H2RBOX: HORIZONTAL BOX ANNOTATION IS ALL YOU NEED FOR ORIENTED OBJECT DETECTION
训练旋转目标检测器使用水平框就够了
abstract
利用水平框标注训练旋转框能够节省标注成本,并且优化大量的现有数据集。
本文使用弱监督结合自监督训练了一个旋转框检测器,并与基于水平框的实例分割模型比较了性能。
代码:https://github.com/yangxue0827/h2rbox-mmrotate
intro
介绍了几个数据集:
DIOR-R
SKU110K-R
介绍了一些HBox-supervised instance segmentation方法:
BoxInst
BoxLevelSet
由于本任务第一次提出,本文的模型将与 实例分割-外接矩形模型 性能比较。

本文的贡献:
- 第一个HBox annotation-based oriented object detector,提出self-supervised angle prediction moule
- 与H2RBox实例分割-外接矩形模型BoxInst (Tian et al., 2021)比较,mAP50(67.9% vs 53.59%),12 x faster(31.6fps vs 2.7fps),显存占用 (6.25 GB vs. 19.93 GB)
- 与经典旋转目标检测模型FCOS比较,
H2RBox is only 0.91% (74.40% vs. 75.31%) behind on DOTA-v1.0, and even surpasses it by 1.7% (34.90% vs. 33.20%) on DIOR-R ,29.1 FPS vs. 29.5 FPS on DOTA-v1.0.
related work
一些等看的论文:
SDI
MCG
BBTP
Mask R-CNN
BoxInst
CondInst
BoxLevelSet
proposed method
这一部分推荐结合论文看,毕竟方法是最重要的部分,作者在论文中阐述的已经是精简的版本了。
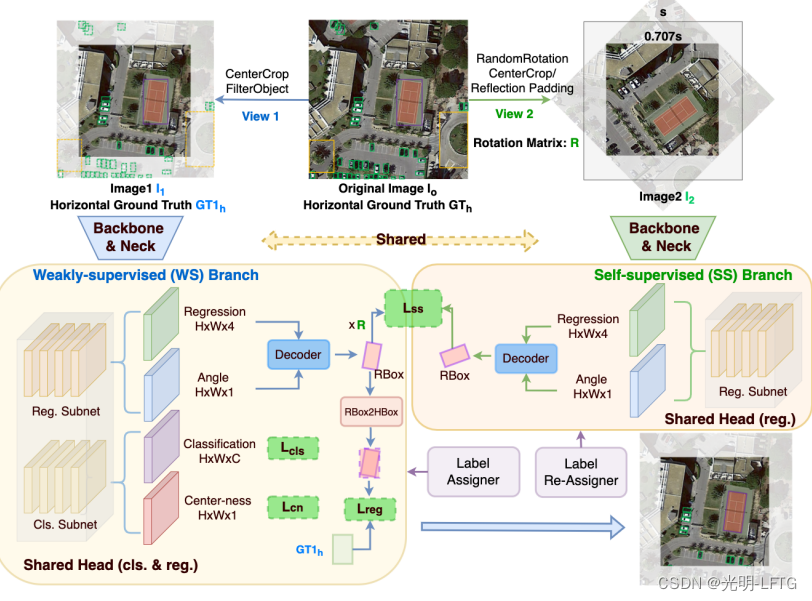
- 增强视角生成
文本最有趣的地方就是使用了自监督,保证预测旋转框的角度一致性,如示意图右边所示。注意:旋转后输入网络,要么需要裁剪,要么需要填充。
1:保留中心区域
2:填充(空白填充 与 反射填充)
(这里填充区域不参与回归损失,不必担心填充部分出现了目标)

- 弱监督分支
使用 resnet + FPN 结构,FCOS的头部网络用于regerssion
如何设置监督呢?
使用外接水平框作为监督,作者说明,这样会导致一个问题,即无法准确预测出RBox,导致如下情况出现

