论文链接:https://arxiv.org/abs/2204.01697
代码链接:https://github.com/google-research/maxvit
如果进入不了github就直接在这里下载,不过没有权重文件,免费的:https://download.csdn.net/download/weixin_44911037/86823798
这是一篇谷歌发表在ECCV2022的论文,这篇论文可以说是提供了一个即插即用的模块(个人觉得),该模块将CNN与Transformer相结合。
众所周知,Transformer在图像领域取得了令人瞩目的结果,但是如果没有广泛的预训练,ViT在图像识别方面表现不佳。这是由于Transformer的模型能力强,灌输较少的归纳偏差,导致过拟合,以此在测试集上效果差,并且关于图像大小的自注意机制缺乏可扩展性(因为模型大小的问题,窗口越大计算量越大),限制了它们在最先进的视觉骨干中的广泛采用。该论文就提出了一种高效的、可扩展的多轴注意模型Max-SA,该模型由阻塞局部注意(窗口注意力)和扩展全局注意(网格注意)两个方面组成。这些设计选择允许在任意输入分辨率上进行全局-局部空间交互,只具有线性复杂度,要知道线性复杂的在很多论文中达不到,毕竟自注意力机制的复杂度是N的平方。 那么为了将该模块应用在计算机视觉任务中,还提出了一个新的架构元素,并相应地提出了一个简单的分层视觉主干,称为MaxViT,通过在多个阶段重复基本构建块。
呈现出来的效果是:在图像分类上,MaxViT在各种设置下都达到了最先进的性能:在没有额外数据的情况下,MaxViT达到了86.5%的ImageNet-1K top-1精度;使用ImageNet-21K预训练,我们的模型达到了88.7%的顶级精度,如下图所示。并且在一些下游任务中,都得到了不错的效果 。
