学习了朱欤老师的“从零开始学视觉Transformer”视频,收货很多,根据自己的理解对课件中的内容进行了一番整理,方便后续回顾。
视频链接: https://aistudio.baidu.com/aistudio/education/group/info/25102
transformer 基础
-
模型结构
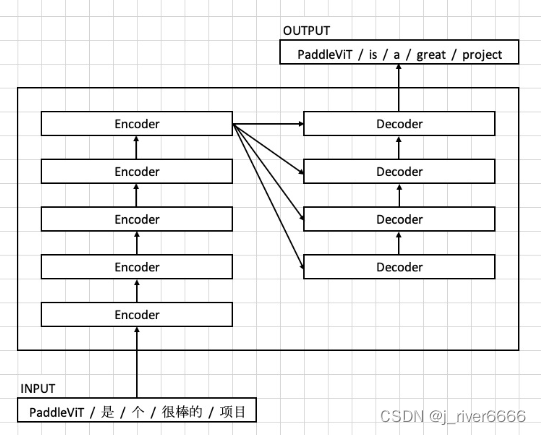

注:(1)encoder部分只有自注意力机制,q、k、v都是由输入embedding乘以相应的权重得到; (2)decoder部分,先随机初始化输出embedding, 对其做self-attention, q、k、v均由输出embedding乘以相应的权重得到,并且为了防止decode时见到未来信息,使用mask进行遮掩;随后接注意力机制,k、v由最后一层encoder的输出乘以相应的权重得到,而q由decoder部分的输出embedding乘以权重得到,也称为encoder-decoder attention。
-
模型输入
char embedding + position embedding + segment embedding
注: (1)Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务; (2)Position Embeddings和原始的Transformer不一样,不是三角函数而是学习出来的
