分类目录:《自然语言处理从入门到应用》总目录
相关文章:
· GPT(Generative Pre-Trained Transformer):基础知识
· GPT(Generative Pre-Trained Transformer):在不同任务中使用GPT
· GPT(Generative Pre-Trained Transformer):GPT-2与Zero-shot Learning
· GPT(Generative Pre-Trained Transformer):GPT-3与Few-shot Learning
GPT预训练语言模型作为一个标准的语言模型,其输入和输出是固定的,即输入一个词序列,输出该词序列的下一个词。《深入理解深度学习——GPT(Generative Pre-Trained Transformer):基础知识》已经完整地剖析了GPT的模型结构,即使在监督微调阶段添加了针对不同任务的自适应层,GPT的输入和输出依旧没有本质上的改变。对于一些任务(如文本分类任务),可以通过带标签的文本分类数据,然后使用微调方法进行训练,让GPT学会文本分类。文本分类任务的微调数据格式如下:
输入文本:梅西宣布退役。
标签:体育新闻
虽然标签代表的文本与输入文本并没有因果关系,但语义上存在强关联,可以理解为预训练语言模型经过微调训练能够学会这样的映射。对于输入文本包含多个句子(有序的句子对、二元组、三元组)的任务,如问答或常识性推理任务,其训练数据的格式如下:
问:今天天气怎么样?
答1:今天多云转阴,气温23摄氏度。
答2:今天适合去爬山。
答3:周末天气很好。
正确选择:答1
对于由多个句子按照规定组合而成的数据格式,GPT显然无法通过更改其输入数据格式来匹配指定任务。将问答语句揉在一起作为输入序列的简单拼接方式存在明显的隐患,事实上,这样做也无法获得很好的微调效果。思考Self-Attention过程在以下输入语句上的表现:
今天天气怎么样?今天多云转阴,气温23摄氏度。今天适合去爬山。周末天气很好。
隐患一,虽然Self-Attention的计算过程不考虑词与词之间的距离,直接计算两个词的语义关联性,但是位置编码会引入位置关系,人类语言学认知及实验结果均表明,距离越近的词具有的语义相关性越强。因此,直接拼接的输入会导致相同的答案在不同的位置与问句产生不同的相关性,即答案之间存在不公平的现象。
隐患二,模型无法准确分割问句与多个答句,通常,模型可以根据问号区分问句和答句,或根据句号来辨别输入的不同答句。在本例中,模型确实可以判断出输入序列是“问+答+答+答”的形式,但是如果问句不带问号,或者答句内部存在句号,则会出现问题,例如:
怎样用一句话证明你去过北京?
北京很干燥。而且北京风沙很大。北京冬天很冷。
但是北京的烤鸭很好吃。
模型无法根据句号来判断这是两个答案还是四个答案。除此之外,句号作为常见的标点符号,本身就具有终止的含义,将句号作为分隔符会对模型产生较大影响。考虑到以上两个隐患,GPT采用遍历式方法(Traversal-style Approach)做输入数据预处理,从而将预训练语言模型应用于有序句对或者多元组任务。如下图所示,列出了分类、蕴含、相似度、多选这4类任务的输入转化格式。注意,对于每个特定的任务,输入数据的首尾必须添加起始符和终止符,记为<s>和<e>。接下来介绍转化细节:
