CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.On the Hidden Mystery of OCR in Large Multimodal Models

标题:论大型多模态模型中 OCR 的隐藏奥秘
作者:Yuliang Liu, Zhang Li, Hongliang Li, Wenwen Yu, Mingxin Huang, Dezhi Peng, Mingyu Liu, Mingrui Chen, Chunyuan Li, Lianwen Jin, Xiang Bai
文章链接:https://arxiv.org/abs/2305.07895
项目代码:https://github.com/Yuliang-Liu/MultimodalOCR
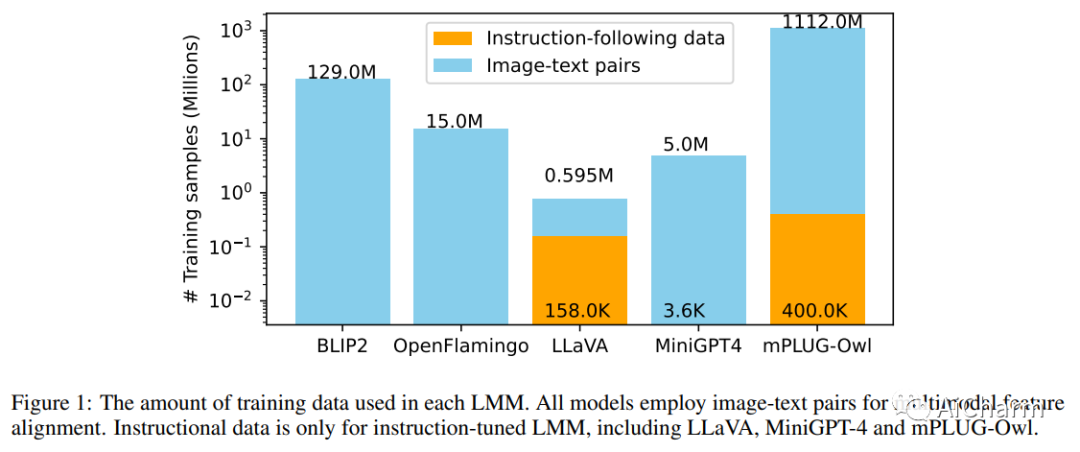
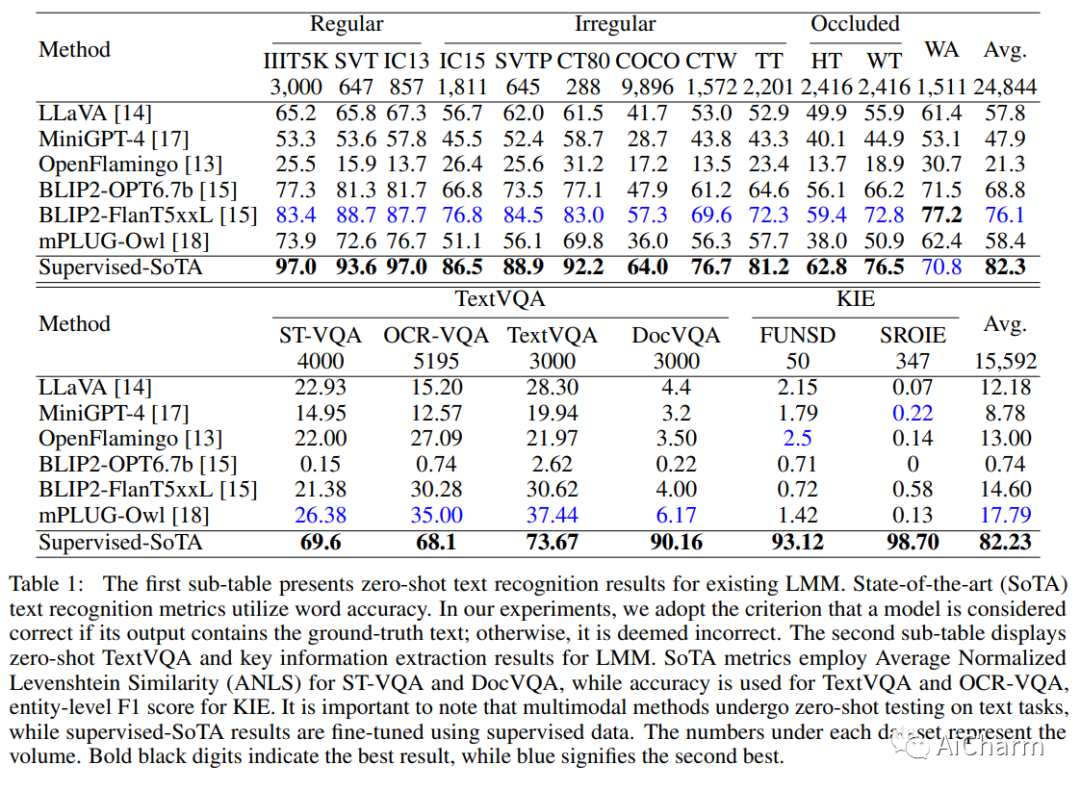

摘要:
大型模型最近在自然语言处理和多模态视觉语言学习中发挥了主导作用。关于它们在与文本相关的视觉任务中的功效的探索仍然较少。我们对现有的公开可用的多模态模型进行了全面研究,评估了它们在文本识别、基于文本的视觉问答和关键信息提取方面的性能。