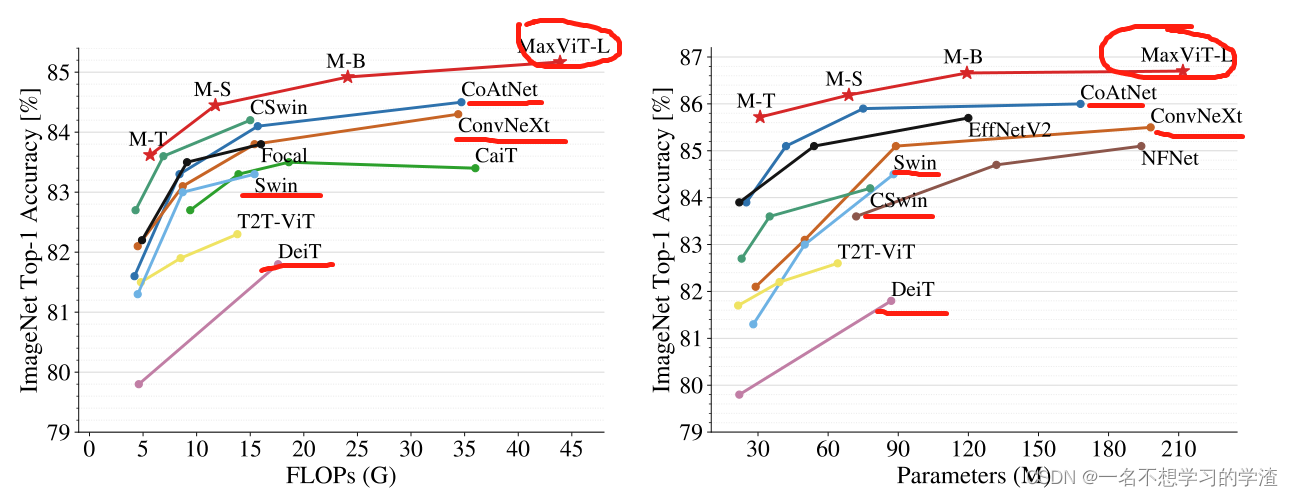
该论文所提出的贡献:
1、一个通用的强Transformer骨干,MaxViT,它可以在网络的每个阶段捕获本地和全局空间交互。
2、由闭塞的局部注意和扩张的全局注意组成的新颖独立的多轴注意模块,在线性复杂性中享受全局感知。
3、通过广泛的消融研究(即最终的成果不是一蹴而就的),我们展示了大量的设计选择,包括层数、布局、MBConv的使用等,最终汇聚成我们最终的模块化设计,MaxViT - Block。
4、我们的大量实验表明,MaxViT在各种数据制度下实现了SOTA结果,包括图像分类,目标检测,图像美学评估和图像生成。
接下来我们来看看他所涉及的MaxViT整体分类模型架构,当然在应用一下下游任务的时候,这个结构的某些超参数是需要改变的,我们可以看出,该网络结构首先通过S0(一般的卷积块)进行下采样,再通过S1,S2,S3,S4个(MaxViT - Block)模块分别不断地重复进行下采样,然后再通过池化、全连接得到最终的输出结果。其实这样的操作和ResNet非常相似。因此我们可以知道本文最终要的结构就是MaxViT - Block。下面就开始分析该MaxViT - Block模块。
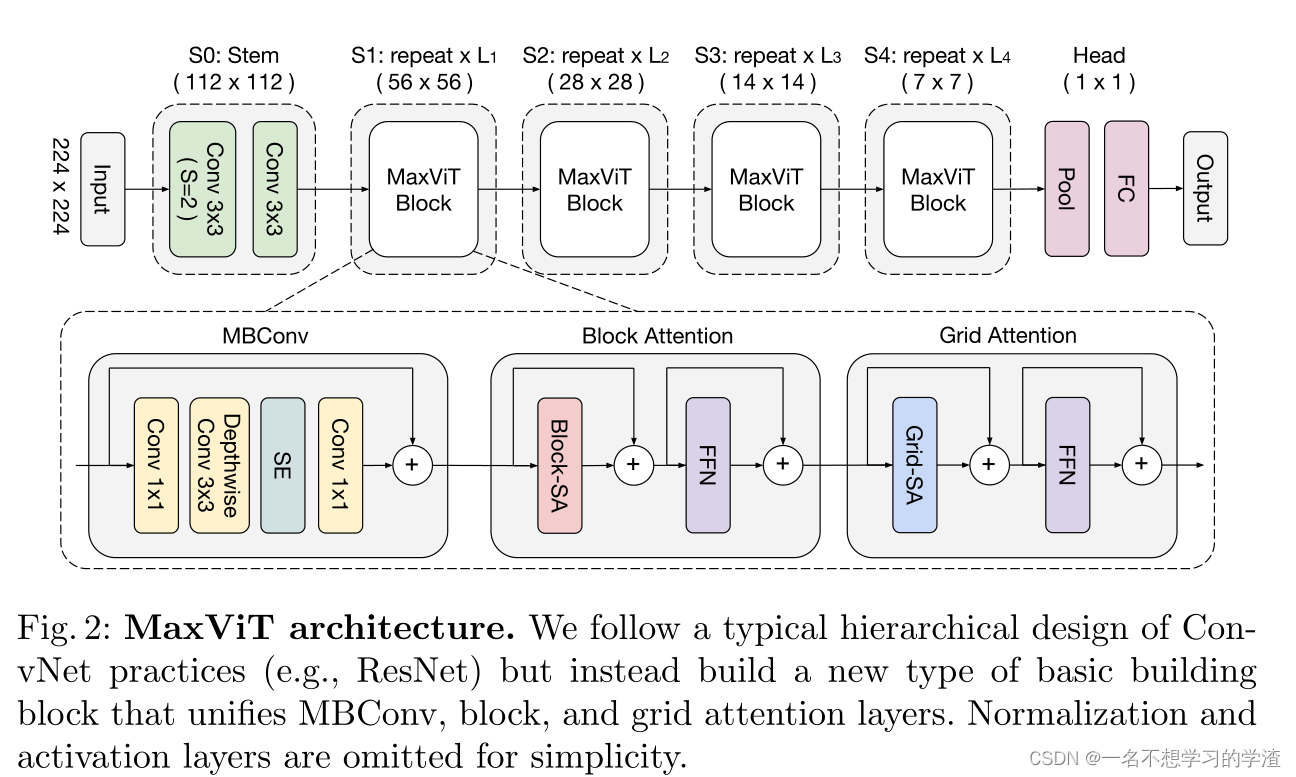
接下来,我们来看MaxViT - Block模块,该模块分为三个部分,分别是MBConv、Block Attention、Grid Attention。与局部卷积相比,全局交互作用是自我注意的主要优势之一。然而,直接沿整个空间施加注意在计算上是不可行的,因为注意算符要求二次复杂度,因为一般的自注意力机制需要和所有像素进行计算。为了解决这个问题,提出了一种多轴方法,通过简单地分解空间轴,将全尺寸注意力分解为两种稀疏形式——局部和全局。如何做的呢?