- 蕴含
- 任务介绍:给定一个前提 P P P(Premise),根据这个前提推断假设 H H H(Hypothesis)与前提 P P P的关系,蕴含关系表示可以根据前提 P P P推理得到假设 H H H。蕴含任务就是计算在已知前提 P P P的情况下,能推理得到假设 H H H成立的概率值。
- 输入改写:顺序连接前提 P P P和假设 H H H,中间加入分隔符
$,如下图中蓝色部分所示。 - 样例:
<s>你借我的球明天还你。$你的球在我这里。<e>
- 相似度(
- 任务介绍:给定两个文本序列,判断两个序列的语义相似性,以概率表示。
- 输入改写:相似度任务中的两个文本序列并没有固定顺序,为了避免序列顺序对相似度计算造成干扰,生成两个不同顺序的输入序列,经过GPT主模型(12个Transformer Block)后,得到语义特征向量 h i m h_i^m him,在输入至任务独有的线性层之前按元素相加,如下图中黄色部分所示。
- 样例:
<s>她很漂亮$她很好看<e><s>她很好看$她很漂亮<e>
- 多选
- 任务介绍:给定上下文文档 Z Z Z(也可以没有)、一个问题 Q Q Q(Wuestion)和一组可能的答案 a k a_k ak(Answer),从可能的答案中选取最佳答案。
- 输入改写:将上下文 Z Z Z和问题 Q Q Q连在一起作为前提条件,加入分隔符与每个可能的答案 a k a_k ak拼接,得到 [ Z ; W ; a k ] [Z; W; a_k] [Z;W;ak]序列。这些序列都用GPT单独进行处理(包括独有的线性层),最后通过Softmax层进行规范化,在所有可能的答案上计算一个概率分布,如下图中紫色部分所示。
- 样例:
<s>今天天气怎么样?$今天多云转阴,气温23摄氏度。<e><s>今天天气怎么样?$今天适合去爬山。<e><s>今天天气怎么样?$周末天气很好。<e>
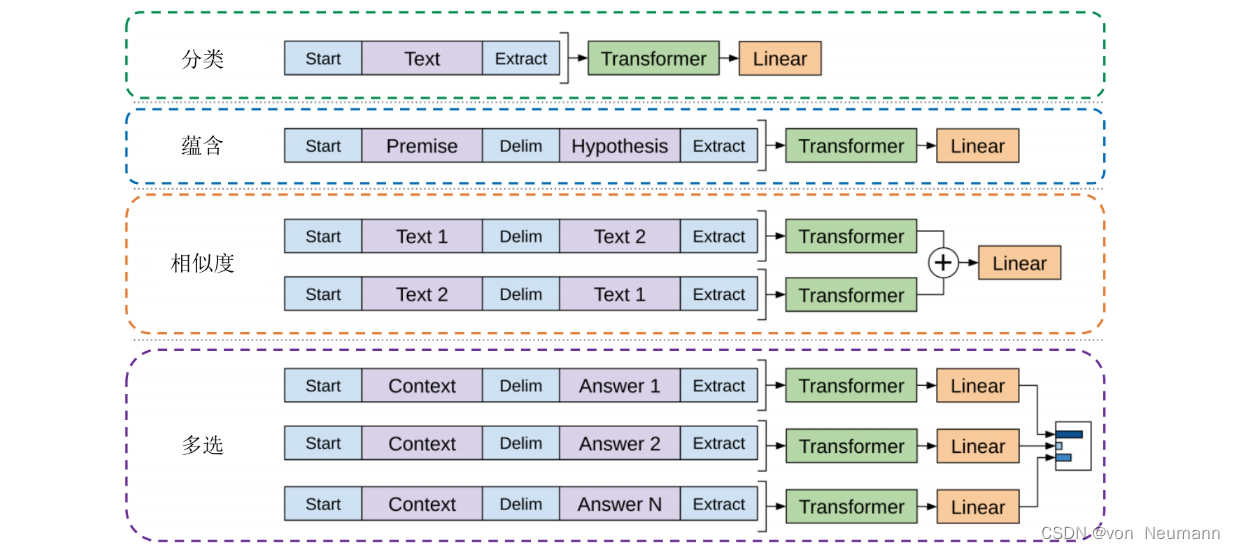
回顾前面提到的两个隐患,可以发现,通过遍历式方法和采用特殊分隔(起始/终止)符可以很好地规避隐患。相似度任务通过交换输入文本的顺序来消除句子相对位置带来的干扰,而多选任务则通过遍历单个问句和答句组合的方式,规避了句子相对位置带来的不公平性。用固定特殊符号$作为分隔符也避免了采用句号等通用标点作为分隔符所产生的不利影响。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[4] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[5] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[6] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.