基于transformer-XL的XLNet是目前在BERT基础上改动较大的后起之秀。在超长文本的场景下,XLNet相比其他bert系列的模型会有更好的性能(recurrent机制使其可捕获更长的上下文依赖关系)以及更快的训练与推理速度(memory单元中缓存了之前(一个或多个)段的隐状态信息,避免了重复计算),且在一般长度的文本场景中会有更完整的语义信息(PLM考虑了被mask的token间的联系)。以上分析都是基于paper中的理论。实际上,当有足够多的数据时,bert系列的各个版本在大部分场景(超长文本的场景比较少,显现不出XLNet的优势)下的效果差别不大。
为了更好的理解XLNet,首先对其采用的特征抽取器transformer-XL进行解读,然后再逐步介绍XLNet内部的各个组件。
Transformer-XL
背景
在对语言建模时,针对如何提升编码器捕获长距离依赖关系能力的问题,有几种比较有效的编码器。LSTM为了建模长距离依赖,利用门控机制和梯度裁剪,有paper验证目前可编码的最长平均距离在200左右。Transformer利用self-attention机制,允许词之间直接建立联系,能更好地捕获长距离依赖,其编码能力超过了LSTM,但局限于固定长度的上下文。
概览
Transformer编码固定长度的上下文。具体地,将一个长文本序列截断为几个固定长度的片段(segment),然后分别编码每个片段,片段间没有任何的信息交互(如BERT的预训练模型中序列长度的极限为512)。如下图所示
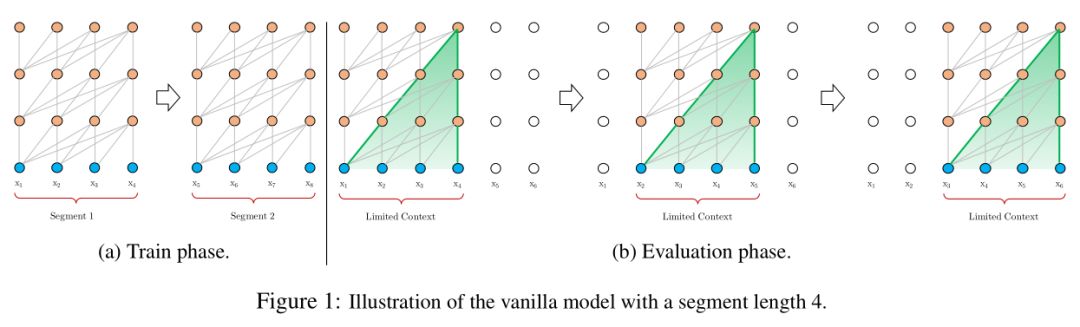
上述编码策略有如下弊端:
对超过固定长度的依赖关系无法建模编码
对长文本的分割破坏了语义边界,导致上下文碎片化(context fragmentation)
为了克服上述弊端,有效建模长距离依赖关系,就有了transformer-XL (XL = eXtra Long),其与传统(Vanilla)的Transformer相比,有如下两个特点:
片段级的递归机制(Segment-Level Recurrence with State Reuse),引入memory模块(cache之前一个或多个segment的隐状态信息),循环建模片段间的联系
使超长距离依赖关系的编码成为可能
使得片段之间产生交互,解决了上下文碎片化问题
相对位置编码(Relative Positional Encodings),代替绝对位置编码
避免了memory中缓存的片段的位置信息与当前片段中的位置信息相互混淆
具体示意图如下:
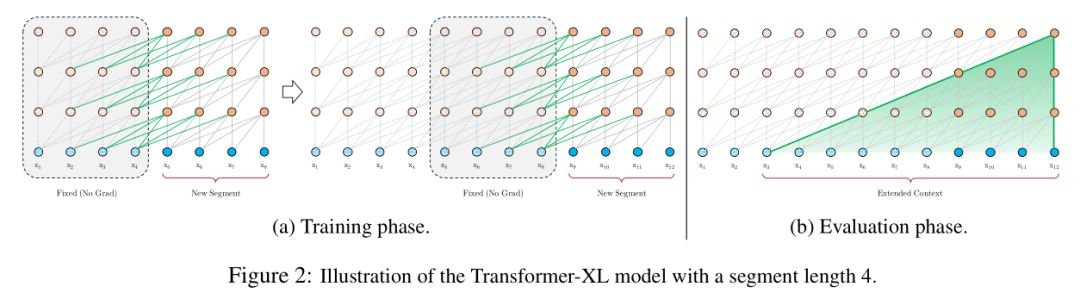
Segment-Level Recurrence with State Reuse
为了解决transformer模型使用固定上下文的限制,transformer-xl引入了循环机制。具体地,在训练阶段,当模型处理下一个新段(segment)时,前一段序列中的隐状态信息被固定并缓存,作为扩展上下文重用,如图2a所示。尽管梯度只保持在一个独立的段中,但额外的输入信息(扩展上下文)允许网络利用历史信息,从而能够对长期依赖关系进行建模并避免上下文碎片化(context fragmentation)。
记两个长为LL的连续段分别为sτ=[xτ,1,⋯,xτ,L]sτ=[xτ,1,⋯,xτ,L]和sτ+1=[xτ+1,1,⋯,xτ+1,L]sτ+1=[xτ+1,1,⋯,xτ+1,L]。
令第ττ个segment中第nn层生成的隐状态序列为hnτ∈RL×dhτn∈RL×d,其中dd表示隐层维度。则segmentsτ+1sτ+1中第nn层的隐状态序列hnτ+1hτ+1n可按如下规则生成:
~hn−1τ+1=[SG(hn−1τ)∘hn−1τ+1]h~τ+1n−1=[SG(hτn−1)∘hτ+1n−1]qnτ+1,knτ+1,vnτ+1=hn−1τ+1WTq,~hn−1τ+1WTk,~hn−1τ+1WTvqτ+1n,kτ+1n,vτ+1n=hτ+1n−1WqT,h~τ+1n−1WkT,h~τ+1n−1WvThnτ+1=Transformer−Layer(qnτ+1,knτ+1,vnτ+1)hτ+1n=Transformer−Layer(qτ+1n,kτ+1n,vτ+1n)
其中SG(⋅)SG(⋅)表示梯度不回传(stop-gradient,fixed and cached),~hn−1τ+1h~τ+1n−1表示第τ+1τ+1个segment的第n−1n−1层扩展上下文后的隐状态序列,其由第ττ个segment的第n−1n−1层隐状态与第τ+1τ+1个segment的第n−1n−1层隐状态在长度(LL)的维度进行拼接后得到。 Wq,Wk,WvWq,Wk,Wv为模型待学习的参数。
与标准的transformer相比,关键区别在于knτ+1kτ+1n与vnτ+1vτ+1n以扩展上下文的隐状态序列~hn−1τ+1h~τ+1n−1为条件,其中hn−1τhτn−1缓存了上一个segment的隐状态序列。图2a中用绿色路径表示依赖的上下文来自memory单元中缓存的隐状态信息。
通过将这种递归机制应用于语料库的两个连续片段,就会在隐状态下创建segment级的递归。因此,可利用的有效上下文可能远不止两个segment。然而,在hn−1τhτn−1与hnτ+1hτ+1n之间的循环依赖关系不同于传统的RNN-LMs中的同层递归,这里在每个segment中向上移动一层。因此最大可能的依赖长度随着层数和segment的长度线性增长,即O(N×L)O(N×L)。如图2b中的阴影区域所示,作者们在设计时限制了跨segment时不同层间的token最多可依赖的token个数为segment的长度,理论上也可以不限制。
除了获得超长的上下文并解决了碎片问题,递归方案的另一个好处是评估速度明显加快,其可重复使用先前segment的表示,不必像图1中那样从头开始计算。
最后,作者们指出递归方案不必仅局限于前面介绍的细节。从理论上讲,我们可以缓存GPU显存允许的尽可能多的先前segment,并在处理当前segment时将所有的先前的segment重用为额外的上下文。因此,我们可以缓存一个预定义的长为MM的之前的隐状态序列,其(可能)跨越多个segment,作为记忆单元mnτ∈RM×dmτn∈RM×d。作者们在实际实验时,在训练期间令MM为segment的长度,评估阶段为MM的倍数。
Relative Positional Encodings
recurrent机制使得先前的绝对位置编码方案不再适用,因为在多个segment中会出现多个同样的位置信息。 为此,作者们提出一种新的相对位置编码形式。其不仅与绝对位置一一对应,而且具有更好的泛化性。