假设输入的一个特征图为CxHxW,将该特征图维度转成CxHW,然后再对空间维度进行分割成不同的块,加入每个块为P(和下图保持一致性令P=4,论文中的代码是7),那么得到CxH/4xW/4x4x4=(C,H/4xW/4,16),这就代表每个窗口的像素值为16,一共有HW/16个窗口,此时再将自注意力机制应用在划分的每个窗口中进行,这样就获得了局部自注意力机制。那么对于网格注意力机制是如何做的呢?从刚刚获得的结果知道,特征图被划分成这样(C,H/4xW/4,16),因此我们可以通过不同窗口来进行计算这样全局注意力机制,下图左边不是划分四个窗口嘛,所以我们可以对让这4个窗口进行自注意力机制进行计算,但是有一个问题就是这个窗口的数目是变化的,等于H/4,W/4,那么如果输入的特征图W和H特别大,那么得到窗口数目也就非常大,所以文中就给出另一种方法,将输入的一张特征图CxHxW,通过规定的G个窗口(论文中提供的G也为7,但是在本文中我们就根据下图来设定4,这样好理解一点)来进行计算,转成(C,GxG,H/GxW/G),这样的话,不管高和宽如何变化,我们最终特征图在空间上就只会划分规定的窗口,这样就会减少计算量了,如下右图所示,相同颜色进行自注意力机制计算。这一块不是特别好理解,比较绕,但是个人觉得这一部分内容相比较Swin-Transformer的shift window更好理解一点。如果你想要知道更具体的内容,可以看极市邀请作者涂正中所作出的论文分享。极市直播第99期|ECCV2022-涂正中:让谷歌的骨干网络MaxViT治好你的科研内耗_哔哩哔哩_bilibili

下面在看看该网络结构的相关变体:

代码是用tensorflow写的,读不懂就算了,自己再去网上找一下Pytorch开源的。
class MaxViTBlock(tf.keras.layers.Layer):
"""MaxViT block = MBConv + Block-Attention + FFN + Grid-Attention + FFN."""
