CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Improved baselines for vision-language pre-training

标题:改进视觉语言预训练的基线
作者:Enrico Fini, Pietro Astolfi, Adriana Romero-Soriano, Jakob Verbeek, Michal Drozdzal
文章链接:https://arxiv.org/abs/2305.08675
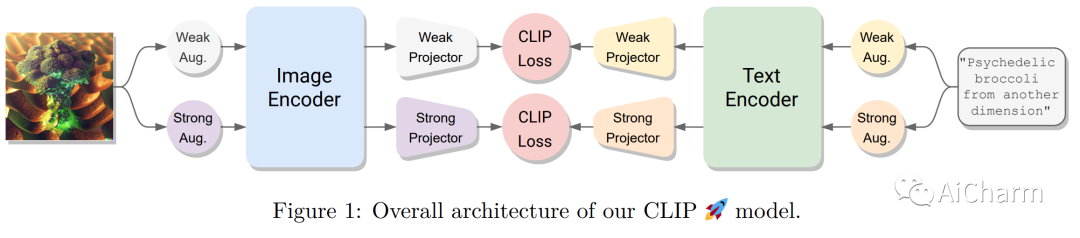

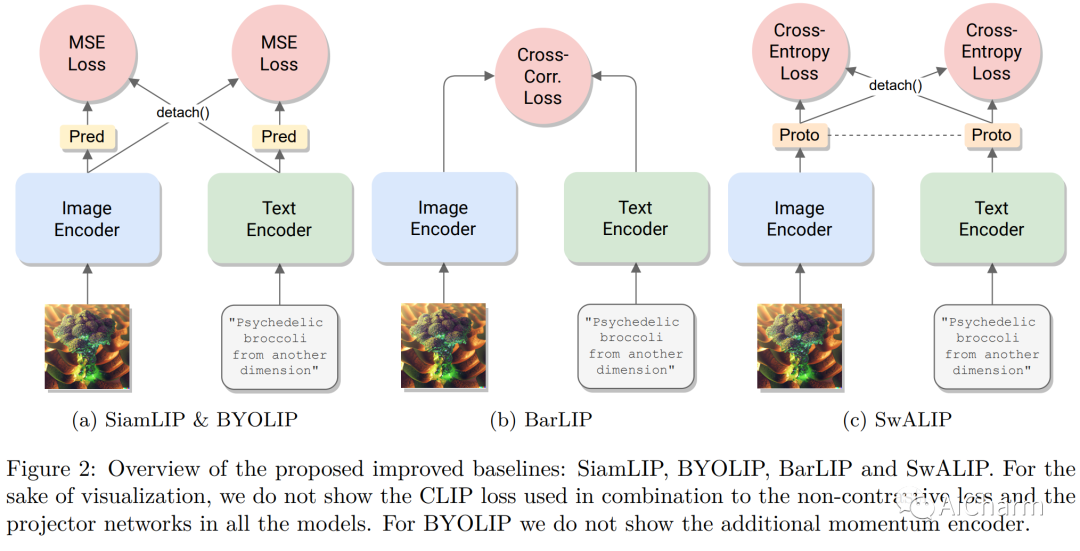

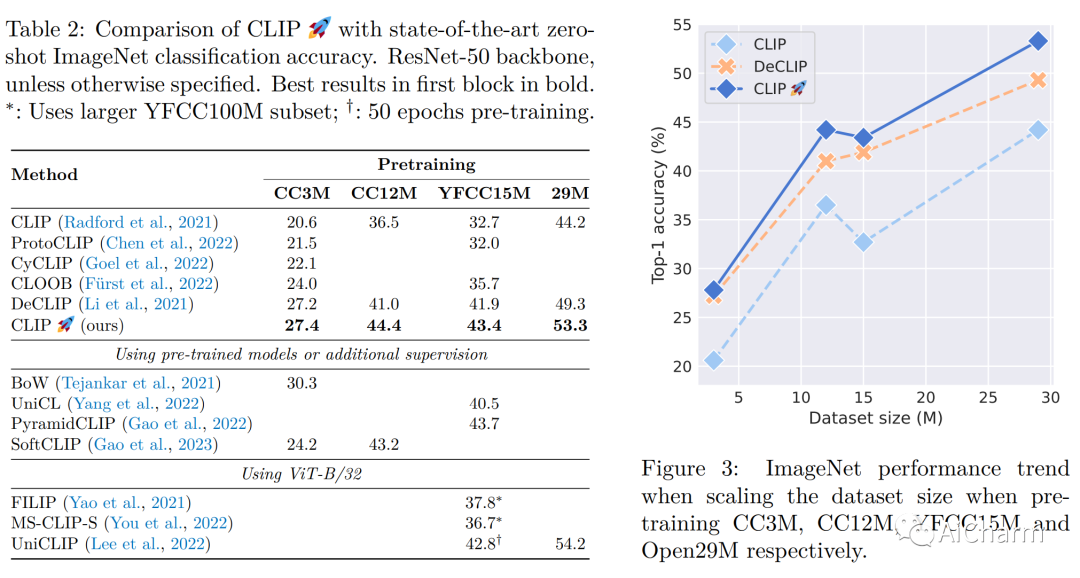
摘要:
对比学习已成为学习多模态表示的有效框架。CLIP 是该领域的一项开创性工作,通过使用对比损失对成对的图像文本数据进行训练,取得了令人瞩目的成果。最近的工作声称使用受自监督学习启发的额外非对比损失对 CLIP 进行了改进。然而,有时很难将这些额外损失的贡献与用于训练模型的其他实现细节(例如数据增强或正则化技术)区分开来。为了阐明这个问题,在本文中,我们首先提出、实施和评估通过将对比学习与自监督学习的最新进展相结合而获得的几个基线。特别是,我们使用已被证明对视觉自监督学习成功的损失函数来对齐图像和文本模式。