项目地址:https://github.com/TrickyGo/Dive-into-DL-TensorFlow2.0
UC 伯克利李沐的《动手学深度学习》开源书一经推出便广受好评。很多开发者使用了书的内容,并采用各种各样的深度学习框架将其复现。
现在,《动手学深度学习》书又有了一个新的复现代码版本——TensorFlow2.0 版,短时间内成为了github上千star项目,欢迎关注。
文章目录
3.2 线性回归的从零开始实现
在了解了线性回归的背景知识之后,现在我们可以动手实现它了。尽管强大的深度学习框架可以减少大量重复性工作,但若过于依赖它提供的便利,会导致我们很难深入理解深度学习是如何工作的。因此,本节将介绍如何只利用Tensor和autograd来实现一个线性回归的训练。
首先,导入本节中实验所需的包或模块,其中的matplotlib包可用于作图,且设置成嵌入显示。
%matplotlib inline
import tensorflow as tf
print(tf.__version__)
from matplotlib import pyplot as plt
import random
3.2.1 生成数据集
我们构造一个简单的人工训练数据集,它可以使我们能够直观比较学到的参数和真实的模型参数的区别。设训练数据集样本数为1000,输入个数(特征数)为2。给定随机生成的批量样本特征 X ∈ R 1000 × 2 \boldsymbol{X} \in \mathbb{R}^{1000 \times 2} X∈R1000×2,我们使用线性回归模型真实权重 w = [ 2 , − 3.4 ] ⊤ \boldsymbol{w} = [2, -3.4]^\top w=[2,−3.4]⊤ 和偏差 b = 4.2 b = 4.2 b=4.2,以及一个随机噪声项 ϵ \epsilon ϵ 来生成标签
y = X w + b + ϵ \boldsymbol{y} = \boldsymbol{X}\boldsymbol{w} + b + \epsilon y=Xw+b+ϵ
其中噪声项 ϵ \epsilon ϵ 服从均值为0、标准差为0.01的正态分布。噪声代表了数据集中无意义的干扰。下面,让我们生成数据集。
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = tf.random.normal((num_examples, num_inputs),stddev = 1)
labels = true_w[0] * features[:,0] + true_w[1] * features[:,1] + true_b
labels += tf.random.normal(labels.shape,stddev=0.01)
注意,features的每一行是一个长度为2的向量,而labels的每一行是一个长度为1的向量(标量)。
print(features[0], labels[0])
输出:
tensor([0.8557, 0.4793]) tensor(4.2887)
通过生成第二个特征features[:, 1]和标签 labels 的散点图,可以更直观地观察两者间的线性关系。
def set_figsize(figsize=(3.5, 2.5)):
plt.rcParams['figure.figsize'] = figsize
set_figsize()
plt.scatter(features[:, 1], labels, 1)
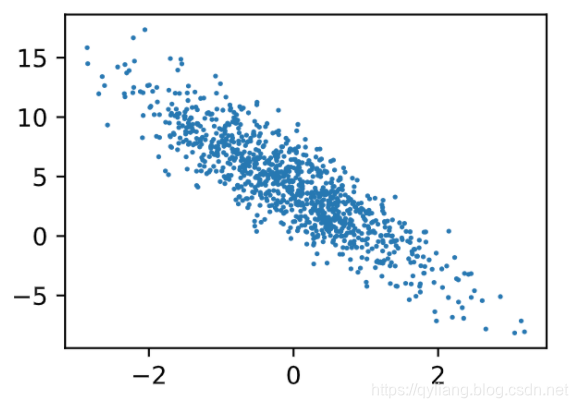
3.2.2 读取数据
在训练模型的时候,我们需要遍历数据集并不断读取小批量数据样本。这里我们定义一个函数:它每次返回batch_size(批量大小)个随机样本的特征和标签。
import numpy as np
def data_iter(batch_size, features, labels):
features = np.array(features)
labels = np.array(labels)
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
j = np.array(indices[i:min(i + batch_size, num_examples)])
yield features[j], labels[j]
让我们读取第一个小批量数据样本并打印。每个批量的特征形状为(10, 2),分别对应批量大小和输入个数;标签形状为批量大小。
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, y)
break
输出:
tensor([[-1.4239, -1.3788],
[ 0.0275, 1.3550],
[ 0.7616, -1.1384],
[ 0.2967, -0.1162],
[ 0.0822, 2.0826],
[-0.6343, -0.7222],
[ 0.4282, 0.0235],
[ 1.4056, 0.3506],
[-0.6496, -0.5202],
[-0.3969, -0.9951]])
tensor([ 6.0394, -0.3365, 9.5882, 5.1810, -2.7355, 5.3873, 4.9827, 5.7962,
4.6727, 6.7921])
3.2.3 初始化模型参数
我们将权重初始化成均值为0、标准差为0.01的正态随机数,偏差则初始化成0。
w = tf.Variable(tf.random.normal((num_inputs, 1), stddev=0.01))
b = tf.Variable(tf.zeros((1,)))
3.2.4 定义模型
下面是线性回归的矢量计算表达式的实现。我们使用matmul函数做矩阵乘法。
def linreg(X, w, b):
return tf.matmul(X, w) + b
3.2.5 定义损失函数
我们使用上一节描述的平方损失来定义线性回归的损失函数。在实现中,我们需要把真实值y变形成预测值y_hat的形状。以下函数返回的结果也将和y_hat的形状相同。
def squared_loss(y_hat, y):
return (y_hat - tf.reshape(y, y_hat.shape)) ** 2 /2
3.2.6 定义优化算法
以下的sgd函数实现了上一节中介绍的小批量随机梯度下降算法。它通过不断迭代模型参数来优化损失函数。这里自动求梯度模块计算得来的梯度是一个批量样本的梯度和。我们将它除以批量大小来得到平均值。
def sgd(params, lr, batch_size,t,l):
for param in params:
# param[:] = param - lr * t.gradient(l, param) / batch_size
param.assign_sub(lr * t.gradient(l, param) / batch_size)