def _retrieve_config(self, config):
required_keys = ['hidden_size', 'head_size', 'window_size', 'grid_size']
optional_keys = {
'num_heads': None,
'expansion_rate': 4,
'activation': 'gelu',
'pool_type': 'avg',
'pool_stride': 1,
'dropatt': None,
'dropout': None,
'rel_attn_type': '2d_multi_head',
'scale_ratio': None,
'survival_prob': None,
'ln_epsilon': 1e-5,
'ln_dtype': None,
'kernel_initializer': tf.random_normal_initializer(stddev=0.02),
'bias_initializer': tf.zeros_initializer,
}
config = create_config_from_dict(config, required_keys, optional_keys)
return config
def __init__(self, config, name='transformer'):
super().__init__(name=name)
self._config = self._retrieve_config(config)
def build(self, input_shape):
config = self._config
input_size = input_shape.as_list()[-1]
if input_size != config.hidden_size:
self._shortcut_proj = TrailDense(
config.hidden_size,
kernel_initializer=config.kernel_initializer,
bias_initializer=config.bias_initializer,
name='shortcut_proj')
else:
self._shortcut_proj = None
self._block_attn_layer_norm = tf.keras.layers.LayerNormalization(
axis=-1,
epsilon=config.ln_epsilon,
dtype=config.ln_dtype,
name='attn_layer_norm')
self._grid_attn_layer_norm = tf.keras.layers.LayerNormalization(
axis=-1,
epsilon=config.ln_epsilon,
dtype=config.ln_dtype,
name='attn_layer_norm_1')
self._block_attention = Attention(
config.hidden_size,
config.head_size,
num_heads=config.num_heads,
dropatt=config.dropatt,
rel_attn_type=config.rel_attn_type,
scale_ratio=config.scale_ratio,
kernel_initializer=config.kernel_initializer,
bias_initializer=config.bias_initializer,
name='attention')
self._grid_attention = Attention(
config.hidden_size,
config.head_size,
num_heads=config.num_heads,
dropatt=config.dropatt,
rel_attn_type=config.rel_attn_type,
scale_ratio=config.scale_ratio,
kernel_initializer=config.kernel_initializer,
bias_initializer=config.bias_initializer,
name='attention_1')
self._block_ffn_layer_norm = tf.keras.layers.LayerNormalization(
axis=-1,
epsilon=config.ln_epsilon,
dtype=config.ln_dtype,
name='ffn_layer_norm')
self._grid_ffn_layer_norm = tf.keras.layers.LayerNormalization(
axis=-1,
epsilon=config.ln_epsilon,
dtype=config.ln_dtype,
name='ffn_layer_norm_1')
self._block_ffn = FFN(
config.hidden_size,
dropout=config.dropout,
expansion_rate=config.expansion_rate,
activation=config.activation,
kernel_initializer=config.kernel_initializer,
bias_initializer=config.bias_initializer,
name='ffn')
self._grid_ffn = FFN(
config.hidden_size,
dropout=config.dropout,
expansion_rate=config.expansion_rate,
activation=config.activation,
kernel_initializer=config.kernel_initializer,
bias_initializer=config.bias_initializer,
name='ffn_1')
self._mbconv = MBConvBlock(config)
def downsample(self, inputs, name):
config = self._config
output = inputs
if config.pool_stride > 1:
output = ops.maybe_reshape_to_2d(output)
output = ops.pooling_2d(output,
config.pool_type,
config.pool_stride,
padding='same',
data_format='channels_last',
name=name)
return output
def window_partition(self, features):
"""Partition the input feature maps into non-overlapping windows.
Args:
features: [B, H, W, C] feature maps.
Returns:
Partitioned features: [B, nH, nW, wSize, wSize, c].
Raises:
ValueError: If the feature map sizes are not divisible by window sizes.
"""
config = self._config
_, h, w, c = features.shape
window_size = config.window_size
if h % window_size != 0 or w % window_size != 0:
raise ValueError(f'Feature map sizes {(h, w)} '
f'not divisible by window size ({window_size}).')
features = tf.reshape(features, (-1,
h // window_size, window_size,
w // window_size, window_size, c))
features = tf.transpose(features, (0, 1, 3, 2, 4, 5))
features = tf.reshape(features, (-1, window_size, window_size, c))
return features
def window_stitch_back(self, features, window_size, h, w):
"""Reverse window_partition."""
features = tf.reshape(features, [
-1, h // window_size, w // window_size, window_size, window_size,
features.shape[-1]
])
return tf.reshape(
tf.transpose(features, (0, 1, 3, 2, 4, 5)),
[-1, h, w, features.shape[-1]])
def grid_partition(self, features):
"""Partition the input feature maps into non-overlapping windows.
Args:
features: [B, H, W, C] feature maps.
Returns:
Partitioned features: [B, nH, nW, wSize, wSize, c].
