CLIP论文翻译、Learning Transferable Visual Models From Natural Language Supervision翻译
文章目录
Abstract
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept.
Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks.
We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification.
The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on.
We release our code and pre-trained model weights at GitHub - openai/CLIP: Contrastive Language-Image Pretraining.
最先进的计算机视觉系统经过训练可以预测一组固定的预定对象类别。 这种受限的监督形式限制了它们的通用性和可用性,因为需要额外的标记数据来指定任何其他视觉概念。
直接从有关图像的原始文本中学习是一种很有前途的替代方案,它可以利用更广泛的监督来源。 我们证明了预测哪个标题与哪个图像对应的简单预训练任务是一种有效且可扩展的方式,可以在从互联网收集的 4 亿(图像、文本)对数据集上从头开始学习 SOTA 图像表示。 预训练后,使用自然语言来引用学习到的视觉概念(或描述新概念),从而实现模型到下游任务的零样本迁移。
我们通过对 30 多个不同的现有计算机视觉数据集进行基准测试来研究这种方法的性能,涵盖 OCR、视频中的动作识别、地理定位和许多类型的细粒度对象分类等任务。
该模型可以轻松地迁移到大多数任务,并且通常可以与完全监督的基线相媲美,而无需任何数据集特定的训练。 例如,我们在 ImageNet 零镜头上匹配原始 ResNet-50 的准确性,而无需使用它所训练的 128 万个训练示例中的任何一个。
我们在 https://github.com/OpenAI/CLIP 上发布了我们的代码和预训练模型权重。
1. Introduction and Motivating Work
Pre-training methods which learn directly from raw text have revolutionized NLP over the last few years (Dai & Le, 2015; Peters et al., 2018; Howard & Ruder, 2018; Radford et al., 2018; Devlin et al., 2018; Raffel et al., 2019).
Task-agnostic objectives such as autoregressive and masked language modeling have scaled across many orders of magnitude in compute, model capacity, and data, steadily improving capabilities. The development of “text-to-text” as a standardized input-output interface (McCann et al., 2018; Radford et al., 2019; Raffel et al., 2019) has enabled task-agnostic architectures to zero-shot transfer to downstream datasets removing the need for specialized output heads or dataset specific customization.
Flagship systems like GPT-3(Brown et al., 2020) are now competitive across many tasks with bespoke models while requiring little to no dataset specific training data.
直接从原始文本中学习的预训练方法在过去几年彻底改变了 NLP.
自回归和屏蔽语言建模等与任务无关的目标已经在计算、模型容量和数据方面扩展了多个数量级,稳步提高了能力。 “文本到文本”作为标准化输入输出接口的发展使任务无关架构能够零样本转移到 下游数据集,并消除了对专门输出头或数据集特定定制的需要。
像 GPT-3这样的旗舰系统现在在使用定制模型的许多任务中具有竞争力,同时几乎不需要数据集特定的训练数据。
These results suggest that the aggregate supervision accessible to modern pre-training methods within web-scale collections of text surpasses that of high-quality crowd-labeled NLP datasets.
However, in other fields such as computer vision it is still standard practice to pre-train models on crowd-labeled datasets such as ImageNet (Deng et al., 2009).
Could scalable pre-training methods which learn directly from web text result in a similar breakthrough in computer vision? Prior work is encouraging.
这些结果表明,现代预训练方法在互联网规模下的文本集合中可获得的总监督超过了高质量人群标记的 NLP 数据集。
然而,在计算机视觉等其他领域,在 ImageNet 等人群标记数据集上预训练模型仍然是标准做法。
直接从网络文本中学习的可扩展预训练方法能否在计算机视觉领域取得类似的突破? 之前的工作令人鼓舞。
Over 20 years ago Mori et al. (1999) explored improving content based image retrieval by training a model to predict the nouns and adjectives in text documents paired with images. Quattoni et al. (2007) demonstrated it was possible to learn more data efficient image representations via manifold learning in the weight space of classifiers trained to predict words in captions associated with images. Sri vastava & Salakhutdinov (2012) explored deep representation learning by training multimodal Deep Boltzmann Machines on top of low-level image and text tag features. Joulin et al. (2016) modernized this line of work and demonstrated that CNNs trained to predict words in image captions learn useful image representations.
They converted the title, description, and hashtag metadata of images in the YFCC100M dataset (Thomee et al., 2016) into a bag-of words multi-label classification task and showed that pre-training AlexNet (Krizhevsky et al., 2012) to predict these labels learned representations which preformed similarly to ImageNet-based pre-training on transfer tasks.
Li et al. (2017) then extended this approach to predicting phrase n-grams in addition to individual words and demonstrated the ability of their system to zero-shot transfer to other image classification datasets by scoring target classes based on their dictionary of learned visual n-grams and predicting the one with the highest score. Adopting more recent architectures and pre-training approaches, VirTex (Desai & Johnson,2020), ICMLM (Bulent Sariyildiz et al., 2020), and ConVIRT (Zhang et al., 2020) have recently demonstrated the potential of transformer-based language modeling, masked language modeling, and contrastive objectives to learn image representations from text.
20 多年前,Mori 通过训练模型来预测与图像配对的文本文档中的名词和形容词,探索改进基于内容的图像检索。Quattoni证明可以通过在分类器的权重空间中进行流形学习来学习更多数据有效的图像表示,这些分类器经过训练可以预测与图像相关的字幕中的单词。 Sri vastava & Salakhutdinov (2012) 通过在低级图像和文本标签特征之上训练多模式深度玻尔兹曼机来探索深度表征学习。 Joulin 等人。 (2016) 对这一工作领域进行了现代化改造,并证明经过训练以预测图像说明中的单词的 CNN 学习了有用的图像表示。
他们将 YFCC100M 数据集(Thomee 等人,2016 年)中图像的标题、描述和主题标签元数据转换为词袋多标签分类任务,并展示了预训练 AlexNet预测这些标签学习的表示,这些表示类似于基于 ImageNet 的传输任务预训练。
Li然后将这种方法扩展到预测短语 n-grams 以及单个单词,并展示了他们的系统通过基于他们学习的视觉 n-grams 和 预测得分最高的那个。 采用更新的架构和预训练方法,VirTex、ICMLM 和 ConVIRT最近展示了基于转换器的语言的潜力 建模、掩码语言建模和对比目标,以从文本中学习图像表示。
While exciting as proofs of concept, using natural language supervision for image representation learning is still rare. This is likely because demonstrated performance on common benchmarks is much lower than alternative approaches.
For example, Li et al. (2017) reach only 11.5% accuracy on ImageNet in a zero-shot setting. This is well below the 88.4% accuracy of the current state of the art (Xie et al.,2020). It is even below the 50% accuracy of classic computer vision approaches (Deng et al., 2012).
Instead, more narrowly scoped but well-targeted uses of weak supervision have improved performance. Mahajan et al. (2018) showed that predicting ImageNet-related hashtags on Instagram images is an effective pre-training task.
When fine-tuned to ImageNet these pre-trained models increased accuracy by over 5% and improved the overall state of the art at the time.
Kolesnikov et al. (2019) and Dosovitskiy et al. (2020) have also demonstrated large gains on a broader set of transfer benchmarks by pre-training models to predict the classes of the noisily labeled JFT-300M dataset.
虽然作为概念证明令人兴奋,但使用自然语言监督进行图像表示学习仍然很少见。这可能是因为在通用基准测试中证明的性能远低于替代方法。
例如,李等人。 (2017) 在零样本设置下在 ImageNet 上的准确率仅为 11.5%。 这远低于当前最先进技术的准确率为 88.4%。 它甚至低于经典计算机视觉方法 50% 的准确率。
相反,范围更窄但目标明确的弱监督使用提高了性能。 Mahajan表明,预测 Instagram 图像上与 ImageNet 相关的主题标签是一项有效的预训练任务。
当针对 ImageNet 进行微调时,这些预训练模型的准确性提高了 5% 以上,并改善了当时的整体技术水平。
Mahajan和 Dosovitskiy 还展示了通过预训练模型在更广泛的迁移基准上取得的巨大收益,以预测带有噪声标记的 JFT-300M 数据集的类别。
This line of work represents the current pragmatic middle ground between learning from a limited amount of supervised “gold-labels” and learning from practically unlimited amounts of raw text.
However, it is not without compromises. Both works carefully design, and in the process limit, their supervision to 1000 and 18291 classes respectively.
Natural language is able to express, and therefore supervise, a much wider set of visual concepts through its generality. Both approaches also use static softmax classifiers to perform prediction and lack a mechanism for dynamic outputs. This severely curtails their flexibility and limits their “zero-shot” capabilities.
