一、安装jdk:
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
然后移动到/opt/java目录下,解压缩
tar -zxvf jdk-9.0.1_linux-x64_bin.tar.gz
配置环境变量:
1、打开profile(个人不喜欢vi编辑,所以用gedit了,虽然很low)
root@ubuntu:/usr/java# gedit /etc/profile2、复制下面的代码放到文件最后边,保存,注意jdk的文件名(看你自己安装jdk的是哪个版本)
export JAVA_HOME=/opt/java/jdk1.8.0_171
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH3、配置立即生效
source /etc/profile4、检查:java -version
二、安装ssh:
由于Hadoop用ssh通信,先安装ssh
~$ sudo apt-get install openssh-serverssh安装完成以后,先启动服务:
~$ sudo /etc/init.d/ssh start 启动后,可以通过如下命令查看服务是否正确启动:
~$ ps -e | grep ssh
作为一个安全通信协议,使用时需要密码,因此我们要设置成免密码登录,生成私钥和公钥:
hadoop@scgm-ProBook:~$ ssh-keygen -t rsa -P ""
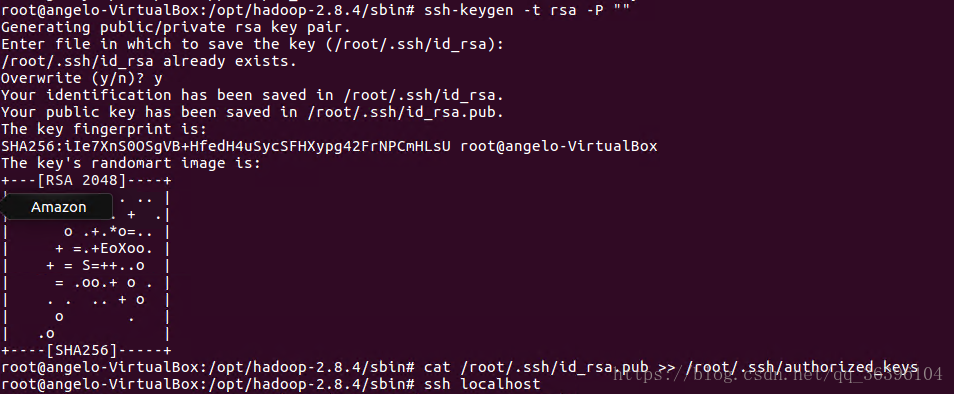
因为我已有私钥,所以会提示是否覆盖当前私钥。第一次操作时会提示输入密码,按Enter直接过,这时会在~/home/{username}/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥,现在我们将公钥追加到authorized_keys中(authorized_keys用于保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容):
这里还是依据自己定义的存放秘钥的位置来弄,我是直接回车使用的默认值:/root/.ssh/id_rsa
~$ cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys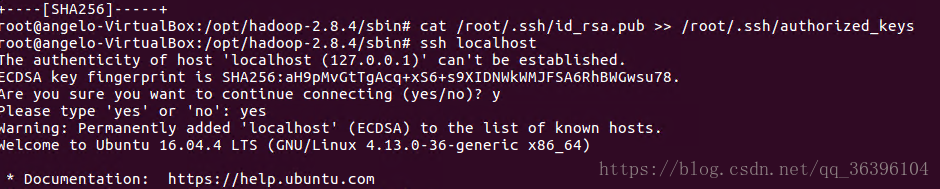
现在可以登入ssh确认以后登录时不用输入密码:
~$ ssh localhost登出:
~$ exit第二次登录:
~$ ssh localhost登出:
~$ exit这样以后登录就不用输入密码了。
三、安装hadoop
下载地址:
http://hadoop.apache.org/releases.html
安装包移动到/opt/hadoop下,解压: tar -zxvf hadoop-x-x-x
配置环境变量:
gedit /etc/profileexport JAVA_HOME=/opt/java/jdk1.8.0_171
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.4
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/sbin:$PATHsbin:$PATHsource /etc/profile注意这里是/sbin不是/bin,在hadoop2.0里面的启动文件放在sbin里,不然第一次就无法启动hadoop,不过之后在配置分布式的时候又遇到了一些问题,由于是新手就不太懂,不过当我把$HADOOP_HOME/bin也加进去的时候,就没有再在这个上面出错了
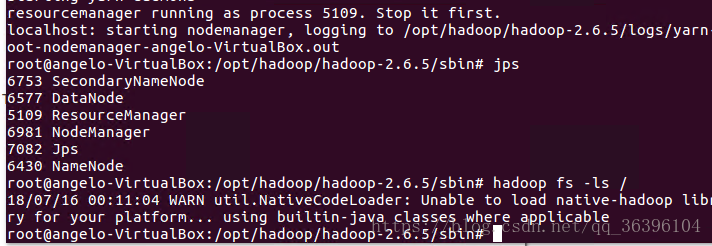
测试:hadoop jps
四、伪分布式配置:
1、修改地址解析文件:
gedit /etc/hosts添加0.0.0.0 hadoop
127.0.0.1 localhost
127.0.1.1 angelo-VirtualBox
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
0.0.0.0 hadoop2、修改/hadoop-x-x-x/etc/hadoop目录下的core-site.xml
添加:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
</configuration>3、修改hdfs-site.xml:
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>4、修改mapred-site.xml(若为.tempxxx则需要更名为.xml)
<configuration>
<property>
<name>mapre.job.tracker</name>
<value>hadoop:9001</value>
</property>
</configuration>
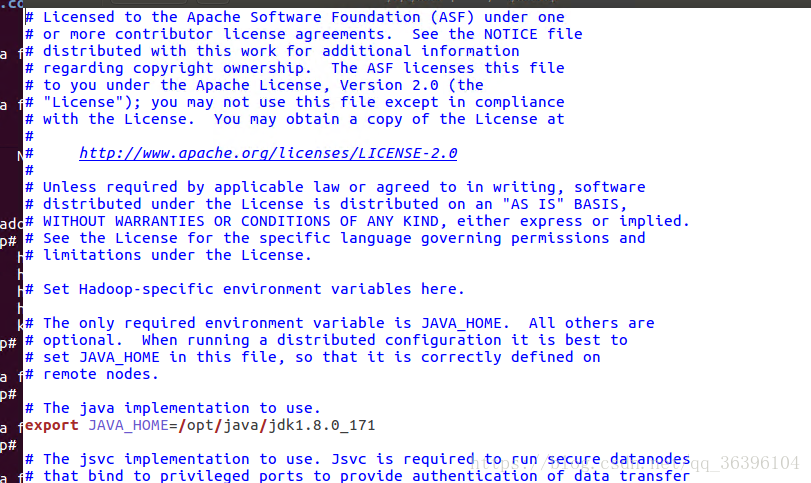
5、修改hadoop-env.sh:
添加JAVA_HOME:
6、格式化namenode:
hdfs namenode -format7、检查: