CLIP : Learning Transferable Visual Models From Natural Language Supervision
Introduction
在raw的数据上自监督的训练模型,已经在NLP领域取得了革命性进展,这种模型需要收到硬件、数据的限制,但是能得到很好的迁移性,如GPT3的Zero-shot能力。
但是在视觉领域,还需要在固定的数据集上训练,如果有新的类别加入,还需要重新训练模型。
以前也有人尝试利用文本的语义来辅助训练视觉模型,但是效果都不是很好,作者指出原因可能是以前没有现在这么大的算力、模型(VIT)、自监督训练(也就是数据量可以很大但是不需要很贵的标注成本)。
在这篇文章,作者收集了4亿个(文本、图像)的数据对通过对比学习的方式对模型进行训练,发现在很多领域如OCR、分类等都能表现出很好的Zero-shot能力,有很好的泛化性,还发现模型的尺寸与精度成正比。
Approach
CLIP证明了在大量的数据集上做简单的预训练就可以在其他任意领域的下游任务表现出一个很好的Zero-shot的能力。
为了对齐预训练语言模型,其中描述图像的文本不单是一个单词,比如说dog-> a photo of dog,作者基于不同类别的图像构建70多个描述图像的模版。
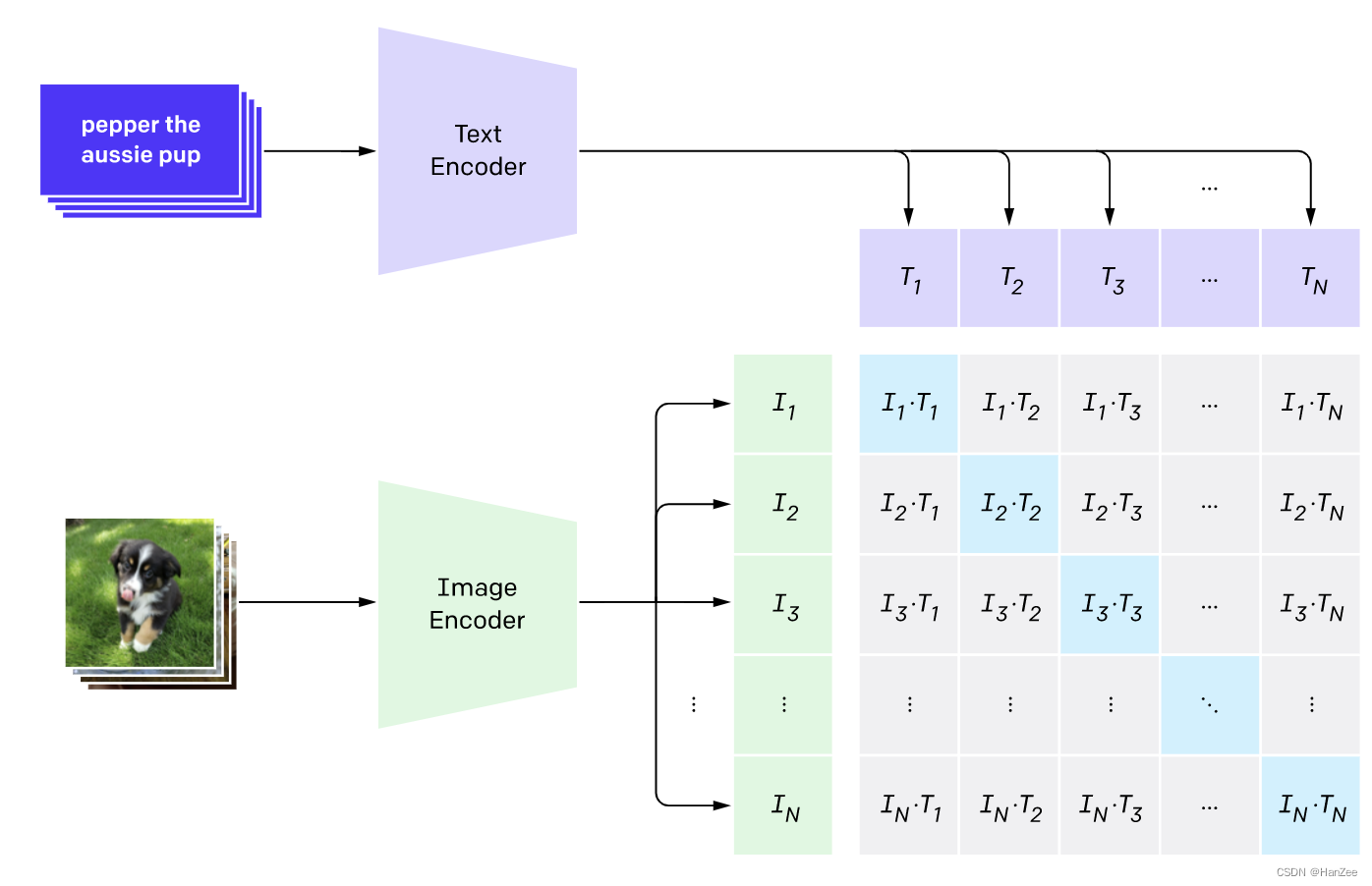
在预训练模型时期,如上图,描述图像的文本与图像分别通过Text Encoder、与Image Encoder 转换成对应的向量,其中Ti表示一个batch中第i个图像表示的特征,Ii表示第i张图像表示的特征。
之后采用对比学习的形式对这两组特征做点乘,结果作为模型的logits,对角线的元素表示了对应的文本与图像的乘积,优化目标就是让对角线的元素softmax后的结果趋近于1,其他趋近于0,分别以图像与文本两个维度做cross_entropy_loss,然后对二者loss加权求和计算总loss。
伪代码如下:

在推理的时候,可以复用在预训练的时候的label,如果在别的领域做下游任务,可以自定义label。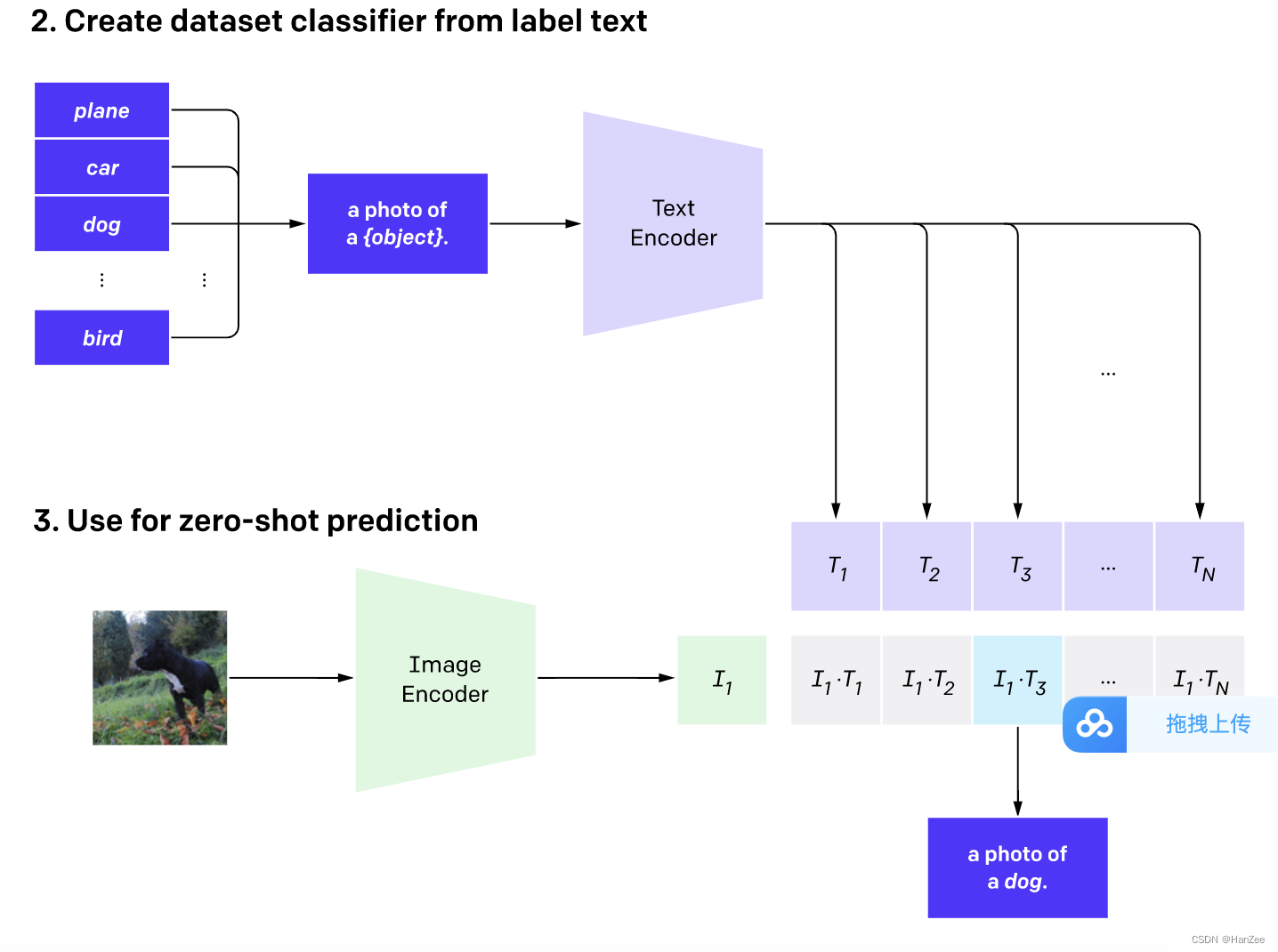
把我们定义好的N个label通过Text Encoder得到N个文本特征,图像输入Image Encoder得到这个图像的特征,然后把图像与N个文本特征做点乘,通过softmax得到类别概率。
参考
https://arxiv.org/abs/2103.00020