Abstract(摘要)
We introduce SinGAN, an unconditional generative model that can be learned from a single natural image. Our model is trained to capture the internal distribution of patches within the image, and is then able to generate high quality, diverse samples that carry the same visual content(视觉内容)as the image. SinGAN contains a pyramid(金字塔) of fully convolutional(全卷积) GANs, each responsible for learning the patch distribution at a different scale of the image. This allows generating new samples of arbitrary size(任意大小) and aspect ratio(高宽比), that have significant variability(具有显著可变性), yet maintain both the global structure and the fine textures(纹理特征) of the training image. In contrast to(与...相比) previous single image GAN schemes(方案), our approach is not limited to texture images, and is not conditional (i.e. it generates samples from noise). User studies confirm(证实) that the generated samples are commonly confused to be real images. We illustrate the util ity(实用性) o f SinGAN in a wide range of image manipulation tasks(图像从处理任务).
1. Introduction
Generative Adversarial Nets (GANs) have made a dramatic leap(杰出的进步) in modeling high dimensional distributions(在高维分布的建模中) of visual data. In particular, unconditional GANs have shown remarkable success in generating realistic, high quality samples when trained on class specifific datasets. However, capturing the distribution of highly diverse datasets with multiple object classes(捕获具有多个对象类的高度不同的数据集的分布 ), is still considered a major challenge and often requires conditioning the generation on another input signal or training the model for a specifific task . Here, we take the use of GANs into a new realm(领域) – un conditional generation learned from a single natural image . Specifically, we show that the internal statistics of patches within a single natural image typically carry enough information for learning a powerful generative model. SinGAN , our new single image generative model, allows us to deal with general natural images that contain complex structures and textures, without the need to rely on the existence of a database of images from the same class. This is achieved by a pyramid of fully convolutional light-weight(轻量级) GANs, each is responsible for capturing the distribution of patches at a different scale . Once trained, SinGAN can produce diverse high quality image samples (of arbitrary dimensions(任意维度的)), which semantically(语义上) resemble(相似) the training image, yet(但是) contain new object configurations and structures . Modeling the internal distribution of patches within a single natural image has been long recognized as a powerful(重要的) prior(先验问题) in many computer vision)(视觉) tasks.(在许多计算机视觉任务中,对单个自然图像中patch的内部分布进行建模一直被认为是一个重要的先验问题 ) Classical(经典的) examples include denoising [去噪 ], deblurring [去模糊 ], super resolution [超分辨率 ], dehazing [ 去雾 ], and image editing . The most closley related work in this context is [ 48 ], where a bidirectional patch similarity measure is defifined and optimized to guarantee that the patches of an image after manipulation(操作) are the same as the original ones. (其中定义并优化了一个双向patch相似度度量,以保证处理后的图像的patch与原始图像的patch是相同的)Motivated by these works, here we how SinGAN can be used within a simple unified(统一的) learning framework to solve a variety of image manipulation tasks, including paint-to-image, editing, harmonization(协调), super resolution, and animation(动画) from a single image. In all these cases, our model produces high quality results that preserve the internal patch statistics of the training image . All tasks are achieved with the same generative network, without any additional information or further(进一步) training beyond the original training image.

这主要就是提了下作者是利用一张图片的内部patch训练来实现的,并提出了SinGan的功能包括图像、编辑、协调、超分辨率和动画。详细的在下面介绍
1.1. Related Work
Single image deep modelsSeveral recent works proposed to “overfit” a deep model to a single training example . However, these methods are designed for specifific tasks (e.g ., super resolution , texture expansion(纹理扩展) ). However, their generation is conditioned on an input image (i.e., mapping images to images) and is not used to draw random samples. In contrast, our framework is purely generative (i.e. maps noise to image samples), and thus suits many different image manipulation tasks. Unconditional single image GANs have been explored(探索) only in the context of texture generation . These models do not generate meaningful samples when trained on non-texture images (Fig. 3 ). Our method, on the other hand, is not restricted to texture and can handle general(一般的) natural images (e.g ., Fig. 1 ).

