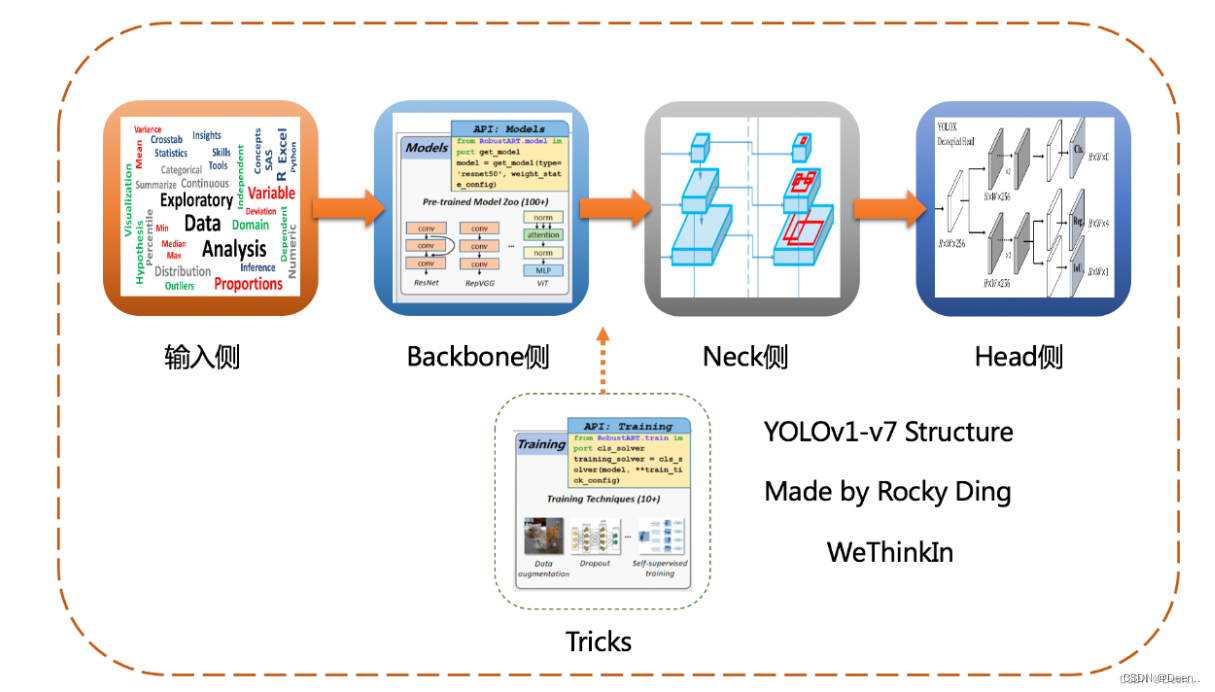
导读
按批将图片进行预测后,将结果与真实框进行loss计算。
训练相对预测部分,多了损失函数的计算以及反向求导梯度下降,进而更新函数。
训练前期属性配置
创建模型:
model = YoloBody(anchors_mask, num_classes, phi, pretrained=pretrained)
设置初始参数:
weights_init(model)
预训练权重加载
思路为:将预训练权重字典按key跟对应内容取出,判断key是否跟模型的key重合,如果重合就记录到临时字典里,直到把预训练权重都判断完毕,然后将临时字典的权重更新到模型权重里。
model_dict = model.state_dict()
pretrained_dict = torch.load(model_path, map_location = device)
load_key, no_load_key, temp_dict = [], [], {
}
for k, v in pretrained_dict.items():
if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):
temp_dict[k] = v
load_key.append(k)
else:
no_load_key.append(k)
model_dict.update(temp_dict)
model.load_state_dict(model_dict)
损失函数设置:
yolo_loss = YOLOLoss(anchors, num_classes, input_shape, anchors_mask, label_smoothing)
记录loss值函数设置,将其保存到log_dir路径下
#----------------------#
if local_rank == 0:
time_str = datetime.datetime.strftime(datetime.datetime.now(),'%Y_%m_%d_%H_%M_%S')
log_dir = os.path.join(save_dir, "loss_" + str(time_str))
loss_history = LossHistory(log_dir, model, input_shape=input_shape)
else:
loss_history = None
权值平滑
在代码中有权值平滑操作,这在yolov5中出现过:
对预模型参数做平均操作,增加模型训练时的鲁棒性,是用来在test或val时才使用,用来更新参数。
ema = torch_utils.ModelEMA(model),对应的滑动公式如下:
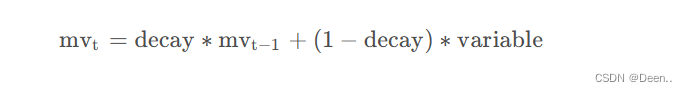
ema = ModelEMA(model_train)
class ModelEMA:
""" Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
Keeps a moving average of everything in the model state_dict (parameters and buffers)
For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
"""
def __init__(self, model, decay=0.9999, tau=2000, updates=0):
# Create EMA
self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
# if next(model.parameters()).device.type != 'cpu':
# self.ema.half() # FP16 EMA
self.updates = updates # number of EMA updates
self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs)
for p in self.ema.parameters():
p.requires_grad_(False)
def update(self, model):
# Update EMA parameters
with torch.no_grad():
self.updates += 1
d = self.decay(self.updates)
msd = de_parallel(model).state_dict() # model state_dict
for k, v in self.ema.state_dict().items():
if v.dtype.is_floating_point:
v *= d
v += (1 - d) * msd[k].detach()
def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
# Update EMA attributes
copy_attr(self.ema, model, include, exclude)
读取数据集对应的txt文件:
with open(train_annotation_path, encoding='utf-8') as f:
train_lines = f.readlines()
with open(val_annotation_path, encoding='utf-8') as f:
val_lines = f.readlines()
num_train = len(train_lines)
num_val = len(val_lines)
判断是否要冻结主干网络,并且自适应调整学习率。
if True:
UnFreeze_flag = False
#------------------------------------#
# 冻结一定部分训练
#------------------------------------#
if Freeze_Train:
for param in model.backbone.parameters():
param.requires_grad = False
#-------------------------------------------------------------------#
# 如果不冻结训练的话,直接设置batch_size为Unfreeze_batch_size
#-------------------------------------------------------------------#
batch_size = Freeze_batch_size if Freeze_Train else Unfreeze_batch_size
#-------------------------------------------------------------------#
# 判断当前batch_size,自适应调整学习率
#-------------------------------------------------------------------#
nbs = 64
lr_limit_max = 1e-3 if optimizer_type == 'adam' else 5e-2