-
attention 计算过程

(1)x * 权重矩阵 ---> q, k, v 向量
(2)q、k 点积 计算相似度,
(3)weight * v, 然后sum
注: 为什么要除以 ? 当数字序列的方差越大时,取softmax之后权值差异非常大,大数值的权值趋近1, 小数值得权值趋近0。除以, 序列的方差为1, 权值分布更加均匀,有利于学到更加有效的信息。
1 视觉transformer结构

1.1 Patch Embedding
在nlp中,单个字、词具有较高的语义密度,作为token输入可以获取丰富的特征信息;而图像中,像素的语义密度低,单个像素体现的特征信息十分有限,不适合直接作为token输入。这里,采用将图片切块的方式,将每个小块作为token输入,并进行embedding,以获取更加丰富的特征信息。

-
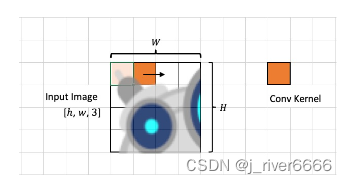
具体做法:可采用与patch相同尺寸的卷积核对原图进行卷积操作,卷积核个数即为embedding的维度。
1.2 Position Embedding
将图片切块并拼接,破坏了原图的位置信息,所以需要引入position embedding。position embedding有两种方式:(1)通过三角函数计算得到固定值(2)随机初始化,通过模型训练进行学习优化。
