目录
论文链接:https://paperswithcode.com/paper/autoregressive-visual-tracking
代码链接:https://github.com/miv-xjtu/artrack
文章侧重点
- ARTrack 利用目标先前帧的预测位置,建模目标运动信息来辅助当前的目标追踪定位。原本的基于帧的追踪任务(次最优化)变成了序列追踪任务(最优化),这一点与目标追踪本身的定义一致。
- 端到端的实现,没有预测头和后置操作。
- 受到Pix2Seq的启发,利用相似的构建离散的坐标体系与Vision feature一同输入后续的Decoder。
- 与先前SwimTrack将目标运动信息作为特征输入Decoder再借助Head输出定位相比,ARTrack 旨在用先前的轨迹教会模型如何进行输出(这点与Pix2Seq一致),直接借助Decoder回归出目标的位置。
网络结构
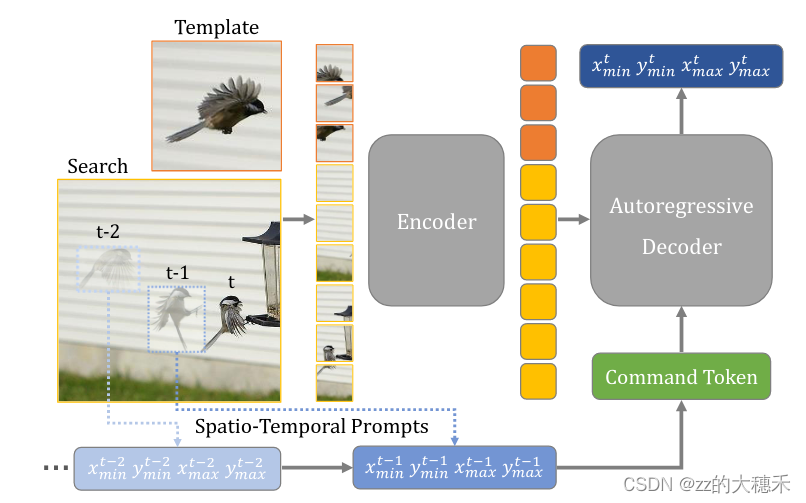 该网络一共有两个组成部分:Encoder(Vision Feature的特征提取融合)+ Decoder(Vision Feature+Motion Feature 特征融合与输出)
该网络一共有两个组成部分:Encoder(Vision Feature的特征提取融合)+ Decoder(Vision Feature+Motion Feature 特征融合与输出)
Encoder(特征提取与融合得到Vision Features)
图取自ViT
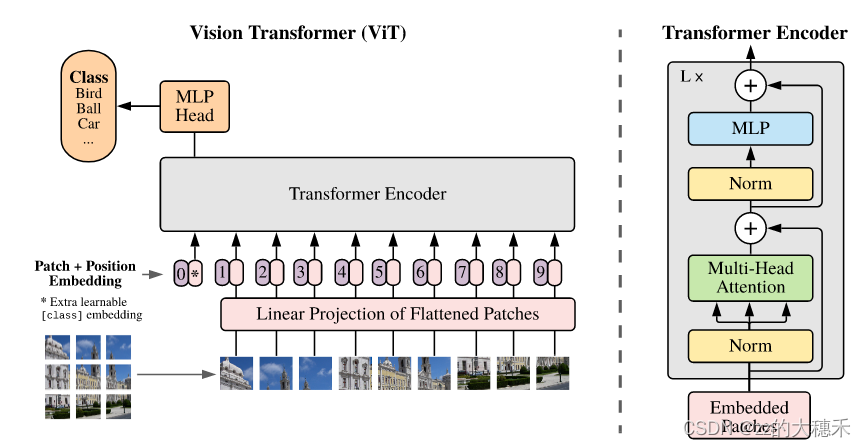
- 输入:模板图片、包含历史帧和当前帧的序列图片们
- 沿用了ViT encoder作为backbone,与OStrack一致:
- Search Regions和Template进行patch embeding生成Patches
- 针对Search Region Patches和Template Patches分别进行flatten并映射生成一个token embeddings的序列。
- 加上位置编码,再将两个tokens拼接起来,送入ViT backbone(encoder的操作和原始Transformer中完全相同)得到编码后的Vision Features。
- 输出:特征融合后的Vision Features
Decoder(Vision Feature+Motion Feature 特征融合与输出)
运动特征生成
历史轨迹的量化一共有两个步骤:坐标值离散化和坐标映射。
- 坐标值离散化
- 历史帧中的目标定位例如: [ x m i n , y m i n , x m a x , y m a x ] [xmin, ymin, xmax, ymax] [xmin,ymin,xmax,ymax] 将这4个值的范围变为[1, nbins],nbins就是图像的最大宽高, 例如输入600x600的图像, nbins为600。如果nbins大于等于图像的最大宽高,则没有量化误差。
- 将量化后的目标坐标值作为一个可学习的词典(Vocabulary)的索引,这样就可以得到坐标相关的Tokens。使得这些Tokens输入到语言模型的decoder中可以回归出坐标。
- 坐标映射
因为历史帧中的坐标有两种:在全图的坐标和在Search Region的坐标。因为Search Region是全图经过变换裁剪得到的,所以当追踪模型的输入是Search Region,那么模型中用到的历史帧中目标坐标也得是基于Search Region中的坐标。由此才需要坐标映射。
如果模型使用整张图片帧作为输入(而非Search Region),则坐标映射不需要。

