分类目录:《深入理解深度学习》总目录
相关文章:
· GPT(Generative Pre-Trained Transformer):基础知识
· GPT(Generative Pre-Trained Transformer):在不同任务中使用GPT
· GPT(Generative Pre-Trained Transformer):GPT-2与Zero-shot Learning
· GPT(Generative Pre-Trained Transformer):GPT-3与Few-shot Learning
N-shot Learning
在介绍GPT的第二代模型GPT-2之前,先来介绍机器学习中的三个概念:Zero-shot Learning(零样本学习)、One-shot Learning(单样本学习)和Few-shot Learning(少样本学习)。深度学习技术的迅速发展离不开大量高质量的数据,但在很多实际应用场景中,获取大量的高质量数据非常困难,所以模型能从少量样本中学习规律并具备推理能力是至关重要的。人类具有极其良好的小样本学习能力,能从少量数据中提炼出抽象概念并推理应用,这也是机器学习未来最主要的发展方向,这个研究方向就是N-shot Learning,其中字母N表示样本数量较少。具体而言,N-shot Learning又分为Zero-shot Learning、One-shot Learning和Few-shot Learning,三者所使用的样本量依次递增。
Zero-shot Learning是指在没有任何训练样本进行微调训练的情况下,预训练语言模型就可以完成特定的任务。用一个形象的例子解释:爸爸拿了一堆动物卡片教小维认识卡片中的动物,小维拿起一张画着马的卡片,爸爸告诉他,这就是马。之后,小维又拿起了画着老虎的卡片,爸爸告诉他:“看,这种身上有条纹的动物就是老虎。”爸爸拿起了画有熊猫的卡片,对小维说:“你看熊猫是黑白色的。”然后,爸爸给小维安排了一个任务,让他在卡片里找一种他从没见过的动物——斑马,并告诉小维有关于斑马的信息:“斑马有着马的轮廓,身上有像老虎一样的条纹,而且它像熊猫一样是黑白色的。”最后,小维根据爸爸的提示,找到了画有斑马的卡片。One-shot Learning是指在仅有一个训练样本进行微调训练的情况下,预训练语言模型就可以完成特定的任务。用一个形象的例子解释:爸爸拿了一张柴犬的卡片给小维,告诉他:“这是柴犬,是犬类的一种。”然后爸爸给了小维三张卡片,卡片上分别画有橘猫、东北虎和金毛,让小维指出哪张卡片上的动物属于犬类,小维根据柴犬的特征,指向画有金毛的卡片。Few-shot Learning是指在仅有少量训练样本进行微调训练的情况下,预训练语言模型就可以完成特定的任务。同样用一个形象的例子解释:爸爸拿了五张分别画有柴犬、柯基、边牧、哈士奇和阿拉斯加的卡片,告诉小维,这些都属于犬类,然后给了小维三张卡片,分别画有橘猫、东北虎和金毛,让小维指出哪张卡片上的动物属于犬类,小维根据已有的五张犬类卡片的特征,指向画有金毛的卡片。近年来,面向N-shot Learning的研究发展极为迅速,出现了基于度量的元学习、图网络等方法。本文和后续的文章就借助Zero-shot Learn-ing、One-shot Learning、Few-shot Learning的概念来呈现GPT系列模型的一些特性。
GPT-2的核心思想
GPT-2的核心思想并不是通过二阶段训练模式(预训练+微调)获得特定自然语言处理任务中更好的性能,而是彻底放弃了微调阶段,仅通过大规模多领域的数据预训练,让模型在Zero-shot Learning的设置下自己学会解决多任务的问题。与之相对的是,在特定领域进行监督微调得到的专家模型并不具备多任务场景下的普适性。GPT-2的惊艳之处在于,它展示了语言模型在Zero-shot Learning设置下依然能够很好地执行各种任务的能力与潜力,证明了自然语言处理领域通用模型的可能性。GPT-2在多个特定领域的语言建模任务(给定词序列,预测下一个词)上均超越了当前最佳的模型的性能,而在此之前,这些任务的最佳表现均来自特定领域数据集上微调训练得到的专家模型。GPT-2并没有使用任务提供的特定领域的训练集进行训练甚至微调,而是直接在这些任务的测试集上进行评估。让人惊讶的是,GPT-2在这些语言建模任务上的表现优于以往的专家模型的表现,在某些任务上的性能提升非常显著。
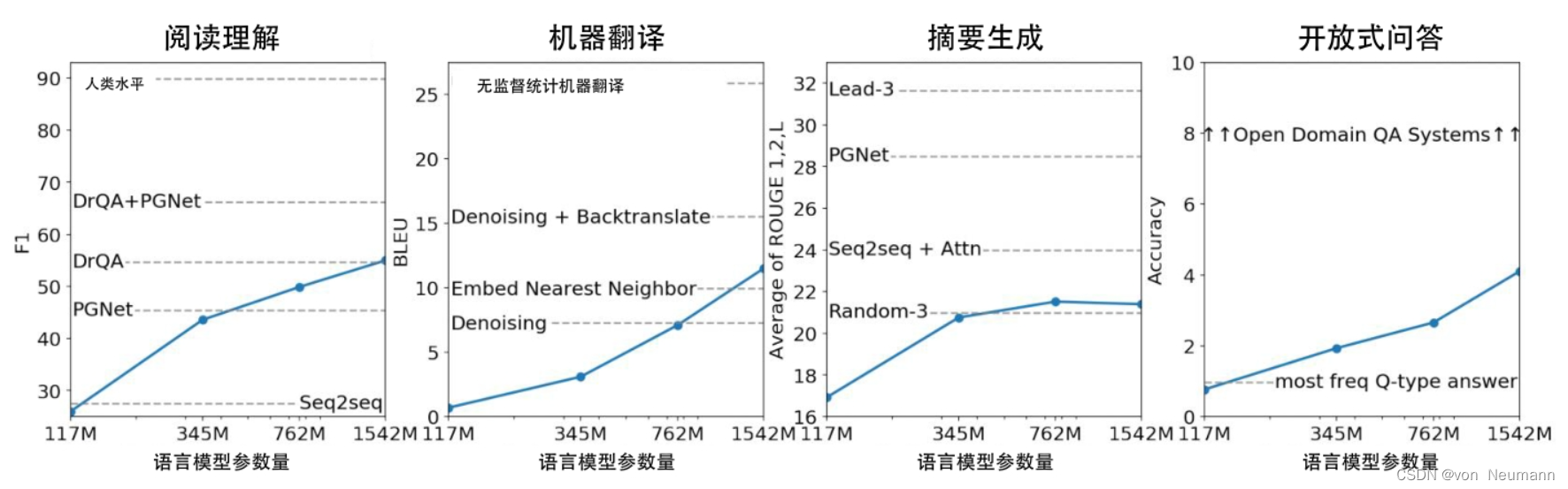
在问答、阅读理解及自动摘要等具有不同输入和输出格式的语言任务中,GPT-2直接采用与GPT一致的输入数据转换方式,得到了令人惊艳的结果。虽然性能无法与专家模型相比,但是从论文给出的模型参数与任务性能趋势图来看,现有的GPT-2模型存在巨大的上升空间。如下图所示,从左至右分别是GPT-2在Zero-shot Learning设置下在阅读理解、机器翻译、摘要生成及开放式问答这4个任务上的表现。虽然GPT-2在Zero-shot Learning设置下的表现远不如SOTA模型,但基本超越了简单模型。除了摘要生成任务,GPT-2在其余三个任务上都表现出了性能随模型规模的增大而提升的趋势,且提升十分明显。这意味着若继续扩大GPT-2的规模,其性能还能提升。
GPT-2模型结构
与第一代GPT模型相比,GPT-2在模型结构上的改动极小。在复用GPT的基础上,GPT-2做了以下修改:
- LN层被放置在Self-Attention层和Feed Forward层前,而不是像原来那样后置
- 在最后一层Transformer Block后新增LN层
- 修改初始化的残差层权重,缩放为原来的 1 N \frac{1}{\sqrt{N}} N1。其中, N N N是残差层的数量
- 特征向量维数从768扩大到1600,词表扩大到50257
- Transformer Block的层数从12扩大到48。GPT-2有4个不同大小的模型,它们的参数设置如下表所示
| 总参数量 | 层数 | 特征向量维数 |
|---|---|---|
| 117M | 12 | 768 |
| 345M | 24 | 1024 |
| 762M | 36 | 1280 |
| 1542M | 48 | 1600 |
其中最小的模型其实就是第一代GPT,参数量也达到了1.17亿;而参数量高达15亿的最大模型,一般被称为GPT-2。模型扩大了10多倍,意味着需要增加足够的数据量,否则会出现欠拟合现象。第一代GPT使用的训练语料是BookCorpus数据集,包含超过7000本未出版的书籍。GPT-2使用的训练语料是从800多万个网页中爬取到的单语数据,数据量是第一代GPT所使用数据量的10多倍,而来自众多网页的语料,涵盖了各个领域、各种格式的文本信息,在一定程度上提升了GPT-2在Zero-shot Learning设置下处理特定任务的能力。GPT-2的不俗表现,证明它是一个极其优秀的预训练语言模型,虽然OpenAI并没有给出GPT-2微调后在各下游任务中的表现,但可以预期的是,其效果一定很好,在监督微调阶段的训练方式与第一代GPT并无差别。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[4] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[5] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[6] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.