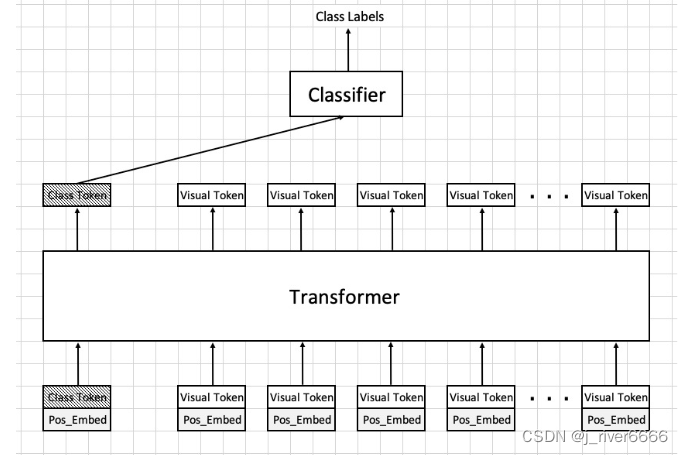
1.3 Class Token
类似nlp中的做法,引入class token, 对图像的全局信息进行表示。
1.4 整体示意图
2 视觉transformer发展历程
2.1 ViT
ViT 是transformer在cv领域进行应用的第一个模型。
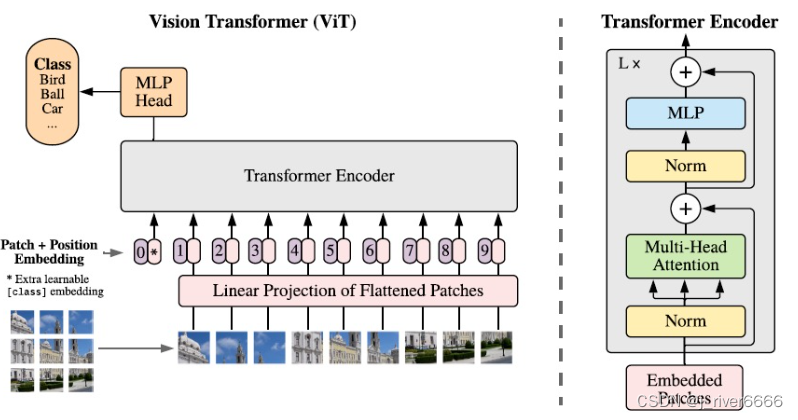
ViT的问题:
(1)训练难
a. 预训练数据集未公开
b. 大量的gpu资源和时间,8卡56天
c. 超参数设置不好难以达到好的效果
(2)只用ImageNet从头开始训练,效果一般,top1 77.91%
2.2 DeiT
DeiT解决了如何有效训练ViT的问题,与ViT相比:
(1)ViT模型的性能大幅提高;
(2)训练所需的gpu资源、数据量、时间均减少。
DeiT取得更好效果的方法:
(1)更好的超参数设置
(2)多个数据增强策略
(3)知识蒸馏
2.2.1 超参数设置
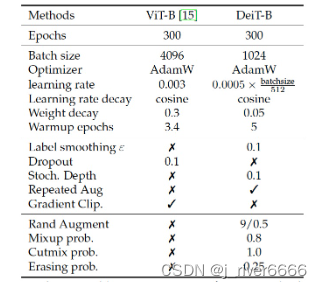
DeiT中还使用了不同的参数初始化方法: Truncated Normal init。