lr_limit_min = 3e-4 if optimizer_type == 'adam' else 5e-4
Init_lr_fit = min(max(batch_size / nbs * Init_lr, lr_limit_min), lr_limit_max)
Min_lr_fit = min(max(batch_size / nbs * Min_lr, lr_limit_min * 1e-2), lr_limit_max * 1e-2)
根据optimizer_type选择优化器
pg0, pg1, pg2 = [], [], []
for k, v in model.named_modules():
if hasattr(v, "bias") and isinstance(v.bias, nn.Parameter):
pg2.append(v.bias)
if isinstance(v, nn.BatchNorm2d) or "bn" in k:
pg0.append(v.weight)
elif hasattr(v, "weight") and isinstance(v.weight, nn.Parameter):
pg1.append(v.weight)
optimizer = {
'adam' : optim.Adam(pg0, Init_lr_fit, betas = (momentum, 0.999)),
'sgd' : optim.SGD(pg0, Init_lr_fit, momentum = momentum, nesterov=True)
}[optimizer_type]
optimizer.add_param_group({
"params": pg1, "weight_decay": weight_decay})
optimizer.add_param_group({
"params": pg2})
获得学习率下降的公式
lr_scheduler_func = get_lr_scheduler(lr_decay_type, Init_lr_fit, Min_lr_fit, UnFreeze_Epoch)
def get_lr_scheduler(lr_decay_type, lr, min_lr, total_iters, warmup_iters_ratio = 0.05, warmup_lr_ratio = 0.1, no_aug_iter_ratio = 0.05, step_num = 10):
def yolox_warm_cos_lr(lr, min_lr, total_iters, warmup_total_iters, warmup_lr_start, no_aug_iter, iters):
if iters <= warmup_total_iters:
# lr = (lr - warmup_lr_start) * iters / float(warmup_total_iters) + warmup_lr_start
lr = (lr - warmup_lr_start) * pow(iters / float(warmup_total_iters), 2
) + warmup_lr_start
elif iters >= total_iters - no_aug_iter:
lr = min_lr
else:
lr = min_lr + 0.5 * (lr - min_lr) * (
1.0
+ math.cos(
math.pi
* (iters - warmup_total_iters)
/ (total_iters - warmup_total_iters - no_aug_iter)
)
)
return lr
数据集加载设置:
train_dataset = YoloDataset(train_lines, input_shape, num_classes, anchors, anchors_mask, epoch_length=UnFreeze_Epoch, \
mosaic=mosaic, mixup=mixup, mosaic_prob=mosaic_prob, mixup_prob=mixup_prob, train=True, special_aug_ratio=special_aug_ratio)
val_dataset = YoloDataset(val_lines, input_shape, num_classes, anchors, anchors_mask, epoch_length=UnFreeze_Epoch, \
mosaic=False, mixup=False, mosaic_prob=0, mixup_prob=0, train=False, special_aug_ratio=0)
数据集生成器设置:
gen = DataLoader(train_dataset, shuffle = shuffle, batch_size = batch_size, num_workers = num_workers, pin_memory=True,
drop_last=True, collate_fn=yolo_dataset_collate, sampler=train_sampler)
gen_val = DataLoader(val_dataset , shuffle = shuffle, batch_size = batch_size, num_workers = num_workers, pin_memory=True,
drop_last=True, collate_fn=yolo_dataset_collate, sampler=val_sampler)
计算验证集的map并且做保存处理的类实例
eval_callback = EvalCallback(model, input_shape, anchors, anchors_mask, class_names, num_classes, val_lines, log_dir, Cuda, \
eval_flag=eval_flag, period=eval_period)
开始训练
一个epoch一个epoch的迭代训练,假设在为冻结训练。代码如下:
for epoch in range(Init_Epoch, UnFreeze_Epoch):
#epoch_nows跟 special_aug_ratio搭配使用,用来控制mosiac的。
gen.dataset.epoch_now = epoch
gen_val.dataset.epoch_now = epoch
if distributed:
train_sampler.set_epoch(epoch)
set_optimizer_lr(optimizer, lr_scheduler_func, epoch)
fit_one_epoch(model_train, model, ema, yolo_loss, loss_history, eval_callback, optimizer, epoch, epoch_step, epoch_step_val, gen, gen_val, UnFreeze_Epoch, Cuda, fp16, scaler, save_period, save_dir, local_rank)
if distributed:
dist.barrier()
if local_rank == 0:
loss_history.writer.close()
单轮训练fit_one_epoch:
训练阶段还是比较熟悉的几个流程,如从加载器中取出图片,然后向前传播,损失计算,反向传播,梯度更新,在验证阶段用到了ema也就是权值平滑。再将loss记录下来
def fit_one_epoch(model_train, model, ema, yolo_loss, loss_history, eval_callback, optimizer, epoch, epoch_step, epoch_step_val, gen, gen_val, Epoch, cuda, fp16, scaler, save_period, save_dir, local_rank=0):
loss = 0
val_loss = 0
if local_rank == 0:
print('Start Train')
pbar = tqdm(total=epoch_step,desc=f'Epoch {
epoch + 1}/{
Epoch}',postfix=dict,mininterval=0.3)
model_train.train()
for iteration, batch in enumerate(gen):
if iteration >= epoch_step:
break
images, targets = batch[0], batch[1]
with torch.no_grad():
if cuda:
images = images.cuda(local_rank)
targets = targets.cuda(local_rank)
#----------------------#
# 清零梯度
#----------------------#
optimizer.zero_grad()
if not fp16:
#----------------------#
# 前向传播
#----------------------#
outputs = model_train(images)
loss_value = yolo_loss(outputs, targets, images)
#----------------------#
# 反向传播
#----------------------#
loss_value.backward()
optimizer.step()
else:
from torch.cuda.amp import autocast
with autocast():
#----------------------#
# 前向传播
#----------------------#
outputs = model_train(images)
loss_value = yolo_loss(outputs, targets, images)
#----------------------#
# 反向传播
#----------------------#
scaler.scale(loss_value).backward()
scaler.step(optimizer)
scaler.update()
if ema:
ema.update(model_train)
loss += loss_value.item()
if local_rank == 0:
pbar.set_postfix(**{
'loss' : loss / (iteration + 1),
'lr' : get_lr(optimizer)})
pbar.update(1)
然后做验证集loss计算与Map计算,当验证机的loss小于历史所存最小loss则保存该轮的训练权值。
if ema:
model_train_eval = ema.ema
else:
model_train_eval = model_train.eval()
for iteration, batch in enumerate(gen_val):
if iteration >= epoch_step_val:
break
images, targets = batch[0], batch[1]
with torch.no_grad():
if cuda:
images = images.cuda(local_rank)
targets = targets.cuda(local_rank)
#----------------------#
# 清零梯度
#----------------------#
optimizer.zero_grad()
#----------------------#
# 前向传播
#----------------------#
outputs = model_train_eval(images)
loss_value = yolo_loss(outputs, targets, images)
val_loss += loss_value.item()
if local_rank == 0:
pbar.set_postfix(**{
'val_loss': val_loss / (iteration + 1)})
pbar.update(1)
if local_rank == 0:
pbar.close()
print('Finish Validation')
loss_history.append_loss(epoch + 1, loss / epoch_step, val_loss / epoch_step_val)
eval_callback.on_epoch_end(epoch + 1, model_train_eval)
print('Epoch:'+ str(epoch + 1) + '/' + str(Epoch))
print('Total Loss: %.3f || Val Loss: %.3f ' % (loss / epoch_step, val_loss / epoch_step_val))
#-----------------------------------------------#
# 保存权值
#-----------------------------------------------#
if ema:
save_state_dict = ema.ema.state_dict()
else:
save_state_dict = model.state_dict()
if (epoch + 1) % save_period == 0 or epoch + 1 == Epoch:
torch.save(save_state_dict, os.path.join(save_dir, "ep%03d-loss%.3f-val_loss%.3f.pth" % (epoch + 1, loss / epoch_step, val_loss / epoch_step_val)))
if len(loss_history.val_loss) <= 1 or (val_loss / epoch_step_val) <= min(loss_history.val_loss):
print('Save best model to best_epoch_weights.pth')
torch.save(save_state_dict, os.path.join(save_dir, "best_epoch_weights.pth"))
torch.save(save_state_dict, os.path.join(save_dir, "last_epoch_weights.pth"))
全部代码:
def fit_one_epoch(model_train, model, ema, yolo_loss, loss_history, eval_callback, optimizer, epoch, epoch_step, epoch_step_val, gen, gen_val, Epoch, cuda, fp16, scaler, save_period, save_dir, local_rank=0):
loss = 0
val_loss = 0
if local_rank == 0:
print('Start Train')
pbar = tqdm(total=epoch_step,desc=f'Epoch {
epoch + 1}/{
Epoch}',postfix=dict,mininterval=0.3)
model_train.train()
for iteration, batch in enumerate(gen):
if iteration >= epoch_step:
break
images, targets = batch[0], batch[1]
with torch.no_grad():
if cuda:
images = images.cuda(local_rank)
targets = targets.cuda(local_rank)
#----------------------#
# 清零梯度
#----------------------#
optimizer.zero_grad()
if not fp16:
#----------------------#
# 前向传播
#----------------------#
outputs = model_train(images)
optimizer.zero_grad()
loss_value = yolo_loss(outputs, targets, images)
#----------------------#
# 反向传播
#----------------------#
loss_value.backward()
optimizer.step()
else:
from torch.cuda.amp import autocast
with autocast():
#----------------------#
# 前向传播
#----------------------#
outputs = model_train(images)
loss_value = yolo_loss(outputs, targets, images)
#----------------------#
# 反向传播
#----------------------#
scaler.scale(loss_value).backward()
scaler.step(optimizer)
scaler.update()
if ema:
ema.update(model_train)
loss += loss_value.item()
if local_rank == 0:
pbar.set_postfix(**{
'loss' : loss / (iteration + 1),
'lr' : get_lr(optimizer)})
pbar.update(1)
if local_rank == 0:
pbar.close()
print('Finish Train')
print('Start Validation')
pbar = tqdm(total=epoch_step_val, desc=f'Epoch {
epoch + 1}/{
Epoch}',postfix=dict,mininterval=0.3)
if ema:
model_train_eval = ema.ema
else:
model_train_eval = model_train.eval()
for iteration, batch in enumerate(gen_val):
if iteration >= epoch_step_val:
break
images, targets = batch[0], batch[1]
with torch.no_grad():
if cuda:
images = images.cuda(local_rank)
targets = targets.cuda(local_rank)
#----------------------#
# 清零梯度
#----------------------#
optimizer.zero_grad()
#----------------------#
# 前向传播
#----------------------#
outputs = model_train_eval(images)
loss_value = yolo_loss(outputs, targets, images)
val_loss += loss_value.item()
if local_rank == 0:
pbar.set_postfix(**{
'val_loss': val_loss / (iteration + 1)})
pbar.update(1)
if local_rank == 0:
pbar.close()
print('Finish Validation')
loss_history.append_loss(epoch + 1, loss / epoch_step, val_loss / epoch_step_val)
eval_callback.on_epoch_end(epoch + 1, model_train_eval)
print('Epoch:'+ str(epoch + 1) + '/' + str(Epoch))
print('Total Loss: %.3f || Val Loss: %.3f ' % (loss / epoch_step, val_loss / epoch_step_val))
#-----------------------------------------------#
# 保存权值
#-----------------------------------------------#
if ema:
save_state_dict = ema.ema.state_dict()
else:
save_state_dict = model.state_dict()
if (epoch + 1) % save_period == 0 or epoch + 1 == Epoch:
torch.save(save_state_dict, os.path.join(save_dir, "ep%03d-loss%.3f-val_loss%.3f.pth" % (epoch + 1, loss / epoch_step, val_loss / epoch_step_val)))
if len(loss_history.val_loss) <= 1 or (val_loss / epoch_step_val) <= min(loss_history.val_loss):
print('Save best model to best_epoch_weights.pth')
torch.save(save_state_dict, os.path.join(save_dir, "best_epoch_weights.pth"))
torch.save(save_state_dict, os.path.join(save_dir, "last_epoch_weights.pth"))