导读
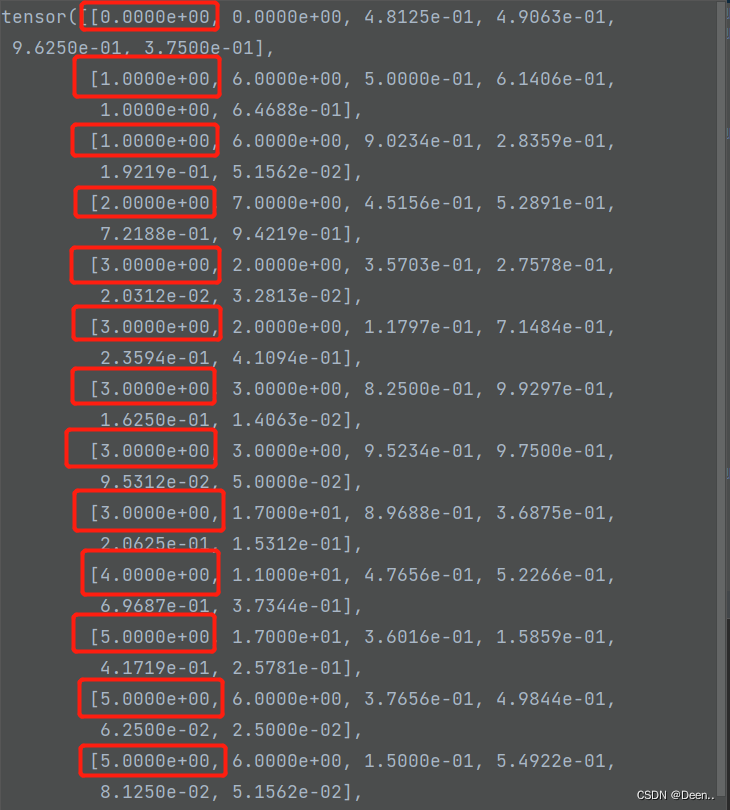
在SSD 中数据集加载的时候,就将真实框调整为用8732个锚框来表示,其格式为[8732,26]:
将真实框转换为相对锚框的偏移量
转化后的真实框用8732个锚框做偏移量来表示,26中前4位为坐标,第5位判断背景,中间20位为类别,最后一位判断目标。训练阶段求loss时候,预测框格式是[8732,25]前4位是坐标,第5位是背景,后面20位是类别。通过loss函数求预测框与真实框的差距。

Yolov7中数据加载部分仅将真实框的坐标进行归一化调整后,从[x,y,x,y]的格式转换为[x,y,w,h]的格式。还未与锚框进行匹配。其格式为[ids,类别,坐标],第一个值是标明该真实框属于哪张图。
我们可知道,图片进入模型后,将输出3个特征层,特征层的每个特征格有3个锚框,每个锚框有(5+numberclass)个值,则每个图层有 3 ∗ ( 5 + n u m b e r c l a s s ) 3*(5+numberclass) 3∗(5+numberclass),其中前4个是坐标,第5个是用来判断是目标的可信程度(置信度),最后numberclass用来判断是哪类,假设有20类,则 3 ∗ ( 5 + 20 ) = 85 3*(5+20)=85 3∗(5+20)=85检测头输出的3个图层的结果
P3 80, 80, 75
P4 40, 40, 75
P5 20, 20, 75
这里注意,做预测后对预测框做NMS极大值抑制的时候,置信度采用的是 目标置信度X类别置信度。
这个预测框输出结果跟真实框的是不一样的,所以需要将真实框通过中间介质(锚框)进行匹配,然后跟预测框的输出结果进行计算。
损失求解
在损失函数YOLOloss中有def call(self, predictions, targets, imgs)魔法方法,其作用为使得类实例对象可以像调用普通函数那样,以“对象名()”的形式使用。求解内容可以写在该函数下。
首先来看predictions、 targets样式。
predictions:
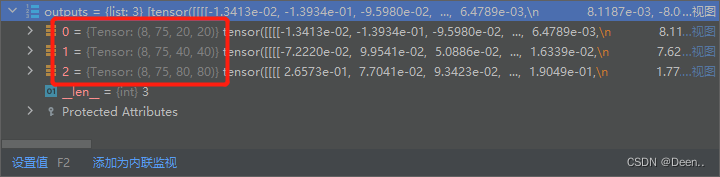
3个图层,每个图层有8张图片,不同图层有不同尺寸,且具有75个数值,75为 3 ∗ ( 5 + n u m b e r c l a s s ) 3*(5+numberclass) 3∗(5+numberclass)的结果。
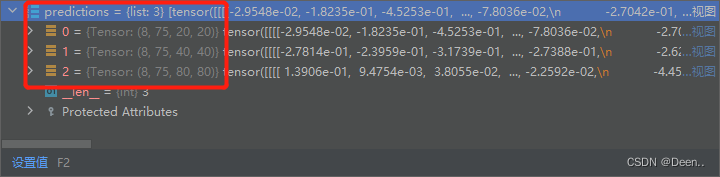
targets
格式为[number,6],第number是这一批8张图片一共有多少个真实框。

6的意思为[ids,类别,坐标],第1个值是标明该真实框属于哪张图。

按特征层处理
如上图所示,预测结果有3个特征层,在求解过程中,依次取出特征层后,对其按锚框数量进行shape调整。
# 对输入进来的预测结果进行reshape
# bs 是batch_size
# bs, 75, 20, 20 => bs, 3, 20, 20, 75
# bs, 75, 40, 40 => bs, 3, 40, 40, 75
# bs, 75, 80, 80 => bs, 3, 80, 80, 75
for i in range(len(predictions)):
bs, _, h, w = predictions[i].size()
predictions[i] = predictions[i].view(bs, len(self.anchors_mask[i]), -1, h, w).permute(0, 1, 3, 4, 2).contiguous()
正样本匹配,正样本锚框制备。
为了扩大正样本的数量,通过匹配策略,使更多的锚框跟真实框匹配上,也称为正样本匹配也就是找到这些被认为有对应真实框的锚框,用以负责这个真实框的预测。
1、通过真实框与锚框宽高比匹配,按照中心最近增加正样本数量
真实框格式为[number,6],三个图层分别处理,以一个图层为例。一个图层有3个锚框,所以使真实框增加维度到为[3,number,6],然后将真实框的宽高与3个锚框的宽高做比值,当比值在所设范围内,则认为该锚框可用来预测真实框。indices[b,c,grid_j,grid_i],anchor[所有正样本,2]即这个真实框属于第b张图,对应的网格左上角坐标为[grid_j,grid_i],其锚框的宽高由c去索引anchor[所有正样本,2]。
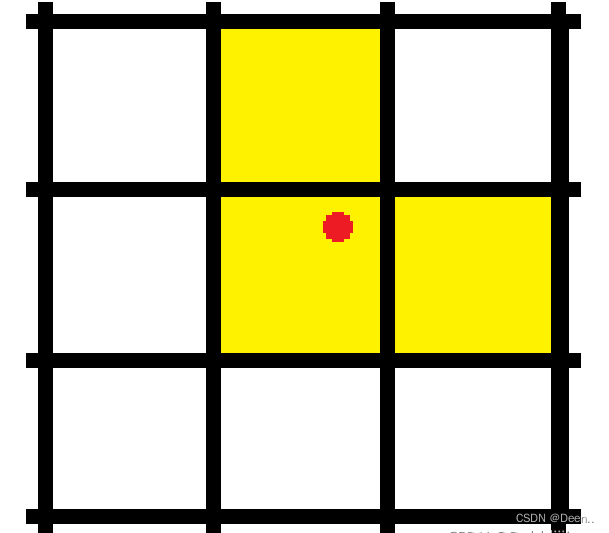
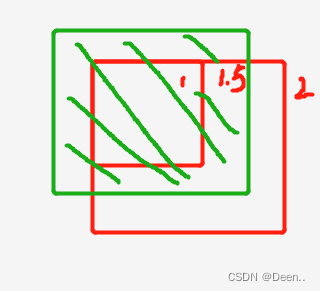
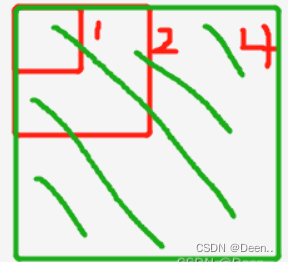
宽高比在一个范围内,如图所示,锚框为中间的红色方块,其内部与外部还有一个红色方块。内部与他的比值是1/4,外部与他的比值是4,令4倍为其所设范围。则真实框的宽高只要在内部与外部的范围内,则认为匹配上了,这个锚框就可以用来预测真实框。也就是途中绿色的框,图中黄色的框为匹配失败。
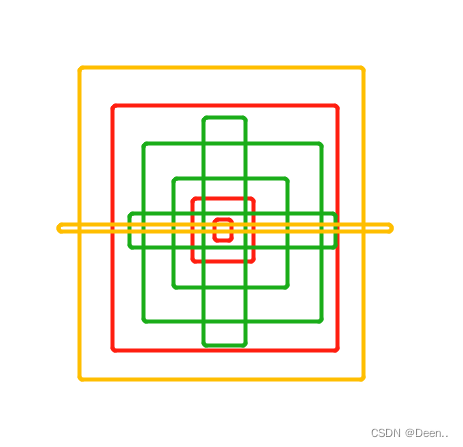
如此一来正样本的数量增多,为进一步增加正样本数量,使离真实框中心点最近的两个网格,也进行该真实框的预测。
如下图所示,三个网格中符合宽高比的锚框都被认为是正样本,用以负责真实框的预测。
具体的代码解读
num_anchor, num_gt = len(self.anchors_mask[0]), targets.shape[0]
self.anchors_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]] , targets = [43 , 6]
每个图层有3个大小不同的锚框,45个真实框
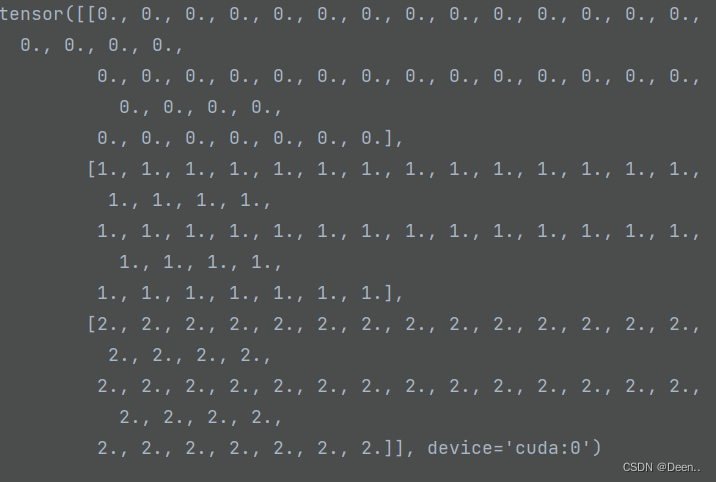
gain = torch.ones(7, device=targets.device)
下面对gain中间数进行赋值,gain=[1,1,20,20,20,20,1] 20是这个图层网格大小。做映射备用
ai = torch.arange(num_anchor, device=targets.device).float().view(num_anchor, 1).repeat(1, num_gt)
ai[3,43] ai为给taget增加维度,新增加的数可以用来判断,这个框属于这个图层中的哪个锚框。
targets = torch.cat((targets.repeat(num_anchor, 1, 1), ai[:, :, None]), 2) # append anchor indices
target [43,6] -->[3,43,7] 将真实框复制3份,一样对应不同大小的锚框,6->7加了一位ai,就是用来记录,这个真实框是属于3个锚框中的哪个。
g = 0.5 # offsets
off = torch.tensor([
[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g
g = 0.5 偏置用,也就是上图中寻找真实框中心点最近的两个网格,用到。
for i in range(len(predictions)):
取出一个图层 [8,3,20,20,25] 其实这里的predictions作用没那么大,就是提供了个数据类型,还有尺寸大小(2020,4040等),还有数量(3个图层)。因为这三点跟真实框必须是一样的。
