1. java -> jdk-7u67-linux-x64.tar.gz
2. hadoop -> hadoop-2.5.0.tar.gz
3. IP/host -> 192.168.47.100/bigdata.001.com
4. CentOS -> 6.7
3
1
1. java -> jdk-7u67-linux-x64.tar.gz
2
2. hadoop -> hadoop-2.5.0.tar.gz
3
3. IP/host -> 192.168.47.100/bigdata.001.com
4
4. CentOS -> 6.7
- 设置IP。
虚拟机 -> 编辑 -> 虚拟网络编辑器。
- 虚拟机必须NAT模式。在虚拟机设置界面去设置。
- 本虚拟机的IP的网段,本虚拟机可以设置本IP网段的任意地址。 192.168.47.XXX(000, 2这两个地址不可以)

3.
/etc/sysconfig/network-scripts/ifcfg-XXX 在该文件中设置IP地址

- hostname的配置
1. 在/etc/hosts 添加本机的IP与对应的域名

2. 配置HOSTNAME
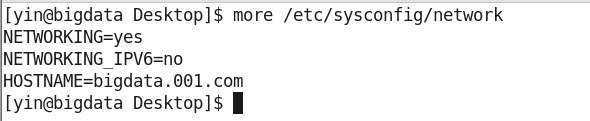
3. 重启,并将 192.168.47.105 bigdata.001.com

4. 可以使用 ping 命令来 ping 通虚拟机与实体机。
- 环境配置
禁用selinux
vi /etc/sysconfig/selinux
SELINUX=disabled
关闭防火墙
看状态service iptables status
设置关闭service iptables stop
自启关闭chkconfig iptables off
8
1
禁用selinux
2
vi /etc/sysconfig/selinux
3
SELINUX=disabled
4
5
关闭防火墙
6
看状态service iptables status
7
设置关闭service iptables stop
8
自启关闭chkconfig iptables off
- 安装Oracle的JDK
查看自带的JDK
rpm -qa | grep java
卸载自带的JDK
rpm -e --nodeps 卸载内容(卸载多文件使用空格)
解压JDK
tar -zxf jdk-7u67-linux-x64.tar.gz -C /opt/moduels/
配置java环境
vi /etc/profile
##JAVA_HOME
export JAVA_HOME=/opt/moduels/jdk1.7.0_67
export PATH=$JAVA_HOME/bin:$PATH
source /etc/profile
java -version
18
1
查看自带的JDK
2
rpm -qa | grep java
3
卸载自带的JDK
4
rpm -e --nodeps 卸载内容(卸载多文件使用空格)
5
6
解压JDK
7
tar -zxf jdk-7u67-linux-x64.tar.gz -C /opt/moduels/
8
9
配置java环境
10
vi /etc/profile
11
12
##JAVA_HOME
13
export JAVA_HOME=/opt/moduels/jdk1.7.0_67
14
export PATH=$JAVA_HOME/bin:$PATH
15
16
source /etc/profile
17
18
java -version
- Hadoop配置 --- HDFS
解压Hadoop
tar -zxf hadoop-2.5.0.tar.gz -C /opt/moduels/
可清理文档: hadoop-2.5.0/share/doc目录
确保环境正确;
路径:/opt/moduels/hadoop-2.5.0
命令:bin/hadoop
Hadoop指定的java安装路径
etc/hadoop/hadoop-env.sh
//虽然官方文档没有写,但是同目录下mapred-env.sh和yarn-env.sh也做相同修改
export JAVA_HOME=/opt/moduels/jdk1.7.0_67
Hadoop三种运行模式
本地单机模式:使用本地文件系统
伪分布式模式:HDFS文件系统
完全分布式模式:HDFS文件系统(真实集群)
修改 etc/hadoop/core-site.xml
//默认文件系统访问入口,1.x系列端口号为9000
//hadoop.tmp.dir为hadoop系统生成文件的临时目录
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata.001.com:8020</value><!--可以用IP来代替主机名-->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/moduels/hadoop-2.5.0/data/tmp</value>
</property>
</configuration>
修改 hdfs-site.xml
//修改副本数量
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
修改slaves, 配置本机的主机名
//从节点机器位置主机名
bigdata.001.com
格式化namenode
命令:bin/hdfs namenode -format
查看结果:data/tmp文件夹生成文件
//只能格式化一次,如果有需求,将tmp文件夹下内容删除再格式化
//多次格式化会导致集群ID不一致,手动修改集群ID也可以修复多次格式化问题
可以通过下列两个路径下的文件进行对比
/opt/app/hadoop-2.5.0/data/tmp/dfs/data/current
/opt/moduels/hadoop-2.5.0/data/tmp/dfs/name/current