首先,在标准的transformer中,在同一个segment下的query向量qiqi和key向量kjkj的注意力得分可分解为:
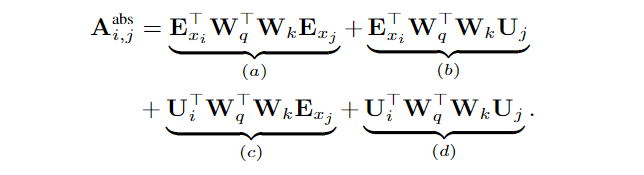
其中EE表示词向量组成的矩阵,它是内容的承载者。UU表示绝对位置向量组成的矩阵,它是绝对位置的承载者。WW主要用于attention机制QK的转换。(a)(a)表示纯基于内容间的寻址,(b)(b)和(c)(c)分别是ii位置的内容和位置信息分别与jj位置的位置和内容信息进行的寻址,(d)(d)表示纯基于位置间的寻址。
分解解读
上式可看成由下列矩阵运算而来:
(Ei+Ui)(Ej+Uj)=EiEj+EiUj+UiEj+UiUj(Ei+Ui)(Ej+Uj)=EiEj+EiUj+UiEj+UiUj
具体地可写成: qTikj=(Wq(Ei+Ui))TWk(Ej+Uj)qiTkj=(Wq(Ei+Ui))TWk(Ej+Uj) =(Ei+Ui)TWTqWk(Ej+Uj)=(Ei+Ui)TWqTWk(Ej+Uj) =ETiWTqWkEj+ETiWTqWkUj+UTiWTqWkEj+UTiWTqWkUj=EiTWqTWkEj+EiTWqTWkUj+UiTWqTWkEj+UiTWqTWkUj
基于仅依赖相对位置信息的思想,transformer-XL将上述query与key的得分改为如下形式:
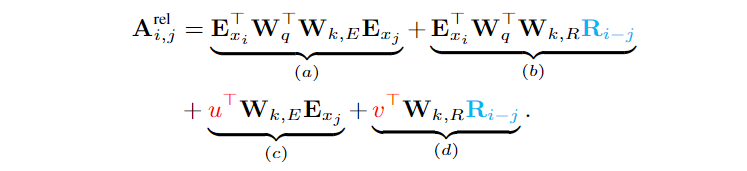
主要改进点如下:
将(b)(b)和(d)(d)项的绝对位置信息UjUj替换成相对位置信息Ri−jRi−j。这在本质上反映了一个先验:只有相对距离才是主要的关注点。其中RR是像transformer中那种不可学习的正弦编码矩阵。该种编码使得在一定长度的memory上训练的模型可以自动推广到评估期间要长好几倍的memory上
将(c)(c)和(d)(d)项的UTiWTqUiTWqT分别替换成可学习的向量u∈Rdu∈Rd和v∈Rdv∈Rd。将UTiWTqUiTWqT替换成可学习的向量,表明对于所有的query位置对应的query(位置)向量是相同的。 即无论query位置如何,对不同词的注意偏差都保持一致。
将转换key的权重矩阵WkWk分成基于内容的key的权重矩阵Wk,EWk,E和基于位置的key的权重矩阵Wk,RWk,R
改进后的四部分的含义解读如下:
(a)(a)表示基于内容的寻址,即没有考虑位置编码的原始分数
(b)(b)表示内容相关的位置偏差,即相对于当前内容的位置偏差
(c)(c)表示全局的内容偏置,从内容层面衡量键的重要性
(d)(d)表示全局的位置偏置,从相对位置层面衡量键的重要性
综合上述的递归机制和相对位置编码,就得到了最终的transformer-XL的架构。下面总结一个只有单attention head的NN层transformer-XL的完整计算过程。对于n=1,⋯,Nn=1,⋯,N有

其中h0τ:=Esτhτ0:=Esτ表示段ττ中所有词的embedding组成的序列。此外,直接按注意力得分AA中的Wnk,RRi−jWk,RnRi−j计算,其复杂度为O(L2)O(L2)。实际上i−ji−j的取值范围为0∼L0∼L,可先计算好LL个向量,然后在计算AA时直接用就好,此时可将复杂度降为O(L)O(L)。详见paper中的附录B。