anchors_i, shape = torch.from_numpy(self.anchors[i] / self.stride[i]).type_as(predictions[i])
, predictions[i].shape
找到图层锚框(真实值)/图层1个格子的长度。 anchors_i [3,2] 是对应图层单位长度的映射尺寸。
gain[2:6] = torch.tensor(predictions[i].shape)[[3, 2, 3, 2]]
获取这个图层的尺寸,这里是20,gain[1,1,20,20,20,20,1]
t = targets * gain
targets [3,43,7] 中坐标尺寸是归一化的结果,这里把target的尺寸按图层尺寸映射。
r = t[:, :, 4:6] / anchors_i[:, None]
r:[3,43,2]
anchors_i [3,1,2]
真实框锚框做比值。
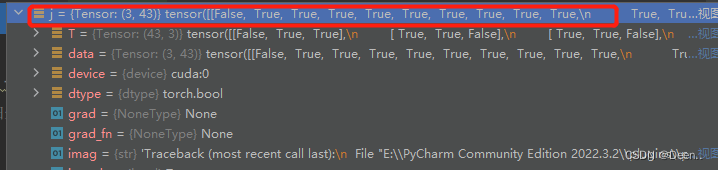
j = torch.max(r, 1. / r).max(2)[0] < self.threshold
j: [3,43] 比值大小小于 self.threshold 则认为有匹配 j是一个bool的tensor:
t = t[j] # filter
将满足比值的真实框选出 t [3,43,7]–>t :[97,7]
#-------------------------------------------#
# gxy 获得所有先验框对应的真实框的x轴y轴坐标
# gxi 取相对于该特征层的右小角的坐标
#-------------------------------------------#
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
#stack在新维度连接张量。
j = torch.stack((torch.ones_like(j), j, k, l, m))
gxy真实框中心点 gxi图层右下角相对真实框中心的距离。
j,k 与c,m是互补关系,j,k决定真实框中心在哪个象限(以左上角),(l,m是以右下角)。

j, k, l, m : [ 97] 都是97个。
j = torch.stack((torch.ones_like(j), j, k, l, m))
j: [5,97]
t = t.repeat((5, 1, 1))[j]
t: [97,7] -->[5,97,7] --> [292,7]
下图所示是 j: [5,97] 中第一位 5 的含义 j = torch.stack((torch.ones_like(j), j, k, l, m)) 97是97个真实框

(torch.ones_like(j) 全是1 如上图,则97个真实框全保留。

j -->保留gxy % 1后 x<0.5的真实框 :j, k = ((gxy % 1. < g) & (gxy > 1.)).T
k -->保留gxy % 1后 y<0.5的真实框 :j, k = ((gxy % 1. < g) & (gxy > 1.)).T
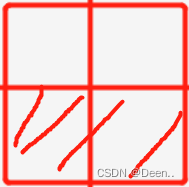
l -->保留gxi % 1后 l>0.5的真实框 :l, m = ((gxi % 1. < g) & (gxi > 1.)).T
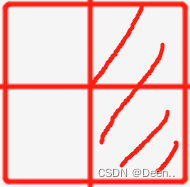
m -->保留gxi % 1后 m>0.5的真实框 :l, m = ((gxi % 1. < g) & (gxi > 1.)).T
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
五个方向。
#-------------------------------------------#
# b 代表属于第几个图片
# c 代表属于哪一类
# gxy 代表该真实框所处的x、y中心坐标
# gwh 代表该真实框的wh坐标
# gij 代表真实框所属的特征点坐标
#-------------------------------------------#
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices
gij = (gxy - offsets).long() 则离中心点最近的2个网格也参与正样本预测。 .long() 全部向下求整。即gij是网格的左上点。
a = t[:, 6].long() # anchor indices
# clamp()函数的功能将输入input张量每个元素的值压缩到区间 [min,max],并返回结果到一个新张量
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid indices
anchors.append(anchors_i[a]) # anchors
将这些匹配好的正样本放到列表里,再返回。
完整代码:
def find_3_positive(self, predictions, targets):
num_anchor, num_gt = len(self.anchors_mask[0]), targets.shape[0]
indices, anchors = [], []
#------------------------------------#
# 创建7个1
# 序号0,1为1
# 序号2:6为特征层的高宽
# 序号6为1
#------------------------------------#
gain = torch.ones(7, device=targets.device)
ai = torch.arange(num_anchor, device=targets.device).float().view(num_anchor, 1).repeat(1, num_gt)
targets = torch.cat((targets.repeat(num_anchor, 1, 1), ai[:, :, None]), 2) # append anchor indices
g = 0.5 # offsets
off = torch.tensor([
[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g
for i in range(len(predictions)):
anchors_i = torch.from_numpy(self.anchors[i] / self.stride[i]).type_as(predictions[i])
anchors_i, shape = torch.from_numpy(self.anchors[i] / self.stride[i]).type_as(predictions[i]), predictions[i].shape
gain[2:6] = torch.tensor(predictions[i].shape)[[3, 2, 3, 2]]
t = targets * gain
if num_gt:
r = t[:, :, 4:6] / anchors_i[:, None]
j = torch.max(r, 1. / r).max(2)[0] < self.threshold
t = t[j] # filter
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
#stack在新维度连接张量。
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid indices
anchors.append(anchors_i[a]) # anchors
return indices, anchors
宽高比匹配与中心位置偏移后得到的indices与anch如下图所示:
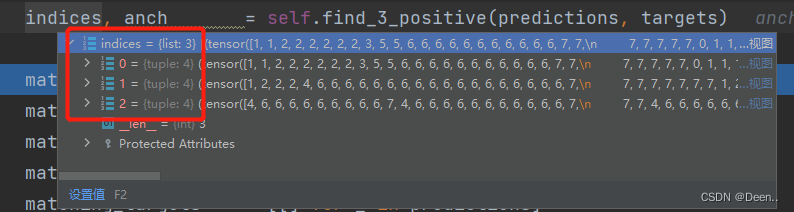
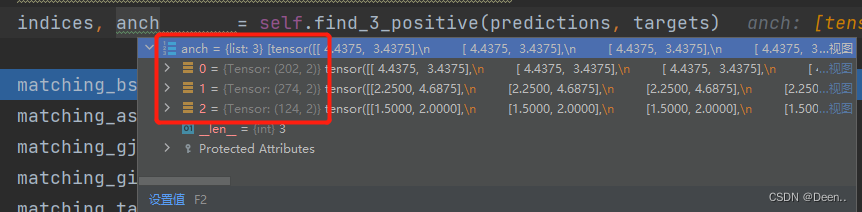
3个图层,每个图层中有4个值,分别是(b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1),每一组(b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1)代表这个匹配成功的正样本锚框属于第b张图,这个锚框的坐标对应这个图层中的(gi,gj)点,这个坐标点是用于预测的网格的左上角。这个锚框的宽高是通过a去检索anch中的宽高。
2、OTA匹配
找出正样本用来预测真实框的锚框后,进一步对这些锚框进行处理,精简的选出最合适的锚框。
大体思路为:
- 将归一化的真实框恢复到真实尺寸跟真实坐标
- 将初步挑选出的锚框与预测框匹配,找到与这些锚框对应的预测框,因为预测框是相对锚框做的偏移,预测框格式为[x,y,w,h]。所以将这些预测框进行解码,得到预测框的真实中心点与宽高。
- 让每个真实框与所有初步挑选的正样本对应的预测框进行iou计算,再将计算结果求和,求和结果取整后得到k值,这个k就是这个真实框所要选取的正样本锚框的数量。 一个真实框可以对应多个正样本,一个正样本锚框只能对应一个真实框。
- 再求每个真实框与所有初步挑选的正样本的目标类别损失计算,最后将iou损失跟目标类别损失求和,得到总损失cost。
- 将一个真实框与与所有初步挑选的正样本对应的预测框的cost计算结果进行排序,取出最小的k个值,这些值对应的锚框就是最后的正样本。
- 如果一个正样本对应多个真实框,就取出这个正样本,然后找到它跟多个真实框的cost值,找到最小的那个cost,让这个正样本去预测那个真实框。
代码细读:
对batch_size进行循环,进行OTA匹配
取出一张图,通过真实框的第1位去选取属于该图片的真实框。然后将真实框取出,因为真实框是归一化的结果,所以将其对应图片长度映射得到真实的尺寸,然后使得其格式从[x,y,w,h]–>[x,y,x,y]
num_layer = len(predictions)
#-------------------------------------------#
# 对batch_size进行循环,进行OTA匹配
# 在batch_size循环中对layer进行循环
#-------------------------------------------#
for batch_idx in range(predictions[0].shape[0]):
#-------------------------------------------#
# 先判断匹配上的真实框哪些属于该图片
#-------------------------------------------#
b_idx = targets[:, 0]==batch_idx
this_target = targets[b_idx]
#-------------------------------------------#
# 如果没有真实框属于该图片则continue
#-------------------------------------------#
if this_target.shape[0] == 0:
continue
#-------------------------------------------#
# 真实框的坐标进行缩放
#-------------------------------------------#
txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1]
#-------------------------------------------#
# 从中心宽高到左上角右下角
#-------------------------------------------#
txyxy = self.xywh2xyxy(txywh)
在batch_size循环中对layer进行循环。
之前匹配的锚框分布在三个layer中,遍历这些layer来将真实框跟那些锚框再次匹配。
b代表第几张图片 a代表第几个先验框,判断初步处理的正样本锚框是属于哪张图哪个图层的,取出正在处理的这张图片的所有正样本锚框。
在这里b的数量有9个,说明有9个正样本属于这张图的这个layer。
b, a, gj, gi = indices[i] #属于哪个图层
idx = (b == batch_idx) #属于哪张图

从预测结果中取出正样本网格对应的预测框。
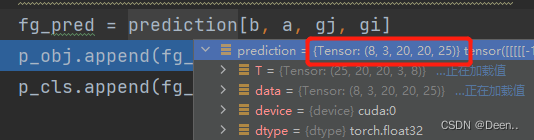
fg_pred = prediction[b, a, gj, gi]
p_obj.append(fg_pred[:, 4:5])
p_cls.append(fg_pred[:, 5:])
这张图的这个layer有9个正样本,则从预测结果中可以取出这9个正样本对应的预测框。
[9,25] : 25 = 5 + 20 25 = 5+20 25=5+20,5表示4个坐标点位与目标置信度,20是类别置信度。
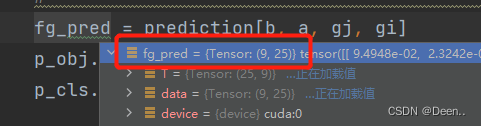
然后对取出的预测框进行解码:
预测的结果
解码公式:
将预测框的中心点通过sigmoid函数映射到(0,1)之间,然后乘2倍然后减0.5,将预测框中心点从(0,1)映射到(-0.5,1.5)
再加上这个网格的左上角点最后乘网格步长,得到这个预测框中心点的真实值。
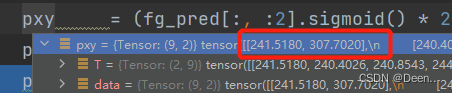
将预测框的宽高通过sigmoid映射到(0,1)之间,然后乘2再做平方,最后乘对应的锚框的宽高。得到预测框宽高真实值
将预测框的宽高从(0,1)映射到(0,4)上。

再将预测框的格式从[x,y,x,y]–>[x,y,w,h]
最后得到这9个预测框的真实中心点坐标跟真实宽高。
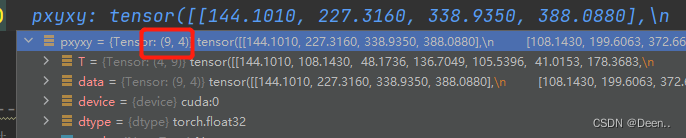
grid = torch.stack([gi, gj], dim=1).type_as(fg_pred)
pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i]
pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i]
pxywh = torch.cat([pxy, pwh], dim=-1)
pxyxy = self.xywh2xyxy(pxywh)
pxyxys.append(pxyxy)
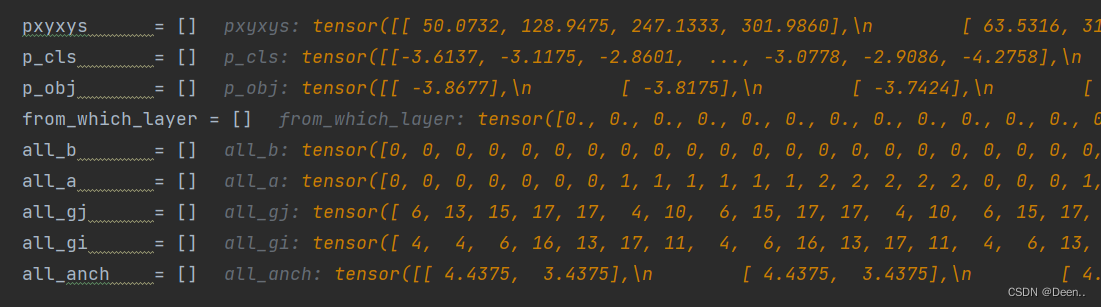
将之前做记录的内容按0维度torch在一起:
p_obj = torch.cat(p_obj, dim=0)
p_cls = torch.cat(p_cls, dim=0)
from_which_layer = torch.cat(from_which_layer, dim=0)
all_b = torch.cat(all_b, dim=0)
all_a = torch.cat(all_a, dim=0)
all_gj = torch.cat(all_gj, dim=0)
all_gi = torch.cat(all_gi, dim=0)
all_anch = torch.cat(all_anch, dim=0)
得到的内如如下图,就得到了正样本对应的预测框。
计算真实框跟预测框的iou
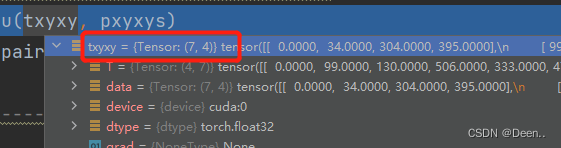
这时候的真实框跟预测框的格式就对上了,都是真实值,且都是[x,y,x,y]格式。
真实框是这张图里所有的真实框,预测框是通过正样本锚框挑选出来的预测框。
下图是真实框情况:这张图有7个真实框。
下图是预测框的情况,这张图3个图层有95个预测框
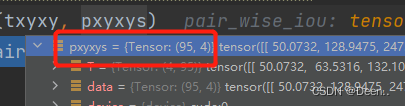
然后计算真实框跟预测框的iou
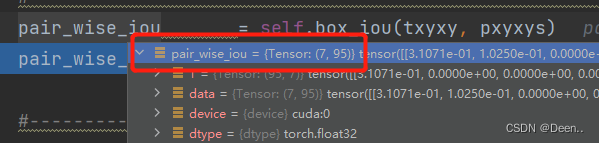
每个真实框都跟95个锚框求iou。得到[7,95] 。 7个真实框,95个iou值。
然后对这[7,95]的iou值进行大小排序。
找到与真实框iou最匹配的预测框,最多20个。
pair_wise_iou_loss是坐标的损失
#-------------------------------------------------------------#
# 计算当前图片中,真实框与预测框的重合程度
# iou的范围为0-1,取-log后为0~inf
# 重合程度越大,取-log后越小
# 因此,真实框与预测框重合度越大,pair_wise_iou_loss越小
#-------------------------------------------------------------#
pair_wise_iou = self.box_iou(txyxy, pxyxys)
pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8)
然后求和,找到每个真实框对应几个预测框,按iou排序的值求和,然后取整,值为多少,就让这个真实框对应多少个预测框。
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
gt_cls_per_image 种类的真实信息:
[7,95]个预测框对应的种类。
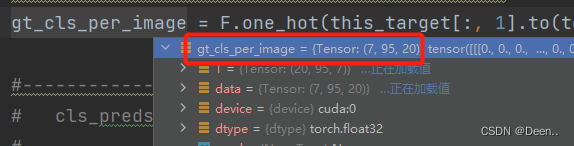
# gt_cls_per_image 种类的真实信息
#-------------------------------------------#
gt_cls_per_image = F.one_hot(this_target[:, 1].to(torch.int64), self.num_classes).float().unsqueeze(1).repeat(1, pxyxys.shape[0], 1)
计算种类置信度的损失:
cls_preds_ 种类置信度的预测信息, cls_preds_越接近于1,y越接近于1。 y / (1 - y)越接近于无穷大。也就是种类置信度预测的越准, pair_wise_cls_loss越小。下列cls_preds_ = p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() 中,用的是类的置信度乘是否有目标的置信度。repeat(num_gt, 1, 1)是为了一会将类损失与 真实框、正样本的iou损失求和,需要他们有一样的维度。
# cls_preds_ 种类置信度的预测信息
# cls_preds_越接近于1,y越接近于1
# y / (1 - y)越接近于无穷大
# 也就是种类置信度预测的越准
# pair_wise_cls_loss越小
#-------------------------------------------#
num_gt = this_target.shape[0]
cls_preds_ = p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
y = cls_preds_.sqrt_()
pair_wise_cls_loss = F.binary_cross_entropy_with_logits(torch.log(y / (1 - y)), gt_cls_per_image, reduction="none").sum(-1)
del cls_preds_
损失求和:真实框与正样本损失+种类置信度损失
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_iou_loss
)
7个真实框与95个正样本的损失情况。
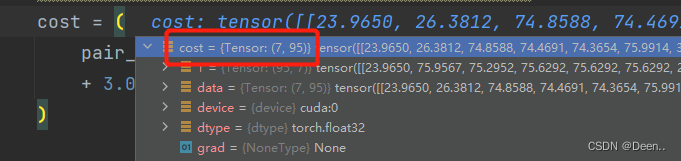
7个真实框如果用95个正样本来预测,正样本的数量太多了。所有选取损失值最小的k个样本来负责真实框的预测。这个k值就是[7,95]中,95个正样本的iou损失值求和取整的值。
# 求cost最小的k个预测框
#-------------------------------------------#
matching_matrix = torch.zeros_like(cost)
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False)
matching_matrix[gt_idx][pos_idx] = 1.0
del top_k, dynamic_ks
k值的获取。
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
完成这一步后,一个真实框就对应了多个预测框。
如果一个预测框对应多个真实框,只使用这个预测框最对应的真实框
下列代码沿着维度0求和,也就是计算,95个正样本,每个正样本分别负责几个真实框的预测。
anchor_matching_gt = matching_matrix.sum(0)
值为0时,这个正样本就不负责真实框的预测
如下图中,某一个正样本的值为2,意味着负责了两个真实框的预测,这种情况是不允许的。
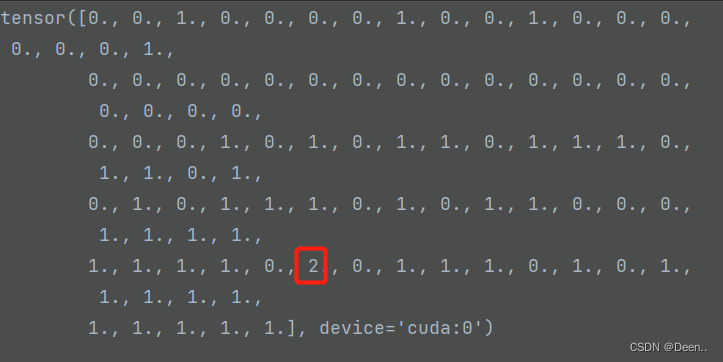
只使用这个正样本与真实框损失值cost最小的正样本进行预测。所以一个正样本锚框只能匹配一个真实框
anchor_matching_gt = matching_matrix.sum(0)
if (anchor_matching_gt > 1).sum() > 0:
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
cost[:, anchor_matching_gt > 1]找到负责2个以上真实框预测的正样本,这时候是[7,1]。7表示7个真实框,1表示这个正样本跟这7个真实框的cost损失值,找到损失值最小的那个torch.min(cost[:, anchor_matching_gt > 1], dim=0),返回的cost_argmin是cost最小的那个值所在的位置,比如在第5个位置,则这个正样本负责第5个真实框的预测。
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
是令[7,1]的这个位置的正样本不负责任何真实框的预测
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
上面这个代码是让[7,1]这位置的正样本,只负责cost值最小值的那个真实框的预测。
这里再重复一下正样本的意思:正样本是利用真实框与锚框宽高比,再做中心点位置偏移后选取到的多个锚框。其本质还是锚框。然后将利用这些锚框在图层中的位置,去选取预测结果中同样位置预测框认为这些预测框,将这些预测框相对锚框解码后,就粗略的认为这些预测框是正样本。
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
上面代码是寻找那些正样本有负责真实框的预测。95个正样本有些负责预测,有些不负责,不负责预测的就丢掉。如下图所示,False的这个正样本就不要了,True的就留下。

然后查看这些正样本分别负责哪个真实框的预测:

如上图所示,负责预测真实框的正样本有44个,第1个正样本负责第2个真实框的预测,以此类推。
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
取出符合条件的框,fg_mask_inboxes意味着95个预测框中哪些预测框有用,哪些预测框没用。
对应的把这些预测框的属性全取出来。
# 取出符合条件的框
#-------------------------------------------#
from_which_layer = from_which_layer.to(fg_mask_inboxes.device)[fg_mask_inboxes]
all_b = all_b[fg_mask_inboxes]
all_a = all_a[fg_mask_inboxes]
all_gj = all_gj[fg_mask_inboxes]
all_gi = all_gi[fg_mask_inboxes]
all_anch = all_anch[fg_mask_inboxes]
this_target = this_target[matched_gt_inds]
按layer将取出的正样本锚框写入列表里:
for i in range(num_layer):
layer_idx = from_which_layer == i
matching_bs[i].append(all_b[layer_idx])
matching_as[i].append(all_a[layer_idx])
matching_gjs[i].append(all_gj[layer_idx])
matching_gis[i].append(all_gi[layer_idx])
matching_targets[i].append(this_target[layer_idx])
matching_anchs[i].append(all_anch[layer_idx])
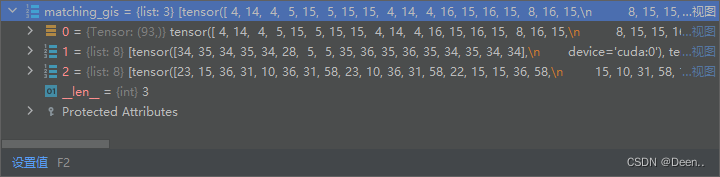
如下图所示,matching_as下有3个layer图层,以第一个图层为例子,第一个正样本锚框的框高尺寸属于这个图层中的第1个锚框。该图层中有3个锚框。

再将3个图层的内容,按图层内容的维度0也就是将各个图层内部的内容全部拼接到一起。用torch.cat()函数:
例如下图是正样本锚框的锚框尺寸,按0维度torch.cat()之后将打包起来。
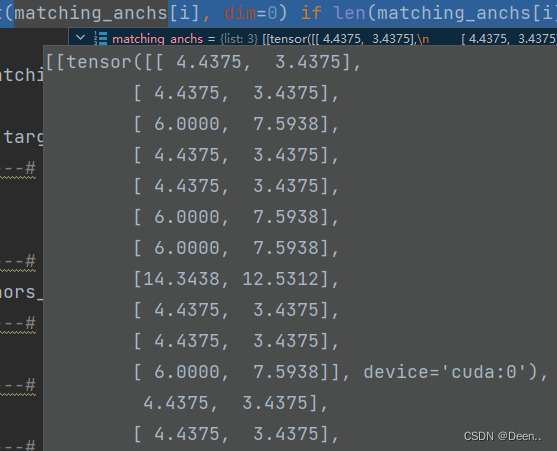
第1个layer是torch.cat()之后的结果。
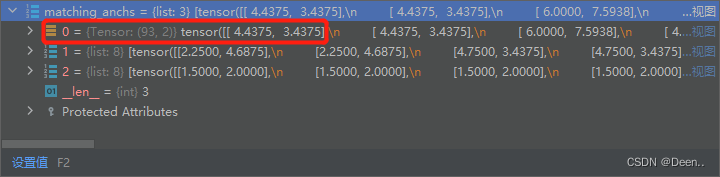
代码如下:
for i in range(num_layer):
matching_bs[i] = torch.cat(matching_bs[i], dim=0) if len(matching_bs[i]) != 0 else torch.Tensor(matching_bs[i])
matching_as[i] = torch.cat(matching_as[i], dim=0) if len(matching_as[i]) != 0 else torch.Tensor(matching_as[i])
matching_gjs[i] = torch.cat(matching_gjs[i], dim=0) if len(matching_gjs[i]) != 0 else torch.Tensor(matching_gjs[i])
matching_gis[i] = torch.cat(matching_gis[i], dim=0) if len(matching_gis[i]) != 0 else torch.Tensor(matching_gis[i])
matching_targets[i] = torch.cat(matching_targets[i], dim=0) if len(matching_targets[i]) != 0 else torch.Tensor(matching_targets[i])
matching_anchs[i] = torch.cat(matching_anchs[i], dim=0) if len(matching_anchs[i]) != 0 else torch.Tensor(matching_anchs[i])
正样本匹配后将值返回。
于是我们就得到了,正样本的数据,具体为一个正样本锚框,它属于那一张图片(matching_bs),它是这张图片中哪个图层的哪个锚框决定的(matching_as),它在图层中的网格位置(matching_gis,matching_gjs),以及它所对应的真实框(matching_targets),还有它对应的锚框尺寸( matching_anchs)。
return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs
下列93意味着是第0个layer图层有93个匹配成功正样本锚框。

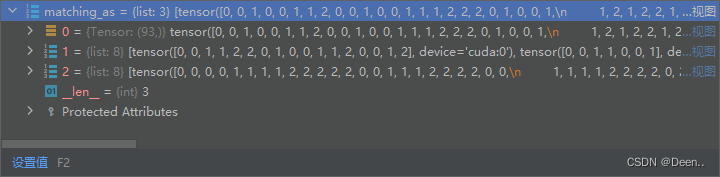
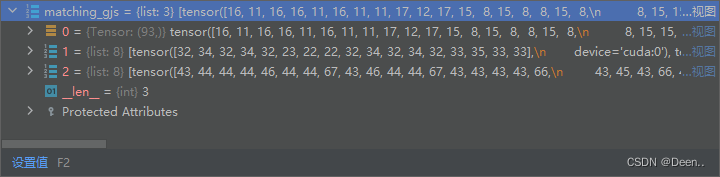

3个图层都匹配完后返回:
以下图举例,第0个图层有93个正样本锚框
以下图举例,第1个图层有145个正样本锚框
以下图举例,第2个图层有90个正样本锚框

全部代码:
bs, as_, gjs, gis, targets, anchors = self.build_targets(predictions, targets, imgs)
def build_targets(self, predictions, targets, imgs):
#-------------------------------------------#
# 匹配正样本
#-------------------------------------------#
indices, anch = self.find_3_positive(predictions, targets)
matching_bs = [[] for _ in predictions]
matching_as = [[] for _ in predictions]
matching_gjs = [[] for _ in predictions]
matching_gis = [[] for _ in predictions]
matching_targets = [[] for _ in predictions]