- 自监督分支
作为ws分支的补充,ss分支只包含回归,不包含分类,这意味着ss就是用来优化网络对于框回归的学习,即xywha
简单回忆一下旋转变换矩阵
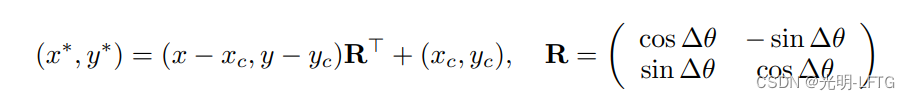
回忆FCOS学习xl xr yl yr四个参数,结合centerness完成label assignment。由于外接水平框一定满足,中心与原始旋转框中心重合,故旋转框需要学习的参数有w h theta,显然当w h都准确时,为了外接矩形与gtH相等,theat只有两种情况。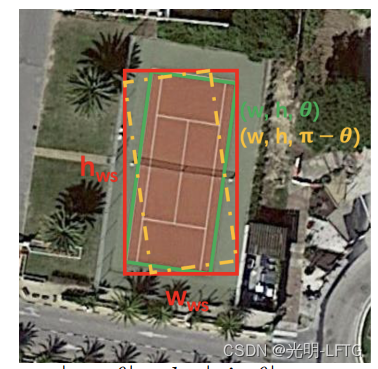
B s s s = S ( R ⋅ B w s c ) B_{ss}^s = S(R\cdot B_{ws}^c) Bsss=S(R⋅Bwsc)
这里等式左边代表ss分支预测的镜像框,右侧S代表水平翻转变换(因为中心对称,称垂直翻转也可),R代表旋转矩阵(即,由 θ \theta θ得到的旋转矩阵,角度为ss的旋转角), B w s c B_{ws}^c Bwsc为ws分支预测的框coincident rbox
(下面几句话我不能理解)
The final SS learning consists of scale-consistent and spatial-location-consistent learning:
S i m ⟨ R ⋅ B w s , B s s ⟩ Sim \langle R\cdot B_{ws},B_{ss} \rangle Sim⟨R⋅Bws,Bss⟩
Fig. 4(b) shows the visualization by using the SS loss, with accurate predictions. The appendix
shows visualizations of feasible solutions for different combinations of constraints.
(主要是我不认为这样就能确定出一个旋转框,让我们接着看吧)
- label assignment
作者:ws分支与ss分支的一致性可以通过 设置中心点损失和角度损失,来学习。
ws 分支预测的rb用于监督ss分支预测出来的rbox。并且图中每一个像素点的centerness category target GT Hbox应该保持一致。
1)一对一,每一个原图点对应到ss图点,用其rb对应的Hb作为监督
2)一对多,最接近中心点的rb用来监督ss分支rb
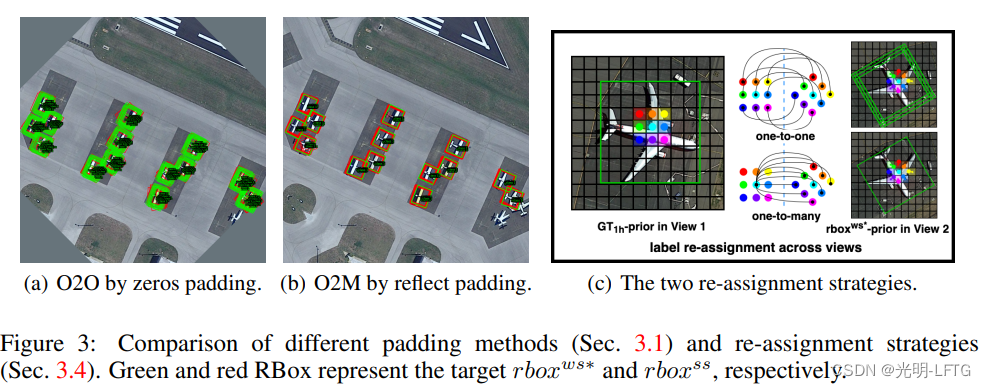
(说实话,这几句,我似懂非懂,也不知道自己理解的对不对,还是得从代码入一下)
- loss combining the ws and ss
ws分支:rotated object detector,基于FCOS,损失: L r e g L c l s L c n L_{reg} L_{cls} L_{cn} LregLclsLcn分别是focal loss cross-entropy loss IoU loss,# 为啥还有Lcn???
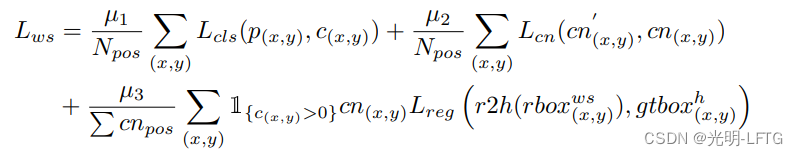
一些参数解释:(不想手打了,没啥区别)