3.2.7 训练模型
在训练中,我们将多次迭代模型参数。在每次迭代中,我们根据当前读取的小批量数据样本(特征X和标签y),通过调用反向函数backward计算小批量随机梯度,并调用优化算法sgd迭代模型参数。由于我们之前设批量大小batch_size为10,每个小批量的损失l的形状为(10, 1)。回忆一下自动求梯度一节。由于变量l并不是一个标量,所以我们可以调用.sum()将其求和得到一个标量,再运行l.backward()得到该变量有关模型参数的梯度。注意在每次更新完参数后不要忘了将参数的梯度清零。
在一个迭代周期(epoch)中,我们将完整遍历一遍data_iter函数,并对训练数据集中所有样本都使用一次(假设样本数能够被批量大小整除)。这里的迭代周期个数num_epochs和学习率lr都是超参数,分别设3和0.03。在实践中,大多超参数都需要通过反复试错来不断调节。虽然迭代周期数设得越大模型可能越有效,但是训练时间可能过长。而有关学习率对模型的影响,我们会在后面“优化算法”一章中详细介绍。
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
with tf.GradientTape(persistent=True) as t:
t.watch([w,b])
l = loss(net(X, w, b), y)
sgd([w, b], lr, batch_size)
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch + 1, tf.reduce_mean(train_l)))
输出:
epoch 1, loss 0.028127
epoch 2, loss 0.000095
epoch 3, loss 0.000050
训练完成后,我们可以比较学到的参数和用来生成训练集的真实参数。它们应该很接近。
print(true_w, '\n', w)
print(true_b, '\n', b)
输出:
[2, -3.4]
tensor([[ 1.9998],
[-3.3998]], requires_grad=True)
4.2
tensor([4.2001], requires_grad=True)
小结
- 可以看出,仅使用
Variables和GradientTape模块就可以很容易地实现一个模型。接下来,本书会在此基础上描述更多深度学习模型,并介绍怎样使用更简洁的代码(见下一节)来实现它们。
3.3 线性回归的简洁实现
随着深度学习框架的发展,开发深度学习应用变得越来越便利。实践中,我们通常可以用比上一节更简洁的代码来实现同样的模型。在本节中,我们将介绍如何使用tensorflow2.0推荐的keras接口更方便地实现线性回归的训练。
3.3.1 生成数据集
我们生成与上一节中相同的数据集。其中features是训练数据特征,labels是标签。
import tensorflow as tf
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = tf.random.normal(shape=(num_examples, num_inputs), stddev=1)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += tf.random.normal(labels.shape, stddev=0.01)
3.3.2 读取数据
虽然tensorflow2.0对于线性回归可以直接拟合,不用再划分数据集,但我们仍学习一下读取数据的方法
from tensorflow import data as tfdata
batch_size = 10
# 将训练数据的特征和标签组合
dataset = tfdata.Dataset.from_tensor_slices((features, labels))
# 随机读取小批量
dataset = dataset.shuffle(buffer_size=num_examples)
dataset = dataset.batch(batch_size)
data_iter = iter(dataset)
shuffle 的 buffer_size 参数应大于等于样本数,batch 可以指定 batch_size 的分割大小。
for X, y in data_iter:
print(X, y)
break
tf.Tensor(
[[ 1.2856768 1.3815335 ]
[ 1.1151928 -1.3777982 ]
[ 0.6097271 1.3478378 ]
[ 2.1615875 1.52963 ]
[-1.3143488 -0.79531455]
[-2.495006 0.3701927 ]
[-0.07739297 -0.8636043 ]
[-0.18479416 -1.5275241 ]
[-0.3426277 -0.01935842]
[ 0.25231913 1.4940815 ]], shape=(10, 2), dtype=float32) tf.Tensor(
[ 2.0673854 11.10116 0.8320709 3.3300133 4.272185 -2.062947
6.981174 9.027803 3.5848885 -0.39152586], shape=(10,), dtype=float32)
使用iter(dataset)的方式,只能遍历数据集一次,是一种比较 tricky 的写法,为了复刻原书表达才这样写。这里也给出一种在官方文档中推荐的写法:
for (batch, (X, y)) in enumerate(dataset):
print(X, y)
break
3.3.3 定义模型和初始化参数
Tensorflow 2.0推荐使用Keras定义网络,故使用Keras定义网络
我们先定义一个模型变量model,它是一个Sequential实例。
在Keras中,Sequential实例可以看作是一个串联各个层的容器。
在构造模型时,我们在该容器中依次添加层。
当给定输入数据时,容器中的每一层将依次推断下一层的输入尺寸。
重要的一点是,在Keras中我们无须指定每一层输入的形状。
线性回归,输入层与输出层等效为一层全连接层keras.layers.Dense()。
Keras 中初始化参数由 kernel_initializer 和 bias_initializer 选项分别设置权重和偏置的初始化方式。我们从 tensorflow 导入 initializers 模块,指定权重参数每个元素将在初始化时随机采样于均值为0、标准差为0.01的正态分布。偏差参数默认会初始化为零。RandomNormal(stddev=0.01)指定权重参数每个元素将在初始化时随机采样于均值为0、标准差为0.01的正态分布。偏差参数默认会初始化为零。