启动 namenode和datanode
命令:
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
验证:
使用jps查看
浏览器界面
http://bigdata.001.com:50070/
http://192.168.47.105:50070/
使用命令
/user/root 是hadoop 内部创建的一个根目录地址,可以在浏览器上看到
创建: bin/hdfs dfs -mkdir -p /user/root/lee
上传: bin/hdfs dfs -put etc/hadoop/core-site.xml /user/root/lee
读取: bin/hdfs dfs -text /user/root/lee/core-site.xml
下载: bin/hdfs dfs -get /user/root/lee/core-site.xml /home/cniao/core-site.xml
启动 SecondaryNameNode
//文件操作记录会进行存储为编辑日志edits文件
//namenode格式化之后生成镜像文件,namenode启动时会读取镜像文件
//SecondaryNameNode用于合并这两个文件,减少namenode启动时间
文件地址:hadoop-2.5.0/data/tmp/dfs/name/current
流程:SecondaryNameNode读取两种文件 -> 合并为fsimage文件 -> 生成新的edits文件
修改hdfs-site.xml文件,指定secondarynamenode机器位置和交互端口号:50090
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.47.105:50090</value>
</property>
启动:sbin/hadoop-daemon.sh start secondarynamenode
检验:jps
外部访问界面:http://lee.cniao5.com:50090
//无法防止数据丢失,后续会介绍
95
1
解压Hadoop
2
tar -zxf hadoop-2.5.0.tar.gz -C /opt/moduels/
3
4
可清理文档: hadoop-2.5.0/share/doc目录
5
6
确保环境正确;
7
路径:/opt/moduels/hadoop-2.5.0
8
命令:bin/hadoop
9
10
11
Hadoop指定的java安装路径
12
etc/hadoop/hadoop-env.sh
13
//虽然官方文档没有写,但是同目录下mapred-env.sh和yarn-env.sh也做相同修改
14
export JAVA_HOME=/opt/moduels/jdk1.7.0_67
15
16
Hadoop三种运行模式
17
本地单机模式:使用本地文件系统
18
伪分布式模式:HDFS文件系统
19
完全分布式模式:HDFS文件系统(真实集群)
20
21
修改 etc/hadoop/core-site.xml
22
//默认文件系统访问入口,1.x系列端口号为9000
23
//hadoop.tmp.dir为hadoop系统生成文件的临时目录
24
25
<configuration>
26
<property>
27
<name>fs.defaultFS</name>
28
<value>hdfs://bigdata.001.com:8020</value><!--可以用IP来代替主机名-->
29
</property>
30
<property>
31
<name>hadoop.tmp.dir</name>
32
<value>/opt/moduels/hadoop-2.5.0/data/tmp</value>
33
</property>
34
</configuration>
35
36
37
修改 hdfs-site.xml
38
//修改副本数量
39
<configuration>
40
<property>
41
<name>dfs.replication</name>
42
<value>1</value>
43
</property>
44
</configuration>
45
46
修改slaves, 配置本机的主机名
47
//从节点机器位置主机名
48
bigdata.001.com
49
50
格式化namenode
51
命令:bin/hdfs namenode -format
52
查看结果:data/tmp文件夹生成文件
53
//只能格式化一次,如果有需求,将tmp文件夹下内容删除再格式化
54
//多次格式化会导致集群ID不一致,手动修改集群ID也可以修复多次格式化问题
55
可以通过下列两个路径下的文件进行对比
56
/opt/app/hadoop-2.5.0/data/tmp/dfs/data/current
57
/opt/moduels/hadoop-2.5.0/data/tmp/dfs/name/current
58
59
60
启动 namenode和datanode
61
命令:
62
sbin/hadoop-daemon.sh start namenode
63
sbin/hadoop-daemon.sh start datanode
64
验证:
65
使用jps查看
66
67
浏览器界面
68
http://bigdata.001.com:50070/
69
http://192.168.47.105:50070/
70
71
72
73
使用命令
74
/user/root 是hadoop 内部创建的一个根目录地址,可以在浏览器上看到
75
创建: bin/hdfs dfs -mkdir -p /user/root/lee
76
上传: bin/hdfs dfs -put etc/hadoop/core-site.xml /user/root/lee
77
读取: bin/hdfs dfs -text /user/root/lee/core-site.xml