我们发现这些基线优于 CLIP 的基本实现。然而,当使用更强的训练方法时,优势就消失了。事实上,我们发现通过使用在其他子领域流行的众所周知的训练技术,一个简单的 CLIP 基线也可以得到实质性的改进,下游零样本任务的相对改进高达 25%。此外,我们发现应用图像和文本增强足以弥补先前工作所获得的大部分改进。借助我们改进的 CLIP 训练方法,我们在四个标准数据集上获得了最先进的性能,并且始终优于之前的工作(在最大数据集上高达 +4%),同时变得更加简单。
Subjects: cs.CL
2.ArtGPT-4: Artistic Vision-Language Understanding with Adapter-enhanced MiniGPT-4

标题:ArtGPT-4:使用 Adapter-enhanced MiniGPT-4 进行艺术视觉-语言理解
作者:Zhengqing Yuan, Huiwen Xue, Xinyi Wang, Yongming Liu, Zhuanzhe Zhao, Kun Wang
文章链接:https://arxiv.org/abs/2305.07490
项目代码:https://huggingface.co/Tyrannosaurus/ArtGPT-4
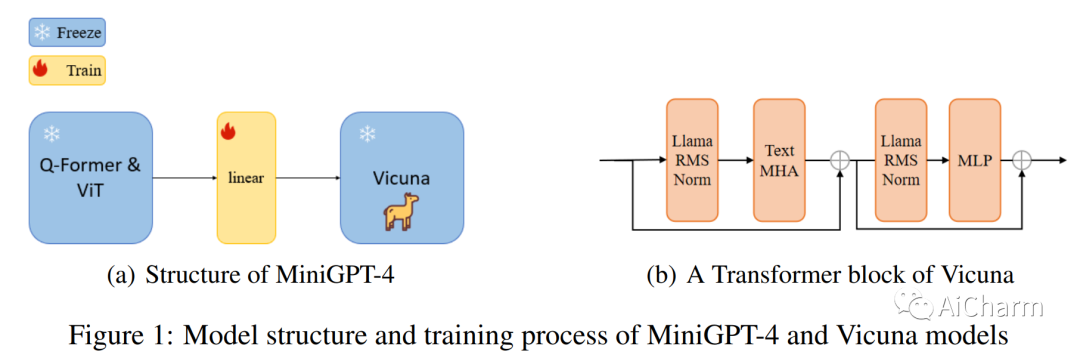
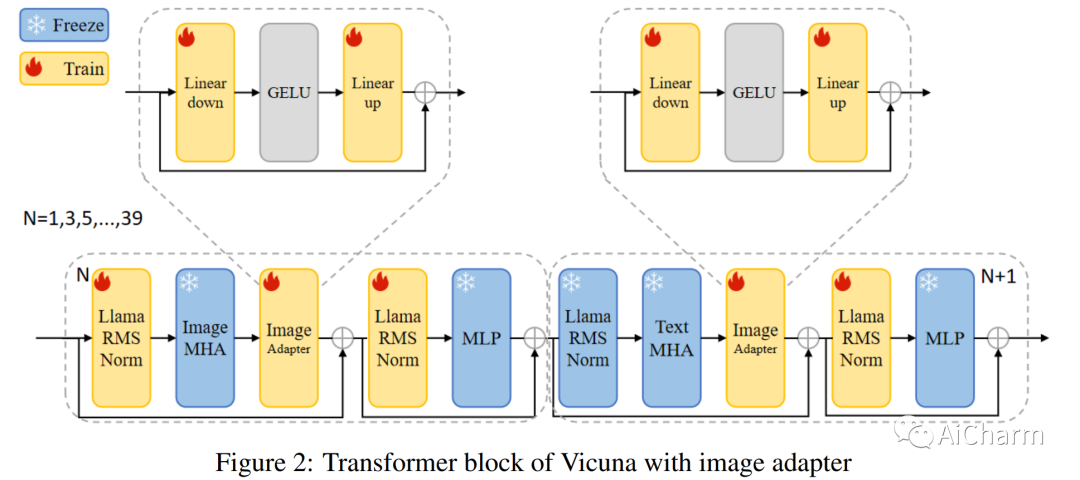