2.2.2 data augment
-
Random Erase
-
Mixup
-
Cutmix
-
RandomAug
-
Droppath
-
Model EMA
-
Label Smoothing
2.2.3 knowledge Distillation
蒸馏方式:
-
soft distillation
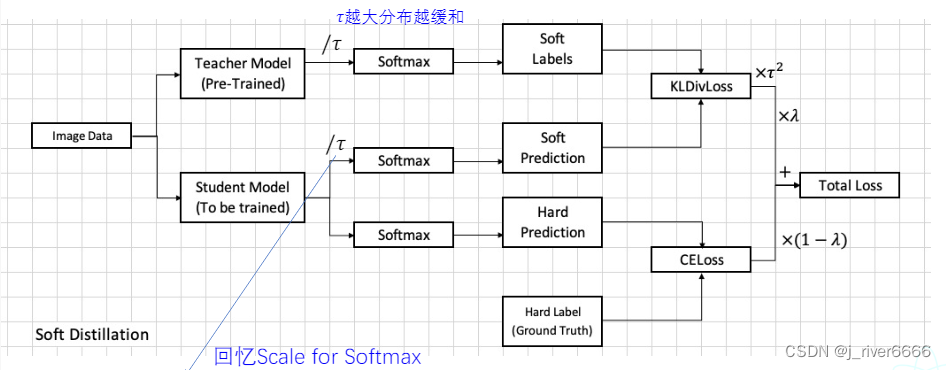
-
hard distillation
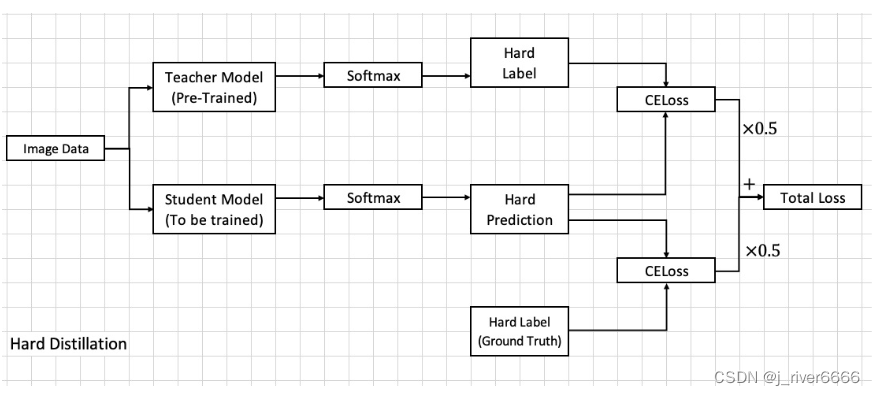
注: 此实验中,hard distillation的效果要比soft distillation好。
在蒸馏过程中,DeiT引入了Distill Token来学习teacher模型的知识。student 模型预测时,同时考虑class token和distill token。

2.3 Swin Transformer
ViT/DeiT 存在的问题: Patch 大小固定(16*16),且MSA擅长考虑全局信息,难以有效捕捉细粒度的局部特征, 对于像素级的下游任务不友好,如分割、目标检测等。
Swin的特点:
(1)从小patch(4*4)开始, 逐步进行patch merging, patch相对于原图的尺度由小到大变化,捕捉不同粒度的信息;