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow import initializers as init
model = keras.Sequential()
model.add(layers.Dense(1, kernel_initializer=init.RandomNormal(stddev=0.01)))
3.3.4 定义损失函数
Tensoflow在losses模块中提供了各种损失函数和自定义损失函数的基类,并直接使用它的均方误差损失作为模型的损失函数。
from tensorflow import losses
loss = losses.MeanSquaredError()
3.3.5 定义优化算法
同样,我们也无须自己实现小批量随机梯度下降算法。tensorflow.keras.optimizers 模块提供了很多常用的优化算法比如SGD、Adam和RMSProp等。下面我们创建一个用于优化model 所有参数的优化器实例,并指定学习率为0.03的小批量随机梯度下降(SGD)为优化算法。
from tensorflow.keras import optimizers
trainer = optimizers.SGD(learning_rate=0.03)
3.3.6 训练模型
在使用Tensorflow训练模型时,我们通过调用tensorflow.GradientTape记录动态图梯度,执行tape.gradient获得动态图中各变量梯度。通过 model.trainable_variables 找到需要更新的变量,并用 trainer.apply_gradients 更新权重,完成一步训练。
num_epochs = 3
for epoch in range(1, num_epochs + 1):
for (batch, (X, y)) in enumerate(dataset):
with tf.GradientTape() as tape:
l = loss(model(X, training=True), y)
grads = tape.gradient(l, model.trainable_variables)
trainer.apply_gradients(zip(grads, model.trainable_variables))
l = loss(model(features), labels)
print('epoch %d, loss: %f' % (epoch, l.numpy().mean()))
epoch 1, loss: 0.519287
epoch 2, loss: 0.008997
epoch 3, loss: 0.000261
下面我们分别比较学到的模型参数和真实的模型参数。我们可以通过model的get_weights()来获得其权重(weight)和偏差(bias)。学到的参数和真实的参数很接近。
true_w, model.get_weights()[0]
([2, -3.4], array([[ 1.9930198],
[-3.3977082]], dtype=float32))
true_b, model.get_weights()[1]
(4.2, array([4.1895046], dtype=float32))
小结
- 使用
Tensorflow可以更简洁地实现模型。 tensorflow.data模块提供了有关数据处理的工具,tensorflow.keras.layers模块定义了大量神经网络的层,tensorflow.initializers模块定义了各种初始化方法,tensorflow.optimizers模块提供了模型的各种优化算法。
注:本节除了代码之外与原书基本相同,原书传送门
3.4 softmax回归
前几节介绍的线性回归模型适用于输出为连续值的情景。在另一类情景中,模型输出可以是一个像图像类别这样的离散值。对于这样的离散值预测问题,我们可以使用诸如softmax回归在内的分类模型。和线性回归不同,softmax回归的输出单元从一个变成了多个,且引入了softmax运算使输出更适合离散值的预测和训练。本节以softmax回归模型为例,介绍神经网络中的分类模型。
3.4.1 分类问题
让我们考虑一个简单的图像分类问题,其输入图像的高和宽均为2像素,且色彩为灰度。这样每个像素值都可以用一个标量表示。我们将图像中的4像素分别记为 x 1 , x 2 , x 3 , x 4 x_1, x_2, x_3, x_4 x1,x2,x3,x4。假设训练数据集中图像的真实标签为狗、猫或鸡(假设可以用4像素表示出这3种动物),这些标签分别对应离散值 y 1 , y 2 , y 3 y_1, y_2, y_3 y1,y2,y3。
我们通常使用离散的数值来表示类别,例如 y 1 = 1 , y 2 = 2 , y 3 = 3 y_1=1, y_2=2, y_3=3 y1=1,y2=2,y3=3。如此,一张图像的标签为1、2和3这3个数值中的一个。虽然我们仍然可以使用回归模型来进行建模,并将预测值就近定点化到1、2和3这3个离散值之一,但这种连续值到离散值的转化通常会影响到分类质量。因此我们一般使用更加适合离散值输出的模型来解决分类问题。
3.4.2 softmax回归模型
softmax回归跟线性回归一样将输入特征与权重做线性叠加。与线性回归的一个主要不同在于,softmax回归的输出值个数等于标签里的类别数。因为一共有4种特征和3种输出动物类别,所以权重包含12个标量(带下标的 w w w)、偏差包含3个标量(带下标的 b b b),且对每个输入计算 o 1 , o 2 , o 3 o_1, o_2, o_3 o1,o2,o3这3个输出:
o 1 = x 1 w 11 + x 2 w 21 + x 3 w 31 + x 4 w 41 + b 1 , o 2 = x 1 w 12 + x 2 w 22 + x 3 w 32 + x 4 w 42 + b 2 , o 3 = x 1 w 13 + x 2 w 23 + x 3 w 33 + x 4 w 43 + b 3 . \begin{aligned} o_1 &= x_1 w_{11} + x_2 w_{21} + x_3 w_{31} + x_4 w_{41} + b_1,\\ o_2 &= x_1 w_{12} + x_2 w_{22} + x_3 w_{32} + x_4 w_{42} + b_2,\\ o_3 &= x_1 w_{13} + x_2 w_{23} + x_3 w_{33} + x_4 w_{43} + b_3. \end{aligned} o1o2o3=x1w11+x2w21+x3w31+x4w41+b1,=x1w12+x2w22+x3w32+x4w42+b2,=x1w13+x2w23+x3w33+x4w43+b3.
图3.2用神经网络图描绘了上面的计算。softmax回归同线性回归一样,也是一个单层神经网络。由于每个输出 o 1 , o 2 , o 3 o_1, o_2, o_3 o1,o2,o3的计算都要依赖于所有的输入 x 1 , x 2 , x 3 , x 4 x_1, x_2, x_3, x_4 x1,x2,x3,x4,softmax回归的输出层也是一个全连接层。
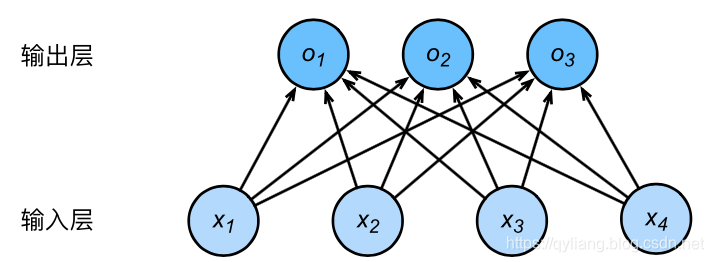
既然分类问题需要得到离散的预测输出,一个简单的办法是将输出值 o i o_i oi当作预测类别是 i i i的置信度,并将值最大的输出所对应的类作为预测输出,即输出 arg max i o i \underset{i}{\arg\max} o_i iargmaxoi。例如,如果 o 1 , o 2 , o 3 o_1,o_2,o_3 o1,o2,o3分别为 0.1 , 10 , 0.1 0.1,10,0.1 0.1,10,0.1,由于 o 2 o_2 o2最大,那么预测类别为2,其代表猫。
然而,直接使用输出层的输出有两个问题。一方面,由于输出层的输出值的范围不确定,我们难以直观上判断这些值的意义。例如,刚才举的例子中的输出值10表示“很置信”图像类别为猫,因为该输出值是其他两类的输出值的100倍。但如果 o 1 = o 3 = 1 0 3 o_1=o_3=10^3 o1=o3=103,那么输出值10却又表示图像类别为猫的概率很低。另一方面,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
softmax运算符(softmax operator)解决了以上两个问题。它通过下式将输出值变换成值为正且和为1的概率分布:
y ^ 1 , y ^ 2 , y ^ 3 = softmax ( o 1 , o 2 , o 3 ) \hat{y}_1, \hat{y}_2, \hat{y}_3 = \text{softmax}(o_1, o_2, o_3) y^1,y^2,y^3=softmax(o1,o2,o3)
其中
y ^ 1 = exp ( o 1 ) ∑ i = 1 3 exp ( o i ) , y ^ 2 = exp ( o 2 ) ∑ i = 1 3 exp ( o i ) , y ^ 3 = exp ( o 3 ) ∑ i = 1 3 exp ( o i ) . \hat{y}_1 = \frac{ \exp(o_1)}{\sum_{i=1}^3 \exp(o_i)},\quad \hat{y}_2 = \frac{ \exp(o_2)}{\sum_{i=1}^3 \exp(o_i)},\quad \hat{y}_3 = \frac{ \exp(o_3)}{\sum_{i=1}^3 \exp(o_i)}. y^1=∑i=13exp(oi)exp(o1),y^2=∑i=13exp(oi)exp(o2),y^3=∑i=13exp(oi)exp(o3).
容易看出 y ^ 1 + y ^ 2 + y ^ 3 = 1 \hat{y}_1 + \hat{y}_2 + \hat{y}_3 = 1 y^1+y^2+y^3=1且 0 ≤ y ^ 1 , y ^ 2 , y ^ 3 ≤ 1 0 \leq \hat{y}_1, \hat{y}_2, \hat{y}_3 \leq 1 0≤y^1,y^2,y^3≤1,因此 y ^ 1 , y ^ 2 , y ^ 3 \hat{y}_1, \hat{y}_2, \hat{y}_3 y^1,y^2,y^3是一个合法的概率分布。这时候,如果 y ^ 2 = 0.8 \hat{y}_2=0.8 y^2=0.8,不管 y ^ 1 \hat{y}_1 y^1和 y ^ 3 \hat{y}_3 y^3的值是多少,我们都知道图像类别为猫的概率是80%。此外,我们注意到
arg max i o i = arg max i y ^ i \underset{i}{\arg\max} o_i = \underset{i}{\arg\max} \hat{y}_i iargmaxoi=iargmaxy^i
因此softmax运算不改变预测类别输出。
3.4.3 单样本分类的矢量计算表达式
为了提高计算效率,我们可以将单样本分类通过矢量计算来表达。在上面的图像分类问题中,假设softmax回归的权重和偏差参数分别为
W = [ w 11 w 12 w 13 w 21 w 22 w 23 w 31 w 32 w 33 w 41 w 42 w 43 ] , b = [ b 1 b 2 b 3 ] , \boldsymbol{W} = \begin{bmatrix} w_{11} & w_{12} & w_{13} \\ w_{21} & w_{22} & w_{23} \\ w_{31} & w_{32} & w_{33} \\ w_{41} & w_{42} & w_{43} \end{bmatrix},\quad \boldsymbol{b} = \begin{bmatrix} b_1 & b_2 & b_3 \end{bmatrix}, W=⎣⎢⎢⎡w11w21w31w41w12w22w32w42w13w23w33w43⎦⎥⎥⎤,b=[b1b2b3],
设高和宽分别为2个像素的图像样本 i i i的特征为
x ( i ) = [ x 1 ( i ) x 2 ( i ) x 3 ( i ) x 4 ( i ) ] , \boldsymbol{x}^{(i)} = \begin{bmatrix}x_1^{(i)} & x_2^{(i)} & x_3^{(i)} & x_4^{(i)}\end{bmatrix}, x(i)=[x1(i)x2(i)x3(i)x4(i)],
输出层的输出为
o ( i ) = [ o 1 ( i ) o 2 ( i ) o 3 ( i ) ] , \boldsymbol{o}^{(i)} = \begin{bmatrix}o_1^{(i)} & o_2^{(i)} & o_3^{(i)}\end{bmatrix}, o(i)=[o1(i)o2(i)o3(i)],
预测为狗、猫或鸡的概率分布为
y ^ ( i ) = [ y ^ 1 ( i ) y ^ 2 ( i ) y ^ 3 ( i ) ] . \boldsymbol{\hat{y}}^{(i)} = \begin{bmatrix}\hat{y}_1^{(i)} & \hat{y}_2^{(i)} & \hat{y}_3^{(i)}\end{bmatrix}. y^(i)=[y^1(i)y^2(i)y^3(i)].
softmax回归对样本 i i i分类的矢量计算表达式为
o ( i ) = x ( i ) W + b , y ^ ( i ) = softmax ( o ( i ) ) . \begin{aligned} \boldsymbol{o}^{(i)} &= \boldsymbol{x}^{(i)} \boldsymbol{W} + \boldsymbol{b},\\ \boldsymbol{\hat{y}}^{(i)} &= \text{softmax}(\boldsymbol{o}^{(i)}). \end{aligned} o(i)y^(i)=x(i)W+b,=softmax(o(i)).
3.4.4 小批量样本分类的矢量计算表达式
为了进一步提升计算效率,我们通常对小批量数据做矢量计算。广义上讲,给定一个小批量样本,其批量大小为 n n n,输入个数(特征数)为 d d d,输出个数(类别数)为 q q q。设批量特征为 X ∈ R n × d \boldsymbol{X} \in \mathbb{R}^{n \times d} X∈Rn×d。假设softmax回归的权重和偏差参数分别为 W ∈ R d × q \boldsymbol{W} \in \mathbb{R}^{d \times q} W∈Rd×q和 b ∈ R 1 × q \boldsymbol{b} \in \mathbb{R}^{1 \times q} b∈R1×q。softmax回归的矢量计算表达式为
O = X W + b , Y ^ = softmax ( O ) , \begin{aligned} \boldsymbol{O} &= \boldsymbol{X} \boldsymbol{W} + \boldsymbol{b},\\ \boldsymbol{\hat{Y}} &= \text{softmax}(\boldsymbol{O}), \end{aligned} OY^=XW+b,=softmax(O),
其中的加法运算使用了广播机制, O , Y ^ ∈ R n × q \boldsymbol{O}, \boldsymbol{\hat{Y}} \in \mathbb{R}^{n \times q} O,Y^∈Rn×q且这两个矩阵的第 i i i行分别为样本 i i i的输出 o ( i ) \boldsymbol{o}^{(i)} o(i)和概率分布 y ^ ( i ) \boldsymbol{\hat{y}}^{(i)} y^(i)。
3.4.5 交叉熵损失函数
前面提到,使用softmax运算后可以更方便地与离散标签计算误差。我们已经知道,softmax运算将输出变换成一个合法的类别预测分布。实际上,真实标签也可以用类别分布表达:对于样本 i i i,我们构造向量 y ( i ) ∈ R q \boldsymbol{y}^{(i)}\in \mathbb{R}^{q} y(i)∈Rq ,使其第 y ( i ) y^{(i)} y(i)(样本 i i i类别的离散数值)个元素为1,其余为0。这样我们的训练目标可以设为使预测概率分布 y ^ ( i ) \boldsymbol{\hat y}^{(i)} y^(i)尽可能接近真实的标签概率分布 y ( i ) \boldsymbol{y}^{(i)} y(i)。
我们可以像线性回归那样使用平方损失函数 ∥ y ^ ( i ) − y ( i ) ∥ 2 / 2 \|\boldsymbol{\hat y}^{(i)}-\boldsymbol{y}^{(i)}\|^2/2 ∥y^(i)−y(i)∥2/2。然而,想要预测分类结果正确,我们其实并不需要预测概率完全等于标签概率。例如,在图像分类的例子里,如果 y ( i ) = 3 y^{(i)}=3 y(i)=3,那么我们只需要 y ^ 3 ( i ) \hat{y}^{(i)}_3 y^3(i)比其他两个预测值 y ^ 1 ( i ) \hat{y}^{(i)}_1 y^1(i)和 y ^ 2 ( i ) \hat{y}^{(i)}_2 y^2(i)大就行了。即使 y ^ 3 ( i ) \hat{y}^{(i)}_3 y^3(i)值为0.6,不管其他两个预测值为多少,类别预测均正确。而平方损失则过于严格,例如 y ^ 1 ( i ) = y ^ 2 ( i ) = 0.2 \hat y^{(i)}_1=\hat y^{(i)}_2=0.2 y^1(i)=y^2(i)=0.2比 y ^ 1 ( i ) = 0 , y ^ 2 ( i ) = 0.4 \hat y^{(i)}_1=0, \hat y^{(i)}_2=0.4 y^1(i)=0,y^2(i)=0.4的损失要小很多,虽然两者都有同样正确的分类预测结果。
改善上述问题的一个方法是使用更适合衡量两个概率分布差异的测量函数。其中,交叉熵(cross entropy)是一个常用的衡量方法:
H ( y ( i ) , y ^ ( i ) ) = − ∑ j = 1 q y j ( i ) log y ^ j ( i ) , H\left(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}\right ) = -\sum_{j=1}^q y_j^{(i)} \log \hat y_j^{(i)}, H(y(i),y^(i))=−j=1∑qyj(i)logy^j(i),
其中带下标的 y j ( i ) y_j^{(i)} yj(i)是向量 y ( i ) \boldsymbol y^{(i)} y(i)中非0即1的元素,需要注意将它与样本 i i i类别的离散数值,即不带下标的 y ( i ) y^{(i)} y(i)区分。在上式中,我们知道向量 y ( i ) \boldsymbol y^{(i)} y(i)中只有第 y ( i ) y^{(i)} y(i)个元素 y y ( i ) ( i ) y^{(i)}_{y^{(i)}} yy(i)(i)为1,其余全为0,于是 H ( y ( i ) , y ^ ( i ) ) = − log y ^ y ( i ) ( i ) H(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}) = -\log \hat y_{y^{(i)}}^{(i)} H(y(i),y^(i))=−logy^y(i)(i)。也就是说,交叉熵只关心对正确类别的预测概率,因为只要其值足够大,就可以确保分类结果正确。当然,遇到一个样本有多个标签时,例如图像里含有不止一个物体时,我们并不能做这一步简化。但即便对于这种情况,交叉熵同样只关心对图像中出现的物体类别的预测概率。
假设训练数据集的样本数为 n n n,交叉熵损失函数定义为
ℓ ( Θ ) = 1 n ∑ i = 1 n H ( y ( i ) , y ^ ( i ) ) , \ell(\boldsymbol{\Theta}) = \frac{1}{n} \sum_{i=1}^n H\left(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}\right ), ℓ(Θ)=n1i=1∑nH(y(i),y^(i)),
其中 Θ \boldsymbol{\Theta} Θ代表模型参数。同样地,如果每个样本只有一个标签,那么交叉熵损失可以简写成 ℓ ( Θ ) = − ( 1 / n ) ∑ i = 1 n log y ^ y ( i ) ( i ) \ell(\boldsymbol{\Theta}) = -(1/n) \sum_{i=1}^n \log \hat y_{y^{(i)}}^{(i)} ℓ(Θ)=−(1/n)∑i=1nlogy^y(i)(i)。从另一个角度来看,我们知道最小化 ℓ ( Θ ) \ell(\boldsymbol{\Theta}) ℓ(Θ)等价于最大化 exp ( − n ℓ ( Θ ) ) = ∏ i = 1 n y ^ y ( i ) ( i ) \exp(-n\ell(\boldsymbol{\Theta}))=\prod_{i=1}^n \hat y_{y^{(i)}}^{(i)} exp(−nℓ(Θ))=∏i=1ny^y(i)(i),即最小化交叉熵损失函数等价于最大化训练数据集所有标签类别的联合预测概率。
3.4.6 模型预测及评价
在训练好softmax回归模型后,给定任一样本特征,就可以预测每个输出类别的概率。通常,我们把预测概率最大的类别作为输出类别。如果它与真实类别(标签)一致,说明这次预测是正确的。在3.6节的实验中,我们将使用准确率(accuracy)来评价模型的表现。它等于正确预测数量与总预测数量之比。
小结
- softmax回归适用于分类问题。它使用softmax运算输出类别的概率分布。
- softmax回归是一个单层神经网络,输出个数等于分类问题中的类别个数。
- 交叉熵适合衡量两个概率分布的差异。
注:本节与原书基本相同,原书此节传送门
3.5. 图像分类数据集(Fashion-MNIST)