介绍了一下前人工作的不足。又强调了自己是从单一图像生成的。
The power of adversarial learning has been demonstrated by recent GAN-based methods, in many different image manipulation tasks . Examples include interactive(交互式) image editing , sketch2image , and other image-to-image translation tasks . However, all these methods are trained on class specific datasets,and here too, often condition the generation on another input signal. We are not interested in capturing common(共同的) features among images of the same class, but rather con sider a different source of training data – all the overlapping(重叠) patches at multiple scales of a single natural image. We show that a powerful generative model can be learned from this data, and can be used in a number of image manipulation tasks.
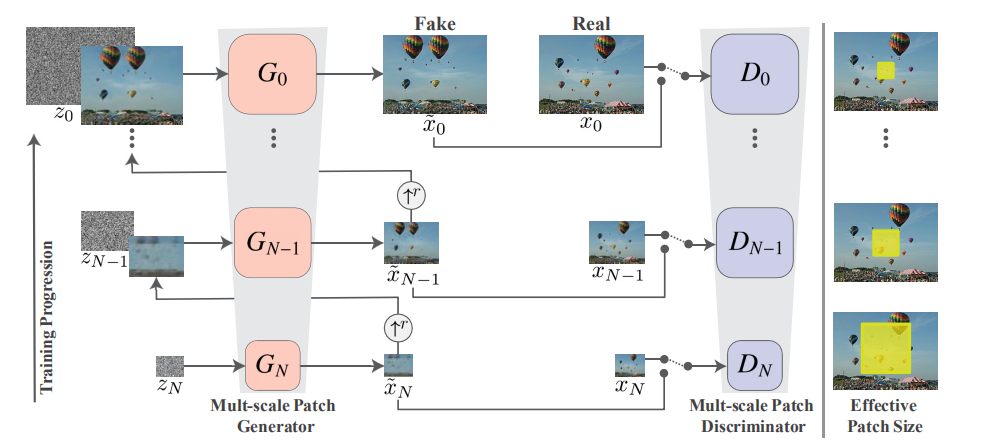

然后网络是3233的全卷积,然后上4个scale,就要变成二倍的,6433.然后用了batchnorm和leaklyrelu。由于生成器是全卷积的,所以可以在测试时生成任意大小和宽高比的图片(通过改变噪声图的尺寸)。然后patch刚开始是1/2左右,越向后就会越小。
2. Method
Our goal is to learn an unconditional generative model that captures the internal statistics of a single training image x . This task is conceptually(概念上) similar to the conventional(传统的) GAN setting, except that here the training samples are patches of a single image, rather than whole image samples from a database . We opt to go beyond texture generation, and to deal with more general natural images. This requires capturing the statistics of complex image structures at many different scales. For example, we want to capture global(全局) properties such as the arrangement(排列) and shape of large objects in the image (e.g . sky at the top, ground at the bottom), as well as fine details and texture information. To achieve that, our generative framework, illustrated in Fig. 4 , consists of a hierarchy(层次) of patch-GANs (Markovian discriminator) , where each is responsible for capturing the patch distribution at a different scale of x . The GANs have small receptive fifields and limited capacity, preventing them from memorizing the single image. While(虽然) similar multi-scale architectures have been explored in conventional GAN settings , we are the first explore it for internal learning from a single image.
2.1. Multi-scale architecture(多尺度结构)
Our model consists of a pyramid of generators, { G 0 , . . . , G N } , trained against an image pyramid of x : { x 0 , . . . , x N } , where x n is a downsampled version of x by a factor r n , for some r > 1 . Each generator G n is responsible of producing realistic image samples w.r.t. the patch distribution in the corresponding image x n. This is achieved through adversarial training(这是通过对抗性训练实现的 ), where Gn learns to fool(愚弄) an associated discriminator(鉴别器) D n , which attempts to distinguish patches in the generated samples from patches in x n. The generation of an image sample starts at the coarsest scale and sequentially(从而) passes through all generators up to the fifinest scale, with noise injected at every scale. All the generators and discriminators have the same receptive field and thus capture structures of decreasing size as we go up the generation process. At the coarsest scale(在最粗糙的尺度上 ), the generation is purely generative, i.e. G N maps(映射) spatial(空间) white Gaussian noise(高斯噪声) z N to an image sample ˜ x N ,
˜xN = GN (zN ). (1)The effective receptive field at this level is typically(通常的) ∼ 1 / 2 of the image’s height, hence G N generates the general layout of the image and the objects’ global structure. Each of the generators G n at finer scales ( n < N ) adds details that were not generated by the previous scales. Thus, in addition to spatial noise z n , each generator G n accepts an upsampled version of the image from the coarser scale, i.e .,˜xn = Gn (zn, (˜xn+1) ↑r), n < N. (2)All the generators have a similar architecture, as depicted in Fig. 5 . Specififically, the noise z n is added to the image (˜x n +1 ) ↑ r , prior to being fed into a sequence of convolutional layers. This ensures that the GAN does not disregard(忽视) the noise, as often happens in conditional schemes involving randomness . The role of the convonlutional layers is to generate the missing details in (˜ x n +1 ) ↑ r (residual learning ). Namely(换句话说), G n performs the operation˜xn = (˜xn+1) ↑r + ψn (zn + (˜xn+1) ↑r), (3)where ψ n is a fully convolutional net with 5 conv-blocks of the form Conv(3 × 3 )-BatchNorm-LeakyReLU .
We start with 32 kernels per block at the coarsest scale and increase this number by a factor of 2 every 4 scales. Because the generators are fully convolutional, we can generate images of arbitrary size(任意大小) and aspect ratio(比例) at test time (by changing the dimensions of the noise maps).
2.2. Training
We train our multi-scale architecture sequentially, from the coarsest scale to the finest one. Once each GAN is trained, it is kept fifixed. Our training loss for the n th GAN is comprised of an adversarial term(部分) and a reconstruction term,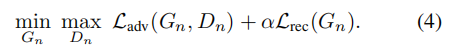