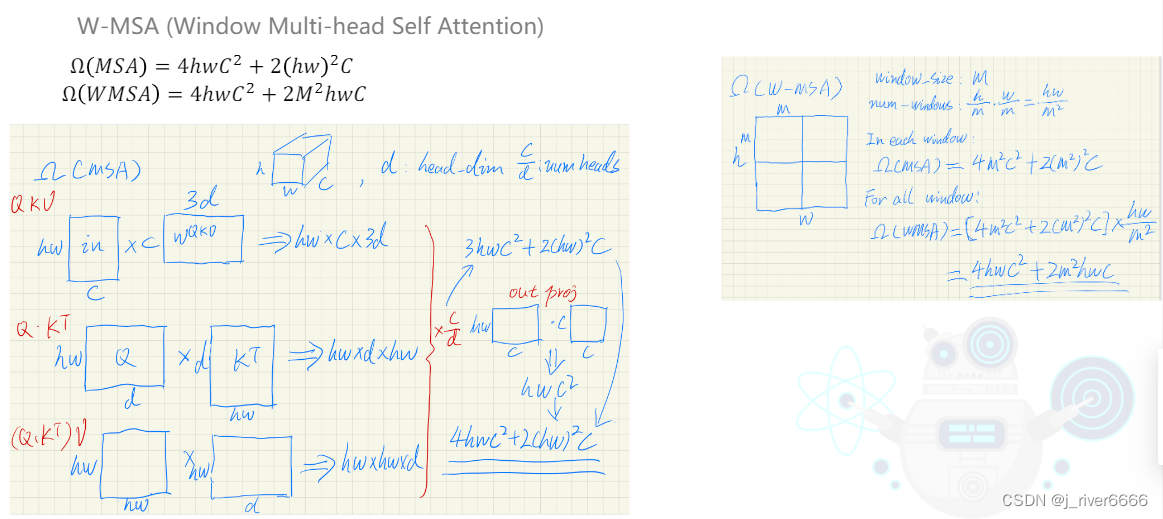
(2)引入window attention, 只计算window内的关系,计算量小,解决了小patch带来的msa计算量增大的问题,并可以捕捉细粒度的信息。
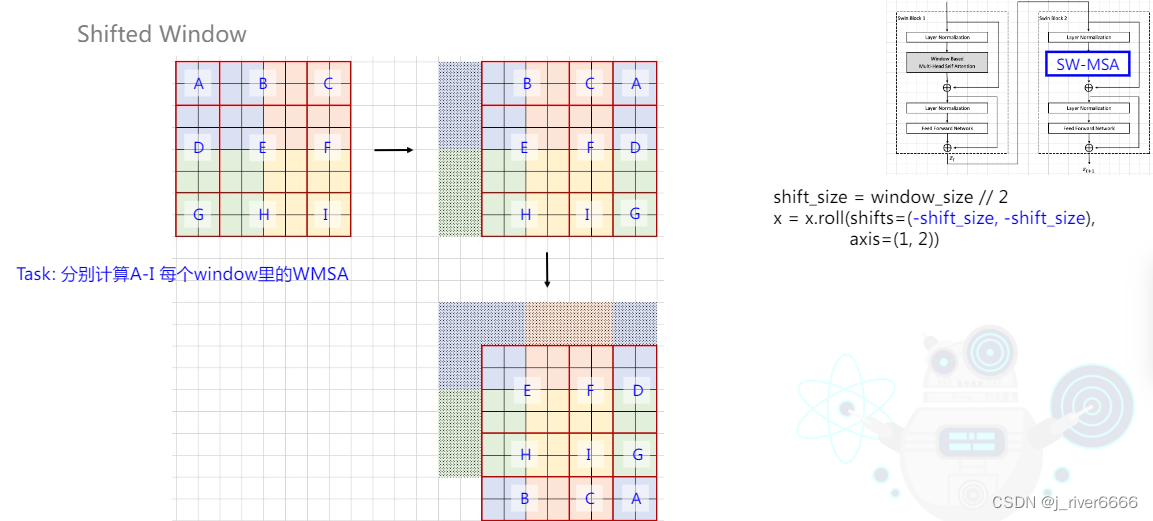
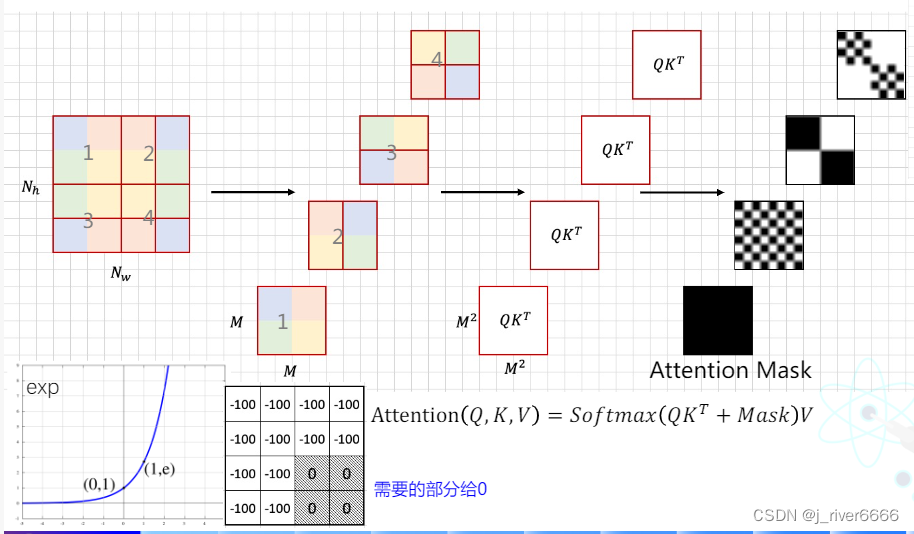
(3)引入Shifted window attention, 考虑不同window间的关系,并且计算方式更高效。
2.3.1 模型结构
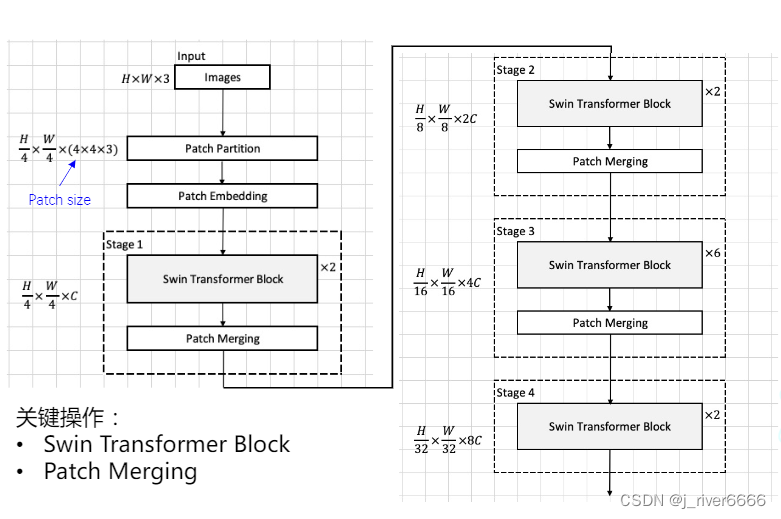
-
Swin Transformer Block
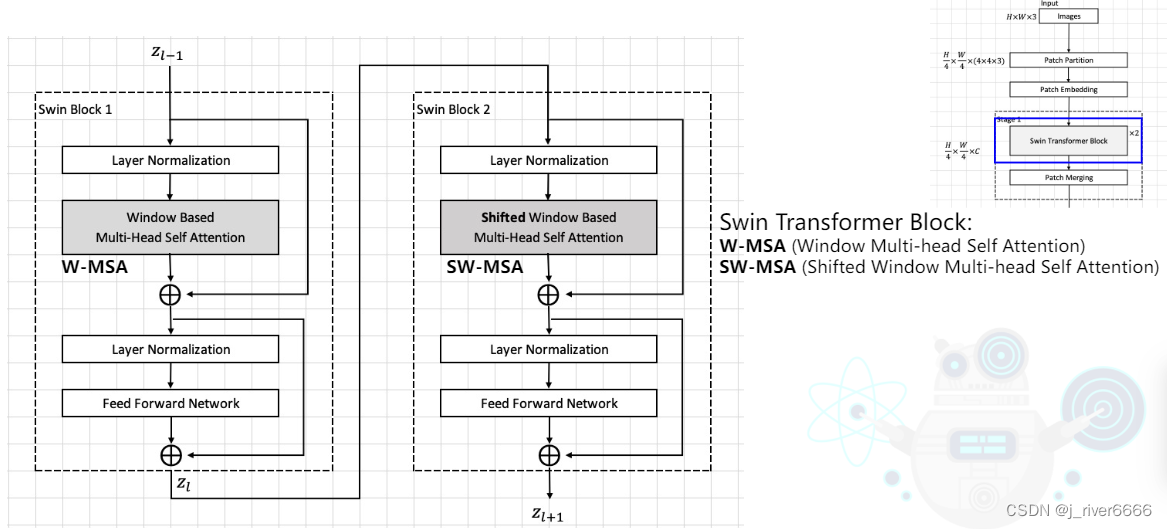
(a) W-MSA

(b) SW-MSA

-
Patch Merging

2.4 卷积和transformer的结合
conv 和 transformer计算有什么区别?
-
conv 如何计算?
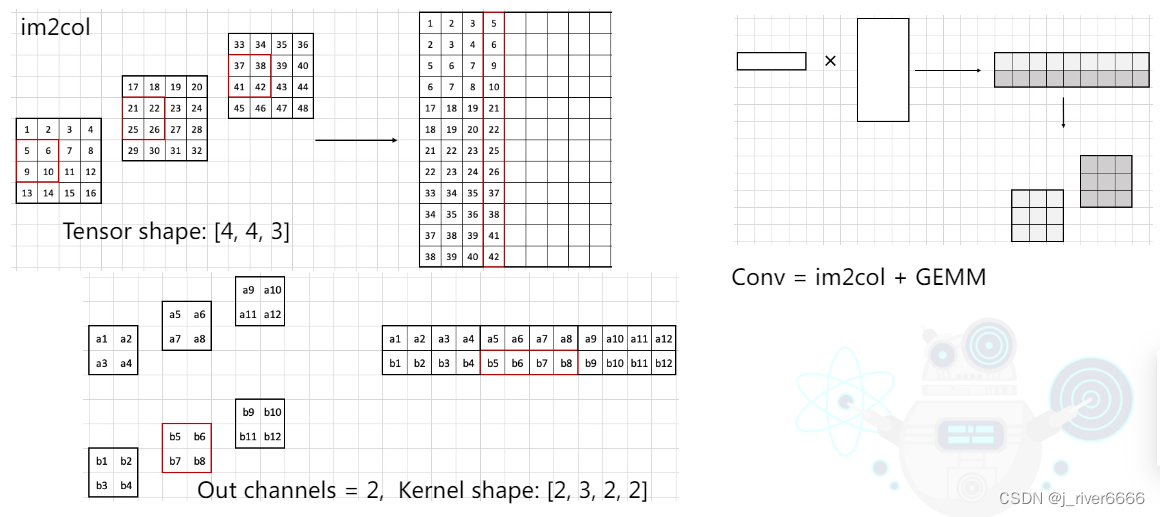
-
1 * 1 conv VS transformer

conv 与 transformer的对比:
(1)可以产生同样大小的输出特征;