在介绍softmax回归的实现前我们先引入一个多类图像分类数据集。它将在后面的章节中被多次使用,以方便我们观察比较算法之间在模型精度和计算效率上的区别。图像分类数据集中最常用的是手写数字识别数据集MNIST [1]。但大部分模型在MNIST上的分类精度都超过了95%。为了更直观地观察算法之间的差异,我们将使用一个图像内容更加复杂的数据集Fashion-MNIST [2]。
3.5.1. 获取数据集
首先导入本节需要的包或模块。
import tensorflow as tf
from tensorflow import keras
import numpy as np
import time
import sys
import matplotlib.pyplot as plt
下面,我们通过keras的dataset包来下载这个数据集。第一次调用时会自动从网上获取数据。我们通过参数train来指定获取训练数据集或测试数据集(testing data set)。测试数据集也叫测试集(testing set),只用来评价模型的表现,并不用来训练模型。
from tensorflow.keras.datasets import fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
训练集中和测试集中的每个类别的图像数分别为6,000和1,000。因为有10个类别,所以训练集和测试集的样本数分别为60,000和10,000。
len(x_train),len(x_test)
(60000, 10000)
我们可以通过方括号[]来访问任意一个样本,下面获取第一个样本的图像和标签。
feature,label=x_train[0],y_train[0]
变量feature对应高和宽均为28像素的图像。每个像素的数值为0到255之间8位无符号整数(uint8)。它使用二维的numpy.ndarray存储。因为数据集中是灰度图像,所以只有两个维度,不需要第三个维度来区分通道。为了表述简洁,我们将高和宽分别为 h 和 w 像素的图像的形状记为 h×w 或(h,w)。
feature.shape, feature.dtype
((28, 28), dtype('uint8'))
图像的标签使用NumPy的标量表示。注意,在keras的fashion_mnist数据和原书mxnet提供的数据集有差别
label, type(label), label.dtype
(9, numpy.uint8, dtype('uint8'))
Fashion-MNIST中一共包括了10个类别,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。以下函数可以将数值标签转成相应的文本标签。
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
下面定义一个可以在一行里画出多张图像和对应标签的函数。
def show_fashion_mnist(images, labels):
_, figs = plt.subplots(1, len(images), figsize=(12, 12))
for f, img, lbl in zip(figs, images, labels):
f.imshow(img.reshape((28, 28)))
f.set_title(lbl)
f.axes.get_xaxis().set_visible(False)
f.axes.get_yaxis().set_visible(False)
plt.show()
现在,我们看一下训练数据集中前9个样本的图像内容和文本标签
X, y = [], []
for i in range(10):
X.append(x_train[i])
y.append(y_train[i])
show_fashion_mnist(X, get_fashion_mnist_labels(y))

3.5.2. 读取小批量
我们将在训练数据集上训练模型,并将训练好的模型在测试数据集上评价模型的表现。虽然我们可以像“线性回归的从零开始实现”一节中那样通过yield来定义读取小批量数据样本的函数,但为了代码简洁,这里我们直接创建DataLoader实例。该实例每次读取一个样本数为batch_size的小批量数据。这里的批量大小batch_size是一个超参数。
此外,我们通过ToTensor实例将图像数据从uint8格式变换成32位浮点数格式,并除以255使得所有像素的数值均在0到1之间。ToTensor实例还将图像通道从最后一维移到最前一维来方便之后介绍的卷积神经网络计算。通过数据集的transform_first函数,我们将ToTensor的变换应用在每个数据样本(图像和标签)的第一个元素,即图像之上。
batch_size = 256
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4
train_iter = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(256)
最后我们查看读取一遍训练数据需要的时间。
start = time.time()
for X, y in train_iter:
continue
print('%.2f sec' % (time.time() - start))
0.22 sec
3.5.3. 小结
- Fashion-MNIST是一个10类服饰分类数据集,之后章节里将使用它来检验不同算法的表现。
- 我们将高和宽分别为 h 和 w 像素的图像的形状记为 h×w 或(h,w)。
3.6 softmax回归的从零开始实现
这一节我们来动手实现softmax回归。首先导入本节实现所需的包或模块。
import tensorflow as tf
import numpy as np
print(tf.__version__)
输出:
2.0.0
3.6.1 获取和读取数据
我们将使用Fashion-MNIST数据集,并设置批量大小为256。
from tensorflow.keras.datasets import fashion_mnist
batch_size=256
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
x_train = tf.cast(x_train, tf.float32) / 255 #在进行矩阵相乘时需要float型,故强制类型转换为float型
x_test = tf.cast(x_test,tf.float32) / 255 #在进行矩阵相乘时需要float型,故强制类型转换为float型
train_iter = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(batch_size)
test_iter = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(batch_size)
3.6.2 初始化模型参数
跟线性回归中的例子一样,我们将使用向量表示每个样本。已知每个样本输入是高和宽均为28像素的图像。模型的输入向量的长度是 28 × 28 = 784 28 \times 28 = 784 28×28=784:该向量的每个元素对应图像中每个像素。由于图像有10个类别,单层神经网络输出层的输出个数为10,因此softmax回归的权重和偏差参数分别为 784 × 10 784 \times 10 784×10和 1 × 10 1 \times 10 1×10的矩阵。Variable来标注需要记录梯度的向量。
num_inputs = 784
num_outputs = 10
W = tf.Variable(tf.random.normal(shape=(num_inputs, num_outputs), mean=0, stddev=0.01, dtype=tf.float32))
b = tf.Variable(tf.zeros(num_outputs, dtype=tf.float32))
3.6.3 实现softmax运算