78
下载: bin/hdfs dfs -get /user/root/lee/core-site.xml /home/cniao/core-site.xml
79
80
启动 SecondaryNameNode
81
//文件操作记录会进行存储为编辑日志edits文件
82
//namenode格式化之后生成镜像文件,namenode启动时会读取镜像文件
83
//SecondaryNameNode用于合并这两个文件,减少namenode启动时间
84
文件地址:hadoop-2.5.0/data/tmp/dfs/name/current
85
流程:SecondaryNameNode读取两种文件 -> 合并为fsimage文件 -> 生成新的edits文件
86
87
修改hdfs-site.xml文件,指定secondarynamenode机器位置和交互端口号:50090
88
<property>
89
<name>dfs.namenode.secondary.http-address</name>
90
<value>192.168.47.105:50090</value>
91
</property>
92
启动:sbin/hadoop-daemon.sh start secondarynamenode
93
检验:jps
94
外部访问界面:http://lee.cniao5.com:50090
95
//无法防止数据丢失,后续会介绍
- Hadoop配置——YARN与MapReduce
修改mapred-site.xml.template //.template表示不生效
删除.template
mv mapred-site.xml.template mapred-site.xml
修改mapred-site.xml
//使MapReduce运行YARN上面
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
//MapReduce运行服务
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
//resourcemanager默认为启动的机器
//伪分布式可以不进行配置,配置一般使用主机名
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.47.105</value>
</property>
启动YARN
命令:
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
//MapReduce不需要启动
//使用jps查看
外部管理界面
192.168.47.105:8088
MapReduce历史服务器
修改mapred-site.xml
//内部交互地址
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.47.105:10020</value>
</property>
//外部交互地址
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.47.105:19888</value>
</property>
启动:sbin/mr-jobhistory-daemon.sh start historyserver
检验:jps
//历史服务器需要重启HDFS与YARN
58
1
修改mapred-site.xml.template //.template表示不生效
2
删除.template
3
mv mapred-site.xml.template mapred-site.xml
4
5
修改mapred-site.xml
6
//使MapReduce运行YARN上面
7
<configuration>
8
<property>
9
<name>mapreduce.framework.name</name>
10
<value>yarn</value>
11
</property>
12
</configuration>
13
14
15
16
修改yarn-site.xml
17
//MapReduce运行服务
18
<configuration>
19
<!-- Site specific YARN configuration properties -->
20
<property>
21
<name>yarn.nodemanager.aux-services</name>
22
<value>mapreduce_shuffle</value>
23
</property>
24
</configuration>
25
26
//resourcemanager默认为启动的机器
27
//伪分布式可以不进行配置,配置一般使用主机名
28
<property>
29
<name>yarn.resourcemanager.hostname</name>
30
<value>192.168.47.105</value>
31
</property>
32
33
启动YARN
34
命令:
35
sbin/yarn-daemon.sh start resourcemanager
36
sbin/yarn-daemon.sh start nodemanager
37
//MapReduce不需要启动
38
//使用jps查看
39
40
外部管理界面
41
192.168.47.105:8088
42
43
MapReduce历史服务器
44
修改mapred-site.xml
45
//内部交互地址
46
<property>
47
<name>mapreduce.jobhistory.address</name>
48
<value>192.168.47.105:10020</value>
49
</property>
50
//外部交互地址
51
<property>
52