我们的发现揭示了这些模型的优点和缺点,这些模型主要依靠语义理解来识别单词,并且对单个字符形状的感知较差。它们还对文本长度表现出漠不关心,并且在检测图像中的细粒度特征方面的能力有限。因此,这些结果表明,即使是当前最强大的大型多模态模型也无法与传统文本任务中的领域特定方法相媲美,并且在更复杂中面临更大的挑战。最重要的是,本研究中展示的基线结果可以为旨在增强零样本多模式技术的创新策略的概念和评估提供基础框架。评估管道将在这个 https URL 上可用。
2.BlendFields: Few-Shot Example-Driven Facial Modeling(CVPR 2023)

标题:BlendFields:Few-Shot 示例驱动的面部建模
作者:Kacper Kania, Stephan J. Garbin, Andrea Tagliasacchi, Virginia Estellers, Kwang Moo Yi, Julien Valentin, Tomasz Trzciński, Marek Kowalski
文章链接:https://arxiv.org/abs/2305.07514
项目代码:https://blendfields.github.io/

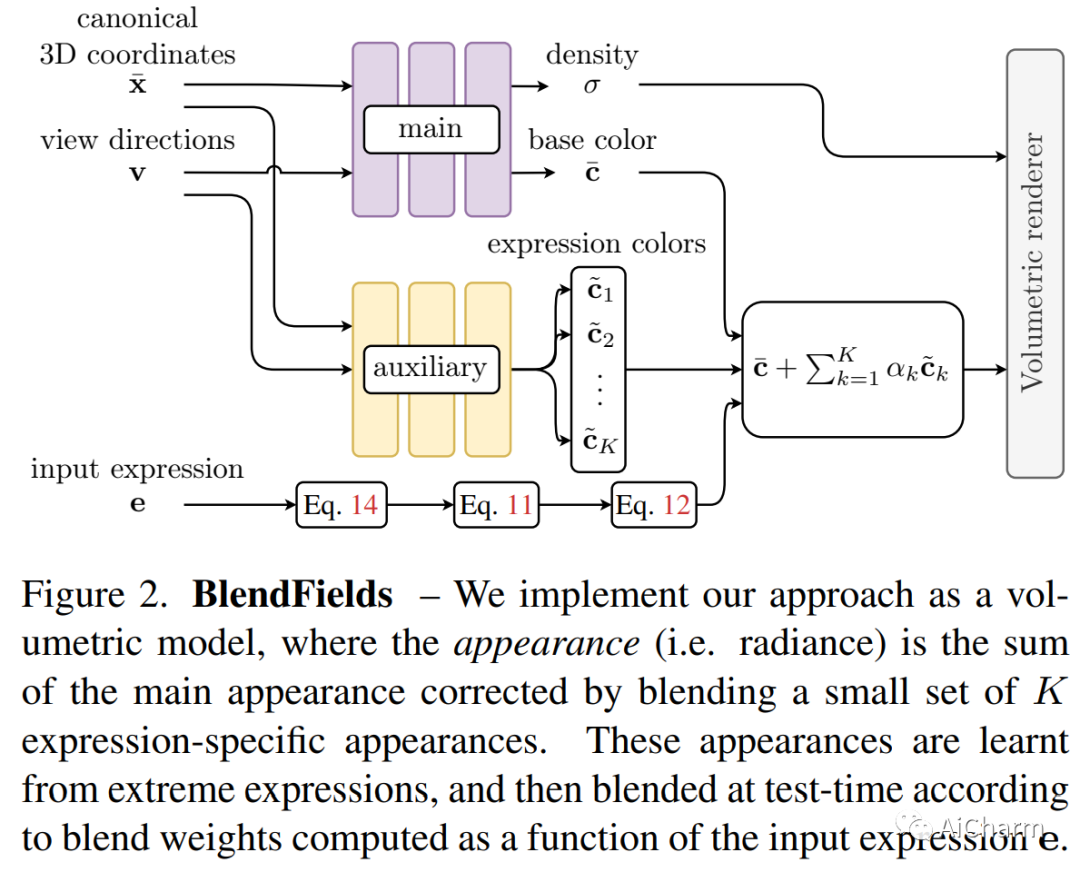
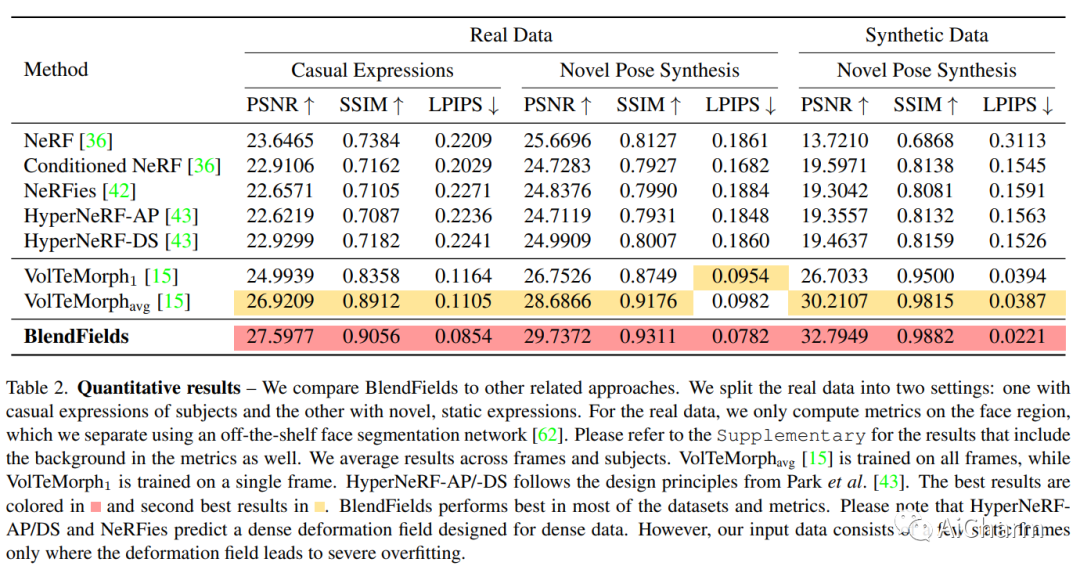
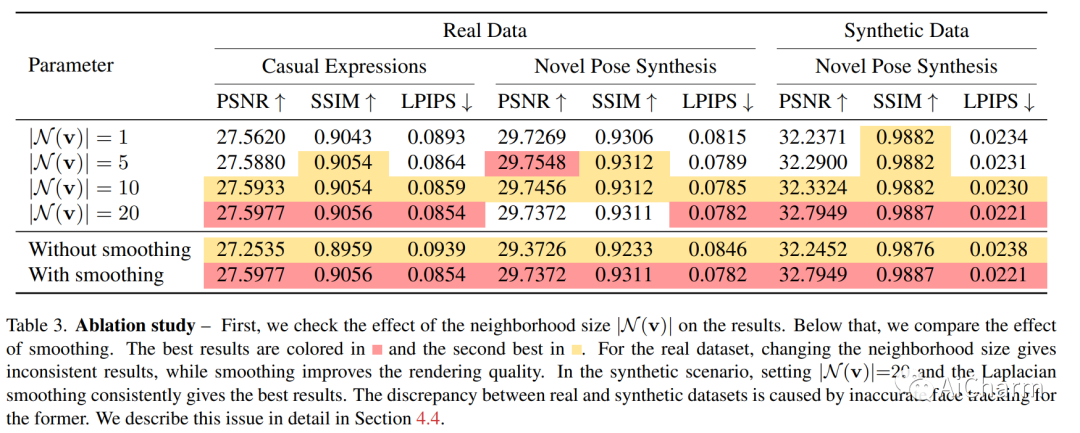
3.CodeT5+: Open Code Large Language Models for Code Understanding and Generation

标题:CodeT5+:用于代码理解和生成的开放代码大型语言模型
作者:Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi D.Q. Bui, Junnan Li, Steven C.H. Hoi
文章链接:https://arxiv.org/abs/2305.07922
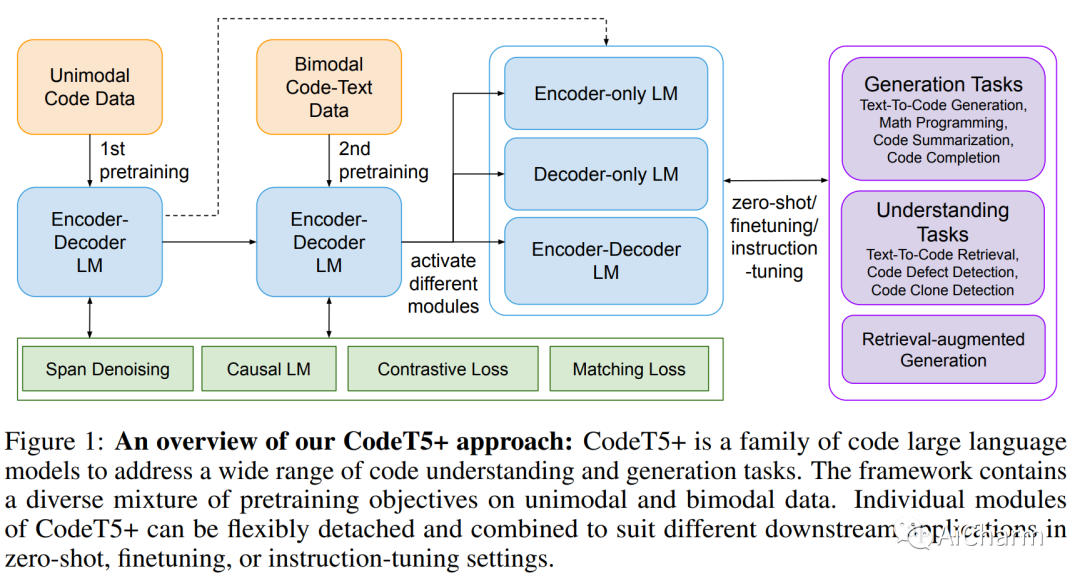




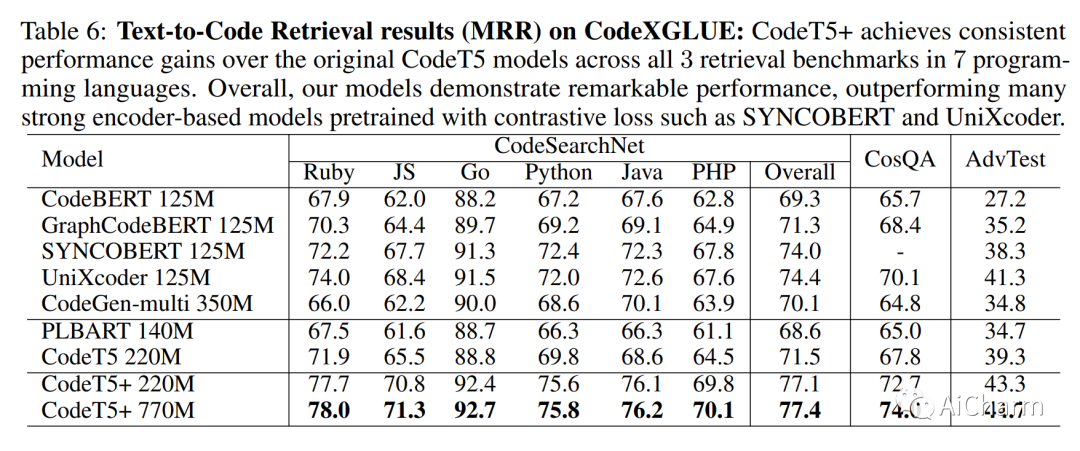
摘要:
在大量源代码上预训练的大型语言模型 (LLM) 在代码智能方面取得了显着进步。然而,现有的代码 LLM 在架构和预训练任务方面有两个主要限制。