重点的,让我们看一下ss分支损失:

额,这个Lxy中的t没有解释,然后B(-,-,+,+)我没有看懂。。
experiment
见论文
ablation studies
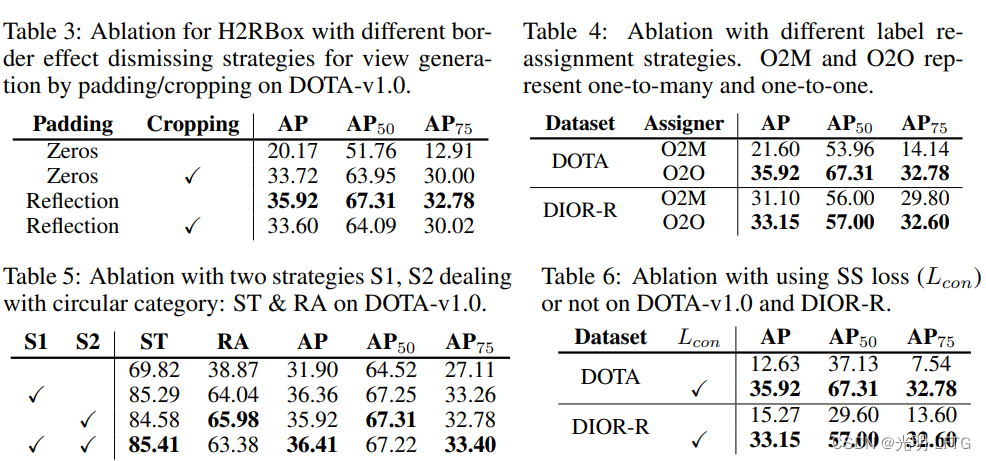
- 生成边界方法对结果的影响
- 不同assigner对结果影响
- 特殊圆形物体的训练、测试策略(st为storage tank)
- ss方法对结果的提升
代码层面解读
代码见论文中链接
看了代码整体代码非常简洁,本文主要是在loss设计新颖
接下来分三个步骤介绍代码
model.forwar_train(self,img,img_meta,gt_bboxes,gt_labels,gt_bboxes_ignore)
这一部分是网络前向传播的代码干了如下事情:
- 随机生成一个角度
- 对原始图片进行旋转,然后反射填充边界
- 旋转后图片和原始图片送入backbone+neck(共享权重)
- 然后把得到的特征图送入head.forward_train
可见与一般的model.forward_train不同的仅仅是多了一个并行分支。
losses=self.bbox_head.forward_train(x,x_aug,rot,img_metas,gt_bboxes,gt_labels,gt_bboxes_ignore)
送入了头部网络Rotated_FCOS_head
头部网络首先是对于原始的x,直接forward(x)作用上去得到,bbox_pred,angle_pred,class,centerness
然后对于x_aug,走一遍回归分支(共享权重)得到bbox_pred,angle_pred
下面就是最重要的loss计算,如何设计loss?
按照论文中,首先关于x的loss使用FCOS的自带loss即可,分类+回归+角度+centerness都有损失,然后x_aug相关的损失可以称为一致性损失。下面让我们细看