matching_anchs = [[] for _ in predictions]
#-------------------------------------------#
# 一共三层
#-------------------------------------------#
num_layer = len(predictions)
#-------------------------------------------#
# 对batch_size进行循环,进行OTA匹配
# 在batch_size循环中对layer进行循环
#-------------------------------------------#
for batch_idx in range(predictions[0].shape[0]):
#-------------------------------------------#
# 先判断匹配上的真实框哪些属于该图片
#-------------------------------------------#
b_idx = targets[:, 0]==batch_idx
this_target = targets[b_idx]
#-------------------------------------------#
# 如果没有真实框属于该图片则continue
#-------------------------------------------#
if this_target.shape[0] == 0:
continue
#-------------------------------------------#
# 真实框的坐标进行缩放
#-------------------------------------------#
txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1]
#-------------------------------------------#
# 从中心宽高到左上角右下角
#-------------------------------------------#
txyxy = self.xywh2xyxy(txywh)
pxyxys = []
p_cls = []
p_obj = []
from_which_layer = []
all_b = []
all_a = []
all_gj = []
all_gi = []
all_anch = []
#-------------------------------------------#
# 对三个layer进行循环
#-------------------------------------------#
for i, prediction in enumerate(predictions):
#-------------------------------------------#
# b代表第几张图片 a代表第几个先验框
# gj代表y轴,gi代表x轴
#-------------------------------------------#
b, a, gj, gi = indices[i]
idx = (b == batch_idx)
b, a, gj, gi = b[idx], a[idx], gj[idx], gi[idx]
all_b.append(b)
all_a.append(a)
all_gj.append(gj)
all_gi.append(gi)
all_anch.append(anch[i][idx])
from_which_layer.append(torch.ones(size=(len(b),)) * i)
#-------------------------------------------#
# 取出这个真实框对应的预测结果
#-------------------------------------------#
fg_pred = prediction[b, a, gj, gi]
p_obj.append(fg_pred[:, 4:5])
p_cls.append(fg_pred[:, 5:])
#-------------------------------------------#
# 获得网格后,进行解码
#-------------------------------------------#
grid = torch.stack([gi, gj], dim=1).type_as(fg_pred)
pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i]
pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i]
pxywh = torch.cat([pxy, pwh], dim=-1)
pxyxy = self.xywh2xyxy(pxywh)
pxyxys.append(pxyxy)
#-------------------------------------------#
# 判断是否存在对应的预测框,不存在则跳过
#-------------------------------------------#
pxyxys = torch.cat(pxyxys, dim=0)
if pxyxys.shape[0] == 0:
continue
#-------------------------------------------#
# 进行堆叠
#-------------------------------------------#
p_obj = torch.cat(p_obj, dim=0)
p_cls = torch.cat(p_cls, dim=0)
from_which_layer = torch.cat(from_which_layer, dim=0)
all_b = torch.cat(all_b, dim=0)
all_a = torch.cat(all_a, dim=0)
all_gj = torch.cat(all_gj, dim=0)
all_gi = torch.cat(all_gi, dim=0)
all_anch = torch.cat(all_anch, dim=0)
#-------------------------------------------------------------#
# 计算当前图片中,真实框与预测框的重合程度
# iou的范围为0-1,取-log后为0~inf
# 重合程度越大,取-log后越小
# 因此,真实框与预测框重合度越大,pair_wise_iou_loss越小
#-------------------------------------------------------------#
pair_wise_iou = self.box_iou(txyxy, pxyxys)
pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8)
#-------------------------------------------#
# 最多二十个预测框与真实框的重合程度
# 然后求和,找到每个真实框对应几个预测框
#-------------------------------------------#