(2)conv 只在 kernel size范围内计算,善于捕捉局部信息;
(3)attention 计算当前特征图内所有元素间的关系,善于捕捉全局信息。 如果将conv和transformer结合, 可以兼顾局部信息和全局信息。
2.4.1 MobileViT
MobileViT 在 mobilenet v2的基础上,引入transformer结构,实现conv与transformer的结合。
-
MobileNetV2结构

-
MobileViT结构

-
MV2 Block
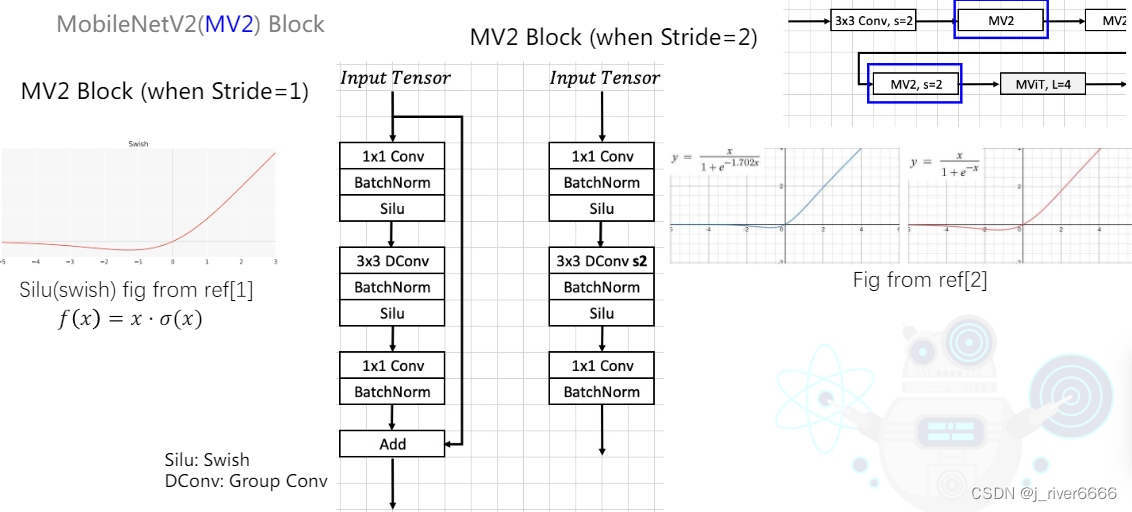
注: (1)Swish:f(x) = x*sigmoid(x) (2)GELU: f(x) = x*sigmoid(1.702x) 近似 GELU在transformer中应用广泛
-
MViT Block
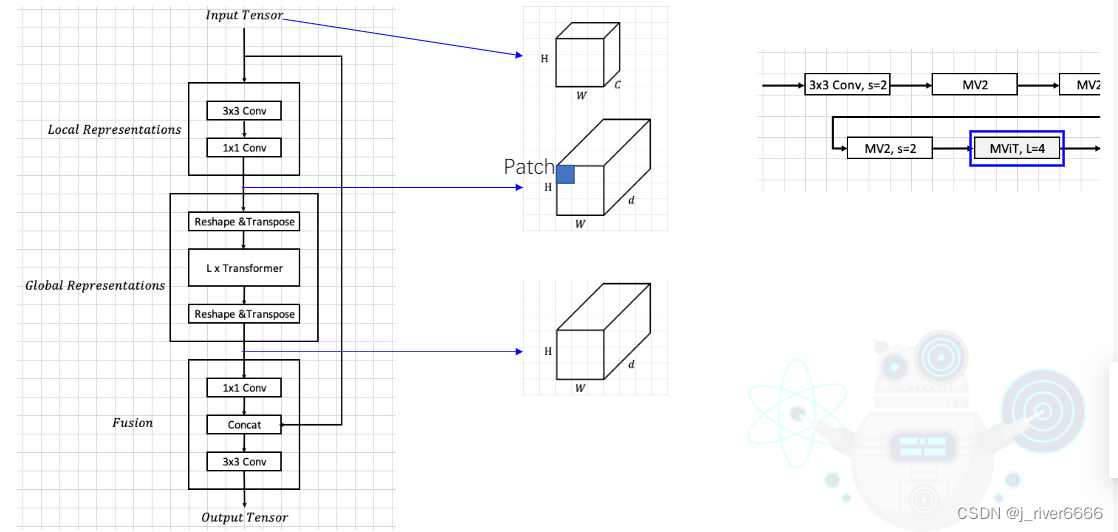

注: self-attention计算的时候,ViT中是计算整个patch embedding与其他patch embedding的关系,mobileViT是计算每个patch embedding中某个位置的元素与其他patch embedding相同位置的元素的关系,类似于空洞卷积的效果。
2.5 transformer如何兼顾局部和全局信息?