这一系列工作代表了当前实用的中间立场,介于从有限数量的受监督“黄金标签”中学习和从几乎无限量的原始文本中学习。
然而,它并非没有妥协。 两者都经过精心设计,并且在过程中将他们的监督分别限制在1000和18291分类。
自然语言能够通过其普遍性表达并因此监督更广泛的视觉概念集。 这两种方法都使用静态 softmax 分类器来执行预测,并且缺乏动态输出机制。 这严重削弱了它们的灵活性并限制了它们的“zero-shot”能力。
A crucial difference between these weakly supervised models and recent explorations of learning image representations directly from natural language is scale. While Mahajan et al. (2018) and Kolesnikov et al. (2019) trained their models for accelerator years on millions to billions of images, VirTex, ICMLM, and ConVIRT trained for accelerator days on one to two hundred thousand images.
In this work, we close this gap and study the behaviors of image classifiers trained with natural language supervision at large scale.
Enabled by the large amounts of publicly available data of this form on the internet, we create a new dataset of 400 million (image, text) pairs and demonstrate that a simplified version of ConVIRT trained from scratch, which we call CLIP, for Contrastive Language-Image Pre-training, is an efficient method of learning from natural language supervision.
We study the scalability of CLIP by training a series of eight models spanning almost 2 orders of magnitude of compute and observe that transfer performance is a smoothly predictable function of compute (Hestness et al., 2017; Kaplan et al.,2020).
We find that CLIP, similar to the GPT family, learns to perform a wide set of tasks during pre-training including OCR, geo-localization, action recognition, and many others.
We measure this by benchmarking the zero-shot transfer performance of CLIP on over 30 existing datasets and find it can be competitive with prior task-specific supervised models. We also confirm these findings with linear-probe representation learning analysis and show that CLIP outperforms the best publicly available ImageNet model while also being more computationally efficient.
We additionally find that zero-shot CLIP models are much more robust than equivalent accuracy supervised ImageNet models which suggests that zero-shot evaluation of task-agnostic models is much more representative of a model’s capability. These results have significant policy and ethical implications, which we consider in Section 7.
这些弱监督模型与最近直接从自然语言学习图像表示的探索之间的一个关键区别是规模。 Mahajan 和 Kolesnikov 在数百万至数十亿张图像上训练他们的模型进行年级别的加速,而VirTex、ICMLM 和 ConVIRT 在 10 到 20 万张图像上进行训练做天级别的加速。
在这项工作中,我们缩小了这一差距并研究了在大规模自然语言监督下训练的图像分类器的行为。
借助互联网上这种形式的大量公开可用数据,我们创建了一个包含 4 亿对(图像、文本)对的新数据集,并展示了从头开始训练的 ConVIRT 的简化版本,我们称之为 CLIP,用于对比语言 -图像预训练,是一种从自然语言监督中学习的有效方法。
我们通过训练跨越近 2 个数量级的计算的一系列八个模型来研究 CLIP 的可扩展性,并观察到传输性能是计算的一个平滑可预测函数(Hestness 等人,2017 年;Kaplan 等人,2020 年)。
我们发现 CLIP 与 GPT 家族类似,在预训练期间学习执行一系列广泛的任务,包括 OCR、地理定位、动作识别等。
我们通过在 30 多个现有数据集上对 CLIP 的零样本传输性能进行基准测试来衡量这一点,并发现它可以与先前的特定任务监督模型竞争。 我们还通过线性探针表示学习分析证实了这些发现,并表明 CLIP 优于公开可用的最佳 ImageNet 模型,同时计算效率更高。
我们还发现零样本 CLIP 模型比同等精度的监督 ImageNet 模型更稳健,这表明任务不可知模型的零样本评估更能代表模型的能力。 这些结果具有重要的政策和伦理意义,我们在第 7 节中对此进行了考虑。
2. Approach
2.1 Natural Language Supervision
At the core of our approach is the idea of learning perception from supervision contained in natural language.
As discussed in the introduction, this is not at all a new idea, however terminology used to describe work in this space is varied, even seemingly contradictory, and stated motivations are diverse. Zhang et al. (2020), Gomez et al. (2017), Joulin et al. (2016), and Desai & Johnson (2020) all introduce methods which learn visual representations from text paired with images but describe their approaches as unsupervised, self-supervised, weakly supervised, and supervised respectively.
我们方法的核心是从自然语言中包含的监督中学习感知的想法。
正如引言中所讨论的,这根本不是一个新想法,但是用于描述该领域工作的术语多种多样,甚至看似矛盾,并且陈述的动机多种多样。 Zhang,Gomez, Joulin 和 Desai & Johnson 都介绍了从与图像配对的文本中学习视觉表示的方法,但分别将它们的方法描述为无监督、自监督、弱监督和监督。
We emphasize that what is common across this line of work is not any of the details of the particular methods used but the appreciation of natural language as a training signal.
All these approaches are learning from natural language supervision. Although early work wrestled with the complexity of natural language when using topic model and n-gram representations, improvements in deep contextual representation learning suggest we now have the tools to effectively leverage this abundant source of supervision (McCann et al.,2017).
我们强调,这项工作的共同点不是所用使用到的特定方法的任何细节,而是得益于将自然语言作为训练信号。
所有这些方法都是从自然语言监督中学习的。 尽管早期的工作在使用主题模型和 n-gram 表示时与自然语言的复杂性作斗争,但深度上下文表示学习的改进表明我们现在拥有有效利用这种丰富的监督资源的工具。
Learning from natural language has several potential strengths over other training methods.
It’s much easier to scale natural language supervision compared to standard crowd-sourced labeling for image classification since it does not require annotations to be in a classic “machine learning compatible format” such as the canonical 1-of-N majority vote “gold label”.
Instead, methods which work on natural language can learn passively from the supervision contained in the vast amount of text on the internet.
Learning from natural language also has an important advantage over most unsupervised or self-supervised learning approaches in that it doesn’t “just” learn a representation but also connects that representation to language which enables flexible zero-shot transfer.
In the following subsections, we detail the specific approach we settled on.
与其他训练方法相比,从自然语言中学习有几个潜在的优势。与用于图像分类的标准众包标签相比,扩展自然语言监督要容易得多,因为它不需要注释采用经典的“机器学习兼容格式”,例如规范的 1-of-N 多数投票“黄金标签” 。
相反,适用于自然语言的方法可以从互联网上大量文本中包含的监督中被动学习。与大多数无监督或自监督学习方法相比,从自然语言中学习也有一个重要的优势,因为它不仅“只是”学习一种表示,而且还将这种表示与语言联系起来,从而实现灵活的zero-shot迁移。在以下小节中,我们详细介绍了我们确定的具体方法。
2.2 Creating a Suffificiently Large Dataset
Existing work has mainly used three datasets, MS-COCO (Lin et al., 2014), Visual Genome (Krishna et al., 2017), and YFCC100M (Thomee et al., 2016). While MS-COCO and Visual Genome are high quality crowd-labeled datasets, they are small by modern standards with approximately 100,000 training photos each.
By comparison, other computer vision systems are trained on up to 3.5 billion Instagram photos(Mahajan et al., 2018). YFCC100M, at 100 million photos,is a possible alternative, but the metadata for each image is sparse and of varying quality.
Many images use automatically generated filenames like 20160716 113957.JPG as “titles” or contain “descriptions” of camera exposure settings.
After filtering to keep only images with natural language titles and/or descriptions in English, the dataset shrunk by a factor of 6 to only 15 million photos. This is approximately the same size as ImageNet.
现有工作主要使用了三个数据集,MS-COCO (Lin et al., 2014)、Visual Genome (Krishna et al., 2017) 和 YFCC100M (Thomee et al., 2016)。 虽然 MS-COCO 和 Visual Genome 是高质量的人群标记数据集,但按照现代标准,它们很小,每个数据集大约有 100,000 张训练照片。
相比之下,其他计算机视觉系统接受了多达 35 亿张 Instagram 照片的训练(Mahajan 等人,2018 年)。 拥有 1 亿张照片的 YFCC100M 是一个可能的替代方案,但每张图像的元数据稀疏且质量参差不齐。
许多图像使用自动生成的文件名,如 20160716 113957.JPG 作为“标题”或包含相机曝光设置的“描述”。
在过滤以仅保留具有自然语言标题和/或英文描述的图像后,数据集缩小了 6 倍,只有 1500 万张照片。 这与 ImageNet 的大小大致相同。
A major motivation for natural language supervision is the large quantities of data of this form available publicly on the internet. Since existing datasets do not adequately reflect this possibility, considering results only on them would underestimate the potential of this line of research.
To address this, we constructed a new dataset of 400 million (image,text) pairs collected form a variety of publicly available sources on the Internet.
To attempt to cover as broad a set of visual concepts as possible, we search for (image, text) pairs as part of the construction process whose text includes one of a set of 500,000 queries.
We approximately class balance the results by including up to 20,000 (image, text) pairs per query. The resulting dataset has a similar total word count as the WebText dataset used to train GPT-2. We refer to this dataset as WIT for WebImageText.
