学习笔记_基于pytorch的YOLOv7 - day2阅读论文梳理概念
话接上文 讲到了YOLOv7的网络结构,今天继续。
第三章 网络结构
3.1 扩展加宽的高效层聚合网络(续)
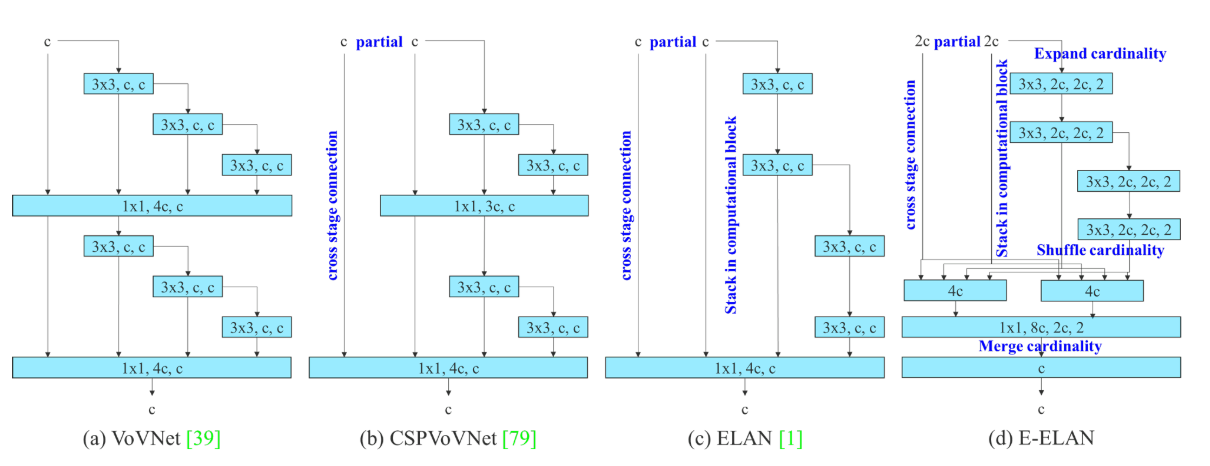
YOLOv7中所用到的网络E-ELAN中涉及到了Partial Convolutional(部分卷积)、cross stage connection(交叉连接)、stack in computational block(堆叠的计算块)、Expand cardinality(扩展基数)、Shuffle cardinality(洗牌基数)、Merge cardinality(合并基数)。
E-ELAN采用扩展、洗牌、合并基数等方法,在不破坏原有梯度路径的前提下,将网络分成多个组加宽了网络的宽度并且将提取到的特征随机组合,不断增强网络的学习能力。与ELAN相比E-ELAN只改变了计算块上的体系结构,而过渡层的体系结构完全不变。 使用群卷积来扩展计算块的信道和基数来扩展加宽网络。
3.2 级联模型的模型缩放
模型缩放的主要目的是调整模型的某些属性,生成不同尺度的模型,以满足不同推理速度的需要。当缩放一个计算块的深度因子时,还必须计算该块输出通道的变化。 然后,将在过渡层上执行宽度因子缩放,以相同的变化量进行缩放。
第四章 可训练的好用方法(bag-of-freebies)
4.1 重新参数化卷积
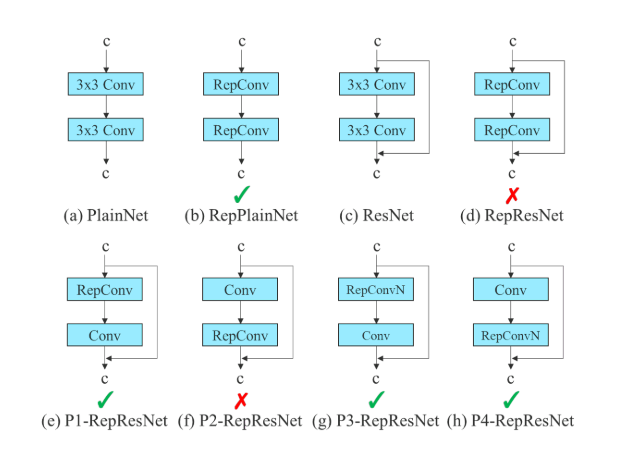
RepConv 将 3×3 卷积、1×1 卷积和恒等连接组合在一个卷积层中。但 RepConv 中的恒等连接破坏了 ResNet 中的残差和 DenseNet 中的连接,因此文中提出了RepConvN。
RepConvN:当一个带有残差或连接的卷积层被重新参数化的卷积代替时,应该没有恒等连接。
4.2 标签分配(粗为辅助,细为主要损失)
YOLOv7中使用的深度监督,深度监督就是在深度神经网络的某些中间隐藏层加了一个辅助的分类器作为一种网络分支来对主干网络进行监督。YOLOv将负责最终输出的分类器称为导头(lead head),用于辅助训练的分类器称为辅助头(auxiliary head),每个分类器都给了不同的标签来计算损失。将网络预测结果与基本事实一起考虑,生成了分配软标签的机制-“标签分配器”。
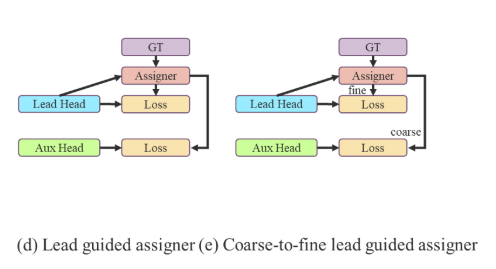
(d)由导头引导分配 (c)由前导头引导分配(由粗到细)
首先通过导头预测来引导辅助头和先导头。换句话说,我们使用前导头预测作为指导来生成由粗到细的层次标签,分别用于辅助头和前导头学习。两种拟议的深度监督标签分配策略分别如图5(d)和(e)所示。
4.3 其他的的bag-of-freebies
这部分不是由作者提出的在附录中有详细阐述。
(1) 批处理规范化
(2) Yolor中的隐含知识与卷积特征图以加法和乘法的方式结合
(3) EMA模型
YOLOv7各个版本
我们为边缘GPU、普通GPU和云GPU设计了基本模型,分别称为Yolov7Tiny、Yolov7和Yolov7-W6。同时,我们还针对不同的服务需求,使用基本模型进行模型缩放,得到不同类型的模型。对于YOLOV7,我们对颈部进行叠加缩放,并使用所提出的复合缩放方法对整个模型的深度和宽度进行放大,并使用该方法获得YOLOV7-X。对于YOLOV7-W6,我们使用新提出的复合标度方法来获得YOLOV7-E6和YOLLV7-D6。此外,我们将所提出的EELAN用于YOLOV7-E6,从而完成YOLOV7E6E。由于YOLOV7-TINY是一个面向边缘GPU的架构,它将使用Leaky ReLU作为激活函数。
根据情况我选择下载了最初始版本
第四章到此结束拉,明天开始进行项目部署,下次再见!