在文字识别任务中,既需要考虑字符之间的序列关系,保证语义通顺;也需要考虑字符内的局部特征,区分形近字。paddleOCR中的SVTR使用Global Mixing 和 Local Mixing 模块分别来获取字符间和字符内的特征关系。
svtr paddle版本:PaddleOCR/rec_svtrnet.py at release/2.5 · PaddlePaddle/PaddleOCR (github.com)
应用过程中,我使用pytorch对svtr进行复现,相对于crnn,效果提升明显。链接:GitHub - j-river/svtr-pytorch: pytorch version of svtr model
-
SVTR结构
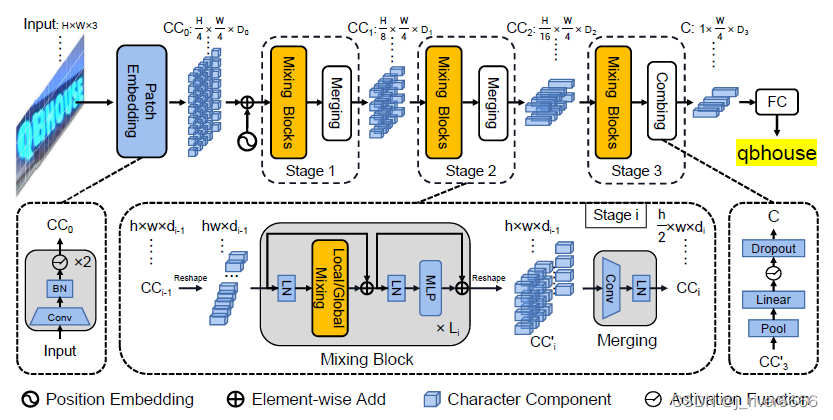
-
Mixing Block
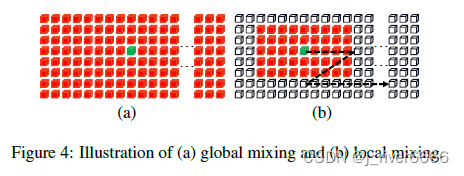
local mixing: 使用7*11滑窗, 每次只在滑窗内计算self-attention。
2.6 自监督ViT
在nlp中, bert 通过self-supervise learning的方式学习通用特征表达,作为下游任务的预训练模型。bert训练目标:(1)预测mask单词(2)预测句间关系。
cv中,如何进行自监督学习?