top_k, _ = torch.topk(pair_wise_iou, min(20, pair_wise_iou.shape[1]), dim=1)
#将输入input张量每个元素的夹紧到区间 [min,max][min,max],并返回结果到一个新张量。
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
#-------------------------------------------#
# gt_cls_per_image 种类的真实信息
#-------------------------------------------#
gt_cls_per_image = F.one_hot(this_target[:, 1].to(torch.int64), self.num_classes).float().unsqueeze(1).repeat(1, pxyxys.shape[0], 1)
#-------------------------------------------#
# cls_preds_ 种类置信度的预测信息
# cls_preds_越接近于1,y越接近于1
# y / (1 - y)越接近于无穷大
# 也就是种类置信度预测的越准
# pair_wise_cls_loss越小
#-------------------------------------------#
num_gt = this_target.shape[0]
cls_preds_ = p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
y = cls_preds_.sqrt_()
pair_wise_cls_loss = F.binary_cross_entropy_with_logits(torch.log(y / (1 - y)), gt_cls_per_image, reduction="none").sum(-1)
del cls_preds_
#-------------------------------------------#
# 求cost的总和
#-------------------------------------------#
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_iou_loss
)
#-------------------------------------------#
# 求cost最小的k个预测框
#-------------------------------------------#
matching_matrix = torch.zeros_like(cost)
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False)
matching_matrix[gt_idx][pos_idx] = 1.0
del top_k, dynamic_ks
#-------------------------------------------#
# 如果一个预测框对应多个真实框
# 只使用这个预测框最对应的真实框
#-------------------------------------------#
anchor_matching_gt = matching_matrix.sum(0)
if (anchor_matching_gt > 1).sum() > 0:
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
#-------------------------------------------#
# 取出符合条件的框
#-------------------------------------------#
from_which_layer = from_which_layer.to(fg_mask_inboxes.device)[fg_mask_inboxes]
all_b = all_b[fg_mask_inboxes]
all_a = all_a[fg_mask_inboxes]
all_gj = all_gj[fg_mask_inboxes]
all_gi = all_gi[fg_mask_inboxes]
all_anch = all_anch[fg_mask_inboxes]
this_target = this_target[matched_gt_inds]
for i in range(num_layer):
layer_idx = from_which_layer == i
matching_bs[i].append(all_b[layer_idx])
matching_as[i].append(all_a[layer_idx])
matching_gjs[i].append(all_gj[layer_idx])
matching_gis[i].append(all_gi[layer_idx])
matching_targets[i].append(this_target[layer_idx])
matching_anchs[i].append(all_anch[layer_idx])
for i in range(num_layer):
matching_bs[i] = torch.cat(matching_bs[i], dim=0) if len(matching_bs[i]) != 0 else torch.Tensor(matching_bs[i])
matching_as[i] = torch.cat(matching_as[i], dim=0) if len(matching_as[i]) != 0 else torch.Tensor(matching_as[i])
matching_gjs[i] = torch.cat(matching_gjs[i], dim=0) if len(matching_gjs[i]) != 0 else torch.Tensor(matching_gjs[i])
matching_gis[i] = torch.cat(matching_gis[i], dim=0) if len(matching_gis[i]) != 0 else torch.Tensor(matching_gis[i])
matching_targets[i] = torch.cat(matching_targets[i], dim=0) if len(matching_targets[i]) != 0 else torch.Tensor(matching_targets[i])
matching_anchs[i] = torch.cat(matching_anchs[i], dim=0) if len(matching_anchs[i]) != 0 else torch.Tensor(matching_anchs[i])
return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs
def find_3_positive(self, predictions, targets):
#------------------------------------#
# 获得每个特征层先验框的数量
# 与真实框的数量
#------------------------------------#