自然语言监督的一个主要动机是互联网上公开提供的大量这种形式的数据。由于现有数据集没有充分反映这种可能性,仅考虑它们的结果会低估这一研究领域的潜力。
为了解决这个问题,我们构建了一个包含 4 亿对(图像、文本)对的新数据集,这些数据集是从 Internet 上的各种公开来源收集而来的。
为了尝试涵盖尽可能广泛的一组视觉概念,我们搜索(图像,文本)对作为构建过程的一部分,其文本包含一组 500,000 个查询中的一个。
我们通过在每个查询中包含多达 20,000 个(图像、文本)对来大致平衡结果。 生成的数据集的总字数与用于训练 GPT-2 的 WebText 数据集相似。 我们将此数据集称为 WebImageText 的 WIT。
2.3 Selecting an Effificient Pre-Training Method
State-of-the-art computer vision systems use very large amounts of compute. Mahajan et al. (2018) required 19 GPU years to train their ResNeXt101-32x48d and Xie et al.(2020) required 33 TPUv3 core-years to train their Noisy Student EfficientNet-L2.
When considering that both these systems were trained to predict only 1000 ImageNet classes, the task of learning an open set of visual concepts from natural language seems daunting.
In the course of our efforts, we found training efficiency was key to successfully scaling natural language supervision and we selected our final pre-training method based on this metric.
最先进的计算机视觉系统使用非常大量的计算。 Mahajan 需要 19 个 GPU 年来训练他们的 ResNeXt101-32x48d,Xie 需要 33 个 TPUv3 核心年来训练他们的 Noisy Student EfficientNet-L2。
考虑到这两个系统都经过训练只能预测 1000 个 ImageNet 类,从自然语言中学习一组开放的视觉概念的任务似乎令人生畏。
在我们努力的过程中,我们发现训练效率是成功扩展自然语言监督的关键,我们根据这个指标选择了最终的预训练方法。
Our initial approach, similar to VirTex, jointly trained an image CNN and text transformer from scratch to predict the caption of an image. However, we encountered difficulties efficiently scaling this method.
In Figure 2 we show that a 63 million parameter transformer language model, which already uses twice the compute of its ResNet-50 image encoder, learns to recognize ImageNet classes three times slower than a much simpler baseline that predicts a bag-of-words encoding of the same text.
我们最初的方法类似于 VirTex,从头开始联合训练图像 CNN 和文本转换器来预测图像的标题。然而,我们在有效扩展这种方法时遇到了困难。
在图 2 中,我们展示了一个 6300 万参数的变换器语言模型,它已经使用了其 ResNet-50 图像编码器两倍的计算,但在相同的文本上识别 ImageNet 类比预测词袋编码的更简单的基线慢三倍。
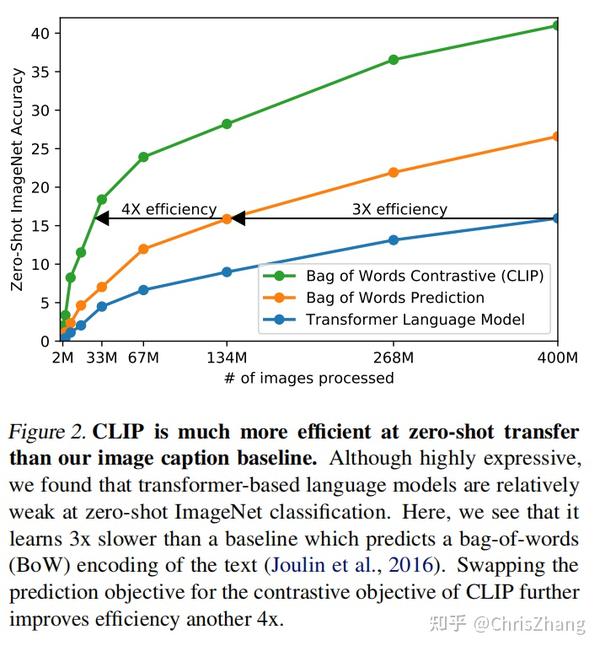
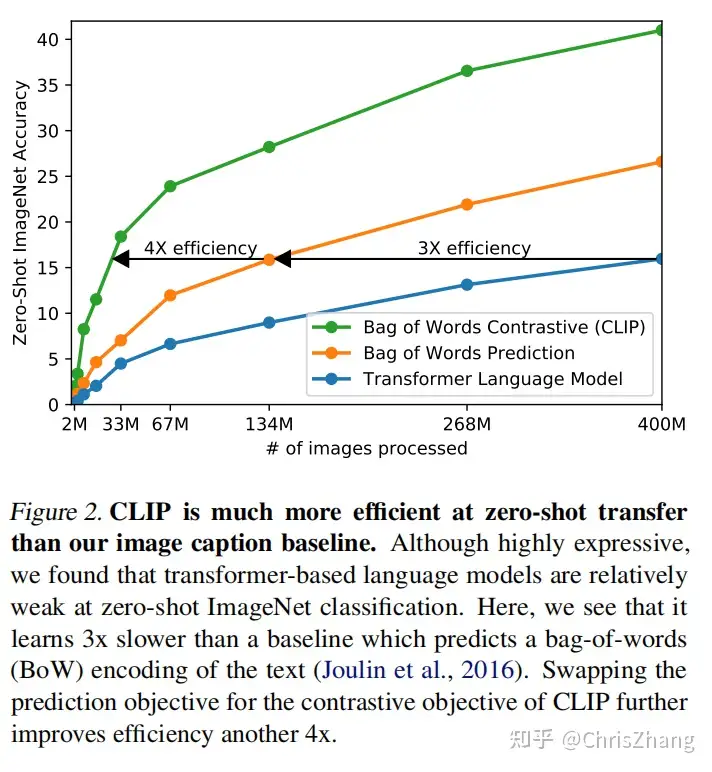
Both these approaches share a key similarity. They try to predict the exact words of the text accompanying each image.
This is a difficult task due to the wide variety of descriptions, comments, and related text that co-occur with images. Recent work in contrastive representation learning for images has found that contrastive objectives can learn better representations than their equivalent predictive objective (Tian et al., 2019).
Other work has found that although generative models of images can learn high quality image representations, they require over an order of magnitude more compute than contrastive models with the same performance (Chen et al., 2020a).
Noting these findings, we explored training a system to solve the potentially easier proxy task of predicting only which text as a whole is paired with which image and not the exact words of that text.
Starting with the same bag-of-words encoding baseline, we swapped the predictive objective for a contrastive objective in Figure 2 and observed a further 4x efficiency improvement in the rate of zero-shot transfer to ImageNet.
这两种方法有一个关键的相似之处。 他们试图预测每张图片所附文字的确切单词。
由于与图像同时出现的描述、评论和相关文本种类繁多,因此这是一项艰巨的任务。 最近在图像对比表示学习方面的工作发现,对比目标可以比它们的等效预测目标学习更好的表示。
其他工作发现,虽然图像的生成模型可以学习高质量的图像表示,但它们需要比具有相同性能的对比模型多一个数量级的计算量。
注意到这些发现,我们探索了训练一个系统来解决可能更容易的代理任务,即仅预测整个文本与哪个图像配对,而不是预测该文本的确切单词。
从相同的词袋编码基线开始,我们将预测目标换成图 2 中的对比目标,并观察到速率进一步提高了 4 倍到 ImageNet 的零样本传输。
Given a batch of N (image, text) pairs, CLIP is trained to predict which of the N × N possible (image, text) pairings across a batch actually occurred. To do this, CLIP learns a multi-modal embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of the N real pairs in the batch while minimizing the cosine similarity of the embeddings of the N2 − N incorrect pairings.
We optimize a symmetric cross entropy loss over these similarity scores.
In Figure 3 we include pseudocode of the core of an implementation of CLIP.
To our knowledge this batch construction technique and objective was first introduced in the area of deep metric learning as the multi-class N-pair loss Sohn (2016), was popularized for contrastive representation learning by Oord et al. (2018) as the InfoNCE loss, and was recently adapted for contrastive (text, image) representation learning in the domain of medical imaging by Zhang et al. (2020).
给定一批 N(图像,文本)对,CLIP 被训练来预测批次中 N × N 可能(图像,文本)对中的哪一个实际发生。 为此,CLIP 通过联合训练图像编码器和文本编码器来学习多模态嵌入空间,以最大化批次中 N 个实数对的图像和文本嵌入的余弦相似度,同时最小化 N2 - N 个不正确的配对。
我们优化了这些相似性分数的对称交叉熵损失。
在图 3 中,我们包含了 CLIP 实现的核心伪代码。
据我们所知,这种批量构建技术和目标首先作为多类 N 对损失 Sohn (2016) 在深度度量学习领域引入,并被 Oord 推广用于对比表示学习。 作为 InfoNCE 损失,最近被 Zhang 等人改编为医学成像领域的对比(文本、图像)表示学习。


Due to the large size of our pre-training dataset, over-fitting is not a major concern and the details of training CLIP are simplified compared to the implementation of Zhang et al.
(2020). We train CLIP from scratch without initializing the image encoder with ImageNet weights or the text encoder with pre-trained weights. We do not use the non-linear projection between the representation and the contrastive embedding space, a change which was introduced by Bachman et al. (2019) and popularized by Chen et al. (2020b).
We instead use only a linear projection to map from each encoder’s representation to the multi-modal embedding space.
We did not notice a difference in training efficiency between the two versions and speculate that non-linear projections may be co-adapted with details of current image only in self-supervised representation learning methods.
We also remove the text transformation function tu t_v . A random square crop from resized images is the only data augmentation used during training. Finally, the temperature parameter which controls the range of the logits in the softmax, τ , is directly optimized during training as a log-parameterized multiplicative scalar to avoid turning as a hyper-parameter.
由于我们的预训练数据集很大,过拟合不是主要问题,与 Zhang 等人的实施相比,训练 CLIP 的细节得到了简化。
我们从头开始训练 CLIP,而没有使用 ImageNet 权重初始化图像编码器或使用预训练权重的文本编码器。 我们不使用表示和对比嵌入空间之间的非线性投影,这是 Bachman 等人引入的变化。 并由 Chen 等人推广。
相反,我们仅使用线性投影将每个编码器的表示映射到多模态嵌入空间。
我们没有注意到两个版本之间训练效率的差异,并推测非线性投影可能仅在自监督表示学习方法中与当前图像的细节共同适应。
我们还删除了 Zhang 等人的文本转换函数
tut_u 。 从文本中统一采样单个句子,因为 CLIP 的预训练数据集中的许多(图像,文本)对只是一个句子。
我们还简化了图像变换函数 tvt_v 。 来自调整大小的图像的随机正方形裁剪是训练期间使用的唯一数据增强。 最后,控制 softmax 中 logits 范围的温度参数 τ 在训练期间直接优化为对数参数化乘法标量,以避免转为超参数。
2.4 Choosing and Scaling a Model
We consider two different architectures for the image encoder.
For the first, we use ResNet-50 (He et al., 2016a)as the base architecture for the image encoder due to its widespread adoption and proven performance.
We make several modifications to the original version using the ResNetD improvements from He et al. (2019) and the antialiased rect-2 blur pooling from Zhang (2019). We also replace the global average pooling layer with an attention pooling mechanism.
The attention pooling is implemented as a single layer of “transformer-style” multi-head QKV attention where the query is conditioned on the global average-pooled representation of the image. For the second architecture, we experiment with the recently introduced Vision Transformer (ViT) (Dosovitskiy et al., 2020).
We closely follow their implementation with only the minor modification of adding an additional layer normalization to the combined patch and position embeddings before the transformer and use a slightly different initialization scheme.
我们考虑图像编码器的两种不同架构。
首先,我们使用 ResNet-50 (He et al., 2016a) 作为图像编码器的基础架构,因为它被广泛采用并且经过验证有良好的性能。
我们使用 He 等人的 ResNetD 改进对原始版本进行了一些改进,同时采用了 Zhang 的抗锯齿 rect-2 模糊池。 我们还用注意力池机制替换了全局平均池层。
注意力池被实现为单层“transformer形式”的多头 QKV 注意力,其中查询以图像的全局平均池表示为条件。 对于第二种架构,我们试验了最近推出的 Vision Transformer (ViT)。
我们密切关注它们的实现,仅对变换器之前的组合补丁和位置嵌入添加额外的层归一化并使用略有不同的初始化方案进行了微小的修改。
The text encoder is a Transformer (Vaswani et al., 2017) with the architecture modifications described in Radford et al. (2019).
As a base size we use a 63M-parameter 12-layer 512-wide model with 8 attention heads. The transformer operates on a lower-cased byte pair encoding (BPE) representation of the text with a 49,152 vocab size (Sennrich et al., 2015). For computational efficiency, the max sequence length was capped at 76.
The text sequence is bracketed with [SOS] and [EOS] tokens and the activations of the highest layer of the transformer at the [EOS] token are treated as the feature representation of the text which is layer normalized and then linearly projected into the multi-modal embedding space.
Masked self-attention was used in the text encoder to preserve the ability to initialize with a pre-trained language model or add language modeling as an auxiliary objective, though exploration of this is left as future work.
文本编码器是一个 Transformer,具有 Radford 等人中描述的架构修改。
作为基础尺寸,我们使用具有 8 个注意力头的 63M 参数 12 层 512 宽模型。 转换器对具有 49,152 个词汇大小的文本的小写字节对编码 (BPE) 表示进行操作。 为了计算效率,最大序列长度上限为 76。
文本序列用 [SOS] 和 [EOS] 标记括起来,转换器最高层在 [EOS] 标记处的激活被视为文本的特征表示,该文本被层归一化,然后线性投影到多 -模态嵌入空间。
Masked self-attention 在文本编码器中使用,以保留使用预训练语言模型进行初始化或添加语言建模作为辅助目标的能力,尽管对此的探索留待未来的工作。
While previous computer vision research has often scaled models by increasing the width (Mahajan et al., 2018) or depth (He et al., 2016a) in isolation, for the ResNet image encoders we adapt the approach of Tan & Le (2019) which found that allocating additional compute across all of widthdepth, and resolution outperforms only allocating it to only one dimension of the model. While Tan & Le (2019) tune the ratio of compute allocated to each dimension for their EfficientNet architecture, we use a simple baseline of allocating additional compute equally to increasing the width, depth, and resolution of the model.
For the text encoder, we only scale the width of the model to be proportional to the calculated increase in width of the ResNet and do not scale the depth at all, as we found CLIP’s performance to be less sensitive to the capacity of the text encoder.
虽然之前的计算机视觉研究通常通过单独增加宽度或深度来缩放模型,但对于 ResNet 图像编码器,我们采用了 Tan & Le(2019)的方法,该方法发现 在所有宽度、深度和分辨率上分配额外的计算优于仅将其分配给模型的一个维度。 虽然 Tan & Le (2019) 调整了为其 EfficientNet 架构分配给每个维度的计算比率,但我们使用了一个简单的基线,即平均分配额外的计算以增加模型的宽度、深度和分辨率。
对于文本编码器,我们只缩放模型的宽度,使其与计算出的 ResNet 宽度增加成正比,根本不缩放深度,因为我们发现 CLIP 的性能对文本编码器的容量不太敏感 .
2.5 Training
We train a series of 5 ResNets and 3 Vision Transformers.
For the ResNets we train a ResNet-50, a ResNet-101, and then 3 more which follow EfficientNet-style model scaling and use approximately 4x, 16x, and 64x the compute of a ResNet-50. They are denoted as RN50x4, RN50x16, and RN50x64 respectively. For the Vision Transformers we train a ViT-B/32, a ViT-B/16, and a ViT-L/14.
We train all models for 32 epochs. We use the Adam optimizer (Kingma& Ba, 2014) with decoupled weight decay regularization(Loshchilov & Hutter, 2017) applied to all weights that are not gains or biases, and decay the learning rate using a cosine schedule (Loshchilov & Hutter, 2016).
Initial hyper-parameters were set using a combination of grid searches, random search, and manual tuning on the baseline ResNet-50 model when trained for 1 epoch. Hyper-parameters were then adapted heuristically for larger models due to computational constraints.
The learnable temperature parameter τ was initialized to the equivalent of 0.07 from (Wu et al.,2018) and clipped to prevent scaling the logits by more than 100 which we found necessary to prevent training instability.
We use a very large minibatch size of 32,768. Mixed-precision (Micikevicius et al., 2017) was used to accelerate training and save memory. To save additional memory, gradient checkpointing (Griewank & Walther, 2000; Chen et al., 2016), half-precision Adam statistics (Dhariwal et al., 2020), and half-precision stochastically rounded text encoder weights were used.
The calculation of embedding similarities was also sharded with individual GPUs computing only the subset of the pairwise similarities necessary for their local batch of embeddings.
The largest ResNet model, RN50x64, took 18 days to train on 592 V100 GPUs while the largest Vision Transformer took 12 days on 256 V100 GPUs.
For the ViT-L/14 we also pre-train at a higher 336 pixel resolution for one additional epoch to boost performance similar to FixRes (Touvron et al., 2019).
We denote this model as ViT-L/14@336px. Unless otherwise specified, all results reported in this paper as “CLIP” use this model which we found to perform best.
我们训练了一系列的 5 个 ResNets 和 3 个 Vision Transformer。
对于 ResNet,我们训练了一个 ResNet-50、一个 ResNet-101,然后是另外 3 个,它们遵循 EfficientNet 风格的模型缩放,并使用大约 4 倍、16 倍和 64 倍的 ResNet-50 计算。 它们分别表示为 RN50x4、RN50x16 和 RN50x64。对于 Vision Transformers,我们训练了一个 ViT-B/32、一个 ViT-B/16 和一个 ViT-L/14。
我们训练所有模型 32 个epoch。 我们使用 Adam 优化器将解耦权重衰减正则化应用于所有不是增益或偏差的权重,并使用余弦计划衰减学习率 (Loshchilov & Hutter, 2016) .