特征融合与输出
- 输入:坐标Tokens Y t − N : t − 1 Y^{t-N:t-1} Yt−N:t−1、Command token、Vision Features
其中,Command token表示一个轨迹预测值(trajectory proposal),旨在与Search X t X^t Xt、Template Z t Z^t Zt的特征们Vision Features得到当前帧的目标坐标估计值 Y t Y^t Yt。 - decoder包括两类Attention
- 坐标Tokens应用Masked Self-Attention,旨在传递交互时空信息。
- Cross-Attention旨在交互Vision Features与Motion Features(坐标Tokens Y t − N : t − 1 Y^{t-N:t-1} Yt−N:t−1、Command token)

为了改进效率,将上面default decoder结构(self-attn+cross-attn)x6,改进下列altered decoder的分开的结构。
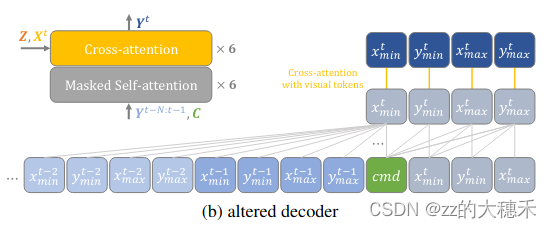
消融实验
N与Vocabulary
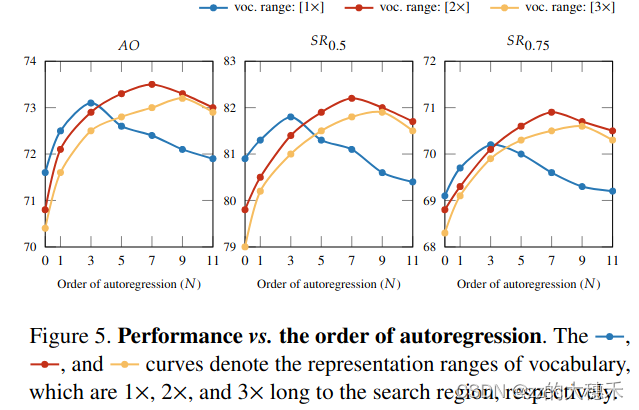
- N表示历史帧的长度,当N=1时,就基于前一帧的历史信息,当N越大,就有更多的历史信息。
- Vocabulary表示坐标范围,一般设置为Search Region大小的倍数,Vocabulary的范围越大,就可以包含更多的历史帧边界框,就有更多的运动信息。
实验结论
如上图所示,当Vocabulary=1时,N=3能达到最佳性能,而N越大性能反而下降是因为虽然历史帧多了,但是落在Vocabulary以外的是无效的。这时候可以考虑扩大Vocabulary的范围,不过虽然性能也有提升,但也为定位目标带来了困难,所以从图中可以看到,相同的N=3下,扩大Vocabulary反而带来了性能下降。
Bins

- Bins是在坐标量化中用到的参数。
- 固定Search Region的分辨率为256,Vocabulary= 2 × 256 2\times256 2×256。
实验结论
可以看到适当增加Bins的值可以改进性能,但是过大的Bins,例如1600,会使得计算后的坐标映射到Vocabulary后反而容易超界。