首先,它们通常采用特定的架构(仅编码器或仅解码器)或依赖统一的编码器-解码器网络来完成不同的下游任务。前者范式受到应用程序不灵活的限制,而在后者中,模型被视为所有任务的单一系统,导致任务子集的性能不佳。其次,他们通常使用一组有限的预训练目标,这些目标可能与某些下游任务无关,因此导致性能大幅下降。为了解决这些限制,我们提出了“CodeT5+”,这是一个用于代码的编码器-解码器 LLM 系列,其中的组件模块可以灵活组合以适应各种下游代码任务。这种灵活性是由我们提出的预训练目标混合实现的,以减轻预训练-微调差异。这些目标涵盖单峰和双峰多语言代码语料库的跨度去噪、对比学习、文本代码匹配和因果 LM 预训练任务。此外,我们建议使用冻结的现成 LLM 初始化 CodeT5+,无需从头开始训练,以有效地扩展我们的模型,并探索指令调优以与自然语言指令保持一致。我们在不同设置(包括零样本、微调和指令调整)的 20 多个与代码相关的基准测试中广泛评估了 CodeT5+。我们观察了各种与代码相关的任务(例如代码生成和完成、数学编程和文本到代码检索任务)的最先进 (SoTA) 模型性能。特别是,我们的指令调优 CodeT5+ 16B 在 HumanEval 代码生成任务上针对其他开放代码 LLM 取得了新的 SoTA 结果。
更多Ai资讯:公主号AiCharm