实验
作者们将transformer-XL应用于词级和字符级语言建模的各种数据集(WikiText-103[词级长依赖-ppl]/enwik8[字符级-bpc]/text8[字符级-bpc]/One Billion Word[词级短依赖-ppl]/PennTreebank[小数据集的词级短依赖-ppl])。基于Transformer-XL的语言模型在以上几个数据集的基准测试中均实现了最先进的(SOTA)结果。
接着做了两种机制(Segment-Level Recurrence和Relative Positional Encodings)的消融(切除)实验,实验表明每种机制对性能提升都有帮助。
然后给出了与RNN、transformer对比后的其可建模的最大依赖长度,进一步表明transformer-XL具有建模更长依赖关系的能力。
接着展示了只在中等大小的WikiText-103语料上训练得到的语言模型,其已可以生成比较一致的文章,而不需要手动挑选,尽管存在微小错误。
最后对比了基于传统transformer的语言模型的推理速度,由于引入状态重用机制,transformer-XL在推理速度上最大获得了1874倍的加速。
结论
transformer-XL是一种强大的语言模型。其有较低的困惑度,与RNN和Transformer相比,可建模更长的依赖关系,在评估过程中实现了实质性的加速,并能够生成连贯的文章。
XLNet
与基于自回归的语言建模的预训练方法(GPT)相比,像BERT那种基于降噪自编码的语言建模的预训练方法可建模双向上下文信息。但是BERT通过使用mask破坏了输入,造成了预训练与微调间的不一致,且忽略了mask间的依赖关系。 基于自回归和自编码语言模型的优缺点,提出一种广义的自回归预训练方法XLNet。其主要由排序语言模型(PLM)、双流自注意机制、(部分预测)Partial Prediction、相对segment编码以及transformer-XL中(基于memory单元)的segment循环机制和相对位置编码构成。 整体设计很有说服力,理论性强。
AR与AE
作者们认为,当前预训练最主要的两个目标可分为两类,一类是类似GPT的AR(AutoRegression,自回归) 方式。即根据前面所有信息预测后一个token,不断重复(自回归)。形式化的描述为:
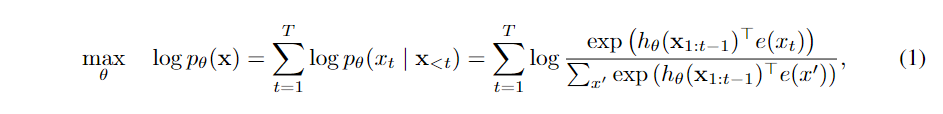
其中x=[x1,⋯,xT]x=[x1,⋯,xT]为给定长度为TT的文本序列,hθ(x1:t−1)hθ(x1:t−1)是由神经模型(如RNN或Transformer)产生的上下文表示,e(x)e(x)表示xx的embedding。
另一类是像BERT的AE(AutoEncoder,自编码器)方式,做法类似DAE(Denoising AutoEncoder,去噪自编码器),即把输入破坏掉一部分,然后还原。BERT中的具体做法是随机将一些token替换成mask(一部分是MASK,一部分是来自词表,一部分保持不变),然后预测被mask掉的token。形式化的描述为:
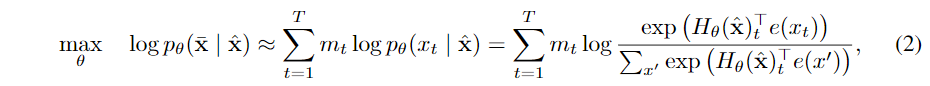
