环境:ubuntu16.04
请先确定已成功安装hadoop单机版
如果没有请参考:【一】hadoop单机版安装及运行wordcount
这里的伪分布式是namenode,datanode全在同一个节点上,读取HDFS上的文件。
1.修改配置文件core-site.xml
cd /app/hadoop/hadoop-2.9.0/etc/hadoop
vi core-site.xml
<configuration> </configuration>
修改为:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/app/hadoop/hadoop-2.9.0/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2.修改配置文件hdfs-site.xml
vi hdfs-site.xml
<configuration> </configuration>
修改为:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/app/hadoop/hadoop-2.9.0/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/app/hadoop/hadoop-2.9.0/tmp/dfs/data</value>
</property>
</configuration>
3.格式化namenode
cd /app/hadoop/hadoop-2.9.0
./bin/hdfs namenode -format

4.开启namenode、datanode进程
cd /app/hadoop/hadoop-2.9.0
./sbin/start-dfs.sh

也到这种输入yes就行

报错:JAVA_HOME is not set and could not be found.
说明JAVA没有安装好或者JAVA的环境变量没有配置好
如果JAVA安装好了,环境变量也配好了,还是出现这种问题,修改hadoop-env.sh文件
vi /app/hadoop/hadoop-2.9.0/etc/hadoop/hadoop-env.sh
把export JAVA_HOME=${JAVA_HOME}
改成绝对路径export JAVA_HOME=/app/java/jdk1.8.0_161
然后重新启动namenode、datanode的进程
5.输入jps查看是否成功启动
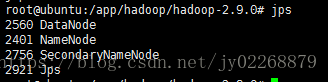
6.成功后通过网站查看节点信息
http://192.168.199.128:50070

7.在伪分布式中运行wordcount实例
之前单机模式是从本地读取的输入文件,现在伪分布式模式从HDFS上读取输入文件。
HDFS创建文件路径
cd /app/hadoop/hadoop-2.9.0
./bin/hdfs dfs -mkdir -p /user/root
HDFS创建的用户目录是ROOT,现在使用的用户也是ROOT,所以可以数据相对路径
./bin/hdfs dfs -mkdir input
将文件上传到HDFS的 /user/root/input中
./bin/hdfs dfs -put ./etc/hadoop/core-site.xml input
查看HDFS文件列表
./bin/hdfs dfs -ls input


或者可以在http://192.168.199.128:50070上看HDFS的文件列表
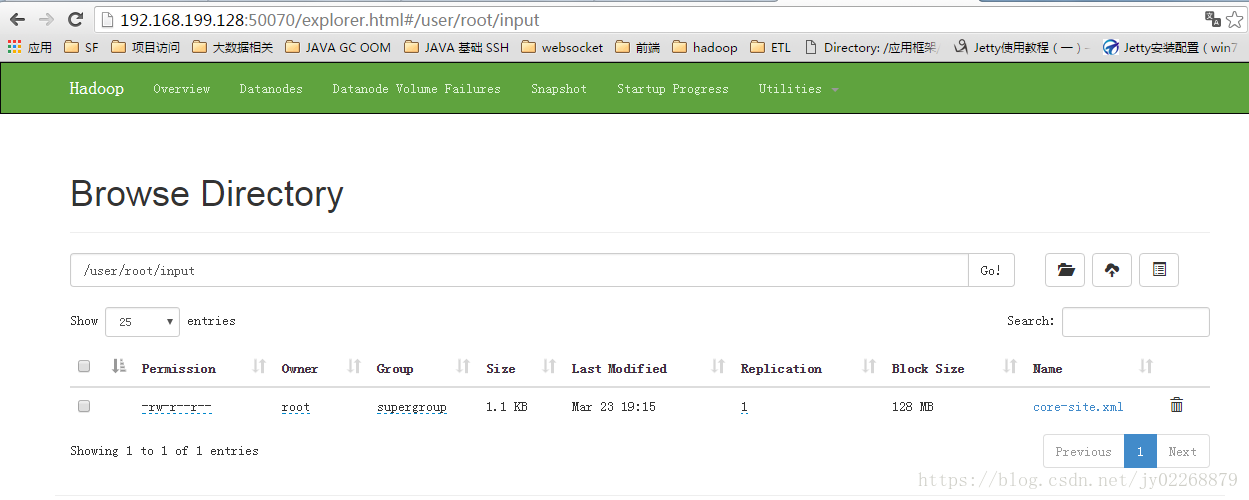
运行wordcount实例
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount input output
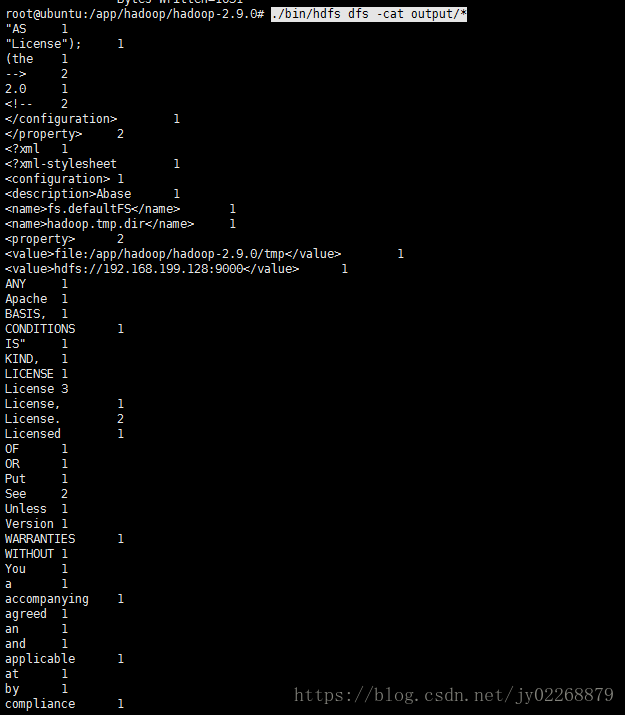
查看运行结果
./bin/hdfs dfs -cat output/*
8.关闭hadoop
cd cd /app/hadoop/hadoop-2.9.0
./sbin/stop-dfs.sh
9.启动yarn
yarn是复制资源管理和任务调度的,提供高可用,搞扩展
cd /app/hadoop/hadoop-2.9.0
修改配置文件mapred-site.xml
mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
vi ./etc/hadoop/mapred-site.xml

