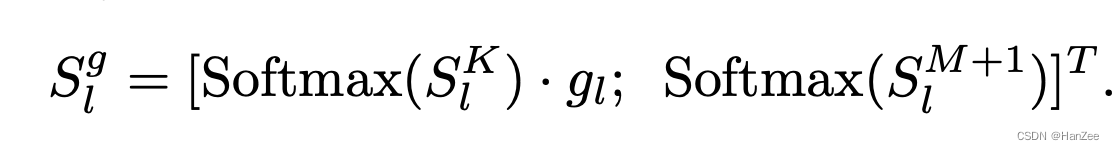
然后通过linear得到下一层的结果。
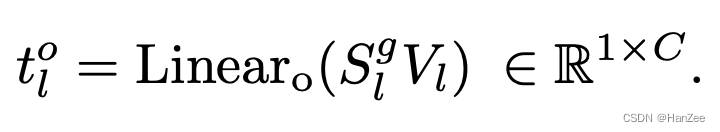
实验
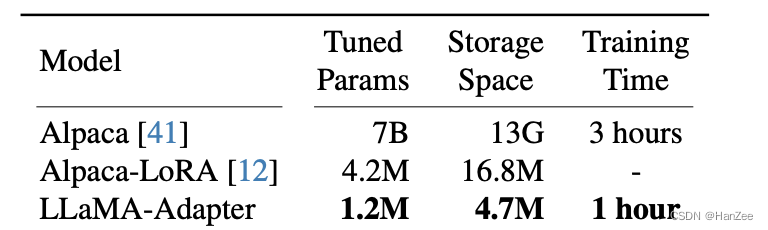
可训练参数比 lora 还少,训练时间相比于原始 alpaca-llama 降低 3 倍
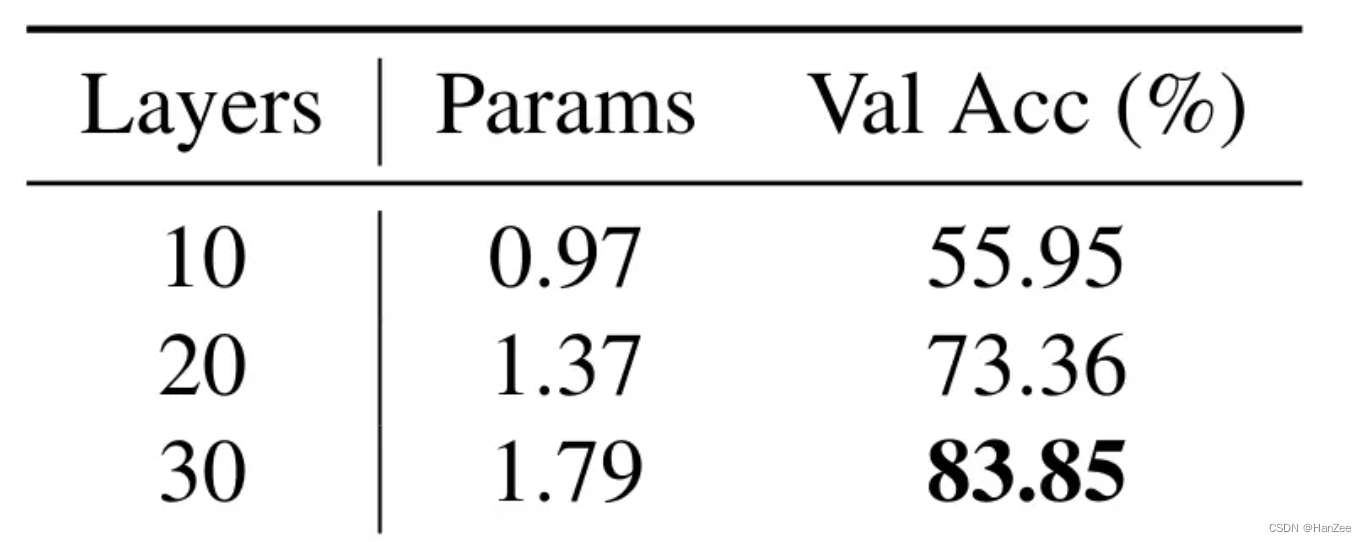
增加 adapter 的训练层数,可以看到增加更多训练层的精度会更好
零初始化效果

方法对过拟合问题较为鲁棒,训练 60 epoch 情况下 acc 是最高的。