其中^xx^表示xx经过mask后的文本序列,即带噪输入。¯xx¯表示给定的文本序列xx中所有被mask的token的集合,mt=1mt=1表明token xtxt被mask,HθHθ表示将一个长为TT的文本序列xx映射成一个隐向量序列Hθ(x)=[Hθ(x)1,⋯,Hθ(x)T]Hθ(x)=[Hθ(x)1,⋯,Hθ(x)T]
从下面几个方面说明两种预训练目标的优缺点:
独立假设。BERT基于所有被mask的token间是相互独立的假设对联合条件概率p(¯x∥^x)p(x¯‖x^)进行因式分解的。式(2)(2)中的≈≈ 强调了这里有独立假设导致等号不成立。而式(1)(1)中则没有这种假设。
输入噪声。式(2)(2)引入了mask,使得预训练与下游任务不一致。而式(1)(1)中则没有这种输入噪声。(此处虽然在原始输入中没有直接引入噪声,但是在内部处理的时候会用到掩码矩阵进行token的预测)
上下文的依赖。式(1)(1)只能依赖当前位置左边的token,而(2)(2)可同时依赖左右两边的token。 这使得bert在NLU方面的性能要好于GPT
排列语言模型(Permutation Language Model)
通过上面的比较可知,AR和AE两种方式在语言建模时各有各的优缺点。作者们提出的排列语言模型,既避免了两者的缺点又兼具了两者的优点。其是一种广义的AR方式,既保留了AR模型的优点,同时允许模型捕获双向上下文。
具体地,对于长度为TT的文本序列xx,共有T!T!种不同的排列顺序,每种不同的排列顺序执行一个有效的自回归式的因子分解。如果模型参数在所有的排列顺序忠共享,那么模型可学习到双向信息。
形式化地,令ZTZT表示长度为TT的文本序列所有可能排列的集合。ztzt和z<tz<t分别表示某个排列z∈ZTz∈ZT中的第tt个元素和前t−1t−1个元素。则排列语言模型的目标函数为:
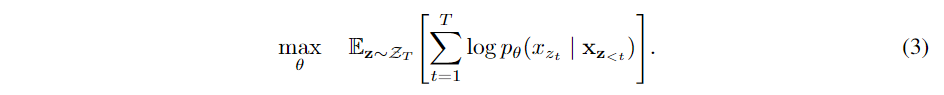
对于一个文本序列xx,每次采样一个因子分解顺序(factorization order)的排列zz并根据得到的排列后的文本序列计算似然pθ(x)pθ(x)。由于训练期间所有的排列共享一个模型参数θθ,因此xtxt可看到文本序列xx中所有可能的元素xi≠xtxi≠xt。 即PLM具有捕获双向上下文的能力。此外,由于目标函数基于AR框架,因此PLM不存在独立假设和预训练与微调不一致的弊端。
备注: PLM只对因子分解顺序进行排列,而不是对初始输入序列进行排序。具体地,保持原始输入序列的顺序不变,使用与原输入序列对应的位置编码,并依靠适当的attention mask实现因子分解顺序的排列。 这保证了预训练与微调的一致性(输入的都是具有自然顺序的文本序列)。
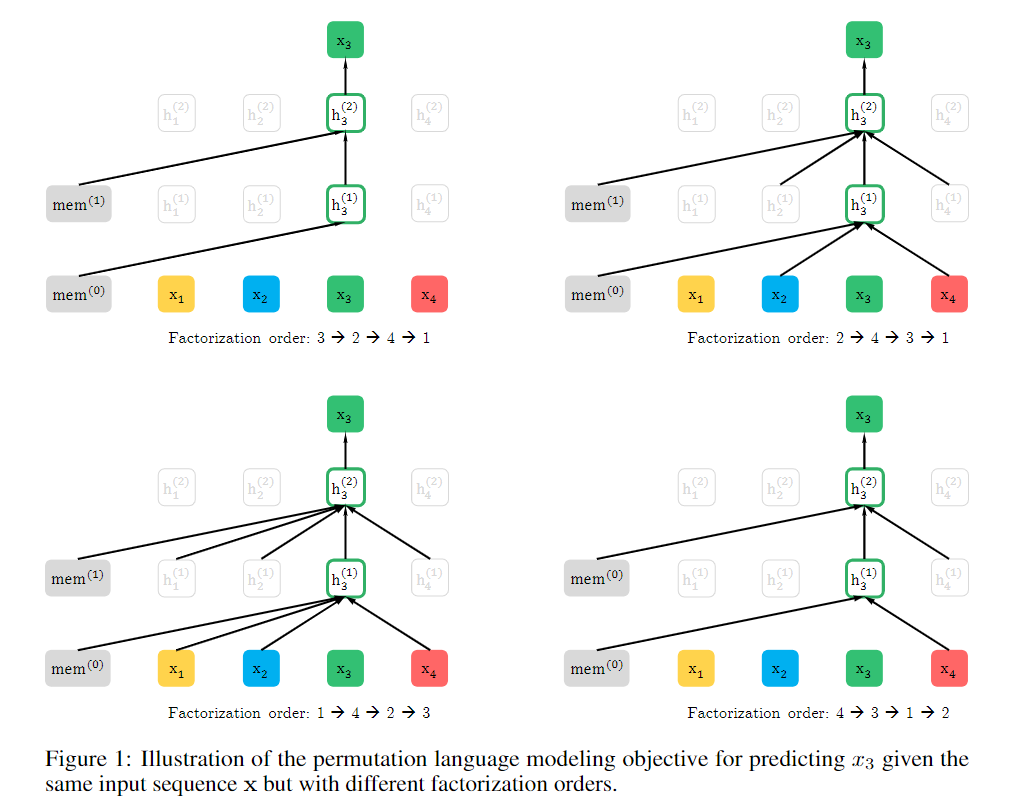
为了说明总体情况,给出如下图示。展示了在给定相同输入的文本序列xx但对应不同的因子分解顺序下,预测tokenx3x3。左边的mem表示transformer-XL中的memory单元。
Two-Stream Self-Attention for Target-Aware Representations
虽然上述提出的PLM的目标函数具有很好的特性(充分利用双向上下文信息且不(显示地)引入外部噪声),但用传统的transformer计算(3)(3)式中的pθpθ无法work。因为在未引入排列机制前,每个输入序列的顺序是确定的。而引入排列机制后,同样的序列(目标token之前的序列)后要预测的token可能不同,如果还是用(1)(1)式那种经典的AR方式计算下一个token的分布情况,会导致不同的token却有相同的分布。 为了避免上述问题,PLM在预测下一个token的分布时将目标token的位置也考虑进来。即
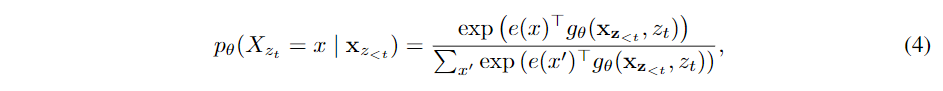
其中gθ(xz<t,zt)gθ(xz<t,zt)表示一种附加了目标位置ztzt作为输入的新型表示。
Two-Stream Self-Attention
虽然gθgθ解决了预测目标的歧义,但如何定义gθgθ仍是个不小的问题。而在传统的transformer结构中有两个相互矛盾的要求:(1)(1)在预测token xztxzt时,gθ(xz<t,zt)gθ(xz<t,zt)只能利用位置信息ztzt和上文信息xz<txz<t,不能利用内容信息xztxzt。 (2)(2)在预测其他token时,如xzjxzj,其中j>tj>t,又希望gθ(xz<t,zt)gθ(xz<t,zt)能将内容信息xztxzt也编码进来,以提供完整的上下文信息。为了解决上述矛盾,提出双流机制(用两种隐状态表示而不是像传统transformer中那样只有一种)。
content表示hθ(xz≤t)hθ(xz≤t),简写为hzthzt。与传统transformer中的隐状态相似,其可编码xztxzt的上(下)文xz<txz<t和xztxzt自身。图示说明如下:
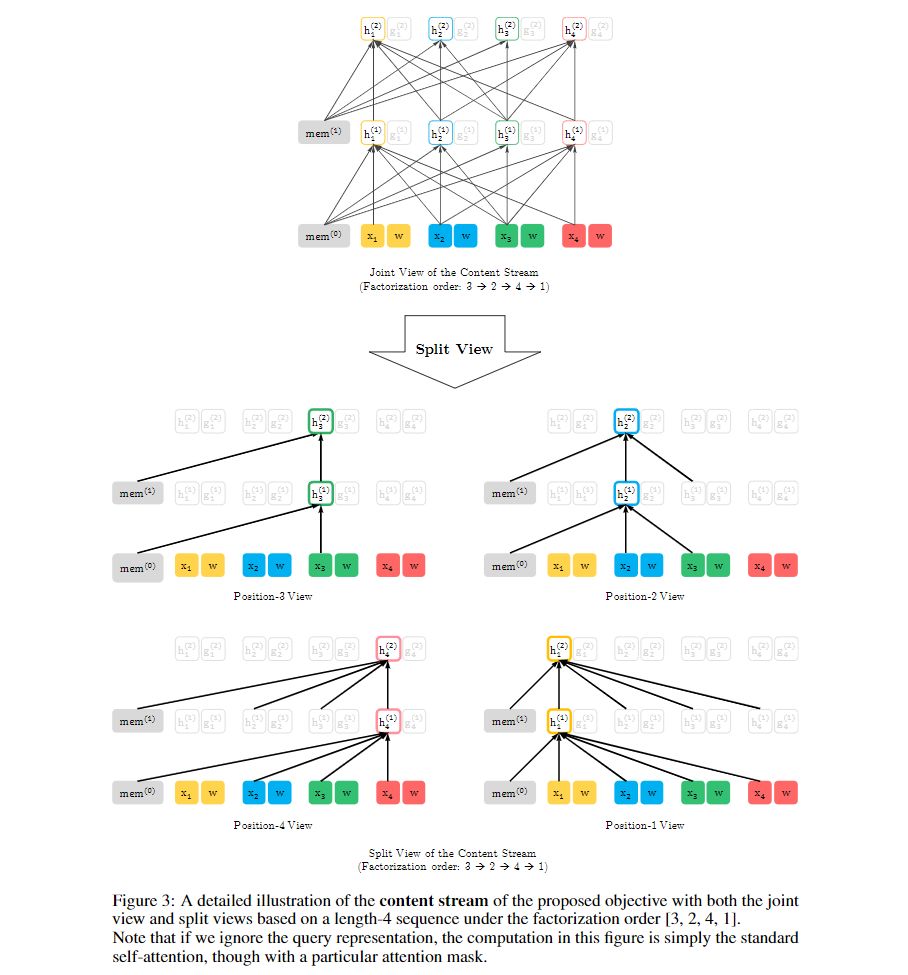
query表示gθ(xz<t,zt)gθ(xz<t,zt),简写为gztgzt。其可编码xztxzt的上(下)文xz<txz<t和xztxzt的位置信息,不能编码xztxzt的内容(content)。图示说明如下:
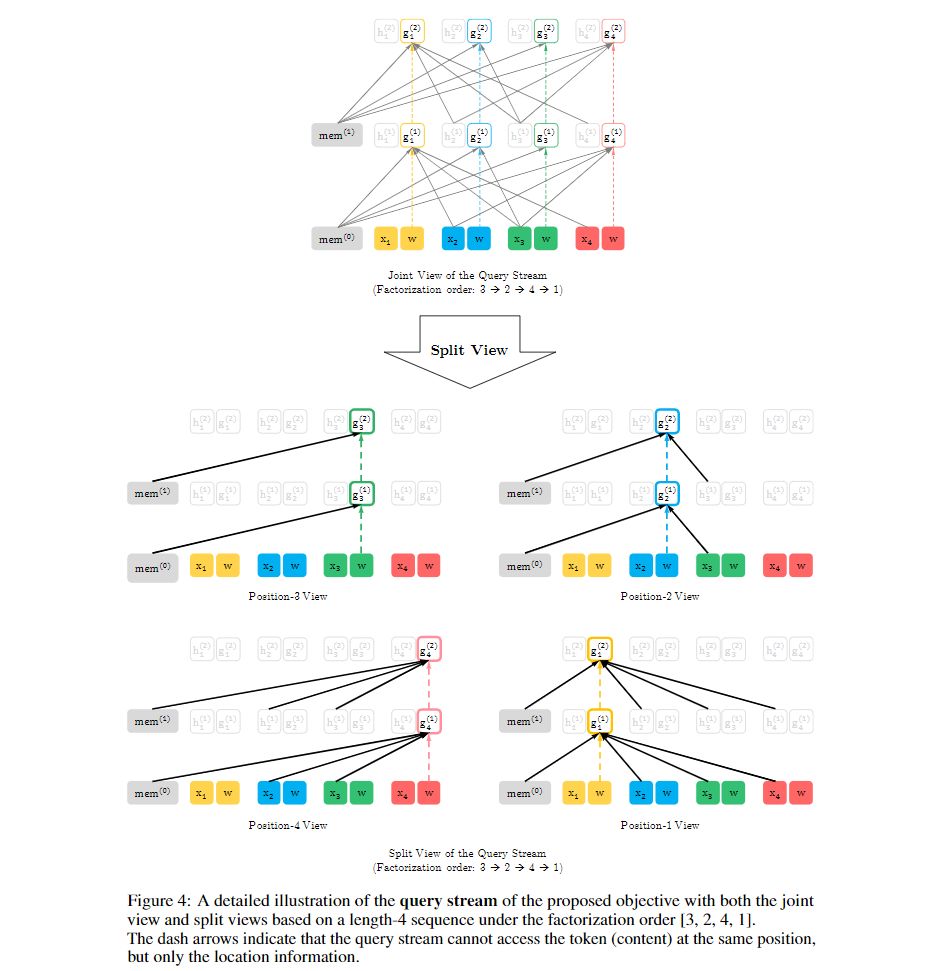
在计算上,第一层的query stream被初始化为一个可学习的向量(g(0)i=wgi(0)=w),而content stream设置为相应的词embedding(h(0)i=e(xi)hi(0)=e(xi))。对于每个自注意层m=1,⋯,Mm=1,⋯,M 通过使用一组共享的参数示意性地更新两个表示流,如下所示:
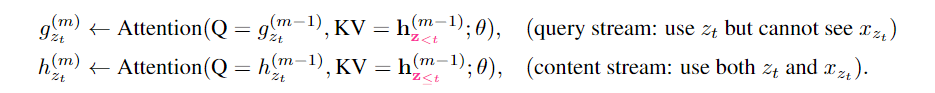
对应的图示说明如下图中的(a)(a)和(b)(b)
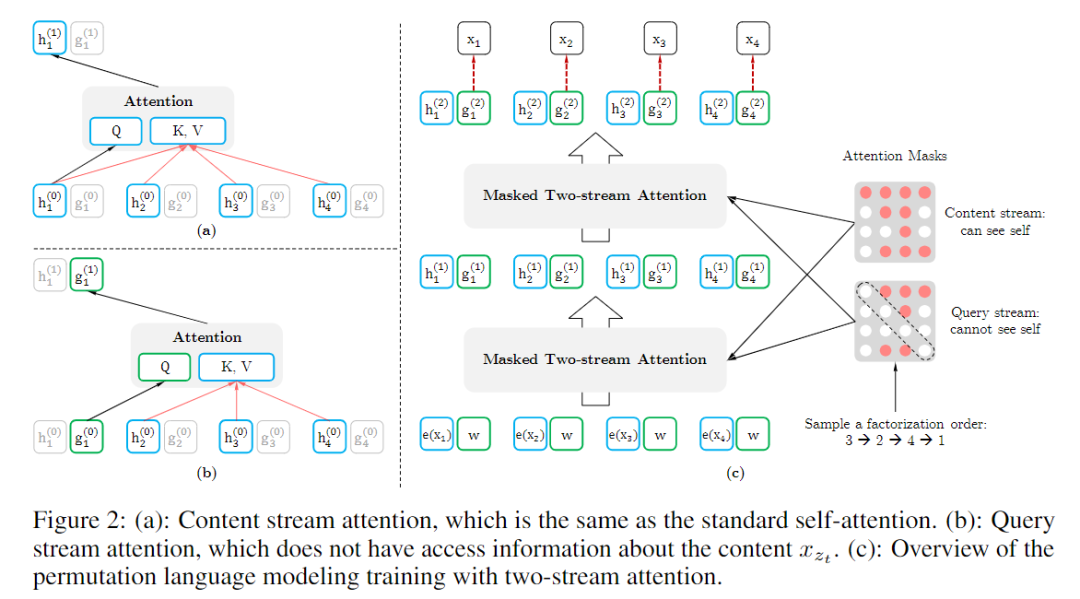
其中Q,K,VQ,K,V与传统transformer中的query,key,value相对应。content表示的更新规则与标准的self-attention完全相同,在微调阶段,可简单地删除query stream,将content stream作为transformer(-XL)的输出。最后,我们使用最后一层的query表示g(M)ztgzt(M)来计算式(4)(4)。
Partial Prediction
虽然式(3)(3)表示的PLM的目标函数有诸多好处,但是由于排列问题,该目标函数比较难优化,且在初步实验中会导致收敛缓慢。为了降低优化难度,作者们选择仅预测某个排列的序列的最后几个token。(有相对充分的context,可加快收敛,节省存储。与transformer-XL中的half-loss有相似的意思,与BERT中只预测一个序列中的部分token类似)