Each of the generators G n is coupled with(与...相耦合) a Markovian discriminator D n that classififies each of the overlapping(重叠) patches of its input as real or fake(真或假) . We use the WGAN-GP loss , which we found to increase training stability, where the final discrimination score is the average over the patch discrimination map. As opposed to single-image GANs for textures , here we defifine the loss over the whole image rather than over random crops (a batch of size 1 ). This allows the net to learn boundary conditions (see SM), which is an important feature in our setting. The architecture of D n is the same as the net ψ n within G n , so that its patch size (the net’s receptive fifield) is 11 × 11 .
We want to ensure that there exists a specific set of input noise maps, which generates the original image x. We specififically choosewhere z ∗ is some fixed noise map (drawn once and kept fixed during training).

We tested our method both qualitatively and quantitatively(定性和定量) on a variety of images spanning(生成) a large range of scenes including urban and nature scenery as well as artistic and texture images. The images that we used are taken from the Berkeley Segmentation Database (BSD) Places and the Web. We always set the minimal dimension at the coarsest scale to 25 px, and choose the number of scales N s.t. the scaling factor r is as close as possible to 4 /3(比例因子r尽可能接近于4/3 ). For all the results, (unless mentioned otherwise(除非另外提到)), we resized the training image to maximal dimension 250 px.Qualitative examples of our generated random image samples are shown in Fig. 1 , Fig. 6 , and many more examples are included in the SM. For each example, we show a number of random samples with the same aspect ratio as the original image, and with decreased and expanded dimensions in each axis(轴). As can be seen, in all these cases, the generated samples depict(描画) new realistic structures and configuration of objects, while preserving(保留) the visual content of the training image. Our model successfully preservers global structure of objects, e.g . mountains (Fig. 1 ), air balloons or pyramids (Fig. 6 ), as well as fine texture information. Because the network has a limited receptive field (smaller than the entire image), it can generate new combinations of patches that do not exist in the training image Furthermore, we observe that in many cases reflections and shadows(反射和阴影) are realistically synthesized(合成的), as can be seen in Fig. 6 and Fig. 1 (and the fifirst example of Fig. 8 ). Note that SinGAN’s architecture is resolution agnostic(不可知的) and can thus be used on high resolution images, as illustrated in Fig. 7 (see 4Mpix results in the SM). Here as well, structures at all scales are nicely generated, from the global arrangement of sky, clouds and mountains, to the fine textures of the snow.