在介绍如何定义softmax回归之前,我们先描述一下对如何对多维Tensor按维度操作。在下面的例子中,给定一个Tensor矩阵X。我们可以只对其中同一列(axis=0)或同一行(axis=1)的元素求和,并在结果中保留行和列这两个维度(keepdims=True)。
X = tf.constant([[1, 2, 3], [4, 5, 6]])
tf.reduce_sum(X, axis=0, keepdims=True), tf.reduce_sum(X, axis=1, keepdims=True)
输出:
(<tf.Tensor: id=462401, shape=(1, 3), dtype=int32, numpy=array([[5, 7, 9]], dtype=int32)>,
<tf.Tensor: id=462403, shape=(2, 1), dtype=int32, numpy=
array([[ 6],
[15]], dtype=int32)>)
下面我们就可以定义前面小节里介绍的softmax运算了。在下面的函数中,矩阵logits的行数是样本数,列数是输出个数。为了表达样本预测各个输出的概率,softmax运算会先通过exp函数对每个元素做指数运算,再对exp矩阵同行元素求和,最后令矩阵每行各元素与该行元素之和相除。这样一来,最终得到的矩阵每行元素和为1且非负。因此,该矩阵每行都是合法的概率分布。softmax运算的输出矩阵中的任意一行元素代表了一个样本在各个输出类别上的预测概率。
def softmax(logits, axis=-1):
return tf.exp(logits)/tf.reduce_sum(tf.exp(logits), axis, keepdims=True)
可以看到,对于随机输入,我们将每个元素变成了非负数,且每一行和为1。
X = tf.random.normal(shape=(2, 5))
X_prob = softmax(X)
X_prob, tf.reduce_sum(X_prob, axis=1)
输出:
(<tf.Tensor: id=462414, shape=(2, 5), dtype=float32, numpy=
array([[0.07188913, 0.19016613, 0.21624805, 0.40005335, 0.12164329],
[0.20424965, 0.22559293, 0.13348413, 0.2243966 , 0.21227665]],
dtype=float32)>,
<tf.Tensor: id=462416, shape=(2,), dtype=float32, numpy=array([1. , 0.99999994], dtype=float32)>)
3.6.4 定义模型
有了softmax运算,我们可以定义上节描述的softmax回归模型了。这里通过view函数将每张原始图像改成长度为num_inputs的向量。
def net(X):
logits = tf.matmul(tf.reshape(X, shape=(-1, W.shape[0])), W) + b
return softmax(logits)
3.6.5 定义损失函数
上一节中,我们介绍了softmax回归使用的交叉熵损失函数。为了得到标签的预测概率,我们可以使用boolean_mask函数和one_hot函数。在下面的例子中,变量y_hat是2个样本在3个类别的预测概率,变量y是这2个样本的标签类别。通过使用gather函数,我们得到了2个样本的标签的预测概率。与3.4节(softmax回归)数学表述中标签类别离散值从1开始逐一递增不同,在代码中,标签类别的离散值是从0开始逐一递增的。
y_hat = np.array([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y = np.array([0, 2], dtype='int32')
tf.boolean_mask(y_hat, tf.one_hot(y, depth=3))
输出:
<tf.Tensor: id=462449, shape=(2,), dtype=float64, numpy=array([0.1, 0.5])>
下面实现了3.4节(softmax回归)中介绍的交叉熵损失函数。(注:由于在 Tensorflow 涉及运算类型转换的问题,使用cast函数对张量进行类型转换。)
def cross_entropy(y_hat, y):
y = tf.cast(tf.reshape(y, shape=[-1, 1]),dtype=tf.int32)
y = tf.one_hot(y, depth=y_hat.shape[-1])
y = tf.cast(tf.reshape(y, shape=[-1, y_hat.shape[-1]]),dtype=tf.int32)
return -tf.math.log(tf.boolean_mask(y_hat, y)+1e-8)
3.6.6 计算分类准确率
给定一个类别的预测概率分布y_hat,我们把预测概率最大的类别作为输出类别。如果它与真实类别y一致,说明这次预测是正确的。分类准确率即正确预测数量与总预测数量之比。
为了演示准确率的计算,下面定义准确率accuracy函数。其中tf.argmax(y_hat, axis=1)返回矩阵y_hat每行中最大元素的索引,且返回结果与变量y形状相同。相等条件判断式(tf.argmax(y_hat, axis=1) == y)是一个数据类型为bool的Tensor,实际取值为:0(相等为假)或 1(相等为真)。
def accuracy(y_hat, y):
return np.mean((tf.argmax(y_hat, axis=1) == y))
让我们继续使用在演示gather函数时定义的变量y_hat和y,并将它们分别作为预测概率分布和标签。可以看到,第一个样本预测类别为2(该行最大元素0.6在本行的索引为2),与真实标签0不一致;第二个样本预测类别为2(该行最大元素0.5在本行的索引为2),与真实标签2一致。因此,这两个样本上的分类准确率为0.5。
accuracy(y_hat, y)
输出:
0.5
类似地,我们可以评价模型net在数据集data_iter上的准确率。
# 描述,对于tensorflow2中,比较的双方必须类型都是int型,所以要将输出和标签都转为int型
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for _, (X, y) in enumerate(data_iter):
y = tf.cast(y,dtype=tf.int64)
acc_sum += np.sum(tf.cast(tf.argmax(net(X), axis=1), dtype=tf.int64) == y)
n += y.shape[0]
return acc_sum / n
因为我们随机初始化了模型net,所以这个随机模型的准确率应该接近于类别个数 10 的倒数即 0.1。
print(evaluate_accuracy(test_iter, net))
输出:
0.0834
3.6.7 训练模型
训练softmax回归的实现跟 3.2(线性回归的从零开始实现)一节介绍的线性回归中的实现非常相似。我们同样使用小批量随机梯度下降来优化模型的损失函数。在训练模型时,迭代周期数num_epochs和学习率lr都是可以调的超参数。改变它们的值可能会得到分类更准确的模型。
# 这里使用 1e-3 学习率,是因为原文 0.1 的学习率过大,会使 cross_entropy loss 计算返回 numpy.nan
num_epochs, lr = 5, 1e-3
# 本函数已保存在d2lzh包中方便以后使用
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size,
params=None, lr=None, trainer=None):
global sample_grads
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
with tf.GradientTape() as tape:
y_hat = net(X)