形式上,将某个因子分解顺序(factorization order)序列zz分成两部分,一个非目标子序列z≤cz≤c和一个目标子序列z>cz>c,cc为切分点。新的语言建模的目标函数为:
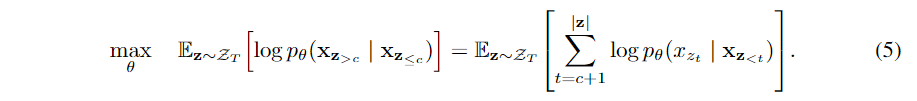
关于选择多少个token作为预测目标,作者设置了一个超参数KK,KK等于序列总token个数除以需要预测的token个数,即
K≈|z|(|z|−c)K≈|z|(|z|−c)
作者们通过实验发现最佳的KK介于6和7之间。而其导数表示预测的token个数占序列中总token个数的百分比,所以一个序列中需要预测的token的最佳百分比在14.3%到16.7%之间。而BERT中将一个序列中的部分token进行mask的百分比为15%,正好介于两者之间。
对于不需要预测的token,无需计算其query表示,从而节省了速度和内存。
Incorporating Ideas from Transformer-XL
由于上述分析的语言建模的目标函数适用于AR框架,因此作者们将最新的AR式的LM transformer-XL整合到预训练框架中。即将transformer-XL中的segment循环机制和相对位置编码集成到XLNet中。相对位置编码部分见transformer-XL中的介绍,不在赘述。segment循环部分主要利用memory中缓存的隐状态信息,从而可捕获更长的上下文依赖关系。对于content stream,其引入recurrent机制后的表示如下:
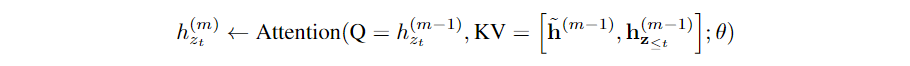
query stream的表示与上述类似。图2(c)(c)及图3、图4展示了基于双流自注意机制的PLM的概述。
Modeling Multiple Segments
许多下游任务具有多个输入段,如问答task中的问题和上下文段落。因此需要考虑如何在AR框架中预训练XLNet来建模多个segment。作者们仿照BERT,在预训练阶段随机采样两个segment(要么来自相同的上下文要么不是),并将其拼接为一个序列执行排序语言建模。在训练时,只重用属于同一个上下文的memory。 具体地,模型的输入为 [A, SEP, B, SEP, CLS],与BERT的输入相似。XLNet-Large在消融实验中发现NSP的task对性能提升不大。
Relative Segment Encodings
在结构上,不同于BERT在每个位置的token的embedding基础上增加绝对segment编码,作者们利用transformer-XL的相对编码思想来编码segment。
具体地,给定一个序列中的一对位置ii和jj,如果ii和jj在同一个segment中,那么segment编码sij=s+sij=s+,否则sij=s−sij=s−。其中s+s+与s−s−是每个attention head中可学习的模型参数。即在编码某个token的segment信息时,不考虑其来自哪个具体的segment,只考虑其与其他位置的token是否在同一个segment内。以上就是对segment进行相对编码的思想。当计算位置ii与位置jj的注意力权重时,会额外加入aij=(qi+b)Tsijaij=(qi+b)Tsij这一项。其中qiqi表示标准attention中的query向量,bb是可学习的特定头部的偏差向量。