Raises:
ValueError: If the feature map sizes are not divisible by window sizes.
"""
config = self._config
_, h, w, c = features.shape
grid_size = config.grid_size
if h % grid_size != 0 or w % grid_size != 0:
raise ValueError(f'Feature map sizes {(h, w)} '
f'not divisible by window size ({grid_size}).')
features = tf.reshape(features, (-1,
grid_size, h // grid_size,
grid_size, w // grid_size, c))
features = tf.transpose(features, (0, 2, 4, 1, 3, 5))
features = tf.reshape(features, (-1, grid_size, grid_size, c))
return features
def grid_stitch_back(self, features, grid_size, h, w):
"""Reverse window_partition."""
features = tf.reshape(features, [
-1, h // grid_size, w // grid_size, grid_size,
grid_size, features.shape[-1]
])
return tf.reshape(
tf.transpose(features, (0, 3, 1, 4, 2, 5)),
[-1, h, w, features.shape[-1]])
def block_shortcut_branch(self, shortcut):
return shortcut
def grid_shortcut_branch(self, shortcut):
return shortcut
def mbconv_shortcut_branch(self, shortcut):
shortcut = self.downsample(shortcut, 'shortcut_pool')
if self._shortcut_proj:
shortcut = self._shortcut_proj(shortcut)
def block_attn_branch(self, inputs, training, attn_mask):
config = self._config
output = self._block_attn_layer_norm(inputs)
# If put grid-attention in front, we don't need to downsample.
# Apply local block-attention
_, h, w, _ = output.shape
output = self.window_partition(output)
output = ops.maybe_reshape_to_1d(output)
output = self._block_attention(output, training, attn_mask=attn_mask)
output = self.window_stitch_back(output, config.window_size, h, w)
return output
def grid_attn_branch(self, inputs, training, attn_mask):
config = self._config
output = self._grid_attn_layer_norm(inputs)
# Apply global grid
_, h, w, _ = output.shape
output = self.grid_partition(output)
output = ops.maybe_reshape_to_1d(output)
output = self._grid_attention(output, training, attn_mask=attn_mask)
output = self.grid_stitch_back(output, config.grid_size, h, w)
return output
def block_ffn_branch(self, inputs, training):
output = self._block_ffn_layer_norm(inputs)
output = self._block_ffn(output, training)
return output
def grid_ffn_branch(self, inputs, training):
output = self._grid_ffn_layer_norm(inputs)
output = self._grid_ffn(output, training)
return output
def mbconv_branch(self, inputs, training):
output = self._mbconv(inputs, training=training)
return output
def call(self, inputs, training, attn_mask=None):
logging.debug('Block %s input shape: %s (%s)', self.name, inputs.shape,
inputs.dtype)
config = self._config
# MBConv
output = self.mbconv_branch(inputs, training)
# block self-attention
shortcut = output
output = self.block_attn_branch(output, training, attn_mask)
if config.dropout:
output = tf.keras.layers.Dropout(
config.dropout, name='after_block_attn_drop')(
output, training=training)
output = ops.residual_add(output, shortcut, config.survival_prob, training)
shortcut = output
output = self.block_ffn_branch(output, training)
if config.dropout:
output = tf.keras.layers.Dropout(
config.dropout, name='after_block_ffn_drop_1')(
output, training=training)
output = ops.residual_add(output, shortcut, config.survival_prob, training)
# grid self-attention
shortcut = output
output = self.grid_attn_branch(output, training, attn_mask)
if config.dropout:
output = tf.keras.layers.Dropout(
config.dropout, name='after_grid_attn_drop')(
output, training=training)
output = ops.residual_add(output, shortcut, config.survival_prob, training)
shortcut = output
output = self.grid_ffn_branch(output, training)
if config.dropout:
output = tf.keras.layers.Dropout(
config.dropout, name='after_grid_ffn_drop')(
output, training=training)
output = ops.residual_add(output, shortcut, config.survival_prob, training)
return output