当训练 1 个epoch时,初始超参数是使用网格搜索、随机搜索和手动调整的组合在基线 ResNet-50 模型上设置的。 由于计算限制,超参数然后启发式地适应更大的模型。
可学习的温度参数 τ 从初始化为相当于 0.07 并被剪裁以防止将 logits 缩放超过 100,我们发现这是防止训练不稳定所必需的。
我们使用 32,768 的非常大的minibatch。 混合精度用于加速训练和节省内存。 为了节省额外的内存,使用了梯度检查点 、半精度 Adam 统计和半精度随机舍入文本编码器权重。
嵌入相似度的计算也与单个 GPU 进行了分片,仅计算其本地批量嵌入所需的成对相似度的子集。
最大的 ResNet 模型 RN50x64 在 592 个 V100 GPU 上训练了 18 天,而最大的 Vision Transformer 在 256 个 V100 GPU 上训练了 12 天。
对于 ViT-L/14,我们还以更高的 336 像素分辨率对一个额外的 epoch 进行了预训练,以提高类似于 FixRes 的性能。
我们将此模型表示为 ViT-L/14@336px。 除非另有说明,否则本文中报告为“CLIP”的所有结果均使用我们发现性能最佳的模型。
3. Experiments
3.1 Zero-Shot Transfer
3.1.1. MOTIVATION
In computer vision, zero-shot learning usually refers to the study of generalizing to unseen object categories in image classification (Lampert et al., 2009). We instead use the term in a broader sense and study generalization to unseen datasets.
We motivate this as a proxy for performing unseen tasks, as aspired to in the zero-data learning paper of Larochelle et al. (2008).
While much research in the field of unsupervised learning focuses on the representation learning capabilities of machine learning systems, we motivate studying zero-shot transfer as a way of measuring the tasklearning capabilities of machine learning systems.
In this view, a dataset evaluates performance on a task on a specific distribution.
However, many popular computer vision datasets were created by the research community primarily as benchmarks to guide the development of generic image classification methods rather than measuring performance on a specific task.
While it is reasonable to say that the SVHN dataset measures the task of street number transcription on the distribution of Google Street View photos, it is unclear what “real” task the CIFAR-10 dataset measures.
It is clear, however, what distribution CIFAR-10 is drawn from - TinyImages (Torralba et al., 2008).
On these kinds of datasets, zero-shot transfer is more an evaluation of CLIP’s robustness to distribution shift and domain generalization rather than task generalization.
Please see Section 3.3 for analysis focused on this.
在计算机视觉中,零样本学习通常是指在图像分类中泛化到不可见对象类别的研究。相反,我们在更广泛的意义上使用该术语,并研究对未见数据集的泛化。
正如 Larochelle 等人的零数据学习论文所期望的那样,我们将其作为执行看不见的任务的代理来激励。
虽然无监督学习领域的许多研究都集中在机器学习系统的表示学习能力上,但我们鼓励研究零样本迁移作为衡量机器学习系统任务学习能力的一种方式。
在此视图中,数据集评估特定分布上任务的性能。
然而,许多流行的计算机视觉数据集是由研究社区创建的,主要作为指导通用图像分类方法开发的基准,而不是测量特定任务的性能。
虽然可以合理地说 SVHN 数据集测量了街道号码转录对谷歌街景照片分布的任务,但尚不清楚 CIFAR-10 数据集测量的是什么“真实”任务。
然而,很明显,CIFAR-10 是从什么分布中提取的——TinyImages(Torralba 等人,2008 年)。
在这些类型的数据集上,零样本迁移更多的是评估 CLIP 对分布转移和领域泛化的鲁棒性,而不是任务泛化。
请参阅第 3.3 节以了解针对此的分析。
To our knowledge, Visual N-Grams (Li et al., 2017) first studied zero-shot transfer to existing image classification datasets in the manner described above.
It is also the only other work we are aware of that has studied zero-shot transfer to standard image classification datasets using a generically pre-trained model and serves as the best reference point for contextualizing CLIP.
Their approach learns the parameters of a dictionary of 142,806 visual n-grams (spanning 1- to 5- grams) and optimizes these n-grams using a differential version of Jelinek-Mercer smoothing to maximize the probability of all text n-grams for a given image.
In order to perform zero-shot transfer, they first convert the text of each of the dataset’s class names into its n-gram representation and then compute its probability according to their model, predicting the one with the highest score.
据我们所知,Visual N-Grams 首先以上述方式研究了对现有图像分类数据集的零样本迁移。
这也是我们所知道的唯一一项使用通用预训练模型研究零镜头迁移到标准图像分类数据集的工作,并作为上下文化 CLIP 的最佳参考点。
他们的方法学习了包含 142,806 个视觉 n-gram(跨越 1-5-gram)的字典的参数,并使用差分版本的 Jelinek-Mercer 平滑优化这些 n-gram,以最大化所有文本 n-gram 的概率 给定的图像。
为了执行零样本迁移,他们首先将每个数据集类名的文本转换为其 n-gram 表示,然后根据他们的模型计算其概率,预测得分最高的那个。
Our focus on studying zero-shot transfer as an evaluation of task learning is inspired by work demonstrating task learning in the field of NLP.
To our knowledge Liu et al. (2018) first identified task learning as an “unexpected side-effect” when a language model trained to generate Wikipedia articles learned to reliably transliterate names between languages.
While GPT-1 (Radford et al., 2018) focused on pre-training as a transfer learning method to improve supervised fine-tuning, it also included an ablation study demonstrating that the performance of four heuristic zero-shot transfer methods improved steadily over the course of pre-training, without any supervised adaption.
This analysis served as the basis for GPT-2 (Radford et al., 2019) which focused exclusively on studying the task-learning capabilities of language models via zero-shot transfer.
我们专注于研究零样本迁移作为任务学习的评估,其灵感来自于 NLP 领域中展示任务学习的工作。
据我们所知,Liu首先将任务学习确定为一种“意想不到的附带结果”,当时经过训练以生成维基百科文章的语言模型学会了在语言之间可靠地音译名称。
虽然 GPT-1专注于将预训练作为一种改进监督微调的迁移学习方法,但它还包括一项消融研究,证明四种启发式零样本迁移方法的性能稳步提高 预训练过程,没有任何监督适应。
该分析是 GPT-2的基础,它专注于通过零样本迁移研究语言模型的任务学习能力。
3.1.2. USING CLIP FOR ZERO-SHOT TRANSFER
CLIP is pre-trained to predict if an image and a text snippet are paired together in its dataset. To perform zero-shot classification, we reuse this capability.
For each dataset, we use the names of all the classes in the dataset as the set of potential text pairings and predict the most probable (image, text) pair according to CLIP. In a bit more detail, we first compute the feature embedding of the image and the feature embedding of the set of possible texts by their respective encoders. The cosine similarity of these embeddings is then calculated, scaled by a temperature parameter τ , and normalized into aprobability distribution via a softmax.
Note that this prediction layer is a multinomial logistic regression classifier with L2-normalized inputs, L2-normalized weights, no bias, and temperature scaling. When interpreted this way, the image encoder is the computer vision backbone which computes a feature representation for the image and the text encoder is a hypernetwork (Ha et al., 2016) which generates the weights of a linear classifier based on the text specifying the visual concepts that the classes represent.
Lei Ba et al. (2015) first introduced a zero-shot image classifier of this form while the idea of generating a classifier from natural language dates back to at least Elhoseiny et al. (2013). Continuing with this interpretation, every step of CLIP pre-training can be viewed as optimizing the performance of a randomly created proxy to a computer vision dataset which contains 1 example per class and has 32,768 total classes defined via natural language descriptions.
For zero-shot evaluation, we cache the zero-shot classifier once it has been computed by the text encoder and reuse it for all subsequent predictions.
This allows the cost of generating it to be amortized across all the predictions in a dataset.
CLIP 经过预训练,可以预测图像和文本片段是否在其数据集中配对在一起。 为了执行零样本分类,我们重用了此功能。
对于每个数据集,我们使用数据集中所有类的名称作为潜在文本对的集合,并根据 CLIP 预测最可能的(图像,文本)对。 更详细一点,我们首先通过各自的编码器计算图像的特征嵌入和一组可能文本的特征嵌入。然后计算这些嵌入的余弦相似度,通过温度参数 τ 缩放,并通过 softmax 归一化为概率分布。
请注意,此预测层是一个多项逻辑回归分类器,具有 L2 归一化输入、L2 归一化权重、无偏差和温度缩放。 以这种方式解释时,图像编码器是计算图像特征表示的计算机视觉主干,而文本编码器是超网络,它根据指定文本生成线性分类器的权重。
Lei Ba 首先引入了这种形式的零样本图像分类器,而从自然语言生成分类器的想法至少可以追溯到 Elhoseiny 等人。 (2013)。 继续这种解释,CLIP 预训练的每一步都可以看作是优化随机创建的计算机视觉数据集代理的性能,其中每个类包含 1 个示例,并且通过自然语言描述定义了总共 32,768 个类。
对于零样本评估,一旦文本编码器计算出零样本分类器,我们就会将其缓存起来,并将其重新用于所有后续预测。
这使得生成它的成本可以分摊到数据集中的所有预测中。
3.1.3. INITIAL COMPARISON TO VISUAL N-GRAMS
In Table 1 we compare Visual N-Grams to CLIP. The best CLIP model improves accuracy on ImageNet from a proof of concept 11.5% to 76.2% and matches the performance of the original ResNet-50 despite using none of the 1.28 million crowd-labeled training examples available for this dataset.