-
MAE
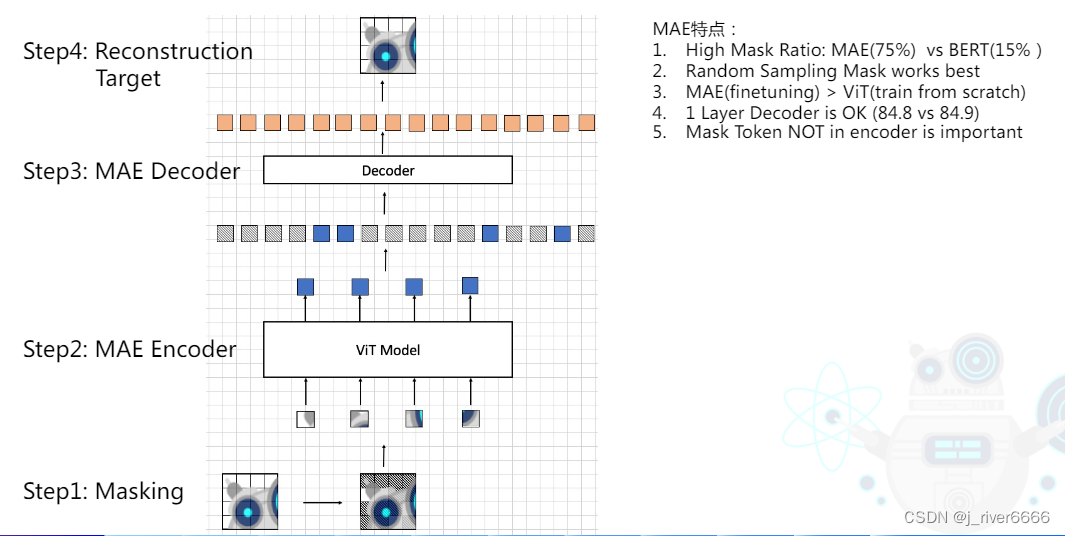
注:decoder只在预训练中使用,finetune阶段只使用encoder部分。
-
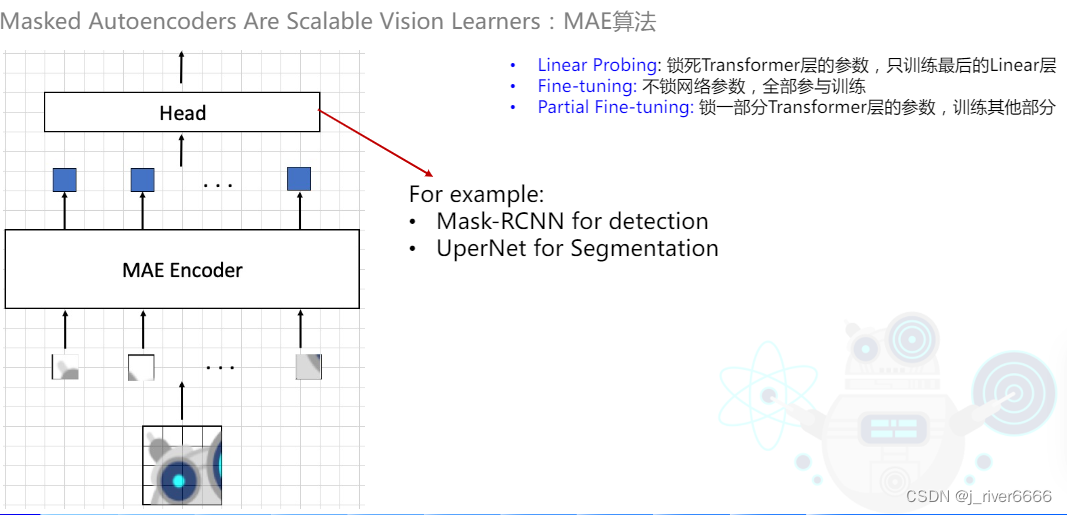
使用MAE作为backbone进行下游任务
3 transformer在cv任务中的应用
[PaddleViT] https://github.com/BR-IDL/PaddleViT
| 任务类型 | 代表模型 |
|---|---|
| 图像分类 | ViT、DeiT、Swin、CvT、ResT、ResTV2 |
| 目标检测 | DETR、PVTv2 |
| 分割 | SETR、DPT、Segmenter、SegFormer |
| 图像生成 | TransGAN、Styleformer、ViTGAN |