摘要:
近年来,大型语言模型 (LLM) 在自然语言处理 (NLP) 方面取得了重大进展,ChatGPT 和 GPT-4 等模型在各种语言任务中取得了令人瞩目的能力。然而,训练如此大规模的模型具有挑战性,并且通常很难找到与模型规模相匹配的数据集。使用新方法微调和训练参数较少的模型已成为克服这些挑战的有前途的方法。MiniGPT-4 就是这样一种模型,它通过利用新颖的预训练模型和创新的训练策略,实现了与 GPT-4 相当的视觉语言理解。然而,该模型在图像理解方面仍然面临一些挑战,特别是在艺术图片方面。已经提出了一种称为 ArtGPT-4 的新型多模式模型来解决这些限制。ArtGPT-4 使用 Tesla A100 设备在短短 2 小时内就图像文本对进行了训练,仅使用了大约 200 GB 的数据。该模型可以描绘具有艺术气息的图像并生成视觉代码,包括美观的 HTML/CSS 网页。此外,本文提出了用于评估视觉语言模型性能的新颖基准。在随后的评估方法中,ArtGPT-4 得分比当前 \textbf{state-of-the-art} 模型高出 1 分以上,在 6 分制上仅比艺术家低 0.25 分。
3.StructGPT: A General Framework for Large Language Model to Reason over Structured Data

标题:StructGPT:用于推理结构化数据的大型语言模型的通用框架
作者:Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
文章链接:https://arxiv.org/abs/2305.09645
项目代码:https://github.com/RUCAIBox/StructGPT
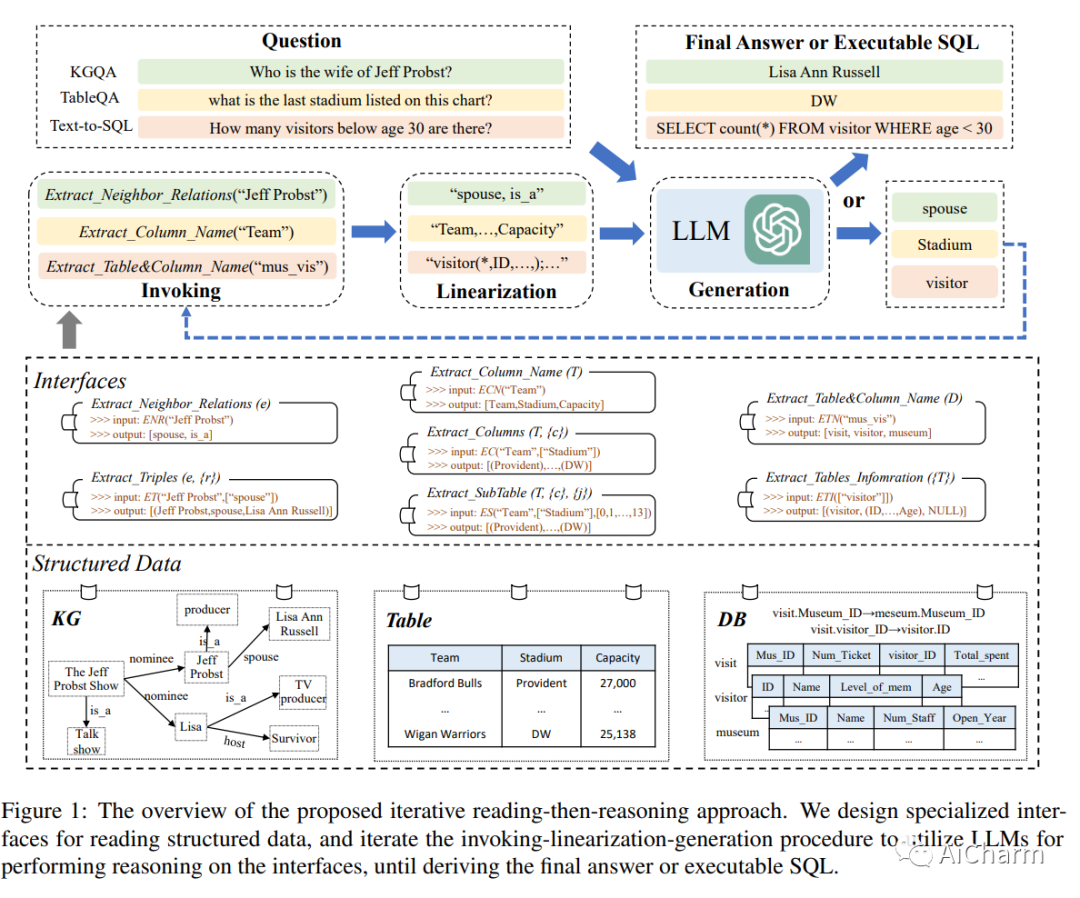

