点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:骚骚骚 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/543160484

YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
论文:https://arxiv.org/abs/2207.02696
代码:https://github.com/WongKinYiu/yolov7
整体上在正负样本分配中,yolov7的策略算是yolov5和YOLOX的结合。
首先大概回顾一下yolov5和YOLOX正负样本分配。
由于笔者能力有限,文章中可能出现一些错误,欢迎大家指出。
一、YOLOv5 正负样本分配策略
在我之前的文章中有详细介绍:
https://zhuanlan.zhihu.com/p/477598659
步骤:
步骤①:anchors和gt匹配,看哪些gt是当前特征图的正样本
步骤②:将当前特征图的正样本分配给对应的grid

那么其特点是:
①anchor base。
②一个gt可能会和多个anchor进行匹配。
③某个anchor与gt匹配上,都会在当前anchor上有3个正样本。(理论上如果有9个anchor,那么一个gt至多可能生成9*3=27个正样本)
二、YOLOX 正负样本分配策略
在我之前的文章中有详细介绍:
https://zhuanlan.zhihu.com/p/394392992

那么其特点是:
①anchor free。
②simOTA能够做到自动的分析每个gt要拥有多少个正样本。
③能自动决定每个gt要从哪个特征图来检测。
三、yolov7正负样本分配策略
首先,yolov7也仍然是anchor base的目标检测算法,yolov7将yolov5和YOLOX中的正负样本分配策略进行结合,流程如下:
①yolov5:使用yolov5正负样本分配策略分配正样本。
②YOLOX:计算每个样本对每个GT的Reg+Cla loss(Loss aware)
③YOLOX:使用每个GT的预测样本确定它需要分配到的正样本数(Dynamic k)
④YOLOX:为每个GT取loss最小的前dynamic k个样本作为正样本
⑤YOLOX:人工去掉同一个样本被分配到多个GT的正样本的情况(全局信息)
其实主要是将simOTA中的第一步“使用中心先验”替换成“yolov5中的策略”。
代码中也大量的复用了yolov5和YOLOX中的源码。
个人感觉,yolov5策略与YOLOX中simOTA策略的融合,相较于只使用yolov5策略,加入了loss aware,利用当前模型的表现,能够再进行一次精筛。而融合策略相较于只使用YOLOX中simOTA,能够提供更精确的先验知识。
yolov6等工作中也都使用了simOTA作为分配策略,可见simOTA确实是能带来很大提升的策略。
四、YOLOv7中AUX HEAD
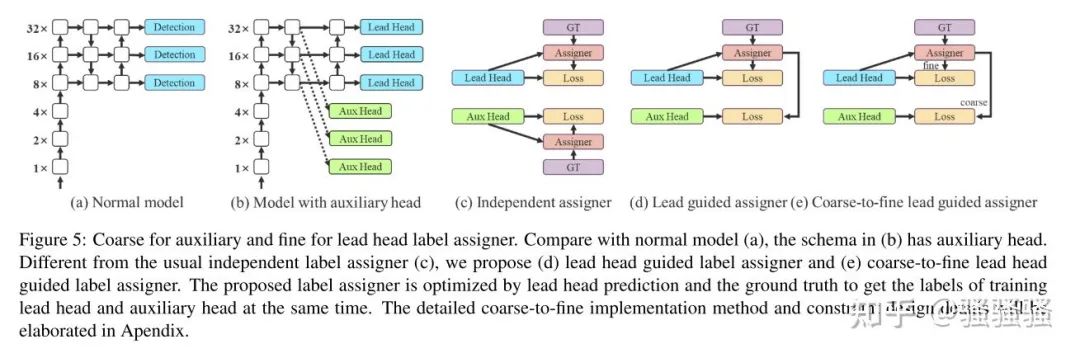
yolov7中的p6 model中都使用了aux head。
论文中提到使用aux head与lead head共同进行模型优化,而aux head的标签是较为“粗糙的“。
通过查看源码,发现aux head的assigner和lead head的assigner仅存在很少的不同,包括:
①lead head中每个anchor与gt如果匹配上,分配3个正样本,而aux head分配5个。
②lead head中将top10个样本iou求和取整,而aux head中取top20。
这也印证了论文中的观点。aux head不那么strong,aux head更关注于recall,而lead head从aux head中精准筛选出样本。

按照yolov7中的这个正负样本分配方式,那么针对图5中,蓝色点代表着gt所处的位置,实线组成的网格代表着特征图grid,虚线代表着一个grid分成了4个象限以进行正负样本分配(不理解的需要去看下yolov5的assign方式)。
如果一个gt位于蓝点位置,那么在lead head中,黄色grid将成为正样本。在aux head中,黄色+橙色grid将成为正样本。
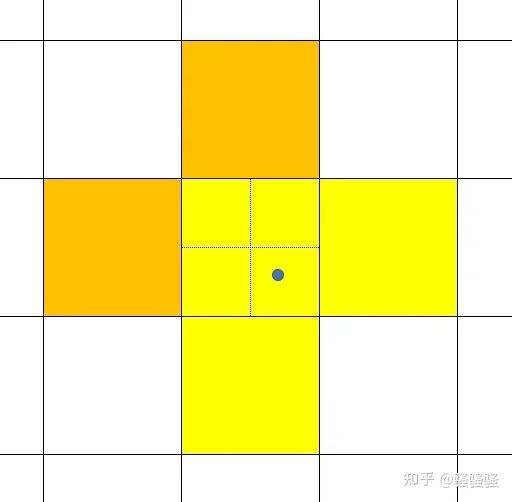
而在推理时,下图6中,蓝色点代表着gt所处的位置,实线组成的网格代表着特征图grid,虚线代表着一个grid分成了4个象限,而依照yolov5中的中心点回归方式,仅能将图中红色特征grid,预测在图中红色+蓝色区域,是根本无法将中心点预测到gt处的!而该红色特征grid在训练时是会作为正样本的。
在aux head中,模型也并没有针对这种情况对回归方式作出更改。所以其实在aux head中,即使被分配为正样本的区域,经过不断的学习,可能仍然无法完全拟合至效果特别好。

而在loss融合方面,aux head loss 和lead head loss 按照0.25:1的比例进行融合。
YOLOv7 论文和代码下载
后台回复:YOLOv7,即可下载上面论文和代码目标检测交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看