Additionally, the top-5 accuracy of CLIP models are noticeably higher than their top-1, and this model has a 95% top-5 accuracy, matching Inception-V4 (Szegedy et al., 2016).
The ability to match the performance of a strong, fully supervised baselines in a zero-shot setting suggests CLIP is a significant step towards flexible and practical
zero-shot computer vision classifiers.
As mentioned above, the comparison to Visual N-Grams is meant for contextualizing the performance of CLIP and should not be interpreted as a direct methods comparison between CLIP and
Visual N-Grams as many performance relevant differences between the two systems were not controlled for.
For instance, we train on a dataset that is 10x larger, use a vision model that requires nearly 100x more compute per prediction, likely used over 1000x their training compute, and use a transformer-based model which did not exist when Visual N-Grams was published.
As a closer comparison, we trained a CLIP ResNet-50 on the same YFCC100M dataset that Visual N-Grams was trained on and found it matched their reported ImageNet performance within a V100 GPU day.
This baseline was also trained from scratch instead of being initialized from pre-trained ImageNet weights as in Visual N-Grams.
在表 1 中,我们将 Visual N-Grams 与 CLIP 进行了比较。 最好的 CLIP 模型将 ImageNet 上的准确性从概念证明的 11.5% 提高到 76.2%,并且与原始 ResNet-50 的性能相匹配,尽管没有使用该数据集可用的 128 万个人群标记训练示例。
此外,CLIP 模型的 top-5 精度明显高于其 top-1,并且该模型具有 95% 的 top-5 精度,与 Inception-V4 相匹配(Szegedy 等人,2016 年)。
在零样本设置中匹配强大的、完全监督的基线性能的能力表明 CLIP 是朝着灵活和实用迈出的重要一步
零样本计算机视觉分类器。
如上所述,与 Visual N-Grams 的比较是为了将 CLIP 的性能置于上下文中,不应解释为 CLIP 和Visual N-Grams 没有控制两个系统之间许多与性能相关的差异。
例如,我们在 10 倍大的数据集上进行训练,使用每次预测需要近 100 倍计算的视觉模型,可能使用超过 1000 倍的训练计算,并使用基于转换器的模型,这在 Visual N-Grams 时并不存在 发表了。
作为更仔细的比较,我们在训练 Visual N-Grams 的同一 YFCC100M 数据集上训练了 CLIP ResNet-50,发现它在 V100 GPU 日内与他们报告的 ImageNet 性能相匹配。
这个基线也是从头开始训练的,而不是像在 Visual N-Grams 中那样从预训练的 ImageNet 权重中初始化。
CLIP also outperforms Visual N-Grams on the other 2 reported datasets. On aYahoo, CLIP achieves a 95% reduction in the number of errors, and on SUN, CLIP more than doubles the accuracy of Visual N-Grams.
To conduct a more comprehensive analysis and stress test, we implement a much larger evaluation suite detailed in Appendix A.
In total we expand from the 3 datasets reported in Visual N-Grams to include over 30 datasets and compare to over 50 existing computer vision systems to contextualize results.
CLIP 在其他 2 个报告的数据集上也优于 Visual N-Grams。 在 aYahoo 上,CLIP 实现了 95% 的错误数量减少,而在 SUN 上,CLIP 的准确性是 Visual N-Grams 的两倍以上。
为了进行更全面的分析和压力测试,我们实施了一个更大的评估套件,详见附录 A。
总的来说,我们从 Visual N-Grams 中报告的 3 个数据集扩展到包括 30 多个数据集,并与 50 多个现有的计算机视觉系统进行比较以将结果上下文化。
3.1.4. PROMPT ENGINEERING AND ENSEMBLING
Most standard image classification datasets treat the information naming or describing classes which enables natural language based zero-shot transfer as an afterthought.
The vast majority of datasets annotate images with just a numeric id of the label and contain a file mapping these ids back to their names in English.
Some datasets, such as Flowers102 and GTSRB, don’t appear to include this mapping at all in their released versions preventing zero-shot transfer entirely.
For many datasets, we observed these labels may be chosen somewhat haphazardly and do not anticipate issues related to zero-shot transfer which relies on task description in order to transfer successfully.
大多数标准图像分类数据集将信息命名或描述类视为事后才想到的,这使得基于自然语言的零样本传输成为可能。
绝大多数数据集仅使用标签的数字 id 来注释图像,并包含一个将这些 id 映射回它们的英文名称的文件。
一些数据集,例如 Flowers102 和 GTSRB,在其发布的版本中似乎根本不包含此映射,从而完全防止零样本传输。
对于许多数据集,我们观察到这些标签的选择可能有些随意,并且没有预料到与依赖于任务描述才能成功传输的零样本传输相关的问题。
A common issue is polysemy. When the name of a class is the only information provided to CLIP’s text encoder it is unable to differentiate which word sense is meant due to the lack of context. In some cases multiple meanings of the same word might be included as different classes in the same dataset! This happens in ImageNet which contains both construction cranes and cranes that fly.
Another example is found in classes of the Oxford-IIIT Pet dataset where the word boxer is, from context, clearly referring to a breed of dog, but to a text encoder lacking context could just as likely refer to a type of athlete.
一个常见的问题是多义词。 当一个类的名称是提供给 CLIP 文本编码器的唯一信息时,由于缺乏上下文,它无法区分哪个词义。 在某些情况下,同一个词的多种含义可能作为不同的类别包含在同一个数据集中! 这发生在 ImageNet 中,它包含建筑起重机和会飞的起重机。
另一个例子是在 Oxford-IIIT Pet 数据集的类中发现的,其中单词 boxer 从上下文中显然指的是一种狗,但缺乏上下文的文本编码器很可能指的是一种运动员。
Another issue we encountered is that it’s relatively rare in our pre-training dataset for the text paired with the image to be just a single word. Usually the text is a full sentence describing the image in some way.
To help bridge this distribution gap, we found that using the prompt template “A photo of a {label}.” to be a good default that helps specify the text is about the content of the image.
This often improves performance over the baseline of using only the label text. For instance, just using this prompt improves accuracy on ImageNet by 1.3%.
我们遇到的另一个问题是,在我们的预训练数据集中,与图像配对的文本只是一个单词的情况相对很少。 通常文本是以某种方式描述图像的完整句子。为了帮助弥合这种分布差距,我们发现使用提示模板“{label} 的照片”。 是一个很好的默认值,有助于指定文本是关于图像的内容。
这通常会提高仅使用标签文本的基线的性能。 例如,仅使用此提示可将 ImageNet 上的准确性提高 1.3%。
Similar to the “prompt engineering” discussion around GPT-3 (Brown et al., 2020; Gao et al., 2020), we have also observed that zero-shot performance can be significantly improved by customizing the prompt text to each task.
A few, non exhaustive, examples follow. We found on several fine-grained image classification datasets that it helped to specify the category. For example on Oxford-IIIT Pets, using “A photo of a {label}, a type of pet.” to help provide context worked well.
Likewise, on Food101 specifying a type of food and on FGVC Aircraft a type of aircraft helped too.
For OCR datasets, we found that putting quotes around the text or number to be recognized improved performance.
Finally, we found that on satellite image classification datasets it helped to specify that the images were of this form and we use variants of “a satellite photo of a {label}.”
类似于围绕 GPT-3 的“提示工程”讨论,我们还观察到通过为每个任务定制提示文本可以显着提高零样本性能。
以下是一些非详尽的示例。 我们在几个细粒度图像分类数据集上发现它有助于指定类别。 例如在 Oxford-IIIT Pets 上,使用“A photo of a {label}, a type of pet”帮助提供上下文效果很好。
同样,在 Food101 上指定一种食物和在 FGVC Aircraft 上指定一种飞机也有帮助。
对于 OCR 数据集,我们发现在要识别的文本或数字周围加上引号可以提高性能。
最后,我们发现在卫星图像分类数据集上,它有助于指定图像属于这种形式,我们使用“a satellite photo of a {label}”的变体。
We also experimented with ensembling over multiple zero-shot classifiers as another way of improving performance.
These classifiers are computed by using different context prompts such as ‘A photo of a big {label}” and “A photo of a small {label}”.
We construct the ensemble over the embedding space instead of probability space.
This allows us to cache a single set of averaged text embeddings so that the compute cost of the ensemble is the same as using a single classifier when amortized over many predictions.
We’ve observed ensembling across many generated zero-shot classifiers to reliably improve performance and use it for the majority of datasets.
On ImageNet, we ensemble 80 different context prompts and this improves performance by an additional 3.5% over the single default prompt discussed above.