Our multi-scale architecture allows control over the amount of variability between samples, by choosing the scale from which to start the generation at test time. To start at scale n, we fix the noise maps upto this scale to be { z N rec , . . . , z n rec +1 } , and use random draws only for { z n , . . . , z 0 } . The effect is illustrated in Fig. 8 . As can be seen, starting the generation at the coarsest scale (n = N), results in large variability in the global structure. In certain cases with a large salient object, like the Zebra(斑马) image, this may lead to unrealistic samples. However, starting the generation from finer scales, enables to keep the global structure intact(完整), while altering only finer image features (e.g. the Zebra’s stripes). Figure 8: Generation from different scales (at infer ence). We show the effect of starting our hierarchical(分层的) generation from a given level n . For our full generation scheme (n = N ), the input at the coarsest level is random noise. For generation from a finer scale n , we plug in the downsampled original image, x n , as input to that scale. This allows us to control the scale of the generated structures, e.g ., we can preserve the shape and pose(姿态) of the Zebra and only change its stripe(条纹) texture by starting the generation from n = N -1
Figure 8: Generation from different scales (at infer ence). We show the effect of starting our hierarchical(分层的) generation from a given level n . For our full generation scheme (n = N ), the input at the coarsest level is random noise. For generation from a finer scale n , we plug in the downsampled original image, x n , as input to that scale. This allows us to control the scale of the generated structures, e.g ., we can preserve the shape and pose(姿态) of the Zebra and only change its stripe(条纹) texture by starting the generation from n = N -1
Figure 9 shows the effect of training with fewer scales. With a small number of scales, the effective receptive field at the coarsest level is smaller, allowing to capture only fine textures. As the number of scales increases, structures of larger support emerge(出现), and the global object arrangement is better preserved(保留).
Figure 9: The effect of training with a different number of scales. The number of scales in SinGAN’s architecture strongly influences the results. A model with a small number of scales only captures textures. As the number of scales increases, SinGAN manages to capture larger structures as well as the global arrangement of objects in the scene.

3.1. Quantitative Evaluation(定量评价)
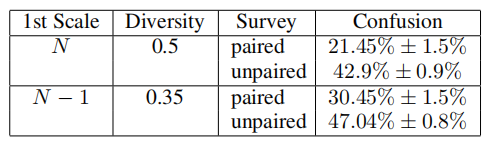
We followed the protocol(协议) of [ 26 , 58 ] and performed perceptual(知觉的) experiments in 2 settings.(i) Paired(配对) (real vs. fake): Workers were presented with a sequence of 50 trials(尝试), in each of which a fake image (generated by SinGAN) was presented against its real training image for 1 second(秒). Workers were asked to pick(挑选) the fake image.(ii) Unpaired (either real or fake): Workers were presented with a single image for 1 second, and were asked if it was fake. In total, 50 real images and a disjoint(不相关的) set of 50 fake images were presented in random order to each worker. We repeated these two protocols for two types of generation processes: Starting the generation from the coarsest (N th) scale, and from scale N - 1 (as in Fig. 8 ). This way, we assess(评估) the realism of our results in two different variability levels. To quantify the diversity of the generated images, for each training example we calculated(计算) the standard deviation (std标准差) of the intensity(强烈) values of each pixel(像素) over 100 generated images, averaged it over all pixels, and normalized(归一化) by the std of the intensity values of the training image. The real images were randomly picked from the “places” database from the subcategories(子分类) Mountains, Hills, Desert(沙漠), Sky. In each of the 4 tests, we had 50 different participants(参与者). In all tests, the first 10 trials were a tutorial(教程) including a feedback. The results are reported in Table 1 . As expected, the confusion rates are consistently(始终) larger in the unpaired case, where there is no reference(参考) for comparison(比较). In addition, it is clear that the confusion rate decreases with the diversity(多样性) of the generated images. However, even when large structures are changed, our generated images were hard to distinguish from the real images (a score of 50% would mean perfect(完美的) confusion between real and fake).
Table 1: “Real/Fake” AMT test. We report confusion rates for two generation processes: Starting from the coarsest scale N (producing samples with large diversity), and starting from the second coarsest scale N- 1 (preserving the global structure of the original image). In each case, we performed both a paired study (real-vs.-fake image pairs are shown), and an unpaired one (either fake or real image is shown). The variance was estimated by bootstrap .
We next quantify how well SinGAN captures the internal statistics of x . A common metric(度量标准 ) for GAN evaluation is the Fr´echet Inception Distance (FID) , which measures the deviation(偏差) between the distribution of deep features of generated images and that of real images. In our setting, however, we only have a single real image, and are rather interested in its internal patch statistics. We thus propose(提出) the Single Image FID (SIFID) metric. Instead of using the activation vector(激活向量) after the last pooling layer(池化层) in the Inception Network (a single vector per image), we use the internal distribution of deep features at the output of the convolutional layer just before the second pooling layer (one vector per location in the map). Our SIFID is the FID between the statistics of those features in the real image and in the generated sample. As can be seen in Table 2 , the average SIFID is lower for generation from scale N-1 than for generation from scale N, which aligns(一致) with the user study results. We also report the correlation between the SIFID scores and the confusion rates for the fake images. Note that there is a significant (anti) correlation between the two, implying that a small SIFID is typically a good indicator for a large confusion rate. The correlation is stronger for the paired tests, since SIFID is a paired measure (it operates on the pair x n , ˜ x n).
Table 2: Single Image FID (SIFID). We adapt the FID metric to a single image and report the average score for 50 images, for full generation (first row), and starting from the second coarsest scale (second row). Correlation with AMT results shows SIFID highly agrees with human ranking.

