2204.VQGAN-CLIP | 论文 | code
基于自然语言导向的开放域图像生成与编辑
摘要
- 从
开放域(open domain)文本提示(text prompts)中生成和编辑图像是一项具有挑战性的任务,迄今为止(heretofore)一直需要昂贵的和经过专门训练的模型。 - 我们演示了一种针对这两种任务的新方法,该方法能够通过使用
多模态编码器(multimodal encoder) 来指导图像生成,在没有任何训练的情况下,从具有显著语义复杂度的文本提示中生成高视觉质量的图像 - 我们在各种任务上演示了如何使用CLIP[37]来指导VQGAN[11]产生比之前更高的视觉质量输出
- 像 minDALL-E[19],Glide[33]和Open-Edit[24]等不太灵活的方法,,尽管没有为所提出的任务进行训练。
2 本文方法
我们从一个文本提示(text prompt)开始,并使用一个GAN迭代地生成候选图像(candidate images),在每一步都使用CLIP来改进图像, 我们通过处理嵌入候选图像(the embedding of the candidate)与嵌入文本提示(the embedding of the text prompt )之间的平方球面距离( squared spherical distance )作为损失函数(as a loss function)来优化图像,通过CLIP对图像的潜在向量表示进行区分(differentiating),我们跟随论文 Neural Discrete Representation Learning) ,称为“z向量”, Neural Discrete Representation Learning 中还提出了矢量量化变分自动编码器 (VQ-VAE):Vector Quantised Variational AutoEncoder )
- 为了生成一个图像,“初始图像”包含随机的像素值( random pixel values)。重复优化过程以改变图像(alter the image),直到输出图像逐渐改进,使其在语义上匹配目标文本(semantically matches the target text ) 。
- 我们还可以通过将编辑图像作为“初始图像”来编辑现有图像
- 用于描述我们希望图像如何更改的文本提示与生成图像的文本提示相同,除了如何选择“初始图像”之外,在生成和操作之间不会对架构进行任何更改。具体过程如下
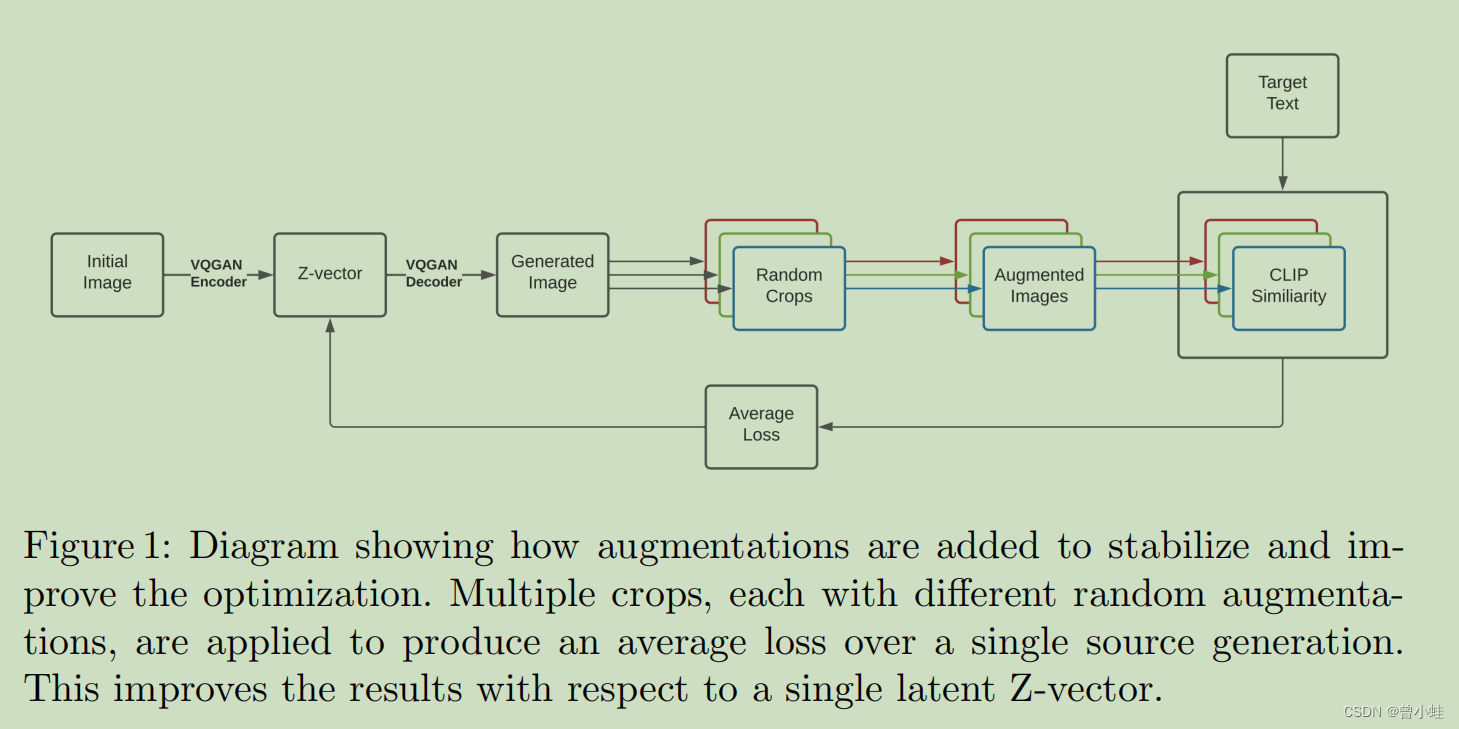
图1 VQGAN-CLIP的结构
我们从一个文本提示符开始,并使用一个GAN迭代地生成候选图像,在每一步都使用CLIP来改进图像
图1,图表展示了如何添加数据增强以稳定和改进优化过程。多重剪切(Multipe crops),每一种都有不同的随机增强(augmentations),以在一个单张生成图片上产生平均损失。这改进了相对于单一潜在z向量的结果。
3 语义图像生成
图2 VQGAN-CLIP的生成例子以及对应的文字提示
提示文字(Prompts)选择展示一系列vqgan-clip能够产生的视觉风格,包括古典艺术(classical art) (g,i),现代艺术(modern art)(l),绘画(drawings)(e),油(oils)(a),和其他由于空间不包括在内。