<name>mapreduce.jobhistory.webapp.address</name>
53
<value>192.168.47.105:19888</value>
54
</property>
55
启动:sbin/mr-jobhistory-daemon.sh start historyserver
56
检验:jps
57
//历史服务器需要重启HDFS与YARN
58
- 检验
使用单词统计进行检验
创建input文件夹 bin/hdfs dfs -mkdir -p mapreduce/input
上传统计文件 bin/hdfs dfs -put /opt/datas/file.input /user/root/mapreduce/input
//输出目录不需要提前存在,任务运行完自动创建,防止任务结果覆盖
//在yarn运行job时候都必须要打jar包
单词统计命令
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/root/mapreduce/input /user/root/mapreduce/output
查看结果
//_SUCCESS表示成功 结果在part-r-00000
bin/hdfs dfs -text /user/root/mapreduce/output/part-r-00000
14
1
使用单词统计进行检验
2
创建input文件夹 bin/hdfs dfs -mkdir -p mapreduce/input
3
上传统计文件 bin/hdfs dfs -put /opt/datas/file.input /user/root/mapreduce/input
4
5
//输出目录不需要提前存在,任务运行完自动创建,防止任务结果覆盖
6
7
//在yarn运行job时候都必须要打jar包
8
9
单词统计命令
10
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/root/mapreduce/input /user/root/mapreduce/output
11
12
查看结果
13
//_SUCCESS表示成功 结果在part-r-00000
14
bin/hdfs dfs -text /user/root/mapreduce/output/part-r-00000
- 常见问题
集群ID不一致
删除data/tmp,重新格式化
进程启动失败
这个问题需要分析log,log位置/logs
尽量用IP来代替主机名
7
1
集群ID不一致
2
删除data/tmp,重新格式化
3
4
进程启动失败
5
这个问题需要分析log,log位置/logs
6
7
尽量用IP来代替主机名
- 使用到的命令
ervice iptables stop
chkconfig iptables off
rpm -qa | grep java
rpm -e --nodeps
tar -zxf jdk-7u67-linux-x64.tar.gz -C /opt/moduels/
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
bin/hdfs dfs -mkdir -p /user/root/lee
bin/hdfs dfs -put etc/hadoop/core-site.xml /user/root/lee
bin/hdfs dfs -text /user/root/lee/core-site.xml
bin/hdfs dfs -get /user/root/lee/core-site.xml /home/cniao/core-site.xml
sbin/hadoop-daemon.sh start secondarynamenode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/root/mapreduce/input /user/root/mapreduce/output
bin/hdfs dfs -text /user/root/mapreduce/output/part-r-00000
17
1
ervice iptables stop
2
chkconfig iptables off
3
rpm -qa | grep java
4
rpm -e --nodeps
5
tar -zxf jdk-7u67-linux-x64.tar.gz -C /opt/moduels/
6
sbin/hadoop-daemon.sh start namenode
7
sbin/hadoop-daemon.sh start datanode
8
bin/hdfs dfs -mkdir -p /user/root/lee
9
bin/hdfs dfs -put etc/hadoop/core-site.xml /user/root/lee
10
bin/hdfs dfs -text /user/root/lee/core-site.xml
11
bin/hdfs dfs -get /user/root/lee/core-site.xml /home/cniao/core-site.xml
12
sbin/hadoop-daemon.sh start secondarynamenode
13
sbin/yarn-daemon.sh start resourcemanager
14
sbin/yarn-daemon.sh start nodemanager
15
sbin/mr-jobhistory-daemon.sh start historyserver
16
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/root/mapreduce/input /user/root/mapreduce/output
17
bin/hdfs dfs -text /user/root/mapreduce/output/part-r-00000