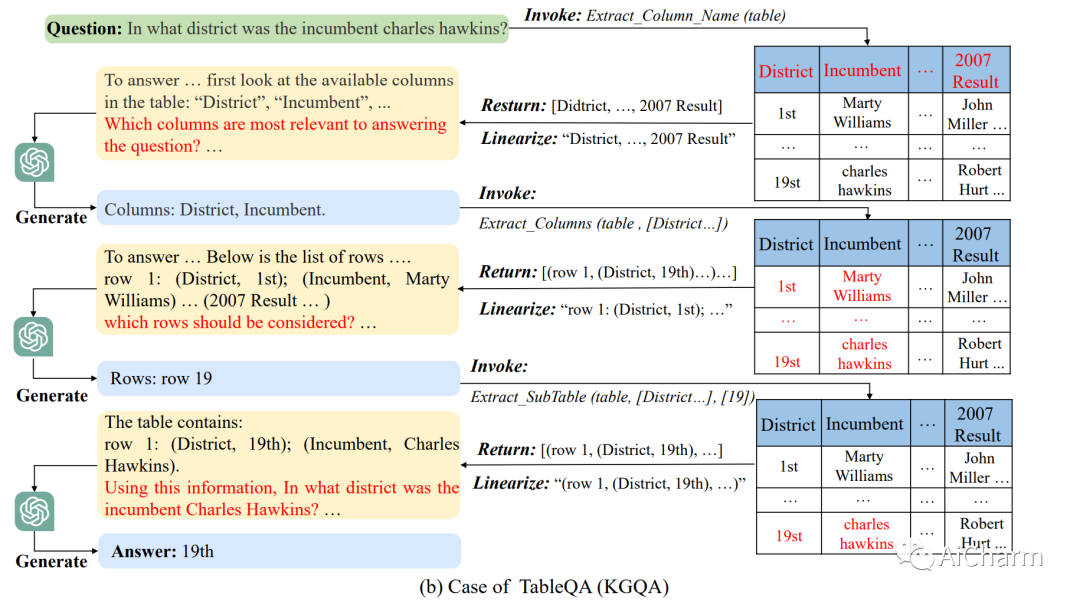

摘要:
在本文中,我们研究了如何以统一的方式提高大型语言模型〜(LLM)对结构化数据的零样本推理能力。受 LLM 工具增强研究的启发,我们开发了一种 Iterative Reading-then-Reasoning~(IRR)方法来解决基于结构化数据的问答任务,称为StructGPT。在我们的方法中,我们构建了专门的函数来从结构化数据中收集相关证据reading),并让 LLM 基于收集到的信息 reasoning)集中推理任务。特别地,我们提出了一个invoking-linearization-generation过程来支持 LLM 在外部接口的帮助下对结构化数据进行推理。通过使用提供的接口迭代此过程,我们的方法可以逐渐接近给定查询的目标答案。对三种类型的结构化数据进行的大量实验证明了我们方法的有效性,它可以显着提高 ChatGPT 的性能,并实现与全数据监督调整基线相当的性能。
更多Ai资讯:公主号AiCharm