num_anchor, num_gt = len(self.anchors_mask[0]), targets.shape[0]
#------------------------------------#
# 创建空列表存放indices和anchors
#------------------------------------#
indices, anchors = [], []
#------------------------------------#
# 创建7个1
# 序号0,1为1
# 序号2:6为特征层的高宽
# 序号6为1
#------------------------------------#
gain = torch.ones(7, device=targets.device)
#------------------------------------#
# ai [num_anchor, num_gt]
# targets [num_gt, 6] => [num_anchor, num_gt, 7]
#------------------------------------#
#repeat,将要重复的张量当成一个单位进行复制。
#ai给target加了一个值,从targets [num_gt, 6] => [num_anchor, num_gt, 7] ,7中最后一个数用来标记这个框是哪个图层的。
ai = torch.arange(num_anchor, device=targets.device).float().view(num_anchor, 1).repeat(1, num_gt)
#Tensor中利用None来增加维度,可以简单的理解为在None的位置上增加一维,新增维度大小为1,同时有几个None就会增加几个维度。
targets = torch.cat((targets.repeat(num_anchor, 1, 1), ai[:, :, None]), 2) # append anchor indices
g = 0.5 # offsets
off = torch.tensor([
[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g
for i in range(len(predictions)):
#----------------------------------------------------#
# 将先验框除以stride,获得相对于特征层的先验框。
# anchors_i [num_anchor, 2]
#----------------------------------------------------#
anchors_i = torch.from_numpy(self.anchors[i] / self.stride[i]).type_as(predictions[i])
#type_as按给定的tensor确定转换的数据类型(类似float32)–如果类型相同则不做改变–否则改为传入的tensor类型–并返回类型改变的tensor数据。
anchors_i, shape = torch.from_numpy(self.anchors[i] / self.stride[i]).type_as(predictions[i]), predictions[i].shape
#-------------------------------------------#
# 计算获得对应特征层的高宽
#-------------------------------------------#
gain[2:6] = torch.tensor(predictions[i].shape)[[3, 2, 3, 2]]
#-------------------------------------------#
# 将真实框乘上gain,
# 其实就是将真实框映射到特征层上
#-------------------------------------------#
t = targets * gain
if num_gt:
#-------------------------------------------#
# 计算真实框与先验框高宽的比值
# 然后根据比值大小进行判断,
# 判断结果用于取出,获得所有先验框对应的真实框
# r [num_anchor, num_gt, 2]
# t [num_anchor, num_gt, 7] => [num_matched_anchor, 7]
#-------------------------------------------#
r = t[:, :, 4:6] / anchors_i[:, None]
#真实框的宽高跟锚框的框高做比值,然后选取比值最大的那个,与阈值对比,如果小于阈值就保留,这里阈值选4
j = torch.max(r, 1. / r).max(2)[0] < self.threshold
t = t[j] # filter
#-------------------------------------------#
# gxy 获得所有先验框对应的真实框的x轴y轴坐标
# gxi 取相对于该特征层的右小角的坐标
#-------------------------------------------#
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
#stack在新维度连接张量。
j = torch.stack((torch.ones_like(j), j, k, l, m))
#-------------------------------------------#
# t 重复5次,使用满足条件的j进行框的提取
# j 一共五行,代表当前特征点在五个
# [0, 0], [1, 0], [0, 1], [-1, 0], [0, -1]
# 方向是否存在
#-------------------------------------------#
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
#-------------------------------------------#
# b 代表属于第几个图片
# c 代表属于哪一类
# gxy 代表该真实框所处的x、y中心坐标
# gwh 代表该真实框的wh坐标
# gij 代表真实框所属的特征点坐标
#-------------------------------------------#
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices
#-------------------------------------------#
# gj、gi不能超出特征层范围
# a代表属于该特征点的第几个先验框
#-------------------------------------------#
a = t[:, 6].long() # anchor indices
# clamp()函数的功能将输入input张量每个元素的值压缩到区间 [min,max],并返回结果到一个新张量
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid indices
anchors.append(anchors_i[a]) # anchors
return indices, anchors