Title:Non-stationary Transformers: Exploring the Stationarity in Time Series Forecasting
Publication:NeuralPS
Author:Tsinghua University
Published Date:2022
Page:1~10(文章内容)、10~22(细节)
Score:优秀
 https://github.com/thuml/Nonstationary_Transformers
https://github.com/thuml/Nonstationary_Transformers| 类型 |
思路 |
| 研究背景 |
由于全局范围建模能力,目前transformer在时序预测中很强,但是在联合分布随时间变化的非平稳数据集上模型能严重退化,所以提出一个非平稳transformer的通用框架。能够在平稳化的同时,解决丢失特征的问题为本文解决的中心问题。 关键词:非平稳时间序列,Transformers |
| 方法和性质 |
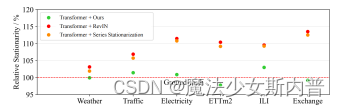
研究对象为时间序列预测任务。 将序列平稳化(如序列分解、归一化)是时间序列预测中的常见手段,平稳后更好预测,一般会提高预测性能。但本文认为,平稳化会存在过度平稳化的问题,导致对于有着不同属性特征的序列,Transformer模型学到的Attention Map很相似,如下图所示:三个不同时段的序列,直接用到Transformer时Attention Map不相似,但平稳化吼在用却很相似,这就是过度平稳化。 因此问题产生: 如何在利用平稳化提高可预测性能的同时,解决过度平稳化的问题呢?
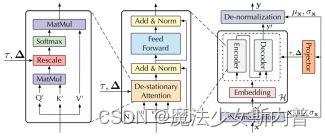
本文提出一个框架如下:包括两个主要模块。一个是平稳化模块(Series Stationarization)用来进行序列平稳化(提高可预测性),一个是去平稳化注意力机制(De-stationary Attention)用来缓解过渡平稳化问题。
1. Series Stationarization 序列平稳化两个模块:输入时归一化(Normalization module)和输出时逆归一化(De-normalization module),归一化计算出的均值和方差会送到归一化层,来还原序列的统计特征。 Normalization module:求均值和方差,将序列归一化再送入模型。 De-normalization module: 利用上面的均值和方差逆归一化。 2. De-stationary Attention 因为我们输入的是平稳化的模型,所以算出的Attention也是平稳化后的序列,存在过度平稳化的问题。但希望得到:模型中的Attention Martrix实际上是非平稳序列的,所以本模块的目的是通过平稳后序列的Attention Matrix来近似原始非平稳序列的Attention Matrix。 推导如下: (Q′, K′, V′ 是由平稳化后序列得到的,而Q, K, V 是由平稳化前序列得到的。) 平稳化前的序列计算Attention如下,其实是我们的目标: (1) 由于平稳化过程是一个归一化过程,可以将平稳化化后的Q′K′T展开为:
然后将(2)带入(1)可得我们目标的Attention Martrix可改写成:
其中后两项是重复在每列操作,都不影响Softmax后的结果。比如对矩阵的任意一行来说,后两项就相当于为该行的每一个元素加上同样的值,并由于Softmax是对矩阵的每一列操作,所以是否加这个相同的值对Softmax的结果没有影响。因此可以直接去掉后两项,(3)直接化简为:
式子4等号后面的第一项中有Q′K′T,这个其实就是平稳后序列的Attention Matrix。所以,式子4搭建了一个从平稳后序列的Attention Matrix来得到平稳前原始序列的Attention Matrix(即我们的目标)的桥梁。 除了Q′K′T,式子4还包括, σx2,(KμQ)T ,但这些是无法从平稳后序列中得到的。因此,可以使用MLP来学习这两个量,即使用额外的两个MLP,一个用来学 τ=σx2 (注意这个量是正数,因此可以学它的对数),另一个用来学 Δ=KμQ ,这里的 τ,Δ 也被称为去平稳因子(de-stationary factors)。MLP的输入其实就是未平稳原始序列及其统计量。注意,要学习的量 σx2和Series Stationarization中的σx2并不一致,因为Series Stationarization中的σx2是整个模型的输入的方差,而要学习的量 σx2是每一层Attention layer的输入的方差,但论文中作者共享所有层Attention layer的去平稳因子。 综上,整个的De-stationary Attention可以写为:
|
| 研究结果 |
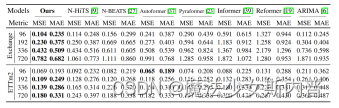
效果非常好 采用的数据集为时序任务中常用的数据集: 在Transformer上降低了49.43%的MSE,在Informer上降低了47.34%,在Reformer上降低了46.89。尤其是在长期预测上,表现突出。
提出的非平稳transformer持续大幅提升四款主流transformer性能,并在六个真是数据集中达到SOTA。 |
| 数据 |
实验结论数据:
相对平稳性检验:
|
| 结论 |
本文从平稳性的角度来探讨时间序列预测。 与以往简单地减弱非平稳性导致过平稳化的研究不同,提出了一种有效的方法来提高序列平稳性,并更新内部机制来重新合并非平稳信息,从而同时提高数据的可预测性和模型预测能力。 实验表明,其在六个真实的基准上显示了良好的通用性和性能。并提供了详细的推导和消融,以证明在我们提出的非平稳transformer框架中每个组件的有效性。 |
| 研究展望 |
在未来将会探索与模型无关的过平稳化问题的解决方案。因为本文只是依托transformer方法的。 Limitation: De-stationary Attention是通过分析self-attention推导出来的,这可能不是高级注意机制的最佳解决方案。projector也有进一步发展的潜力,包括更多的归纳偏置。此外,所提出的框架仅限于基于transformer的模型,而任何深度时间预测模型如果使用不适当的平稳化方法都可能出现过平稳问题。因此,对过平稳问题的模型不可知的解决方法将是我们今后的探索方向。 |
| 重要性 |
更好地预测未来。Transformer目前是应用比较广泛的方法,有很强的全局建模能力。但是在实现非平稳数据预测时,性能会严重退化,于是大家都想出来先平稳化再预测,对时间序列进行校区非平稳化预处理已被普遍认可,相关研究也是热点,但是平稳化又会丢失很多特征信息,这对现实世界突发事件预测的指导意义不大。所以提出了过平稳化问题的解决方案,来解决平稳化操作带来的一些问题。 |
| 想法和问题 |
Series Stationarization用到的两个模块应该参考了Reversible instance normalization for accurate time-series forecasting against distribution shift(RevIN)【这是一篇2022发表在ICIR上的文章,后续看完SCINet会看】,而且实验证明Series Stationarization和RevIN的效果差不多。不过这都是受到Batch Normalization、Layer Normalization的启发就是了,这些Normalization的方式就是先归一化后又逆归一化,只不过时间序列中逆归一化的参数不是学的,是归一化时的统计量得到的,这也符合直觉,即输入序列的均值和方差应该和输出序列的均值和方差大致相同。 De-stationary Attention的设计非常巧妙,用理论推出了新的Attention的形式,但推导的两个假设在非线性激活条件下就不成立了。在计算时,里面的关键是去平稳因子,因为这是避免过渡平稳化现象的核心。但是作者并没有展示关于学习到的去平稳因子、Attention Matrix以及它们具体是怎么作用的。不过其他的定量实验还是很充足的。 |







引用参考:
Non-stationary Transformers: Rethinking the Stationarity in Time Series Forecasting - 知乎
本文仅自学使用,有任何问题可评论指出。