day1阅读论文重点梳理
参考文章: YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time objectdetectors
YOLOv7 源码在这里!
这是22年7月最新出的算法YOLOv7,我准备从阅读论文开始,对网络中用到的所有算法和知识点进行逐个总结记录,最后再对源码进行分析,和大家一起学习。
摘要
YOLOv7 在 5 FPS 到 160 FPS 范围内的速度和精度都超过了所有已知的物体检测器,并且在 GPU V100 上具有 30 FPS 或更高的所有已知实时物体检测器中具有最高的精度 56.8% AP。具体情况如图:

与其他实时目标检测器的比较,YOLOv7实现了最先进的性能。
第一章 介绍
- 实时对象检测是计算机视觉中非常重要的主题,因为它通常是计算机视觉系统中的必要组件。目标检测器YOLOv7主要希望它能够同时支持移动 GPU 和从边缘到云端的 GPU 设备。
- 本文提出的方法的发展方向与当前主流的实时目标检测器不同。除了架构优化之外,我们提出的方法将专注于训练过程的优化。我们的重点将放在一些优化的模块和优化方法上,它们可能会增加训练成本以提高目标检测的准确性,但不会增加推理成本。我们将提出的模块和优化方法称为可训练的免费赠品袋(bag-of-freebies)。
- 最近,模型重新参数化(model re-parameterization)和动态标签分配(dynamic label assignment)已成为网络训练和目标检测的重要课题。主要是在上述新概念提出之后,物体检测器的训练演变出了很多新的问题。在本文中,我们将介绍我们发现的一些新问题,并设计解决这些问题的有效方法。
本文的贡献总结:
(1) 我们设计了几种可训练的bag-of-freebies方法,使得实时目标检测可以在不增加推理成本的情况下大大提高检测精度;
(2) 对于目标检测方法的演进,我们发现了两个新问题,即重新参数化的模块如何替换原始模块,以及动态标签分配策略如何处理分配给不同输出层的问题。此外,我们还提出了解决这些问题所带来的困难的方法;
(3) 我们提出了实时目标检测器的“扩展”和“复合缩放”方法,可以有效地利用参数和计算;
(4) 我们提出的方法可以有效减少最先进的实时目标检测器约40%的参数和50%的计算量,并且具有更快的推理速度和更高的检测精度。
第二章 相关工作
2.1 实时物体检测器
目前最先进的实时目标检测器主要基于 YOLO 和 FCOS .能够成为最先进的实时目标检测器通常需要以下特性:
(1)更快更强的网络架构;
(2) 更有效的特征整合方法;
(3) 更准确的检测方法;
(4) 更稳健的损失函数 ;
(5) 一种更有效的标签分配方法 ;
(6) 更有效的训练方法。
在本文中,将针对与上述 (4)、(5) 和 (6) 相关的最先进方法衍生的问题设计新的可训练免费赠品方法。
2.2.模型重新参数化
模型重新参数化是在推理阶段将多个计算模块合并为一个。有两种方法,即模块级集成和模型级集成:
- 模型级重新参数化有两种做法来获得最终的推理模型。一种是用不同的训练数据训练多个相同的模型,然后对多个训练模型的权重进行平均。另一种是对不同迭代次数的模型权重进行加权平均。
- 模块级重新参数化是最近比较热门的研究问题。这种方法在训练时将一个模块拆分为多个相同或不同的模块分支,在推理时将多个分支模块整合为一个完全等效的模块。
2.3.模型缩放
模型缩放是一种放大或缩小已设计模型并使其适合不同计算设备的方法。模型缩放方法通常使用不同的缩放因子,例如分辨率(输入图像的大小)、深度(层数)、宽度(通道数)和阶段(特征金字塔的数量),从而在网络参数量、计算量、推理速度和准确率之间取得良好的折衷。
网络架构搜索(NAS),优点:而无需定义过于复杂的规则;
缺点:需要非常昂贵的计算来完成对模型缩放因子的搜索
第三章 网络结构
3.1 扩展的高效层聚合网络

CSPVoVNet [79] 的设计是 VoVNet [39] 的变体。CSPVoVNet [79] 的架构分析了梯度路径,以使不同层的权重能够学习更多不同的特征。上述梯度分析方法使推理更快、更准确。图 2 © 中的 ELAN [1] :通过控制最短最长的梯度路径,更深的网络可以有效地学习和收敛。在本文中,我们提出了基于 ELAN 的扩展 ELAN(E-ELAN),其主要架构如图 2(d)所示。
YOLOv7中所使用的E-ELAN使用expand、shuffle、merge cardinality来实现在不破坏原有梯度路径的情况下不断增强网络学习能力的能力。E-ELAN 只改变了计算块的架构,而过渡层的架构完全没有改变。网络块使用组卷积来扩展计算块的通道和输出特征图。我们将对计算层的所有计算块应用相同的组参数和通道乘数。然后,每个计算块计算出的特征图会根据设置的组参数g被打乱成g组,然后将它们连接在一起。此时,每组特征图的通道数将与原始架构中的通道数相同。最后,我们添加 g 组特征图来进行合并。除了保持原有的 ELAN 设计架构,E-ELAN 还可以引导不同组的计算块学习更多样化的特征,图 2(d)中添加了两组。
partial -> Partial Convolutional(部分卷积):
部分卷积来源于英伟达在ECCV2018发表的论文《Image Inpainting for Irregular Holes Using Partial Convolutions》,最初是用于图像修复的任务。论文值得好好看一下。
PConv部分卷积运算在网络中主要负责将图片中有目标区域的像素加强。每一层PConv的运算可以用以下公式来表达: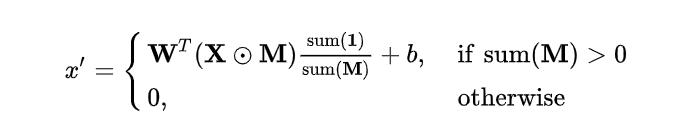
其中X为输入的feature map, M 为输入的mask(0-1分布), W 为卷积核,b为卷积运算的偏置。注意:这里的X和M都只是当前运算区域的像素,例如W为一个3×3的卷积核,那么X和M的大小也是3×3。输出的x`是单个像素,也就是3×3卷积核的中心位置。 sum(1) 是指与卷积核相同大小(例如3×3),元素全部为1的矩阵。第一层PConv的M中,1为未损坏区域,而0为损坏区域。sum(1)/sum(M)可以对输出结果进行增强,这样部分卷积运算可以对于目标区域更加敏感。
cross stage connection(交叉连接)

交叉连接的核心就是这个公式。x0是一个列向量,其中的主要运算可以看成:
(1)x0和自己的转置进行相乘(矩阵的相乘);
(2)然后和一个权重向量相乘;
(3)最后和自己原始的x相加。
在这里要注意,输入x0、w和b都是一维向量,cross network以一种参数共享的方式,通过对叠加层数的控制,可以高效地学习出低维的特征交叉组合,避免了人工特征工程