When considered together, prompt engineering and ensembling improve ImageNet accuracy by almost 5%.
In Figure 4 we visualize how prompt engineering and ensembling change the performance of a set of CLIP models compared to the contextless baseline approach of directly embedding the class name as done in Li et al. (2017).
我们还尝试了对多个零样本分类器进行集成作为提高性能的另一种方法。
这些分类器是通过使用不同的上下文提示来计算的,例如“A photo of a big {label}”和“A photo of a small {label}”。
我们在嵌入空间而不是概率空间上构建集成。
这允许我们缓存一组平均文本嵌入,以便在分摊到许多预测时,集成的计算成本与使用单个分类器相同。
我们已经观察到许多生成的零样本分类器的集成可以可靠地提高性能并将其用于大多数数据集。
在 ImageNet 上,我们集成了 80 种不同的上下文提示,与上面讨论的单个默认提示相比,这将性能提高了 3.5%。
当一起考虑时,提示工程和集成将 ImageNet 的准确性提高了近 5%。
在图 4 中,我们将提示工程和集成如何改变一组 CLIP 模型的性能与直接嵌入类名的无上下文基线方法(如 Li 等人所做的)进行了对比。 (2017)。
3.1.5. ANALYSIS OF ZERO-SHOT CLIP PERFORMANCE
原文:https://zhuanlan.zhihu.com/p/600847090
Since task-agnostic zero-shot classifiers for computer vision have been understudied, CLIP provides a promising oppor- tunity to gain a better understanding of this type of model. In this section, we conduct a study of various properties of CLIP’s zero-shot classifiers. As a first question, we look simply at how well zero-shot classifiers perform. To con- textualize this, we compare to the performance of a simple off-the-shelf baseline: fitting a fully supervised, regularized, logistic regression classifier on the features of the canonical ResNet-50. In Figure 5 we show this comparison across 27 datasets. Please see Appendix A for details of datasets and setup.由于用于计算机视觉的任务不可知零样本分类器已经被充分研究,CLIP 提供了一个有希望的机会来更好地理解这种类型的模型。 在本节中,我们对 CLIP 的零样本分类器的各种特性进行了研究。 作为第一个问题,我们简单地看一下零样本分类器的性能。 为了对此进行上下文化,我们将其与一个简单的现成基线的性能进行比较:在规范的 ResNet-50 的特征上拟合一个完全监督的、正则化的、逻辑回归分类器。 在图 5 中,我们展示了 27 个数据集的这种比较。 有关数据集和设置的详细信息,请参阅附录 A。
Zero-shot CLIP outperforms this baseline slightly more often than not and wins on 16 of the 27 datasets. Looking at individual datasets reveals some interesting behavior. On fine-grained classification tasks, we observe a wide spread in performance. On two of these datasets, Stanford Cars and Food101, zero-shot CLIP outperforms logistic regression on ResNet-50 features by over 20% while on two others, Flowers102 and FGVCAircraft, zero-shot CLIP underper- forms by over 10%. On OxfordPets and Birdsnap, per- formance is much closer. We suspect these difference are primarily due to varying amounts of per-task supervision between WIT and ImageNet. On “general” object classifica- tion datasets such as ImageNet, CIFAR10/100, STL10, and PascalVOC2007 performance is relatively similar with a slight advantage for zero-shot CLIP in all cases. On STL10, CLIP achieves 99.3% overall which appears to be a new state of the art despite not using any training examples. Zero- shot CLIP significantly outperforms a ResNet-50 on two datasets measuring action recognition in videos. On Kinet- ics700, CLIP outperforms a ResNet-50 by 14.5%. Zero- shot CLIP also outperforms a ResNet-50’s features by 7.7% on UCF101. We speculate this is due to natural language providing wider supervision for visual concepts involving verbs, compared to the noun-centric object supervision in ImageNet.零样本 CLIP 略微优于该基线,并在 27 个数据集中的 16 个上获胜。 查看单个数据集会发现一些有趣的行为。 在细粒度分类任务中,我们观察到性能差异很大。 在其中两个数据集 Stanford Cars 和 Food101 上,零样本 CLIP 在 ResNet-50 特征上的表现优于逻辑回归 20% 以上,而在另外两个数据集 Flowers102 和 FGVCAircraft 上,零样本 CLIP 的表现落后 10% 以上。 在 OxfordPets 和 Birdsnap 上,性能更接近。 我们怀疑这些差异主要是由于 WIT 和 ImageNet 之间每个任务的监督数量不同。 在 ImageNet、CIFAR10/100、STL10 和 PascalVOC2007 等“通用”对象分类数据集上,性能相对相似,在所有情况下零样本 CLIP 都略有优势。 在 STL10 上,CLIP 总体上达到了 99.3%,这似乎是一种新的技术水平,尽管没有使用任何训练示例。 Zeroshot CLIP 在两个测量视频动作识别的数据集上明显优于 ResNet-50。 在 Kinetics700 上,CLIP 优于 ResNet-50 14.5%。 Zeroshot CLIP 在 UCF101 上的性能也优于 ResNet-50 的特性 7.7%。 我们推测这是由于与 ImageNet 中以名词为中心的对象监督相比,自然语言为涉及动词的视觉概念提供了更广泛的监督。
Looking at where zero-shot CLIP notably underperforms,we see that zero-shot CLIP is quite weak on several spe- cialized, complex, or abstract tasks such as satellite image classification (EuroSAT and RESISC45), lymph node tumor detection (PatchCamelyon), counting objects in synthetic scenes (CLEVRCounts), self-driving related tasks such as German traffic sign recognition (GTSRB), recognizing dis- tance to the nearest car (KITTI Distance). These results highlight the poor capability of zero-shot CLIP on more complex tasks. By contrast, non-expert humans can robustly perform several of these tasks, such as counting, satellite image classification, and traffic sign recognition, suggesting significant room for improvement. However, we caution that it is unclear whether measuring zero-shot transfer, as opposed to few-shot transfer, is a meaningful evaluation for difficult tasks that a learner has no prior experience with, such as lymph node tumor classification for almost all hu- mans (and possibly CLIP).看看零样本 CLIP 明显表现不佳的地方,我们发现零样本 CLIP 在卫星图像分类(EuroSAT 和 RESISC45)、淋巴结肿瘤检测(PatchCamelyon)、 计算合成场景中的物体(CLEVRCounts),自动驾驶相关任务,例如德国交通标志识别(GTSRB),识别到最近汽车的距离(KITTI 距离)。 这些结果凸显了零样本 CLIP 在更复杂任务上的较差能力。 相比之下,非专家人员可以稳健地执行其中的多项任务,例如计数、卫星图像分类和交通标志识别,这表明还有很大的改进空间。 然而,我们警告说,与小样本迁移相比,测量零样本迁移是否是对学习者之前没有经验的困难任务的有意义的评估尚不清楚,例如几乎所有人类的淋巴结肿瘤分类( 和可能的剪辑)。
While comparing zero-shot performance to fully supervised models contextualizes the task-learning capabilities of CLIP, comparing to few-shot methods is a more direct comparison, since zero-shot is its limit. In Figure 6, we visualize how zero-shot CLIP compares to few-shot logistic regression on the features of many image models including the best publicly available ImageNet models, self-supervised learning methods, and CLIP itself. While it is intuitive to expect zero-shot to underperform one-shot, we instead find that zero-shot CLIP matches the performance of 4-shot logistic regression on the same feature space. This is likely due to an important difference between the zero-shot and few-shot approach. First, CLIP’s zero-shot classifier is generated via natural language which allows for visual concepts to be directly specified (“communicated”). By contrast, “normal” supervised learning must infer concepts indirectly from training examples. Context-less example-based learning has the drawback that many different hypotheses can be consistent with the data, especially in the one-shot case. A single image often contains many different visual concepts. Although a capable learner is able to exploit visual cues and heuristics, such as assuming that the concept being demonstrated is the primary object in an image, there is no guarantee.虽然将零样本性能与完全监督模型进行比较可以使 CLIP 的任务学习能力情境化,但与少样本方法进行比较是更直接的比较,因为零样本是它的极限。 在图 6 中,我们可视化了零样本 CLIP 与少样本逻辑回归在许多图像模型(包括最佳公开可用的 ImageNet 模型、自监督学习方法和 CLIP 本身)的特征上的比较。 虽然期望零样本表现不如单样本是很直观的,但我们发现零样本 CLIP 在同一特征空间上与 4 样本逻辑回归的性能相匹配。 这可能是由于零样本和少样本方法之间的重要区别。 首先,CLIP 的零样本分类器是通过自然语言生成的,允许直接指定(“交流”)视觉概念。 相比之下,“正常”的监督学习必须间接地从训练示例中推断出概念。 无上下文的基于示例的学习的缺点是许多不同的假设可能与数据一致,尤其是在一次性情况下。 单个图像通常包含许多不同的视觉概念。 尽管有能力的学习者能够利用视觉线索和启发式方法,例如假设正在展示的概念是图像中的主要对象,但这并不能保证。