对segment进行相对编码,一方面提升了模型的泛化能力,另一方面使得对具有两个以上的输入segment进行微调成为可能,而使用绝对编码是不可能的。
以上便是XLNet模型中的各个细节。
Discussion and Analysis
Comparison with BERT
比较式(2)(2)和式(5)(5)可知,BERT和XLNet都只预测一个序列中的部分token。对BERT来说,这是必须的,因为如果mask了所有的token,就不可能做出有意义的预测。此外,对BERT和XLNet而言,部分预测通过仅预测具有足够上下文的token来降低优化难度。然而BERT中由于独立性假设无法对mask的token间的依赖关系进行建模,XLNet就没有这种缺陷。
Comparison with Language Modeling
标准的AR式的语言模型,只能建模单向的依赖,而XLNet通过排列机制,其可建模双向依赖,从而能够编码更全面的语义信息。
Bridging the Gap Between Language Modeling and Pretraining
语言建模是一个快速发展的研究领域。然而由于缺乏双向上下文的建模能力,语言建模和预训练间还存在着一定的差距。如果语言建模不能直接改善下游任务,那么语言建模是否有意义。XLNet通过泛化语言建模的形式弥补了两者的差距。因此,XLNet进一步证明了语言建模研究的重要性。此外,利用快速发展的语言模型进行预训练也成为可能。如XLNet集成了最新的语言模型transformer-XL。
Experiments
与BERT类似,先预训练出一个模型,然后在其基础上针对各种不同的task进行微调。具体细节描述见paper。
conclusions
XLNet是一种广义的AR式的预训练方法,其利用PLM将AR和AE的优点结合起来。XLNet通过集成transformer-XL并设计双流注意机制,完美设配了AR式的目标函数。其在各项task中相比BERT都取得了一定的提升。
参考
Attention Is All You Need
The Illustrated Transformer
Sharp Nearby, Fuzzy Far Away: How NeuralLanguage Models Use Context
论文笔记 —— Transformer-XL
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
XLNet: Generalized Autoregressive Pretraining for Language Understanding
飞跃芝麻街:XLNet 详解
Transformer-XL及XLNet论文笔记
本文由作者授权AINLP原创发布于公众号平台,欢迎投稿,AI、NLP均可。原文链接,点击"阅读原文"直达:
https://carlos9310.github.io/2019/11/11/transformer-xl-and-xlnet/
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。