修改为:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改配置文件yarn-site.xml
vi ./etc/hadoop/yarn-site.xml
修改为
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
启动yarn(先启动hadoop)
./sbin/start-dfs.sh
./sbin/start-yarn.sh
./sbin/mr-jobhistory-daemon.sh start historyserver 开启历史服务器后可以在网页中查看任务运行
启动用输入jps
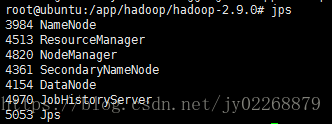
这时就有了resourceManager和nodeManager还有jobhistoryserver
在网页中查看任务情况http://192.168.199.128:8088
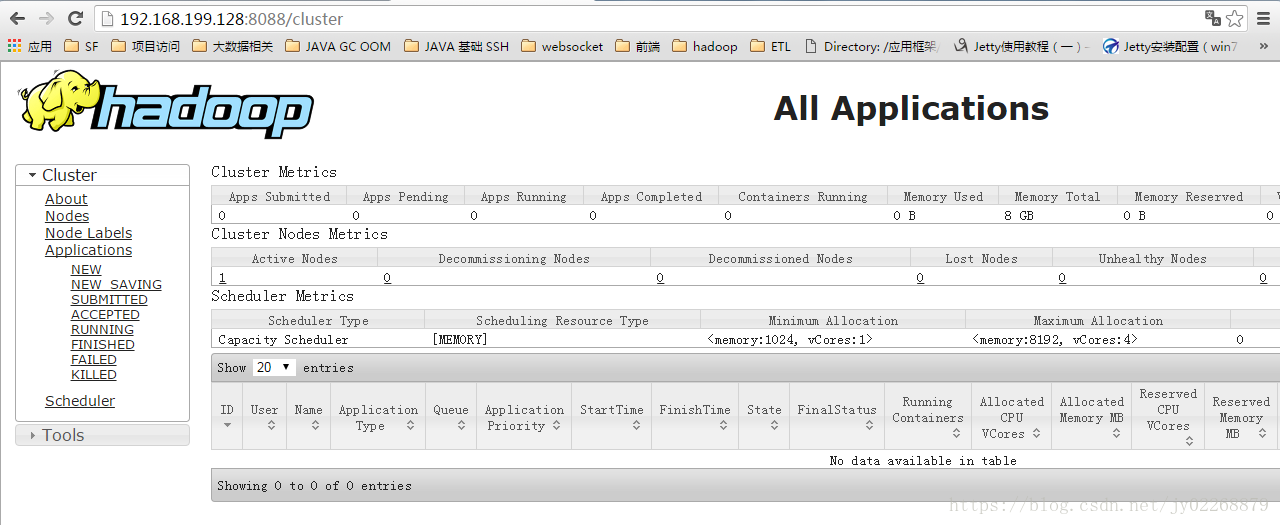
10.关闭yarn
cd /app/hadoop/hadoop-2.9.0
./sbin/stop-yarn.sh
11.配置HADOOP_HOME环境变量
vi ~/.bashrc
export PATH=$PATH:/app/hadoop/hadoop-2.9.0/sbin:/app/hadoop/hadoop-2.9.0/bin
保存后重新加载这个文件
source ~/.bashrc
现在可以直接输入stop-dfs.sh来关闭hadoop了。
也可以直接用hdfs dfs -ls input来查看文件列表了