A potential resolution of this discrepancy between zeroshot and few-shot performance is to use CLIP’s zero-shot classifier as a prior for the weights of the few-shot classifier. While adding an L2 penalty towards the generated weights is a straightforward implementation of this idea, we found that hyperparameter optimization would often select for such a large value of this regularizer that the resulting fewshot classifier was “just” the zero-shot classifier. Research into better methods of combining the strength of zero-shot transfer with flexibility of few-shot learning is a promising direction for future work.解决 zeroshot 和 few-shot 性能之间这种差异的一个潜在解决方案是使用 CLIP 的 zero-shot 分类器作为 few-shot 分类器权重的先验。 虽然对生成的权重添加 L2 惩罚是该想法的直接实现,但我们发现超参数优化通常会选择如此大的正则化值,以至于生成的 fewshot 分类器“只是”零样本分类器。 研究将零样本迁移的强度与少样本学习的灵活性相结合的更好方法是未来工作的一个有前途的方向。
When comparing zero-shot CLIP to few-shot logistic regression on the features of other models, zero-shot CLIP roughly matches the performance of the best performing 16-shot classifier in our evaluation suite, which uses the features of a BiT-M ResNet-152x2 trained on ImageNet-21K. We are certain that a BiT-L model trained on JFT-300M would perform even better but these models have not been publicly released. That a BiT-M ResNet-152x2 performs best in a 16-shot setting is somewhat surprising since, as analyzed in Section 3.2, the Noisy Student EfficientNet-L2 outperforms it in a fully supervised setting by almost 5% on average across 27 datasets.将零样本 CLIP 与其他模型特征的少样本逻辑回归进行比较时,零样本 CLIP 与我们评估套件中性能最佳的 16 样本分类器的性能大致相当,该分类器使用 BiT-M ResNet 的特征 -152x2 在 ImageNet-21K 上训练。 我们确信在 JFT-300M 上训练的 BiT-L 模型会表现得更好,但这些模型尚未公开发布。 BiT-M ResNet-152x2 在 16 次拍摄设置中表现最佳有点令人惊讶,因为如第 3.2 节中分析的那样,Noisy Student EfficientNet-L2 在 27 个数据集上的完全监督设置中平均优于它近 5%。
In addition to studying the average performance of zero-shot CLIP and few-shot logistic regression, we also examine performance on individual datasets. In Figure 7, we show estimates for the number of labeled examples per class that a logistic regression classifier on the same feature space requires to match the performance of zero-shot CLIP. Since zero-shot CLIP is also a linear classifier, this estimates the effective data efficiency of zero-shot transfer in this setting. In order to avoid training thousands of linear classifiers, we estimate the effective data efficiency based on a loglinear interpolation of the performance of a 1, 2, 4, 8, 16- shot (when possible), and a fully supervised linear classifier trained on each dataset. We find that zero-shot transfer can have widely varying efficiency per dataset from less than 1 labeled example per class to 184. Two datasets, Flowers102 and EuroSAT underperform one-shot models. Half of the datasets require less than 5 examples per class with a median of 5.4. However, the mean estimated data efficiency is 20.8 examples per class. This is due to the 20% of datasets where supervised classifiers require many labeled examples per class in order to match performance. On ImageNet, zero-shot CLIP matches the performance of a 16-shot linear classifier trained on the same feature space.除了研究零样本 CLIP 和少样本逻辑回归的平均性能外,我们还检查了单个数据集的性能。 在图 7 中,我们显示了对同一特征空间上的逻辑回归分类器匹配零样本 CLIP 性能所需的每个类别的标记示例数量的估计。 由于零样本 CLIP 也是一个线性分类器,因此这估计了此设置中零样本传输的有效数据效率。 为了避免训练数千个线性分类器,我们根据 1、2、4、8、16 次拍摄(如果可能)的性能的对数线性插值估计有效数据效率,以及在 每个数据集。 我们发现零样本传输在每个数据集上的效率差异很大,从每个类少于 1 个标记示例到 184 个。两个数据集 Flowers102 和 EuroSAT 的表现不如单样本模型。 一半的数据集每个类需要少于 5 个示例,中位数为 5.4。 然而,平均估计数据效率为每类 20.8 个示例。 这是因为在 20% 的数据集中,监督分类器需要每个类有许多标记示例才能匹配性能。 在 ImageNet 上,零样本 CLIP 与在同一特征空间上训练的 16 样本线性分类器的性能相匹配。
If we assume that evaluation datasets are large enough that the parameters of linear classifiers trained on them are well estimated, then, because CLIP’s zero-shot classifier is also a linear classifier, the performance of the fully supervised classifiers roughly sets an upper bound for what zero-shot transfer can achieve. In Figure 8 we compare CLIP’s zeroshot performance with fully supervised linear classifiers across datasets. The dashed, y = x line represents an “optimal” zero-shot classifier that matches the performance of its fully supervised equivalent. For most datasets, the performance of zero-shot classifiers still underperform fully supervised classifiers by 10% to 25%, suggesting that there is still plenty of headroom for improving CLIP’s task-learning and zero-shot transfer capabilities.如果我们假设评估数据集足够大,可以很好地估计在其上训练的线性分类器的参数,那么,由于 CLIP 的零样本分类器也是线性分类器,因此完全监督分类器的性能大致设定了一个上限 可以实现零样本传输。 在图 8 中,我们比较了 CLIP 的 zeroshot 性能与跨数据集的完全监督线性分类器。 虚线 y = x 表示“最佳”零样本分类器,其性能与其完全监督的等效分类器相匹配。 对于大多数数据集,零样本分类器的性能仍然比完全监督分类器低 10% 到 25%,这表明 CLIP 的任务学习和零样本迁移能力仍有很大提升空间。
There is a positive correlation of 0.82 (p-value < 10-6) between zero-shot performance and fully supervised performance, suggesting that CLIP is relatively consistent at connecting underlying representation and task learning to zeroshot transfer. However, zero-shot CLIP only approaches fully supervised performance on 5 datasets: STL10, CIFAR10, Food101, OxfordPets, and Caltech101. On all 5 datasets, both zero-shot accuracy and fully supervised accuracy are over 90%. This suggests that CLIP may be more effective at zero-shot transfer for tasks where its underlying representations are also high quality. The slope of a linear regression model predicting zero-shot performance as a function of fully supervised performance estimates that for every 1% improvement in fully supervised performance, zero-shot performance improves by 1.28%. However, the 95th-percentile confidence intervals still include values of less than 1 (0.93-1.79).零样本性能和完全监督的性能之间存在 0.82 的正相关(p 值 < 10-6),这表明 CLIP 在将基础表示和任务学习与零样本迁移联系起来方面相对一致。 然而,零样本 CLIP 仅在 5 个数据集上接近完全监督的性能:STL10、CIFAR10、Food101、OxfordPets 和 Caltech101。 在所有 5 个数据集上,零样本准确率和全监督准确率均超过 90%。 这表明 CLIP 在其底层表示也具有高质量的任务的零样本迁移方面可能更有效。 预测零射击性能作为完全监督性能的函数的线性回归模型的斜率估计,对于完全监督性能每提高 1%,零射击性能提高 1.28%。 但是,第 95 个百分位置信区间仍包含小于 1 (0.93-1.79) 的值。
Over the past few years, empirical studies of deep learning systems have documented that performance is predictable as a function of important quantities such as training compute and dataset size (Hestness et al., 2017; Kaplan et al., 2020). The GPT family of models has so far demonstrated consistent improvements in zero-shot performance across a 1000x increase in training compute. In Figure 9, we check whether the zero-shot performance of CLIP follows a similar scaling pattern. We plot the average error rate of the 5 ResNet CLIP models across 39 evaluations on 36 different datasets and find that a similar log-log linear scaling trend holds for CLIP across a 44x increase in model compute. While the overall trend is smooth, we found that performance on individual evaluations can be much noisier. We are unsure whether this is caused by high variance between individual training runs on sub-tasks (as documented in D’Amour et al. (2020)) masking a steadily improving trend or whether performance is actually non-monotonic as a function of compute on some tasks.在过去几年中,深度学习系统的实证研究表明,性能是可预测的,它是训练计算和数据集大小等重要数量的函数(Hestness 等人,2017 年;Kaplan 等人,2020 年)。 迄今为止,GPT 系列模型在训练计算量增加 1000 倍的过程中证明了零样本性能的持续改进。 在图 9 中,我们检查 CLIP 的零样本性能是否遵循类似的缩放模式。 我们绘制了 5 个 ResNet CLIP 模型在 36 个不同数据集上的 39 次评估的平均错误率,并发现在模型计算增加 44 倍的情况下,CLIP 具有类似的对数对数线性缩放趋势。 虽然总体趋势是平稳的,但我们发现个别评估的表现可能更加嘈杂。 我们不确定这是否是由于子任务的个体训练运行之间的高差异(如 D'Amour 等人 (2020) 中所述)掩盖了稳步提高的趋势,或者性能是否实际上是非单调的计算函数 在一些任务上。