文章侧重点
本文的出发点是认为现有的多阶段Siamese追踪框架【特征提取-特征融合-边界框预测】的前两步【特征提取-特征融合】统一完成。原本【特征提取】是对template、Search Region特征分别提取;【特征融合】是对template、Search Region特征进行融合。而MixFormer是将template、Search Region的图片像素拼在一起,利用自注意力机制完成特征提取增强、交叉注意力机制完成特征交叉融合。以上提到的其实是考虑到空间特征,而从时序上考虑,则应用模板更新策略,以应对遮挡等挑战。
网络结构
MAM —— Mixed Attention Module
这个模块的作用既提取特征也融合特征。自注意力(self-attention)提取
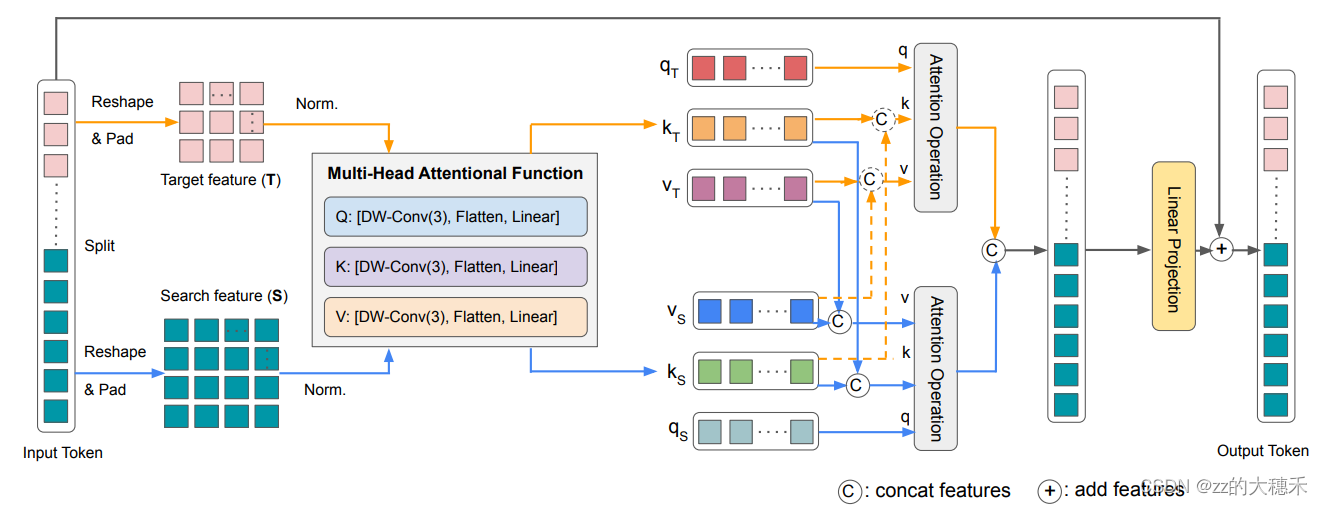
- 输入:Target Template 和 Search region的特征Token(经过卷积处理过的浅层特征)
- 第二步:对Token进行空间位置编码。 对Token进行reshape&pad成2D的特征, 正则化,然后用Depth-wise 的卷积实现位置编码,Flatten&Linear是为了将Token线性映射成Transformer的输入格式。
- 第三步:对Target Token和Search region Token应用Attention操作。 文中有个策略是,如文中蓝色线所示,将Target Token作自注意力,而Search region Token + Target Token作交叉注意力【Search region Token 作query,Search region Token + Target Token作vaule和key】。橙色线为虚线,因为文中选择不做对称的交叉注意力,即【Target Token 作query,Search region Token + Target Token作vaule和key】,因为作者认为这样会污染目标模板,加入了Search region Token的一些干扰元素。这点也可以看TransT的可视化效果。
MixFormer
MAM 模块是一个可以作为backbone堆叠的简单子结构,就像ResNet的残差结构一样。整体网络结构如下图:
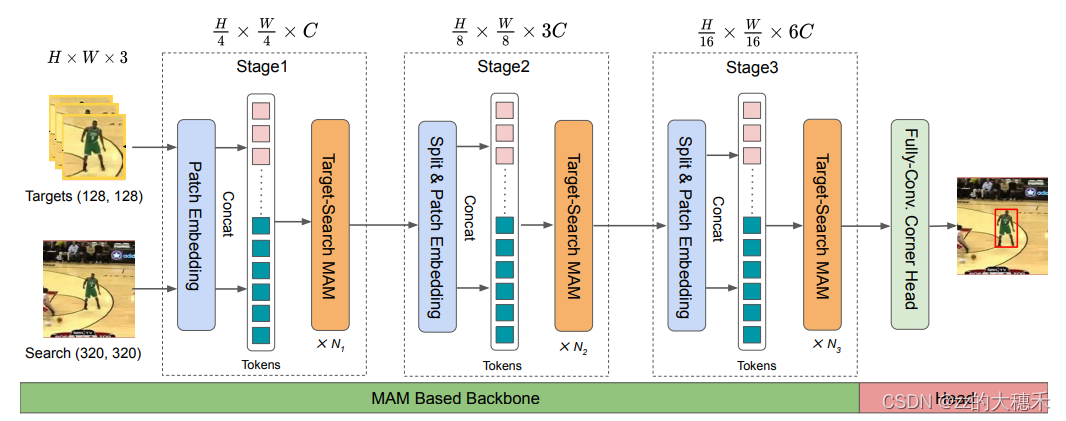
- stage的详细参数如下表格:

其中,每一层都有MAM 模块 + 线性映射层, H H H表示注意力机制中的multi-head的个数; D D D表示特征Embedding的维数; R R R是MLP中特征尺度扩展比。 - Head部分是参照STARK,设计的全卷积网络进行角点定位。 也就是通过几个Conv-BN-ReLU层对边界框的左上角和右下角的概率预测。
心疼今天查六级的强强一秒~