l = tf.reduce_sum(loss(y_hat, y))
grads = tape.gradient(l, params)
if trainer is None:
sample_grads = grads
params[0].assign_sub(grads[0] * lr)
params[1].assign_sub(grads[1] * lr)
else:
trainer.apply_gradients(zip(grads, params)) # “softmax回归的简洁实现”一节将用到
y = tf.cast(y, dtype=tf.float32)
train_l_sum += l.numpy()
train_acc_sum += tf.reduce_sum(tf.cast(tf.argmax(y_hat, axis=1) == tf.cast(y, dtype=tf.int64), dtype=tf.int64)).numpy()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
trainer = tf.keras.optimizers.SGD(lr)
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, batch_size, [W, b], lr)
输出:
epoch 1, loss 0.8969, train acc 0.736, test acc 0.813
epoch 2, loss 0.5987, train acc 0.806, test acc 0.826
epoch 3, loss 0.5524, train acc 0.820, test acc 0.832
epoch 4, loss 0.5297, train acc 0.826, test acc 0.834
epoch 5, loss 0.5139, train acc 0.830, test acc 0.836
3.6.8 预测
训练完成后,现在就可以演示如何对图像进行分类了。给定一系列图像(第三行图像输出),我们比较一下它们的真实标签(第一行文本输出)和模型预测结果(第二行文本输出)。
import matplotlib.pyplot as plt
X, y = iter(test_iter).next()
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
def show_fashion_mnist(images, labels):
# 这⾥的_表示我们忽略(不使⽤)的变量
_, figs = plt.subplots(1, len(images), figsize=(12, 12)) # 这里注意subplot 和subplots 的区别
for f, img, lbl in zip(figs, images, labels):
f.imshow(tf.reshape(img, shape=(28, 28)).numpy())
f.set_title(lbl)
f.axes.get_xaxis().set_visible(False)
f.axes.get_yaxis().set_visible(False)
plt.show()
true_labels = get_fashion_mnist_labels(y.numpy())
pred_labels = get_fashion_mnist_labels(tf.argmax(net(X), axis=1).numpy())
titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)]

小结
- 可以使用softmax回归做多类别分类。与训练线性回归相比,你会发现训练softmax回归的步骤和它非常相似:获取并读取数据、定义模型和损失函数并使用优化算法训练模型。事实上,绝大多数深度学习模型的训练都有着类似的步骤。
注:本节除了代码之外与原书基本相同,原书传送门
3.7 softmax回归的简洁实现
我们在3.3节(线性回归的简洁实现)中已经了解了使用Tensorflow2.0实现模型的便利。下面,让我们再次使用Tensorflow2.0来实现一个softmax回归模型。首先导入所需的包或模块。
import tensorflow as tf
from tensorflow import keras
3.7.1 获取和读取数据
我们仍然使用Fashion-MNIST数据集和上一节中设置的批量大小。
fashion_mnist = keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
对数据进行处理,归一化,便于训练
x_train = x_train / 255.0
x_test = x_test / 255.0
3.7.2 定义和初始化模型
在3.4节(softmax回归)中提到,softmax回归的输出层是一个全连接层。因此,我们添加一个输出个数为10的全连接层。 第一层是Flatten,将28 * 28的像素值,压缩成一行 (784, ) 第二层还是Dense,因为是多分类问题,激活函数使用softmax
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
3.7.3 softmax和交叉熵损失函数
如果做了上一节的练习,那么你可能意识到了分开定义softmax运算和交叉熵损失函数可能会造成数值不稳定。因此,Tensorflow2.0的keras API提供了一个loss参数。它的数值稳定性更好。
loss = 'sparse_categorical_crossentropy'
3.7.4 定义优化算法
我们使用学习率为0.1的小批量随机梯度下降作为优化算法。
optimizer = tf.keras.optimizers.SGD(0.1)
3.7.5 训练模型
接下来,我们使用上一节中定义的训练函数来训练模型。
model.compile(optimizer=tf.keras.optimizers.SGD(0.1),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train,y_train,epochs=5,batch_size=256)
输出:
Train on 60000 samples
Epoch 1/5
60000/60000 [==============================] - 1s 20us/sample - loss: 0.7941 - accuracy: 0.7408
Epoch 2/5
60000/60000 [==============================] - 1s 11us/sample - loss: 0.5729 - accuracy: 0.8112
Epoch 3/5
60000/60000 [==============================] - 1s 11us/sample - loss: 0.5281 - accuracy: 0.8241
Epoch 4/5
60000/60000 [==============================] - 1s 11us/sample - loss: 0.5038 - accuracy: 0.8296
Epoch 5/5
60000/60000 [==============================] - 1s 11us/sample - loss: 0.4866 - accuracy: 0.8351
接下来,比较模型在测试数据集上的表现情况
test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test Acc:',test_acc)
输出:
- 1s 55us/sample - loss: 0.4347 - accuracy: 0.8186
Test Acc: 0.8186
小结
- Tensorflow2.0提供的函数往往具有更好的数值稳定性。
- 可以使用Tensorflow2.0更简洁地实现softmax回归。
注:本节除了代码之外与原书基本相同,原书传送门