3.1 艺术风格(Artistic Impressions)
我们发现vqgan-clip能够唤起世界各地著名艺术家的艺术风格和主要的艺术风格。。.图2 (g)是“梵高风格的宇航员”,其背景让人想起星夜和“j·m·w·Turner 的“ (圣经)巴别塔;[电影]通天塔)”,它利用了特纳的调色(color palate)和对光的使用。
另一种方法是直接要求“名画”或“名艺术”,见图3
图3 对著名艺术家的风格印象
-
我们展示了六种以这种方式创作的图像,它们描绘了来自不同地区、不同时期和不同艺术风格的艺术家。虽然这些图像经常缺乏凝聚力(很可能是由于“一幅画”作为一种提示的模糊性),但它们都明显地让人想起了相关的艺术家。
-
谷歌的反向图像搜索等第三方工具表明,本模型生成的相应图片,目标艺术家的真实绘画都是视觉上最相似的图像。(a)梵高,(b)毕加索 (c)葛饰北斋(日本艺术家)(d)Turner (英国浪漫主义画家) (e) Kahlo (f) 抽象油画的多层画——Julie Mehretu

3.2 与其他工作对比
图4 对比不同模型基于文字生成的图片
- 从第一行到最后一行,依次为 minDALL-E, GLIDE(CLIP-guided), GLIDE (CF-guided), and our
vqgan-clip(最下一行)结果 - 每一列的提示文字依次为,(a)艺术化的图书馆 (b) 一幅大教堂的木炭画 © 儿童画的棒球比赛 (d) 用低聚体呈现的森林

4 语义图像编辑
图5 改变颜色

图6 改变天气

图7 混合修改
木质的飞机、枯萎的花朵(Withered flowers)、聚焦模式(Focused)