4. Applications
We explore the use of SinGAN for a number of image manipulation tasks. To do so, we use our model after train ing , with no architectural changes or further tuning and follow the same approach for all applications. The idea is to utilize(利用) the fact that at inference, SinGAN can only produce images with the same patch distribution as the training image. Thus, manipulation can be done by injecting (a possibly downsampled version of) an image into the generation pyramid at some scale n < N , and feed forwarding it through the generators so as to match(相配) its patch distribution to that of the training image. Different injection scales lead to different effects. We consider the following applications (see SM for more results and the injection scale effect).

Figure 10: Super-Resolution. When SinGAN is trained on a low resolution image, we are able to super resolve. This is done by iteratively(迭代的) upsampling the image and feeding it to SinGAN’s finest scale generator. As can be seen, SinGAN’s visual quality is better than the SOTA internal methods ZSSR [46] and DIP [51]. It is also better than EDSR [32] and comparable to SRGAN [30], external methods trained on large collections. Corresponding PSNR and NIQE [40] are shown in parentheses.
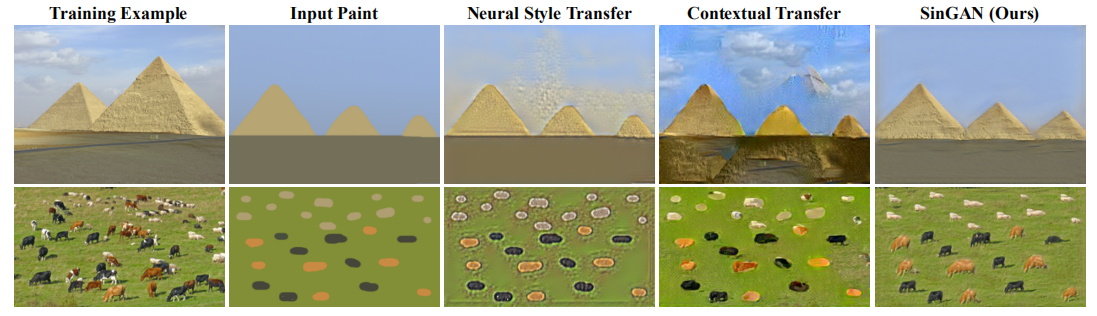
Figure 11: Paint-to-Image. We train SinGAN on a target image and inject a downsampled version of the paint into one of the coarse levels at test time. Our generated images preserve the layout and general structure of the clipart(剪贴艺术) while generating realistic texture and fine details that match the training image. Well-known style transfer methods fail in this task.

Figure 12: Editing. We copy and paste a few patches from the original image (a), and input a downsampled version of the edited image (b) to an intermediate(中间体) level of our model (pretrained on (a)). In the generated image (d), these local edits are translated into coherent(连贯的) and photo-realistic structures. (c) comparison to Photoshop content aware move.

Figure 13: Harmonization(调和). Our model is able to preserve the structure of the pasted object, while adjusting its appearance and texture. The dedicated(专用的) harmonization method overly blends (混合)the object with the background.
5. Conclusion
We introduced SinGAN, a new unconditional generative scheme that is learned from a single natural image. We demonstrated(证实) its ability to go beyond textures and to generate diverse realistic samples for natural complex images. Internal learning is inherently limited(固有的局限性) in terms of semantic diversity(语义多样性) compared to externally trained generation methods. For example, if the training image contains a single dog, our model will not generate samples of different dog breeds(品种). Nevertheless, as demonstrated by our experiments, SinGAN can provide a very powerful tool for a wide range of image manipulation tasks.